Java NIO Reactor网络编程模型的深度理解
Posted 刘Java
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java NIO Reactor网络编程模型的深度理解相关的知识,希望对你有一定的参考价值。
详细介绍了Reactor网络编程模型的概念。
此前,我们介绍了了Java中常见的四种网络IO模型:Java 四种常见网络IO模型以及select、poll、epoll函数的简单介绍。现在我们来看看基于IO多路复用演变而来的Reactor网络编程模型。
1 Reactor模型的介绍
常见的网络编程模型并不是最基本的四种网络IO模型,因为这涉及到了底层代码的编写,大佬们在基本网络IO模型的基础上采用面向对象的方式进行了进一步封装,形成了更加易于理解的Reactor、Proactor、Acceptor-Connector等编程模型。Reactor模型是最常见的网络编程模型,大名鼎鼎的Netty、Tomcat等框架或者软件都是使用Reactor模型实现高并发、高性能的网络通信。
Java并发编程之父Doug Lea早在多年之前就对Reactor模型进行了详尽的阐述:http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf,Java nio包中的Selector就是基于最简单的Reactor模型实现的,在Doug Lea的文章中还给出了一些使用案例。
IO 多路复用模型我们此前就学过了,好处主要有两个:一是该模型能够在同一个线程内同时监听多个IO请求,系统不必创建大量的线程,从而大大减小了系统的开销。二是阻塞等待的方式能减少无效的系统调用,减少了对 CPU 资源的消耗。
Reactor模型是IO 多路复用模型的进一步面向对象的封装,让使用者不用考虑底层网络 API 的细节,只需要关注应用代码的编写。Reactor直译过来就是反应器,这里的反应是指对事件的反应:当IO多路复用程序监听并收到事件通知之后,根据事件类型分配给不同的处理器处理,因此Reactor 模型也被称为 Dispatcher (分派器)模型,或者称为基于事件驱动的模型。
Reactor模型可以抽象出两个重要组件:
- Reactor,专门用于监听和响应各种IO事件,比如连接建立就绪(ACCEPT)、读就绪(READ)、写就绪(WRITE)等,当检测到一个新的事件到来时,将其发送给相应的Handler去处理。
- Handler,专门用于处理特定的事件,比如读取数据,业务逻辑执行,写出响应等。
Reactor模型发展至今,包含了多种实现,常见的有单Reactor单线程模式、单Reactor多线程模式,多Reactor多线程模式。
2 单Reactor单线程模式
Doug Lea文章中给出的该模式的流程图如下:

上图中,Reactor用于监听各种IO事件,并分配(dispatch)给特定的Handler,accepter组件专门用于处理建立连接事件,可以看做是一个特殊的Handler。
总体流程为:
- 服务端的Reactor 线程对象通过循环 select调用(IO 多路复用)监听各种IO事件,还会注册一个accepter事件处理器到Reactor中,accepter专用于处理建立连接事件。
- 客户端首先发起一个建立连接的请求,Reactor监听到ACCEPT事件的到来后将该ACCEPT事件分派给accepter组件,accepter通过accept()方法与客户端建立对应的连接(SocketChannel),然后将该连接所关注的READ事件以及对应的READ事件处理器注册到Reactor中,这样Reactor就会监听该连接的READ事件。
- 当Reactor监听到该连接有读或者写事件发生时,将相关的事件派发给对应的处理器进行处理。比如,读处理器会通过SocketChannel的read()方法直接读取到数据,随后可进行各种业务处理,之后需要向客户端发送数据时,也可以注册该连接的WRITE事件和其对应的处理器,当channel可写时,通过SocketChannel的wtite()方法写数据。
- 每当处理完所有就绪的IO事件后,Reactor线程会再次执行select()操作阻塞等待新的事件就绪并将其分派给对应处理器进行处理。
单Reactor单线程模式的意思就是以上的Reactor和Hander的所有操作都是在同一个线程中完成的。上面的select、accept、read、wtite等调用以及业务逻辑处理,都是在同一个线程中完成的。
单Reactor单线程模式是最基础的Reactor模型,实现起来比较简单,由于是单线程,业务代码编写也不用考虑有任何的并发问题,Java的NIO模式的Selector底层其实就是最简单的单Reactor单线程模式。
但是单Reactor单线程模式只有一个线程工作,无法充分利用现代多核CPU的性能,并且如果某个client的业务逻辑耗时较长,将会造成后续其他client的请求阻塞执行。
因为Redis的业务处理主要都是在内存中完成,内存操作的速度很快,Redis性能瓶颈不在 CPU 上(在网络IO的消耗以及内存上),加上这种模式实现起来也很简单,所以Redis 6之前的对于命令的执行也是单Reactor单线程模型。
但是在Redis 6之后还是引入了多线程机制(多线程真香),但Redis 的多线程只是在网络IO数据的读写这类耗时操作上使用,降低了网络IO带来的性能损耗,而实际执行命令(Handler)仍然是单线程顺序执行的,因此也不需要担心Redis的线程安全问题。
2.1 伪代码
Doug Lea文章中给出的单Reactor单线程模式的伪代码如下:
Reactor:
/**
* Reactor
* 负责监听并分发事件
*/
class Reactor implements Runnable {
final Selector selector;
final ServerSocketChannel serverSocket;
Reactor(int port) throws IOException { //Reactor初始化
selector = Selector.open();
serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(port));
//socket设置为非阻塞
serverSocket.configureBlocking(false);
//注册监听accept事件
SelectionKey sk =
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
//注册一个Acceptor作为accept事件的回调
sk.attach(new Acceptor());
}
@Override
public void run() {
try {
while (!Thread.interrupted()) {
//循环调用select等到事件就绪
selector.select();
Set selected = selector.selectedKeys();
Iterator it = selected.iterator();
while (it.hasNext()) {
//Reactor负责dispatch收到的事件
dispatch((SelectionKey) (it.next()));
}
selected.clear();
}
} catch (IOException ex) { /* ... */ }
}
void dispatch(SelectionKey k) {
Runnable r = (Runnable) (k.attachment());
//调用之前注册的callback对象
if (r != null) {
r.run();
}
}
/**
* Acceptor
* 处理accept事件的回调函数
*/
class Acceptor implements Runnable {
@Override
public void run() {
try {
SocketChannel channel = serverSocket.accept();
if (channel != null) {
new Handler(selector, channel);
}
} catch (IOException ex) { /* ... */ }
}
}
}
Handler:
class Handler implements Runnable {
final SocketChannel channel;
final SelectionKey sk;
final int MAXIN = 2048;
final int MAXOUT = 2048;
//分配缓冲区
ByteBuffer input = ByteBuffer.allocate(MAXIN);
ByteBuffer output = ByteBuffer.allocate(MAXOUT);
static final int READING = 0, SENDING = 1;
int state = READING;
Handler(Selector selector, SocketChannel c) throws IOException {
channel = c;
c.configureBlocking(false);
// 默认不注册任何事件
// 0表示对这个channel的任何事件都不感兴趣,这样会导致永远select不到这个channel
sk = channel.register(selector, 0);
//将当前Handler对象作为事件就绪时的callback对象
sk.attach(this);
//注册Read就绪事件
sk.interestOps(SelectionKey.OP_READ);
selector.wakeup();
}
boolean inputIsComplete() {
/* ... */
return false;
}
boolean outputIsComplete() {
/* ... */
return false;
}
void process() {
/* ... */
return;
}
@Override
public void run() {
try {
//处理读就绪事件
if (state == READING) {
read();
//处理写就绪事件
} else if (state == SENDING) {
send();
}
} catch (IOException ex) { /* ... */ }
}
/**
* 处理读就绪事件
*/
void read() throws IOException {
//读取数据
channel.read(input);
if (inputIsComplete()) {
//处理数据
process();
state = SENDING;
//数据处理完毕,需要写数据
//开始监听写就绪事件
sk.interestOps(SelectionKey.OP_WRITE);
}
}
/**
* 处理写就绪事件
*/
void send() throws IOException {
channel.write(output);
//write完就表示一次事件处理完毕结,关闭SelectionKey
if (outputIsComplete()) {
sk.cancel();
}
}
}
3 单Reactor多线程模式
为了克服单Reactor单线程模型下无法利用多核CPU的优势以及可能因为某个请求的业务执行时间过长造成后续请求IO阻塞的问题,发展出了单Reactor多线程模型。
Doug Lea文章中给出的该模式的流程图如下:
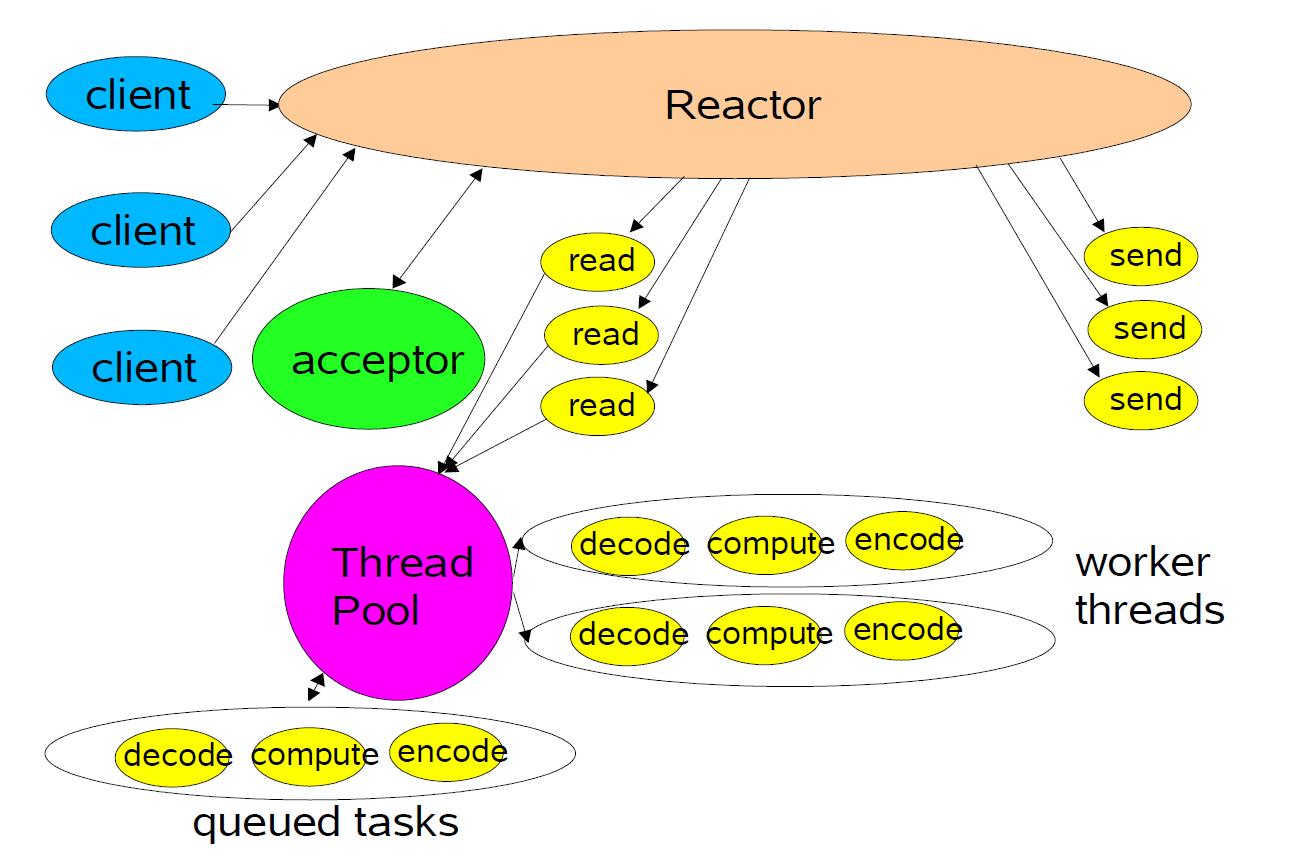
上图中,单个Reactor线程用于监听各种IO事件,并分配(dispatch)给特定的Handler,这一点和单Reactor单线程模型是一样的,区别该改模型还添加了一个工作线程池,将非IO操作(除了read、send调用之外的业务操作)从Reactor线程中移出转交给工作线程池来并发的执行。
总体流程为:
- 服务端的Reactor 线程对象通过循环 select调用(IO 多路复用)监听各种IO事件,还会注册一个accepter事件处理器到Reactor中,accepter专用于处理建立连接事件。
- 客户端首先发起一个建立连接的请求,Reactor监听到ACCEPT事件的到来后将该ACCEPT事件分派给accepter组件,accepter通过accept()方法与客户端建立对应的连接(SocketChannel),然后将该连接所关注的READ事件以及对应的READ事件处理器注册到Reactor中,这样Reactor就会监听该连接的READ事件。
- 当Reactor监听到该连接有读或者写事件发生时,将相关的事件派发给对应的处理器进行处理。比如,读处理器会通过SocketChannel的read()方法直接读取到数据,随后可进行各种业务处理,之后需要向客户端发送数据时,也可以注册该连接的WRITE事件和其对应的处理器,当channel可写时,通过SocketChannel的wtite()方法写数据。
- 这里和单Reactor单线程模型的不同点就是,Reactor线程只负责Hander中的网络IO调用,即read读取数据和send发送数据调用,读取到数据之后的处理,比如反序列化、执行业务逻辑、序列化等操作则是通过一个线程池来并行执行的。
- 每当处理完所有就绪的IO事件后,Reactor线程会再次执行select()操作阻塞等待新的事件就绪并将其分派给对应处理器进行处理。
该模式中,Handler处理时除了read和send调用之外的其他业务逻辑都是多线程执行的,这样就可以让Reactor线程更快的进行下一轮的select操作,提升了对于请求的IO响应速度,不至于因为一些耗时的业务逻辑而延迟对后面IO请求的处理。
该模式中能够充分利用多核 CPU 性能,但是会带来多线程并发的问题,对于业务逻辑的编写需要特别注意共享数据的处理。
另外,虽然该模式下业务处理使用了异步执行,效率有所提升,但是仍然是采用单个 Reactor 线程承担所有事件的监听和基本IO操作,比如accept、read、send、connect操作,在面对瞬间到来的成百上千个连接这样的高并发场景时,仍然会成为性能瓶颈。
3.1 伪代码
Doug Lea文章中给出的单Reactor多线程模式的伪代码如下:
Handler类变成了支持多线程处理业务的MthreadHandler,Reactor类没有太大变化,在Acceptor中,new Handler变成了new MthreadHandler:
class MthreadHandler implements Runnable {
final SocketChannel channel;
final SelectionKey selectionKey;
final int MAXIN = 2048;
final int MAXOUT = 2048;
ByteBuffer input = ByteBuffer.allocate(MAXIN);
ByteBuffer output = ByteBuffer.allocate(MAXOUT);
static final int READING = 0, SENDING = 1;
int state = READING;
/**
* 设置一个静态线程池
*/
static ExecutorService pool = Executors.newFixedThreadPool(2);
static final int PROCESSING = 3;
MthreadHandler(Selector selector, SocketChannel c) throws IOException {
channel = c;
c.configureBlocking(false);
selectionKey = channel.register(selector, 0);
selectionKey.attach(this);
selectionKey.interestOps(SelectionKey.OP_READ);
selector.wakeup();
}
boolean inputIsComplete() {
/* ... */
return false;
}
boolean outputIsComplete() {
/* ... */
return false;
}
@Override
public void run() {
try {
if (state == READING) {
read();
} else if (state == SENDING) {
send();
}
} catch (IOException ex) { /* ... */ }
}
synchronized void read() throws IOException {
//接受数据
channel.read(input);
if (inputIsComplete()) {
state = PROCESSING;
/*
* 使用线程池中的线程异步的处理数据,执行业务逻辑
*
* 该调用执行之后Reactor线程可以马上返回,不需要等到业务执行完毕
*/
pool.execute(new Processer());
}
}
void send() throws IOException {
channel.write(output);
if (outputIsComplete()) {
selectionKey.cancel();
}
}
/**
* 异步任务
*/
class Processer implements Runnable {
@Override
public void run() {
processAndHandOff();
}
}
synchronized void processAndHandOff() {
//执行业务
process();
state = SENDING;
//数据处理完毕,需要写数据
//开始监听写就绪事件
selectionKey.interestOps(SelectionKey.OP_WRITE);
}
void process() {
/* ... */
return;
}
}
4 多Reactor多线程模式
为了不让单个Reactor成为性能瓶颈,我们可以继续改造,将一个Reactor的功能拆分为“连接客户端”和“与客户端通信”两部分,由不同的Reactor实例(多个Reactor线程)来共同完成,这就是多Reactor多线程模式,也被称为Reactor主从多线程模式。
Doug Lea文章中给出的该模式的流程图如下:

mainReactor拥有自己的Selector,通过 select 专门监控连接建立事件,事件准备就绪后通过 Acceptor 对象中的 accept 检核与客户端的连接,随后将新的连接分配给某个subReactor,subReactor也有自己的Selector,在subReactor中对该连接继续进行监听并执行其他事件,比如读就绪和写就绪事件,这样就将Reactor的工作分为两部分,这两部分可以在独立的线程中执行,进一步提升性能。
总体流程为:
- 服务端的mainReactor线程通过循环 select调用(IO 多路复用)监听连接建立事件,还会注册一个accepter事件处理器到Reactor中,accepter专用于处理建立连接事件。
- 客户端首先发起一个建立连接的请求,mainReactor监听到ACCEPT事件的到来后将该ACCEPT事件分派给accepter组件,accepter通过accept()方法与客户端建立对应的连接(SocketChannel),然后将该连接分配给一个subReactor。随后mainReactor线程返回,继续执行下一轮的select监听操作。
- subReactor也有自己的Selector,它会将该连接将所关注的READ事件以及对应的READ事件处理器注册并通过select监听该连接的READ事件。
- 当subReactor监听到该连接有读或者写事件发生时,将相关的事件派发给对应的处理器进行处理。比如,读处理器会通过SocketChannel的read()方法直接读取到数据,随后可进行各种业务处理,之后需要向客户端发送数据时,也可以注册该连接的WRITE事件和其对应的处理器,当channel可写时,通过SocketChannel的wtite()方法写数据。
- subReactor线程只负责Hander中的网络IO调用,即read读取数据和send发送数据调用,读取到数据之后的处理,比如反序列化、执行业务逻辑、序列化等操作则是通过一个线程池来并行执行的。
- 每当处理完所有就绪的IO事件后,subReactor线程会再次执行select()操作阻塞等待新的事件就绪并将其分派给对应处理器进行处理。
多 Reactor 多线程模式中,mainReactor和subReactor都可以有多个,每一个都有自己的Selector,都在一个独立的线程中工作,这样进一步利用了多核CPU的多线程优势,让Reactor不会轻易成为性能瓶颈,提升了连接速度以及IO读写的速度。
但多 Reactor 多线程模式仍然不能从根源上解决耗时的IO操作对其他的client的影响,因为一个subReactor仍有可能对应多个client连接,为此,可以使用真正的异步IO模型演化而来的设计模式—Proactor模式来实现真正的异步IO。
Netty 和 Memcached 都是采用的多 Reactor 多线程模式。Nginx 也是采用多 Reactor 多进程模式。实际上Netty的多 Reactor 多线程模式实现更为简单,subReactor处理read、write等IO操作的同时还处理业务的执行,即去掉了工作者线程池(Thread Pool),或者说SubReactor和Worker线程在同一个线程池中:
- mainReactor对应Netty中配置的BossGroup线程组,主要负责接受客户端连接的建立。一般只暴露一个服务端口,BossGroup线程组一般一个线程工作即可
- subReactor对应Netty中配置的WorkerGroup线程组,BossGroup线程组接受并建立完客户端的连接后,将网络socket转交给WorkerGroup线程组,然后在WorkerGroup线程组内选择一个线程,进行I/O的处理。WorkerGroup线程组主要处理I/O,一般设置2*CPU核数个线程。
Netty 可以通过配置的参数同时支持 Reactor 单线程模型、多线程模型,默认模式时上面的多 Reactor 多线程模式变体。
4.1 伪代码
Doug Lea文章中给出的多Reactor多线程模式的伪代码如下:
class MthreadReactor implements Runnable {
/**
* subReactors集合, 一个selector代表一个subReactor
*/
Selector[] selectors = new Selector[2];
int next = 0;
final ServerSocketChannel serverSocket;
/**
* mainSelector
*/
final Selector selector;
MthreadReactor(int port) throws IOException {
selector = Selector.open();
selectors[0] = Selector.open();
selectors[1] = Selector.open();
serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(port));
serverSocket.configureBlocking(false);
//监听accept事件
SelectionKey sk =
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
//Acceptor用于建立连接
sk.attach(new Acceptor());
}
@Override
public void run() {
try {
while (!Thread.interrupted()) {
selector.select();
Set selected = selector.selectedKeys();
Iterator it = selected.iterator();
while (it.hasNext()) {
//Reactor负责dispatch收到的事件
dispatch((SelectionKey) (it.next()));
}
selected.clear();
}
} catch (IOException ex) { /* ... */ }
}
void dispatch(SelectionKey k) {
Runnable r = (Runnable) (k.attachment());
//调用之前注册的callback对象
if (r != null) {
r.run();
}
}
class Acceptor implements Runnable { // ...
@SneakyThrows
@Override
public synchronized void run() {
//mainSelector负责accept建立连接
try (SocketChannel connection = serverSocket.accept()) {
//连接建立之后将连接传给一个subSelector,监听read和write事件
if (connection != null) {
new Handler(selectors[next], connection); //选个subReactor去负责接收到的connection
}
}
if (++next == selectors.length) {
next = 0;
}
}
}
}
参考资料:
如有需要交流,或者文章有误,请直接留言。另外希望点赞、收藏、关注,我将不间断更新各种Java学习博客!
以上是关于Java NIO Reactor网络编程模型的深度理解的主要内容,如果未能解决你的问题,请参考以下文章