数组越界会发生什么
Posted 森明帮大于黑虎帮
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数组越界会发生什么相关的知识,希望对你有一定的参考价值。
文章目录
一、数组越界会发生什么
C语言非常重视运行时的效率,所以没有进行数组越界检查,而C++继承了C的效率要求,自然也不做数组越界检查。(检查数据越界,编译器就必须在生成的目标代码中加入额外的代码用于程序运行时检测下标是否越界,这就会导致程序的运行速度下降)。看下面一段代码:
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
using namespace std;
int main()
{
int arr[5] = { 1, 2, 3, 4, 5 };
for (int i = 0; i <= 5; i++)
{
cout << i << " " << endl;
}
cout << arr[6] << endl;
cout << arr[7] << endl;
return 0;
}
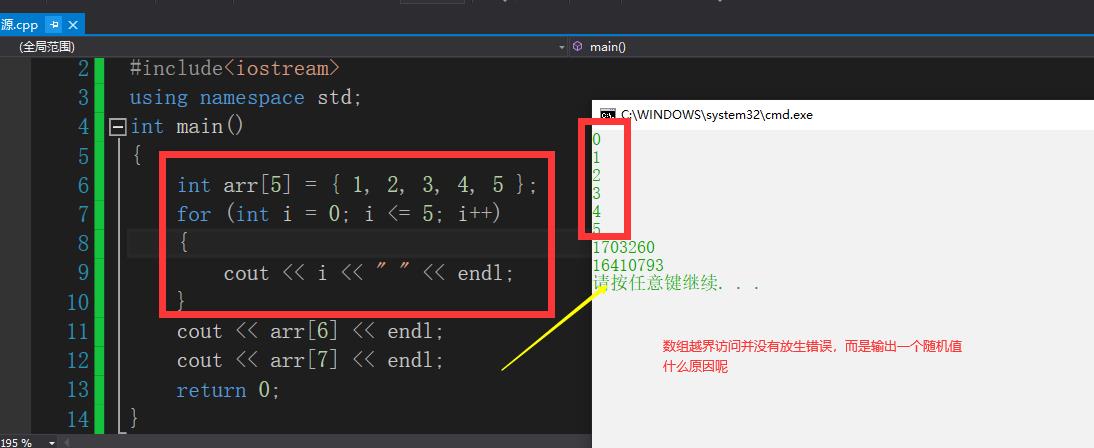
第一行输出结果是arr[0]、arr[1]、arr[2]、arr[3]、arr[4]的值,第二行分别输出它们两个个的地址。数组越界后,会自动接着前面那块内存往后写,这样带来的将会是一系列安全问题。因为界外的内存不确定是否已经存放了东西,如果不凑巧存放着比较重要的数据,那么数组越界后将会把这块内存上的重要数据替换掉,后果可想而知。
对于数组越界问题,不同编译器或许有不同的处理方案,C/C++标准中仅是对界内访问做了明确的规定,而访问界外数据时却没有说怎么处理。总结一下:
- 不检查下标是否越界可以有效提高程序运行的效率,因为如果你检查,那么编译器必须在生成的目标代码中加入额外的代码用于程序运行时检测下标是否越界,这就会导致程序的运行速度下降,所以为了程序的运行效率,C/C++才不检查下标是否越界。
- 不检查下标是为了给程序员更大的空间,也为指针操作带来更多的方便。如果有这个检查的话指针的功能将会大大被削弱,C的数组标识符,里面并没有包含该数组长度的信息,只包含地址信息,所以语言本身无法检查,只能通过编译器检查,而早期的C语言编译器也不对数组越界进行检查,只能由程序员自己检查确保。
- 如果数组下标越界了,那么它会自动接着那块内存往后写。想了一下明白了,以前说不允许数组下标越界,并不是因为界外没有存储空间,而是因为界外的内容是未知的。也就是说如果界外的空间暂时没有被利用,那么我们可以占用那块内存,但是如果之前界外的内存已经存放了东西,那么我们越界过去就会覆盖那块内存,则有可能会导致错误的产生或是程序最终的运行结果出错。
二、 数组越界详解
阅读下面代码,并分析导致其结果的原因(以下分析基于VS环境的调试):
#include <stdio.h>
#include<stdlib.h>
int main()
{
int i = 0;
int arr[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; //拥有10个元素的整型数组
for (i = 0; i <= 12; i++) //循环13次,越界访问
{
arr[i] = 0;
printf("Hello World.\\n");
}
system("pause");
return 0;
}
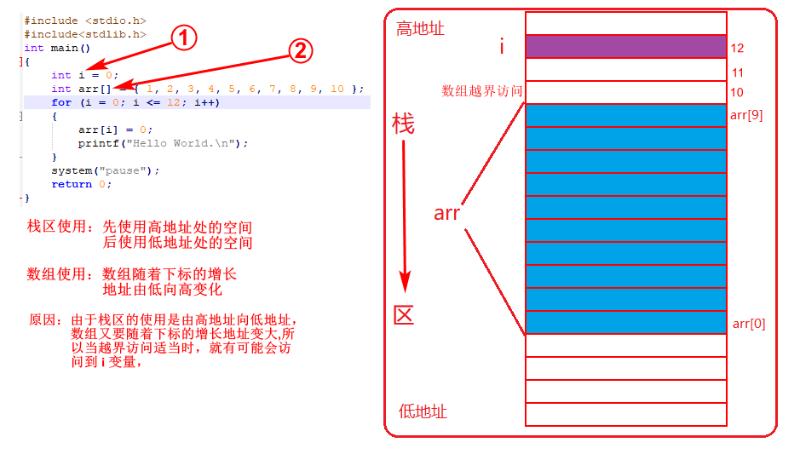
分析:整型数组arr有10个元素,for循环13次,导致数组越界访问。运行程序结果显示如下如图所示,“Hello World”在屏幕循环打印,陷入死循环中。
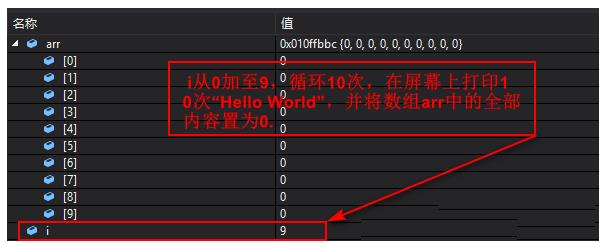
i 从0加至9,循环10次,在屏幕上打印10次“Hello World”,并将数组arr中的全部内容置为0。

i 加至10和11时,越界访问了arr[10]和arr[11],并将arr[10]和arr[11]置为0,当i加至12时将arr[12]也置为0,此时发现 i 也被置为0。
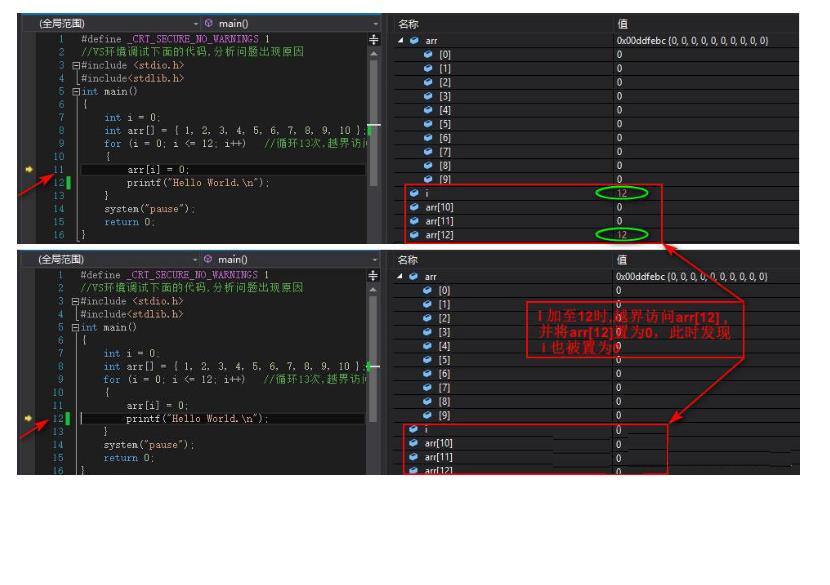
细心的读者就可能会发现,在i加至10、11、12时arr[12]中的内容也随之被改为10、11、12,即图中绿色标记处。那么问题又来了为什么 i 的改变导致arr[12]的改变呢?
观察 i 的地址和arr[12]的地址如下图,i 的地址和arr[12]的地址均是 0x 00 dd fe ec ,这也就解释了为什么 i 的改变会导致arr[12]的改变。
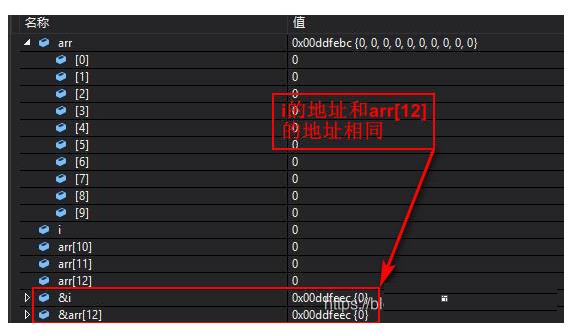
这就能解释清楚为什么数组越界会导致程序陷入死循环:
for循环循环13次(i 从0加至12),数组arr下标0至9,当 i = 10、11、12 时,越界访问数组,因为 i 的地址和arr[12]的地址相同,是同一变量空间,当 i = 12 时,将arr[12] 置为0,也就是将 i 置为0,因此for循环中的条件2永远成立,也就是说 i <=12 恒成立,所以程序陷入死循环中。
上述分析可知 i 的地址和 arr[12] 的地址相同,是同一变量空间,究其根源就得知道计算机中内存是如何分布的。首先的清楚以下几个知识点:
1. 生命周期:变量的作用范围,变量的创建到变量的销毁之间的时间段。
2. 内存:内存储器的存储量,一个数据得占用一块物理空间,逻辑的东西必须有物理的东西来支持。而存储器在一般电脑上是:寄存器-> 缓存->内存->硬盘。
3. 栈区(stack):空间小,系统自动创建销毁。生长方向是由高地址向低地址生长。
4. 堆区(heap):程序员手动开辟,手动释放,程序结束时可能由 OS 回收。使用关键字malloc / new,free / delete对其开辟释放空间,每个人电脑的空间都是有限的。生长方向是由低地址向高地址生长。
5. 静态区( static):内容在总个程序的生命周期内都存在,由编译器在编译的时候分配、存储。
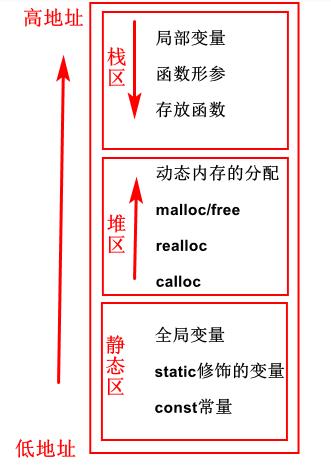
究其根源为什么 i 和 arr[12] 是同一变量空间
局部变量 i 和 arr 在栈区上被使用,因为栈区的生长方向是高地址向低地址生长,所以栈区是先使用高地址处的空间,后使用低地址处的空间,又因为数组随着下标的增长地址由低向高变化,当越界访问适当时,就会访问到变量 i ,执行arr[i]=0;后就会将 i 置为0,导致程序陷入死循环中。栈区的分布如图所示。
修改:for循环中的循环条件为 i<=11 时,不会越界访问到变量 i ,就不会陷入死循环中,系统会提示报错信息。
for (i = 0; i <= 11; i++)
{
arr[i] = 0;
printf(“Hello World.\\n”);
}

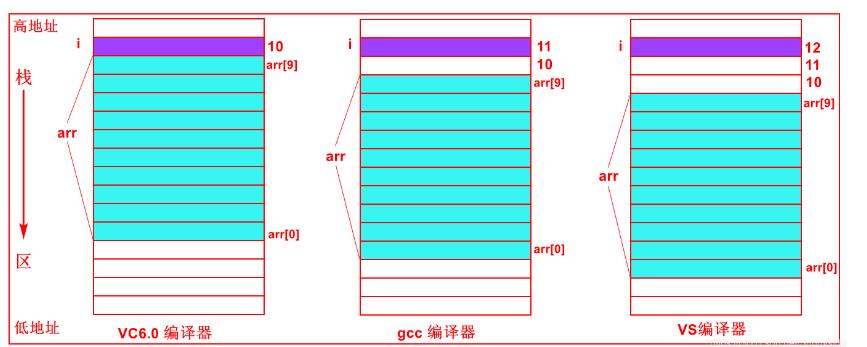
对比:以上是在VS2013上进行调试和编译的,在不同的编译器死循环的位置可能不尽相同。在VC6.0中测试for(i=0;i<=10;i++)程序陷入死循环,在Linux的gcc中测试for(i=0;i<=11;i++)程序陷入死循环。那么在不同编译器下的内存布局如下图所示。
以上是关于数组越界会发生什么的主要内容,如果未能解决你的问题,请参考以下文章