PyTorch开源图像分类算法框架
Posted SpikeKing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch开源图像分类算法框架相关的知识,希望对你有一定的参考价值。
PyTorch的开源图像分类算法框架pytorch-image-models,功能完善,集成大量数据增强方法和主流的网络框架,同时易用。
- pytorch-image-models:https://github.com/rwightman/pytorch-image-models
训练
使用方法:
- 训练脚本:train.py
- 数据集:训练train,验证val,标签文件夹+图像模式
训练脚本:
python3 train.py ./mydata/clz_dataset/ --dataset clz_dataset --train-split train --val-split val --num-classes 6 --batch-size 24 --input-size 3 336 336
- 第1个参数是数据集路径;
--dataset是数据集名称--train-split是训练集名称--val-split是验证集名称--num-classes是输出类别,默认与模型相同,例如默认resnet50的类别是ImageNet的1000个--batch_size是batch_size,默认是128,显卡单卡2080+224x224大约是48--input-size是输入尺寸,3维,例如修改为3 336 336
例如:
nohup python3 -u train.py ../MobileNetV3-Doc-Clz/mydata/document_dataset_v2_1/ --dataset document_dataset_v2_1 --train-split train --val-split val --num-classes 6 --batch-size 24 --input-size 3 336 336 > nohup.out &
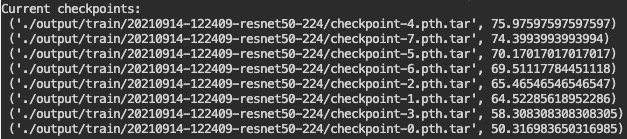
输出模型,默认位于./output/train/中,显示当前模型效果:
验证
测试逻辑如下:
- 使用已训练的模型,如model_best_c6_20210914.pth.tar
- 设置训练模型时相对应的网络结构,如resnet50,设置类别数
- 下载预训练模型resnet50_ram-a26f946b.pth,放置于
/Users/xxx/.cache/torch/hub/checkpoint - 预测结果,需要先转cpu()再转numpy(),避免在GPU环境下报错
参考:https://github.com/rwightman/pytorch-image-models/blob/master/docs/models/resnet.md
源码,面向对象的推理类:
#!/usr/bin/env python
# -- coding: utf-8 --
"""
Copyright (c) 2021. All rights reserved.
Created by C. L. Wang on 15.9.21
"""
import os
import cv2
import torch
from PIL import Image
from torch.nn import functional as F
import timm
from myutils.project_utils import download_url_img
from root_dir import DATA_DIR
from timm.data import resolve_data_config
from timm.data.transforms_factory import create_transform
class ImgPredictor(object):
"""
预测图像
"""
def __init__(self, model_path, base_net, num_classes):
print('[Info] ------ 预测图像 ------')
self.model_path = model_path
self.model, self.transform = self.load_model(self.model_path, base_net, num_classes)
print('[Info] 模型路径: {}'.format(self.model_path))
print('[Info] base_net: {}'.format(base_net))
print('[Info] num_classes: {}'.format(num_classes))
@staticmethod
def load_model(model_path, base_net, num_classes):
"""
加载模型
"""
model = timm.create_model(model_name=base_net, pretrained=False,
checkpoint_path=model_path, num_classes=num_classes)
if torch.cuda.is_available():
print('[Info] cuda on!!!')
model = model.cuda()
model.eval()
config = resolve_data_config({}, model=model)
transform = create_transform(**config)
return model, transform
@staticmethod
def preprocess_img(img_rgb, transform):
"""
预处理图像
"""
img_pil = Image.fromarray(img_rgb.astype('uint8')).convert('RGB')
img_tensor = transform(img_pil).unsqueeze(0) # transform and add batch dimension
if torch.cuda.is_available():
img_tensor = img_tensor.cuda()
return img_tensor
def predict_img(self, img_rgb):
"""
预测RGB图像
"""
print('[Info] 预测图像尺寸: {}'.format(img_rgb.shape))
img_tensor = self.preprocess_img(img_rgb, self.transform)
print('[Info] 模型输入: {}'.format(img_rgb.shape))
with torch.no_grad():
out = self.model(img_tensor)
probabilities = F.softmax(out[0], dim=0)
print('[Info] 模型结果: {}'.format(probabilities.shape))
top5_prob, top5_catid = torch.topk(probabilities, 5)
top5_catid = list(top5_catid.cpu().numpy())
top5_prob = list(top5_prob.cpu().numpy())
print('[Info] 预测类别: {}'.format(top5_catid))
print('[Info] 预测概率: {}'.format(top5_prob))
return top5_catid, top5_prob
def predict_img_path(self, img_path):
"""
预测图像路径
"""
img_bgr = cv2.imread(img_path)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
top5_catid, top5_prob = self.predict_img(img_rgb)
return top5_catid, top5_prob
def predict_img_url(self, img_url):
"""
预测图像URL
"""
_, img_bgr = download_url_img(img_url)
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB)
top5_catid, top5_prob = self.predict_img(img_rgb)
return top5_catid, top5_prob
@staticmethod
def convert_catid_2_label(catid_list, label_list):
"""
预测类别id转换为str
"""
str_list = [label_list[int(ci)] for ci in catid_list]
return str_list
def main():
img_path = os.path.join(DATA_DIR, "document_dataset_mini", "train", "000", "train_040000_000.jpg")
# img_path = os.path.join(DATA_DIR, "document_dataset_mini", "train", "001", "train_060000_001.jpg")
# img_path = os.path.join(DATA_DIR, "document_dataset_mini", "train", "002", "train_020000_002.jpg")
# img_path = os.path.join(DATA_DIR, "document_dataset_mini", "train", "003", "train_100000_003.jpg")
# img_path = os.path.join(DATA_DIR, "document_dataset_mini", "train", "004", "train_000000_004.jpg")
# img_path = os.path.join(DATA_DIR, "document_dataset_mini", "train", "005", "train_080000_005.jpg")
model_path = os.path.join(DATA_DIR, "models", "model_best_c6_20210915.pth.tar")
base_net = "resnet50"
num_classes = 6
label_list = ["纸质文档", "拍摄电脑屏幕", "精美生活照", "不确定的类别", "手机截屏", "卡证"]
me = ImgPredictor(model_path, base_net, num_classes)
top5_catid, top5_prob = me.predict_img_path(img_path)
top5_cat = me.convert_catid_2_label(top5_catid, label_list)
print('[Info] 预测类别: {}'.format(top5_cat))
print('[Info] 预测概率: {}'.format(top5_prob))
if __name__ == '__main__':
main()
输出:
[Info] ------ 预测图像 ------
[Info] 模型路径: /Users/wang/workspace/pytorch-image-models-my/mydata/models/model_best_c6_20210915.pth.tar
[Info] base_net: resnet50
[Info] num_classes: 6
[Info] 预测图像尺寸: (3587, 1842, 3)
[Info] 模型输入: (3587, 1842, 3)
[Info] 模型结果: torch.Size([6])
[Info] 预测类别: [0, 4, 1, 2, 3]
[Info] 预测概率: [0.9736742, 0.011683866, 0.0074456413, 0.0031396446, 0.0024162722]
[Info] 预测类别: ['纸质文档', '手机截屏', '拍摄电脑屏幕', '精美生活照', '不确定的类别']
[Info] 预测概率: [0.9736742, 0.011683866, 0.0074456413, 0.0031396446, 0.0024162722]
以上是关于PyTorch开源图像分类算法框架的主要内容,如果未能解决你的问题,请参考以下文章