5.剑指Offer --- 优化时间和空间效率
Posted enlyhua
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5.剑指Offer --- 优化时间和空间效率相关的知识,希望对你有一定的参考价值。
第5章 优化时间和空间效率
5.1 面试官谈效率
5.2 时间效率
面试题29:数组中出现次数超过一半的数字
题目:数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。例如输入一个长度为9的数组 {1,2,3,2,2,2,5,4,2}。由于数字2在数组中出现了5次,超过数组
长度的一半,因此输出2.
解法一:基于Partition函数的O(n)算法
数组的特性:数组中有一个数字出现的次数超过了数组长度的一半,如果把这个数组排序,那么排序之后位于数组中间的数字一定就是那个出现次数超过数组长度一半的数字。
也就是统计学上的中位数,即长度为n的数组中第n/2大的数字。我们有成熟的O(n)算法得到数组中任意第k大的数字。
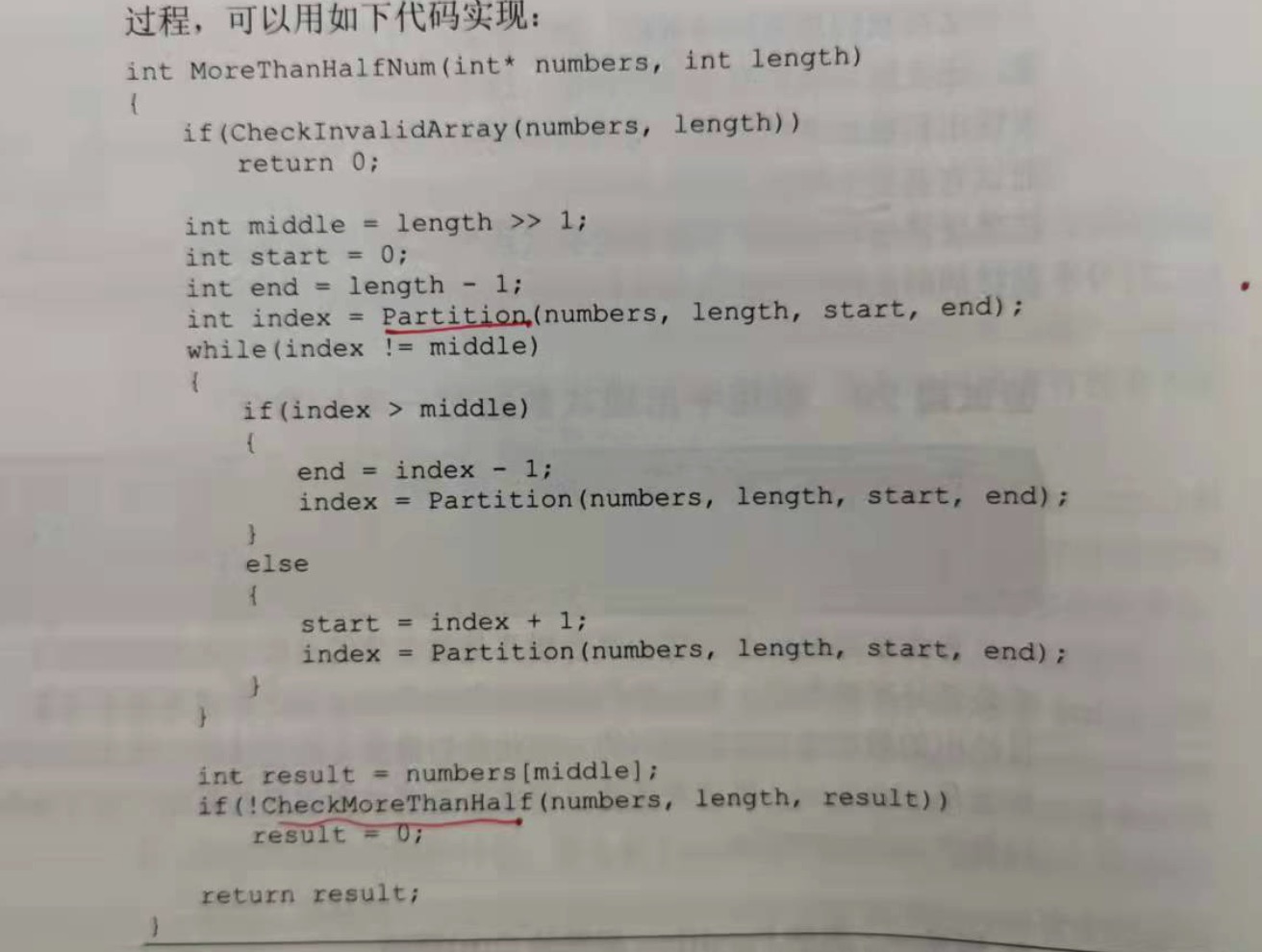
int MoreThanHalfNum(int* numbers, int length)
{
//判断输入的数组是不是无效的
if (CheckInvalidArray(numbers, length)) {
return 0;
}
int middle = length >> 1;
int start = 0;
int end = length - 1;
//Partition 快速排序
int index = Partition(numbers, length, start, end);
while (index != middle) {
if (index > middle) {
end = index - 1;
index = Partition(numbers, length, start, end);
} else {
start = index + 1;
index = Partition(numbers, length, start, end);
}
}
int result = numbers[middle];
//检查出现频率最高的数字,是否超过数组的一半
if (!CheckMoreThanHalf(numbers, length, result)) {
return 0;
}
return result;
}
bool g_bInputInvalid = false;
bool CheckInvalidArray(int* numbers, int length)
{
g_bInputInvalid = false;
if (numbers == null || length <= 0)
g_bInputInvalid = true;
return g_bInputInvalid;
}
bool CheckMoreThanHalf(int* numbers, int length, int number)
{
int times = 0;
for (int i = 0; i < length; i++) {
if (numbers[i] == number)
times++;
}
bool isMoreThanHalf = true;
if (times * 2 <= length) {
g_bInputInvalid = true;
isMoreThanHalf = false;
}
return isMoreThanHalf;
}
int Partition(int data[], int length, int start, int end)
{
if (data == null || length <= 0 || start< 0 || end >= length) {
die('错了');
}
int index = RandomInRange(start,end);
Swap(&data[index], &data[end]);
int small = start - 1;
for (index = start; index < end; index++) {
if (data[index] < data[end]) {
small++;
if (small != index)
Swap(&data[index], &data[small]);
}
}
small++;
Swap(&data[small], &data[end]);
return small;
}
解法二:根据数组特点找出O(n)的算法
接下来我们换个思路。数组中有一个数字出现的次数超过数组长度的一半,也就是说它出现的次数比其他所有的数字出现次数的和还要多。因此我们可以考虑在遍历数组的时候
保存两个值:一个是数组中的数字,一个是次数。当我们遍历到下一个数字的时候,如果下一个数字和我们之前保存的数组相同,则次数加1;如果下一个数字和我们之前保存的数字
不同,则次数减1。如果次数为0,我们需要保存下一个数字,并把次数设置为1.由于我们要找的数字出现的次数比其他所有的数字出现的次数之和还要多,那么要找的数字肯定是
最后一次把次数设置为1时对应的数字。
int MoreThanHalfNum(int* numbers, int length)
{
if (CheckInvalidArray(numbers, length))
return 0;
int result = numbers[0];
int times = 1;
for (int i = 1; i < length; i++) {
if (times == 0) {
result = numbers[i];
times = 1;
} else if (numbers[i] == result) {
times++;
} else {
time--;
}
}
if (!CheckMoreThanHalf(numbers, length, result))
result = 0;
return result;
}
面试题30:最小的k个数
题目:输入n个整数,找出其中最小的k个数。例如输入 4,5,1,6,2,7,3,8 这8个数字,则最小的4个数字是1,2,3,4.
这道题目最简单的思路莫过于把输入的n个整数排序,排序之后位于最前面的k个数字就是最小的k个数。这种思路的时间复杂度是O(nlogn),面试官会提醒我们有更快的算法。
解法一:O(n)的算法,只有当我们可以修改输入的数组时可以用。
我们同样可以基于 Partition 函数来解决这个问题。如果基于数组的第k个数字来调整,使得比第k个数字小的所有数字都位于数组的左边,比第k个数字大的所有数字都
位于数组的右边。这样调整之后,位于数组的左边的k个数字就是小于k个数字(这k个数字不一定是排序的)。
void GetLeastNumbers(int* input, int n, int* output, int k)
{
if (input == null || output == null || k > n || n <= 0 || k <= 0)
return;
int start = 0;
int end = n - 1;
int index = Partition(input, n, start, end);
while (index != k - 1) {
if (index > k - 1) {
end = index - 1;
index = Partition(input, n, start, end);
} else {
start = index + 1;
index = Partition(input, n, start, end)
}
}
for (int i = 0; i < k; i++) {
output[i] = input[i];
}
}
缺点:需要修改输入的数组。
解法二:O(nlogk)的算法,特别适合处理海量数据
我们可以先创建一个大小为k的数据容器来存储最小的k个数字,接下来我们每次从输入的n个整数读入一个数。如果容器中已有的数字少于k个,则直接把这次读入的整数放入
容器中;如果容器中已有k个数字,也就是容器满了,此时我们不能再插入新的数字而只能替换已有的数字。找出这k个数字最大的值,然后拿这次插入的新的数字和最大的值比较,
如果待插入的值比当前已有的最大值小,则用这个数字替换当前已有的最大值;如果待插入的值比当前已有的最大值还要大,那么这个数不可能是最小的k个整数之一,可以抛弃。
因此,当容器满了,我们需要做三件事:一是在k个整数中找到最大数;而是有可能在这个容器中删除最大数;三是有可能要插入一个新的数字。
我们可以选择不同的二叉树实现这个容器,由于每次都需要找到k个整数中最大的数字,很容易联想到最大堆。在最大堆中,根结点的值总是大于它的子树中任意结点的值。
于是我们每次可以在O(1)得到已有的k个数字的最大值,但需要O(logk)时间完成删除及插入操作。
typedef multiset<int, greatere<int>> intSet;
typedef multiset<int, greatere<int>>::iterator setIterator;
void GetLeastNumbers(const vector<int>& data, intSet& leastNumbers, int k)
{
leastNumbers.clear();
if (k < 1 || data.size() < k)
return;
vector<int>::const_iterator iter = data.begin();
for ( ; iter != data.end(); iter++) {
if ( (leastNumbers.size()) < k ) {
leastNumbers.insert(*iter);
} else {
setIterator iterGreatest = leastNumbers.begin();
if (*iter < *(leastNumbers.begin())) {
leastNumbers.erase(iterGreatest);
leastNumbers.insert(*iter);
}
}
}
}
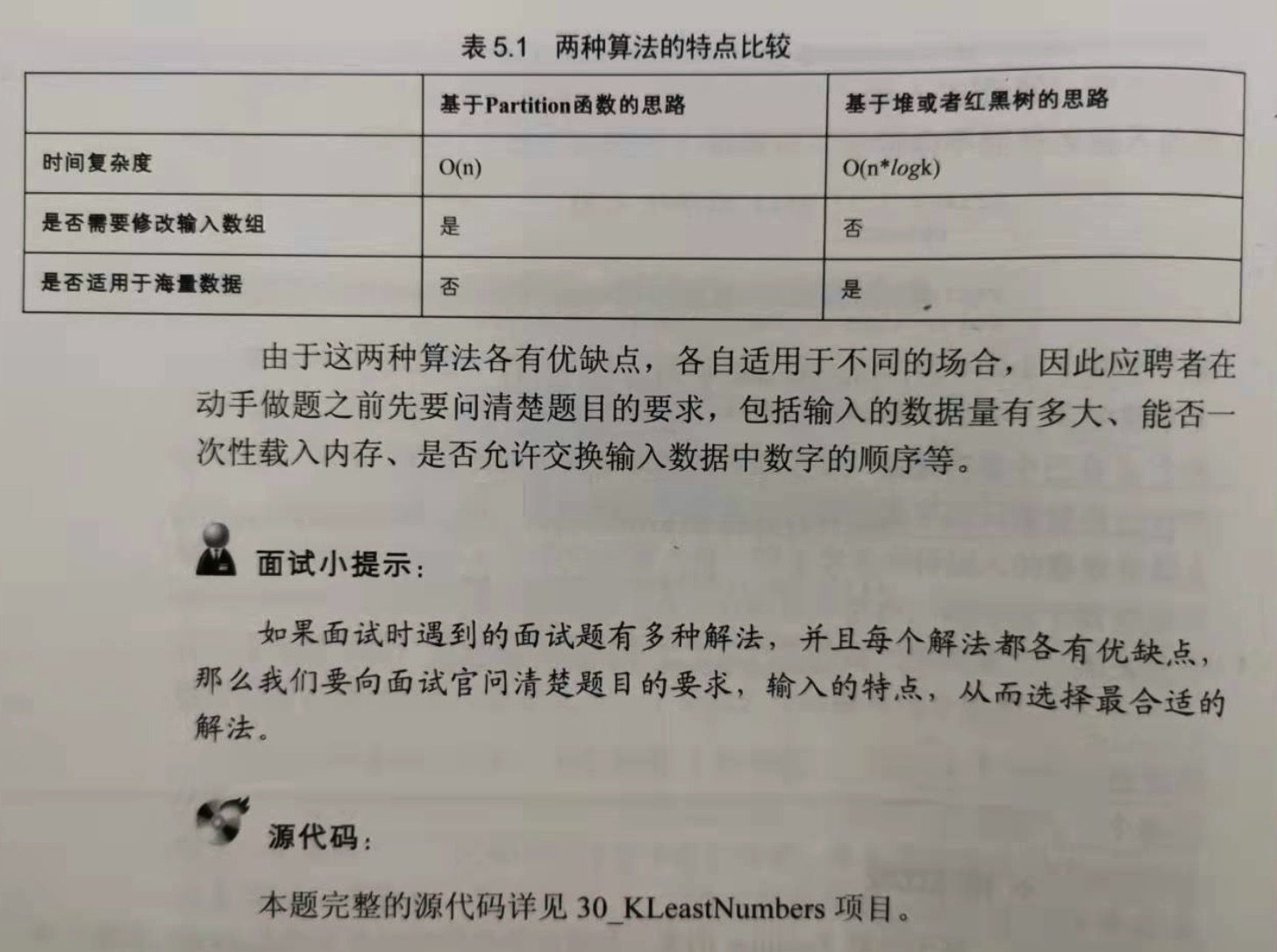
解法比较:
基于函数 Partition 的第一种方法的平均时间复杂度是O(n),比第二种思路要快,但需要修改输入的数组。
第二种解法慢一点,但它有两个明显的好处:1.是没有修改输入的数字(data),我们每次只是从data中读入数字,所有的写操作都是在容器 leastNumbers中进行的。
2.是该算法特别适合海量数据的输入。假设题目的要求是从海量的数据中找出最小的k个数字,由于内存的大小是有限的,又不可能把这些海量的数据一次性全部载入内存。这个时候
我们可以从辅助存储空间(比如硬盘)中每次读入一个数字,根据GetLeastNumbers 的方式判断是不是需要放入容器 leastNumbers即可。
面试题31:连续子数组的最大和
题目:输入一个整形数组,数组里面有正数也有负数。数组中的一个或者连续的多个数组组成一个子数组。求所有的子数组的和的最大值,要求时间复杂度为O(n)。
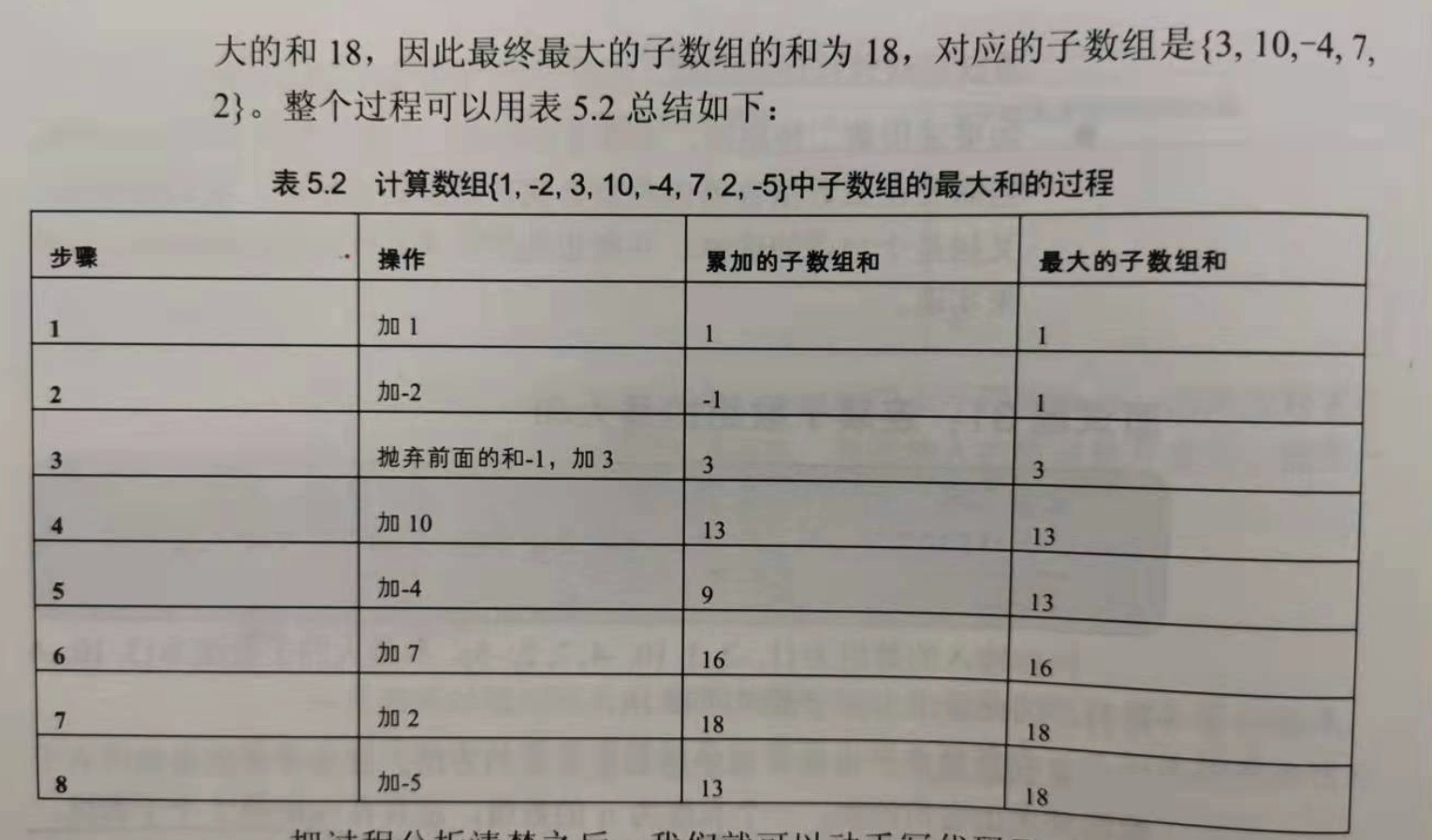
例如输入的数组为 {1,-2,3,10,-4,7,2,-5},和最大的子数组为{3,10,-4,7,2},因此输入该子数组的和为18.
最直观的方法,即枚举出数组的所有子数组并求出它们的和。一个长度为n的数组,总共有 n(n+1)/2 个子数组。计算出所有子数组的和,最快也需要O(n^2)的时间。
解法一:举例分析数组的规律
bool g_InvalidInput = false;
int FindGreatestSumOfSubArray(int *pData, int nLength)
{
if ( (pData == null ) || (nLength <= 0) ) {
g_InvalidInput = true;
return 0;
}
g_InvalidInput = false;
int nCurSum = 0;
int nGreatestSum = 0x80000000;
for (int i = 0; i < nLength; i++) {
if (nCurSum <= 0) {
nCurSum = pData[i];
} else {
nCurSum += pData[i];
}
if (nCurSum > nGreatestSum) {
nGreatestSum = nCurSum;
}
return nGreatestSum;
}
}
注意需要考虑无效的输入,还有如果函数返回0,那么我们怎么区分子数组的和是0,还是无效输入。所以需要用个全局变量来定义错误。
解法二:应用动态规划法
面试题32:从1到n整数中1出现的次数
题目:输入一个整数n,求从1到n这n个整数的十进制表示中1出现的次数。例如输入12,从1到12这些整数中包含1的数字有1,10,11和12,1一共出现了5次。
解法一:不考虑时间效率的解法,靠它拿offer有点难
思路:累加1到n中每个数字出现1的次数。可以每次对10求余数判断整数的个数位是不是1.
int NumberOf1Between1AndN(unsigned int n)
{
int number = 0;
for (unsigned int i = 1; i <= n; i++) {
number += NumberOf1(i);
}
return number;
}
int NumberOf1(unsigned int n)
{
int number = 0;
while (n) {
if (n & 10 == 1) {
number++;
}
n = n / 10;
}
return number;
}
缺点:
上述思路中,我们需要对每个数字做除法和求余运算。如果输入的数字n,n有O(logN)位,我们需要判断每一位是不是1,那么它的时间复杂度是O(n*logn)。当n比较大的
时候,运算效率不高。
解法二:从数字规律着手明显提高时间效率的解法,让面试官耳目一新
int NumberOf1Between1AndN(int n)
{
if (n <= 0) {
return 0;
}
char strN[50];
sprintf(strN, "%d", n);
return NumberOf1(strN);
}
int NumberOf1(const cahr* strN)
{
if (!strN || *strN < '0' || *strN > '9' || *strN == '\\0')
return 0;
int first = *strN - '0';
unsigned int length = static_cast<unsigned int>(strlen(strN));
if (length == 1 && first == 0) {
return 0;
}
if (length == 1 && first > 0) {
return 1;
}
//假设strN是 "21345"
//numFirstDigit 是数字 10000~19999 的第一个位中的数目
int numFirstDigit = 0;
if (first > 1) {
numFirstDigit = PowerBase10(length - 1);
} else if (first == 1) {
//atoi,字符串转换为整数
numFirstDigit = atoi(strN + 1) + 1;
}
//numOtherDigits 是 1346~21345 除了第一位之外的数位中的数目
int numOtherDigits = first * (length - 1) * PowerBase10(length - 2);
int numRecursive = NumberOf1(strN + 1);
return numFirstDigit + numOtherDigits + numRecursive;
}
int PowerBase10(unsigned int n)
{
int result = 1;
for (unsigned int i = 0; i < n; i++) {
result *= 10;
}
return result;
}
这种思路是每次去掉最高位做递归,递归的次数和位数相同。一个数组n有 O(logn)位,因此这种思路的时间复杂度是O(logn)。
面试题33:把数组排成最小的数
题目:输入一个正整数数组,把数组里面所有数字拼接起来排成一个数,打印能拼接处的所有数字中最小的一个。例如输入的数组{3,32,321},则打印出这3个数字能排成的
最小的数字 321323 。
分析:
这个题目最直接的做法是先求出这个数组中所有数字的全排列,然后把每个排列拼接起来,最后求出拼接起来的数组的最小值。n个数字的总共同有n!个排列。
这道题其实是希望我们找到一个排序规则,数组根据这个规则排序之后能排成一个最小的数字。要确定排序规则,就要比较两个数字,也就是给出两个数字m和n,我们需要判断
m和n哪个应该排在前面,而不是比较这2个数字的值哪个大。
根据题目要求,两个数字m和n能拼接成mn和nm。如果mn<nm,那么我们应该打印出mn,也就是m应该排在n前面,我们定义此时m小于n;反之,n小于m。接下来考虑如何拼接
数字,即给出数字m和n,怎么得到数字mn和nm并比较大小。直接用数值计算不难办到,但需要考虑一个潜在的问题,m和n都在int范围内,但把它们拼接起来的数字mn和nm用int
表示可能溢出了,这还是一个潜在的大数问题。
一个非常直观的解决大数问题的方法就是把数字转换成字符串。另外,由于m和n拼接起来得到mn和nm,它们的位数肯定是相同的,因此比较它们的大小只需要按照字符串大小
的比较规则就可以了。
const int g_MaxNumberLength = 0;
char* g_StrCombine1 = new char[g_MaxNumberLength * 2 + 1];
char* g_StrCombine2 = new char[g_MaxNumberLength * 2 + 1];
void PrintMinNumber(int* numbers, int length)
{
if (numbers == null || length <= 0)
return;
char** strNumbers = (char**)(new int[length]);
//先把数组中的整数转换成字符串
for (int i = 0; i < length; i++) {
strNumbers[i] = new char[g_MaxNumberLength + 1];
sprintf(strNumbers[i], "%d", numbers[i]);
}
//在函数 compare 中定义比较规则,并根据该规则用库函数 qsort 排序。
qsort(strNumbers, length, sizeof(char*), compare);
//最后把排好序的数组中的数字依次打印出来,就是该数组中数字能拼接出来的最小数字。时间复杂度是 O(nlogn)
for (int i = 0; i < length; i++) {
printf("%s", strNumbers[i]);
}
printf("\\n");
for (int i = 0; i < length; i++) {
delete[] strNumbers[i];
}
delete[] strNumbers;
}
int compare(const void* strNumber1, const void* strNumber2)
{
strcpy(g_StrCombine1, *(const char**)strNumber1);
strcat(g_StrCombine1, *(const char**)strNumber2);
strcpy(g_StrCombine2, *(const char**)strNumber2);
strcat(g_StrCombine1, *(const char**)strNumber1);
return strcmp(g_StrCombine1, g_StrCombine2);
}
5.3 时间效率与空间效率的平衡
面试题34:丑数
题目:我们把只包含因子2,3和5的数叫做丑数。求按从小到大的顺序的第1500个丑数。例如6,8都是丑数,但14不是,因为它包含因子7.习惯上我们把1当做第一个丑数。
解法一:逐个判断每个整数是不是丑数的解法,直观订但不够高效
所谓一个数m是另外一个数n的因子,是指n能被m整除,也就是 n%m==0。根据丑数的定义,丑数只能被2,3,5整除。也就是说如果一个数能被2整除,我们把它连续
除以2;如果能被3整除,就连续除以3;如果能被5整除,就除以连续5。如果最后我们得到的是1,那么这个数就是丑数,否则不是。
bool IsUgly(int number)
{
while (number % 2 == 0)
number /= 2;
while (number % 3 == 0)
number /= 3;
while (number % 5 == 0)
number /= 5;
return (number == 1) ? true : false;
}
int GetUglyNumber(int index)
{
if (index <= 0)
return 0;
int number = 0;
int uglyFound = 0;
while (uglyFound < index) {
++number;
if (IsUgly(number)) {
++uglyFound;
}
}
return number;
}
解法二:创建数组保存已经找到的丑数,用空间换时间的解法
前面的算法之所以低效,很大程度上是因为不管一个数是不是丑数,我们都要对它进行计算。接下来我们试着找到一种只要计算丑数的方法,而不在非丑数的整数
上花费太多时间。根据丑数的定义,丑数应该是另外一个丑数乘以2,3,5的结果(1除外)。因此我们可以创建一个数组,里面的数字是排序好的丑数,每一个丑数都是
前面的丑数乘以2,3或5得到的。
这种思路的关键在于怎样确保里面的丑数是排序好的。
int GetUglyNumber_Solution2(int index)
{
if (index <= 0)
return 0;
int *pUglyNumbers = new int[index];
pUglyNumbers[0] = 1;
int nextUglyIndex = 1;
int* pMultiply2 = pUglyNumbers;
int* pMultiply3 = pUglyNumbers;
int* pMultiply5 = pUglyNumbers;
while (nextUglyIndex < index) {
int min = Min(*pMultiply2 * 2, *pMultiply3 * 3, *pMultiply5 * 5);
pUglyNumbers[nextUglyIndex] = min;
while (*pMultiply2 * 2 <= pUglyNumbers[nextUglyIndex]);
++pMultiply2;
while (*pMultiply3 * 3 <= pUglyNumbers[nextUglyIndex]);
++pMultiply3;
while (*pMultiply5 * 5 <= pUglyNumbers[nextUglyIndex]);
++pMultiply5;
++nextUglyIndex;
}
int ugly = pUglyNumbers[nextUglyIndex - 1];
delete[] pUglyNumbers;
return ugly;
}
int Min(int number1, int number2, int number3)
{
int min = (number1 < number2) ? number1 : number2;
min = (min < number3) ? min : number3;
return min;
}
面试题35:第一个只出现一次的字符
题目:在字符串中找出第一个只出现一次的字符。如输入"abaccdeff",则输出'b'。
如果有n个字符,每个字符可能与后面的O(n)个字符相比较,因此这种思路的时间复杂度是O(n^2)。
char FirstNotRepeatingChar(char* pString)
{
if (pString == null)
return '\\0';
const int tableSize = 256;
unsigned int hashTable[tableSize];
//初始化hashTable
for (unsigned int i = 0; i < tableSize; i++) {
hashTable[i] = 0;
}
//将值填入
char* pHashKey = pString;
while ( *(pHashKey) != '\\0' ) {
hashTable[ *(pHashKey++) ]++;
}
//找出次数等于1的
pHashKey = pString;
while (*pHashKey != '\\0') {
if (hashTable[*pHashKey] == 1) {
return *pHashKey;
}
pHashKey++;
}
return '\\0';
}
相关题目:
1.定义一个函数,输入两个字符串,从第一个字符串中删除在第二个字符串中出现过的所有字符。例如从第一个字符串"We are students."中删除在第二个
字符串"aeiou"中出现过的字符得到的结果是"W r Stdnts."。为了解决这个问题,我们可以创建一个用数组实现的简单哈希表来存储第二个字符串。这样我们从头到尾
扫描第一个字符串的每一个字符时,用O(1)时间就能判断出该字符是不是在第二个字符中。如果第一个字符串的长度是n,那么总的时间复杂度是O(n)。
2.定义一个函数,删除字符串中所有重复出现的字符。例如输入"google",删除重复的字符之后的结果是"gole"。这个题目和上面的问题比较相似,我们可以创建
一个用布尔型数组实现的简单的哈希表。数组中的元素的意义是其下标看做 ASCII 码后对应的字母在字符串中是否已经出现。我们先把数组中所有的元素都设置false。
以"google"为例,当扫描到第一个g时,g的ASCII码是103,那么我们把数组中下标为103的元素设置true。当扫描到第二个g时,我们发现数组中下标为103的元素的值
是true,就知道g已经在前面出现过了。也就是说,我们用O(1)时间就能判断每个字符在前面是否出现过。如果字符串的长度为n,那么总的时间复杂度是O(n)。
3.在英语中,如果两个单词出现的字母相同,并且每个字母出现的次数也相同,那么这个两个单词互为变位词。例如,silent与listen,evil与live等互为
变位词。我们可以创建一个用数组实现的简单哈希表,用来统计字符串中每个字符出现的次数。当扫描第一个字符串的每个字符时,为哈希表对应的项的值增加1.
接下来扫描第二个字符串,扫到的每一个字符串,为哈希表对应的项减去1。如果扫完第二个字符串后,哈希表中的值都是0,那么这两个字符串就互为变位词。
举一反三:
如果需要判断多个字符是不是在某个字符串里出现或者统计多个字符在某个字符串中出现的次数,我们可以考虑基于数组创建一个简单的哈希表。这样可以用很小的
空间消耗来换取时间效率的提升。
面试题36:数组中的逆序对
题目:在数组中的两个数字如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
例如,在数组{7,5,6,4}中,一共存在5个逆序对,分别是 (7,6),(7,5),(7,4),(6,4),(5,4)。
解法一:顺序扫码数组,用两次循环,时间复杂度为O(n^2)。
解法二:归并排序
总结出逆序对统计的过程:先把数组分隔成子数组,先统计出子数组内部的逆序对的数目,然后再统计出两个相邻子数组之间的逆序对的数目。在统计逆序对的过程
中,还需要对数组进行排序。如果对排序算法很熟悉,就不难发现排序的过程实际上就是归并排序。基于归并排序,写出如下代码。
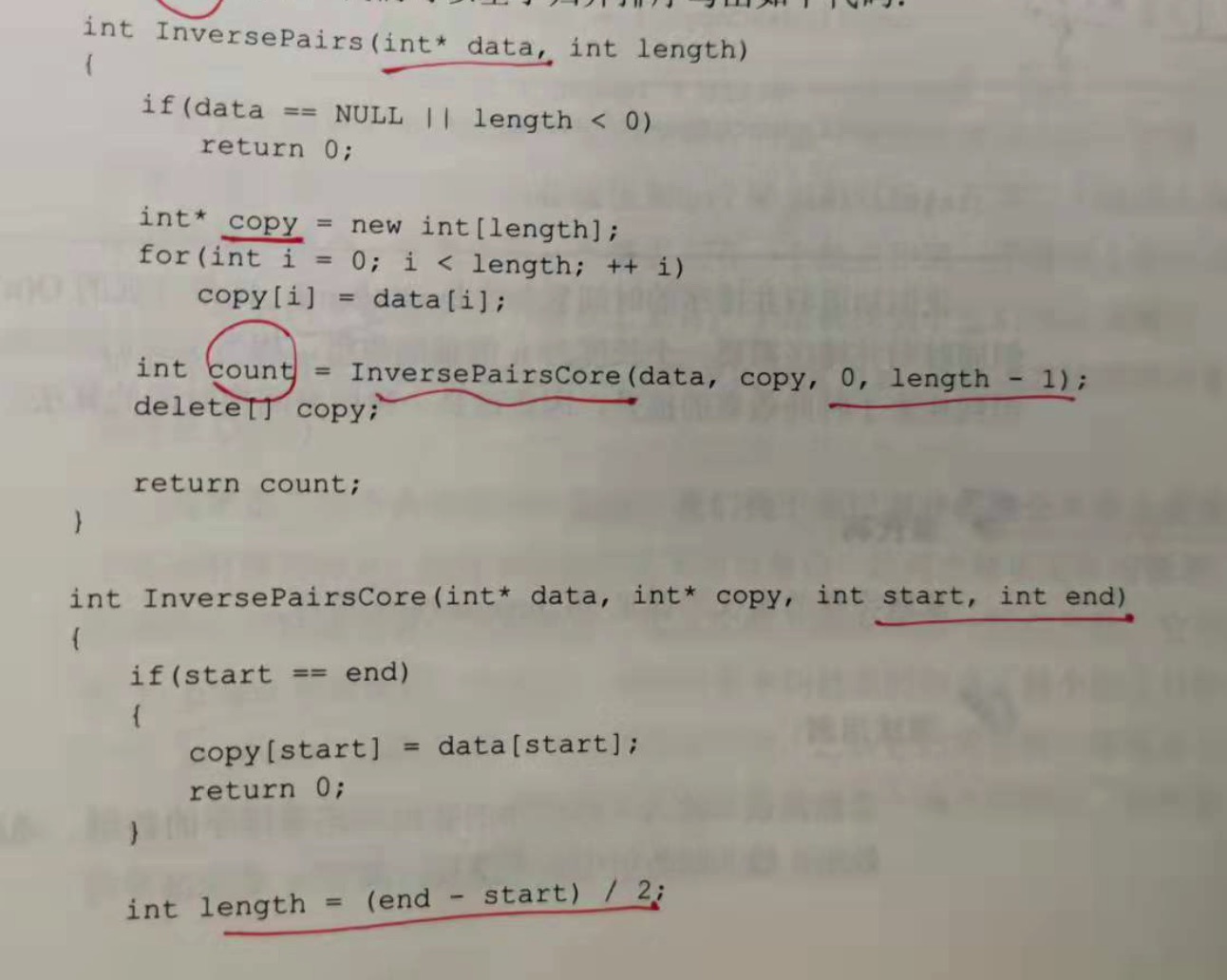
int InverseParis(int* data, int length)
{
if (data == null || length < 0)
return 0;
int* copy = new int[length];
for (int i = 0; i < length; i++) {
copy[i] = data[i];
}
int count = InversePairsCore(data, copy, 0, length - 1);
delete[] copy;
return count;
}
int InversePairsCore(int* data, int* copy, int start, int end)
{
if (start == end) {
copy[start] = data[start];
return 0;
}
int length = (end - start) / 2;
int left = InversePairsCore(copy, data, start, start + length);
int right = InversePairsCore(copy, data, start + length + 1, end);
//i初始化为前半段最后一个数字的下标
int i = start + length;
//j初始化为后半段最后一个数字的下标
int j = end;
int indexCopy = end;
int count = 0;
while (i >= start && j >= start + length + 1) {
//p1 > p2,有逆序对
if (data[i] > data[j]) {
copy[indexCopy--] = data[i--];
count += j - start - length;
} else {
copy[indexCopy--] = data[j--];
}
}
for ( ; i >= start; i--) {
copy[indexCopy--] = data[i];
}
for ( ; j >= start + length + 1; j--) {
copy[indexCopy--] = data[j];
}
return left + right + count;
}
我们知道归并排序的时间复杂度是O(nlogn),比最直观的O(n^2)要快,但同时需要消耗一个长度为n的辅助数组。
面试题37:两个链表的第一个公共结点
题目:输入两个链表,找出它们的第一个公共结点。链表节点的定义如下:
struct ListNode {
int m_nKey;
ListNode* m_pNext;
};
思路1:在第一个链表上顺序遍历每个结点,每遍历到一个结点的时候,在第二个链表上顺序遍历每一个结点。如果第二个链表上有一个结点和第一个链表上的结点一样,
说明两个链表在这个结点上重合。于是找到了公共结点。如果第一个链表的长度为m,第二个链表的长度为n,时间复杂度为O(mn)。
思路2:用两个辅助栈,分别把两个链表放入栈里,这样两个链表的尾结点就位于两个栈的栈顶,接下来比较两个栈顶是否相同。如果相同,则接着比下一个,直到找到
最后一个相同的结点。
思路3:当两个链表的长度不相同的时候,如果我们从头开始遍历到达尾结点的时间就不一致。解决的方法是,首先遍历两个链表的长度,就知道哪个链表长,在较长的
链表上先走若干步,接着再同时遍历,找到的一个相同结点就是它们的第一个公共的结点。
ListNode* FindFirstCommonNode(ListNode* pHead1, ListNode* pHead2)
{
//得到两个链表的长度
unsigned int nLength1 = GetListLength(pHead1);
unsigned int nLength2 = GetListLength(pHead2);
int nLengthDif = nLength1 - nLength2;
ListNode* pListHeadLong = pHead1;
ListNode* pListHeadShort = pHead2;
if (nLength2 > nLength1) {
pListHeadLong = pHead2;
pListHeadShort = pHead1;
nLengthDif = nLength2 - nLength1;
}
//先在长链表上走几步,再同时在两个链表上遍历
for (int i = 0; i < nLengthDif; i++) {
pListHeadLong = pListHeadLong->m_pNext;
}
while ( (pListHeadLong != null) && (pListHeadShort != null) && (pListHeadLong != pListHeadShort) ) {
pListHeadLong = pListHeadLong->m_pNext;
pListHeadShort = pListHeadShort->m_pNext;
}
//得到第一个公共节点
ListNode* pFirstCommonNode = pListHeadLong;
return pFirstCommonNode;
}
unsigned int GetListLength(ListNode* pHead)
{
unsigned int nLength = 0;
ListNode* pNode = pHead;
while (pNode != null) {
++nLength;
pNode = pNode->m_pNext;
}
return nLength;
}





































































以上是关于5.剑指Offer --- 优化时间和空间效率的主要内容,如果未能解决你的问题,请参考以下文章