为什么大厂都在用 Spark?
Posted zhisheng_blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么大厂都在用 Spark?相关的知识,希望对你有一定的参考价值。
现在,几乎所有公司都离不开推荐、广告、搜索这 3 类业务场景,因此 Spark 也相应成了大多数互联网公司的标配:
美团在 2014 年就引入 Spark,并将其逐渐覆盖到大多数业务线;字节跳动也基于 Spark 构建数据仓库,去服务了几乎所有的产品线;还有 Facebook 也将数据分析引擎切换为 Spark。
以美团为例,它海量的日志数据将被汇总处理、分析、挖掘与学习,为各种推荐、搜索系统甚至公司战略目标制定提供数据支持。
而 Spark 能在相同资源使用情况下,把作业执行的速度提升百倍,极大的提高了生产效率,这也是 Spark 逐步替代 MapReduce 作业,成为美团大数据处理的主流计算引擎的原因。
我觉得,在发展迅猛的数据应用领域,Spark 能持久地立于不败之地,主要是因为它“快”和“全”。
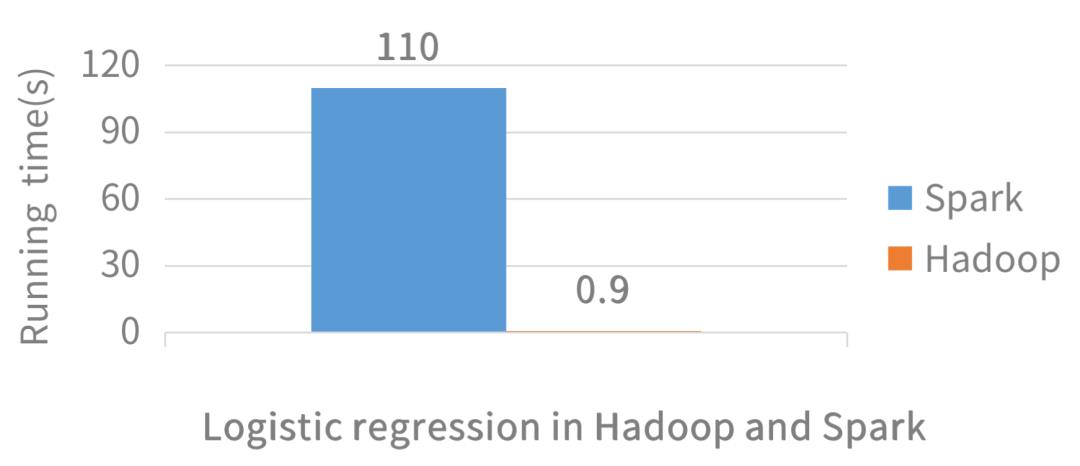
Hadoop 和 Spark 的对数几率回归对比
运行速度相差 100 倍
Spark 的开发和执行效率都很快,它支持多种开发语言,提供种类丰富的开发算子,让开发者能快速地完成数据应用开发;另外,它在计算场景的支持上也非常强大,能让开发者在同一套计算框架之内,实现不同类型的数据应用。

Spark 子框架与不同的计算场景
在数据应用领域,无论你是大数据工程师、数据分析师、数据科学家,还是机器学习算法研究员,Spark 都是必备的傍身之计。
但入门 Spark 却不是件容易的事,知识点繁多复杂,Scala 语法也晦涩难懂。如果只照本宣科地看原理,一旦遇到具体的业务需求,大概率还是无从下手。
这里推荐给你一副「Spark 知识体系全景图」,涉及 Spark 入门必备的 80% 以上的知识点,十分全面。
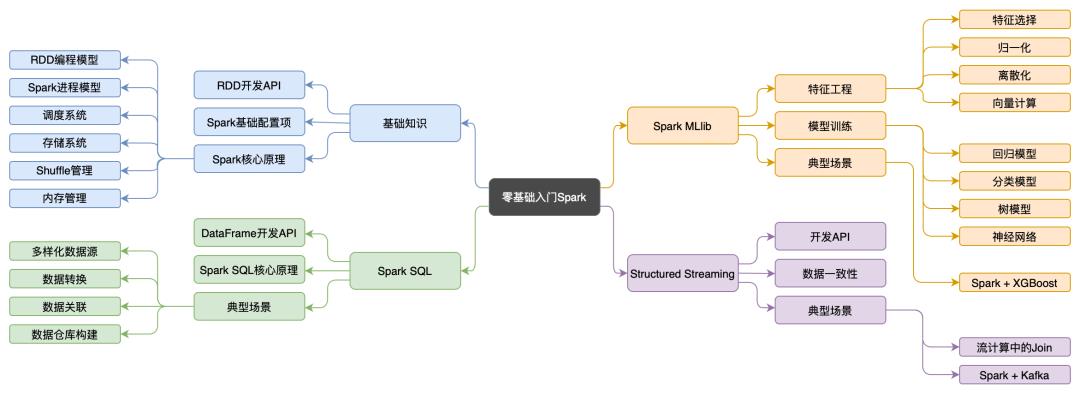
Spark 知识体系全景图
这张图出自吴磊,他是国内第一批搞 Spark 的人,目前是 Freewheel 公司机器学习团队负责人,主导计算广告业务中机器学习的应用、落地与推广,有丰富的大数据开发与调优经验,曾任职于 IBM、联想研究院、新浪微博等大厂。同时他曾在 CSDN、《IBM developerWorks》、《程序员》和 InfoQ 上发布过多篇技术干货,深受好评。
最重要的,磊哥还是 2021 年的 AWS Machine Learning Hero 得主,更是 30 个入选人中唯一一个中国人(这个奖每年由亚马逊公司策划和评选,含金量很高)。
最近,磊哥推出了《零基础入门 Spark》专栏。在专栏里,他专门结合自己的学习和成长经历,讲了如何快速构建 Spark 核心知识体系,以及 从 0 到 1 入门 Spark 的窍门等,还结合了 Spark 三大计算场景案例的实操。值得一提的是,专栏里的代码都是逐句注释的,并且在讲开发实战技巧的模块,都是用故事带入,既形象生动又便于理解记忆,做到真正的从项目入手,带你深入浅出玩转 Spark。
早鸟+口令「spark6666」立省 ¥40,
原价 ¥129,口令仅「前 50 人」有效
吴磊是如何讲解 Spark 专栏的?
磊哥根据自己多年经验总结了一套「入门 Spark 三步法」,独特地将运用 Spark 比作“驾驶赛车”,入门 Spark 就和学开赛车一样,仅需三步,第一步是学基础,掌握 Spark 常用的开发 API 与开发算子,第二步是学工作原理,吃透 Spark 的核心原理,第三步是应对各类场景,玩转 Spark 计算子框架。
为了更好地提升大家的学习效率,他在专栏中设计了基础知识、Spark SQL、Spark MLlib 和 Structured Streaming 这 4 个模块,将这“三步走”完美融入其中。
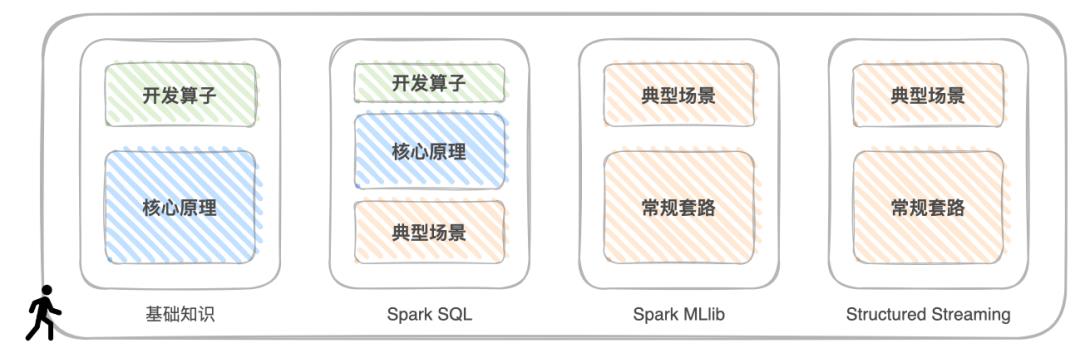
“三步走”与专栏内容安排
第一个模块是基础知识。他会详细讲解包括RDD编程模型、Spark进程模型、调度系统、存储系统、Shuffle管理、内存管理等在内的 Spark 核心原理,并通过一个个有趣的故事,让你像读小说一样轻松诙谐地弄懂 Spark 。
第二个模块是 Spark SQL。他会从一个小项目入手,带你先熟悉开发 API ,再结合案例讲解 Spark SQL 的核心原理与优化过程,再重点介绍Spark SQL与数据分析有关的部分,如数据的转换、清洗、关联、分组、聚合、排序等等。
第三个模块是 Spark 机器学习子框架:Spark MLlib。他从“房价预测”这个项目入手,带你初步了解机器学习中的回归模型、及 Spark MLlib 的基本用法,同时深入学习 Spark MLlib 丰富的特征处理函数,和支持的模型与算法,并构建端到端的机器学习流水线。此外,他还会分享 Spark + XGBoost 集成,是如何帮助开发者应对大多数的回归与分类的问题。
第四个模版是 Spark 的流处理框架 Structured Streaming。他会重点讲解 Structured Streaming 如何同时保证语义与数据的一致性,以及如何应对流处理中的数据关联,并通过 Kafka + Spark 这对“Couple”的系统集成,演示流处理中的典型计算场景。
相信经过这四个部分的“洗礼”,你能很快建立属于自己的 Spark 知识体系,彻底跨进了 Spark 应用开发的大门,成功交付一个满足业务需求、运行稳定、且执行性能良好的分布式应用,并能对大部分的数据应用需求都灵活应对。
说了那么多,看看目录吧:

磊哥的分享,最厉害的点就在于他的技术讲解非常通俗易懂,有种看武侠小说的感觉,即便我们面对的是一个全新的领域,也能在最短的时间内,做到零基础快速入门。
市面上关于 Spark 的课良莠不齐,像磊哥这样能带着你从 0 到 1 构建知识体系,甚至连源码都带逐句注释和讲解的,确实不多了。推荐给想要进入大数据领域或想对大数据基础查缺补漏的朋友,真的很值得一看。
老规矩,我给各位申请了专属优惠口令:
秒杀+专属口令「spark6666」立省 ¥40
原价¥129,口令仅「前 50 名」有效

点击「阅读原文」
输入粉丝专享口令「spark6666」
以 立省 ¥40 入手
以上是关于为什么大厂都在用 Spark?的主要内容,如果未能解决你的问题,请参考以下文章