理解MySql索引与优化
Posted 单片机菜鸟哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了理解MySql索引与优化相关的知识,希望对你有一定的参考价值。
1、索引是什么?
简单理解为:
用来
加快数据访问
1.1 mysql数据存储在什么地方?
磁盘
延伸思考一下,为什么不存在内存中?
- 断电保存
- 数据量
- 内存消耗
1.2 查询数据比较慢,一般情况下卡在哪里?
IO
这里延伸出来的问题就是:要想查询快,想办法提高IO查询效率。
- 减少IO次数
- 减少IO量
1.3 去磁盘读取数据,用多少读多少?
磁盘预读
这里涉及到:
- 局部性原理:
数据和程序都有聚集成群的倾向,同时之前被访问到的数据很有可能再次被查询。(时间局部性、空间局部性) - 磁盘预读
内存跟磁盘发生数据交互的时候,一般情况下有一个最小逻辑单元。称之为页(page)。页一般由操作系统决定多大,一般是4K或者8K。而我们在进行数据交互的时候,可以取页的整数倍来进行读取。innodb存储引擎每次读取数据,读取16K。
1.4 索引存储在哪里?
磁盘
磁盘,查询数据的时候会优先将索引加载到内存中。
1.5 索引在存储的时候需要什么信息?一般需要考虑存储什么字段值?
唯一标识(Key),实际数据行中存储的值。
文件地址(数据记录)
offset:偏移量,在文件中的哪个位置
1.6 1.5这种格式的数据要使用什么样的数据结构进行存储?
抽象为K-V,key + value组合
符合的数据结构:
- 哈希表
- 树(二叉树、红黑树、AVL树、B树、B+树)
1.7 mysql的索引并不是按照1.5存储,用了B+树。
2、索引结构
2.1 哈希索引
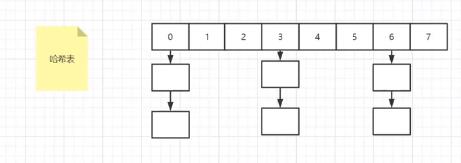
2.1.1 缺点
2.1.1.1 哈希冲突
- 造成
数据散列不均匀,会产生大量线性查询,比较浪费时间
2.1.1.2 不支持范围查询
- 当进行范围查询的时候,必须挨个遍历
2.1.1.3 内存空间高
- 对于内存空间的要求比较高,加载全部数据
2.1.2 优点
2.1.2.1 等值查询非常快
- 通过hash值直接得到数组位置直接定位
2.1.3 mysql有hash索引?
- memory存储引擎使用hash索引
- innodb支持自适应hash
2.2 BST二分查找树
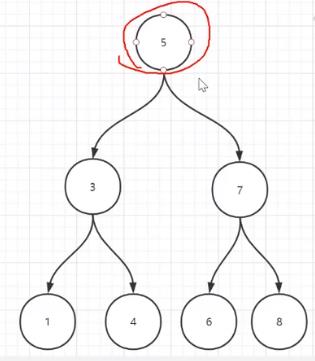
- Binary Search Tree
- 插入数据的时候必须有序,左子树必须小于根节点,右子树必须保证大于根节点
- 使用二分查找提高查询效率
2.2.1 缺点
2.2.1.1 递增数据,退化为链表
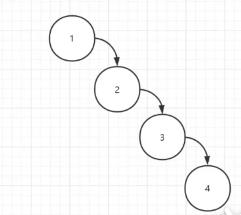
解决思路:继续进化,让树保持平衡(经过左旋或者右旋让树平衡起来,AVL平衡二叉树)
2.3 AVL平衡二叉树
最短子树和最长子树高度差不能超过1
为了保证平衡,在插入数据的时候必须进行旋转。通过插入性能的损失来换取查询性能的提升。
比较适用于写少读多的场景。
2.3.1 缺点
2.3.1.1 不适合写多读少场景
但是如何读写差不多或者写比读多?
解决思路:继续进化,红黑树
2.4 红黑树
最长子树只要不超过最短子树的两倍即可- 查询性能和插入性能近似取得
平衡
2.4.1 缺点
2.4.1.1 随着数据插入,树深度变深,IO次数越多,影响效率
原因:
- 每个节点只有两个分支
解决思路:继续进化,二叉树变成多叉树,把原来有序二叉树变成有序多叉树,进化为B树
2.5 B树
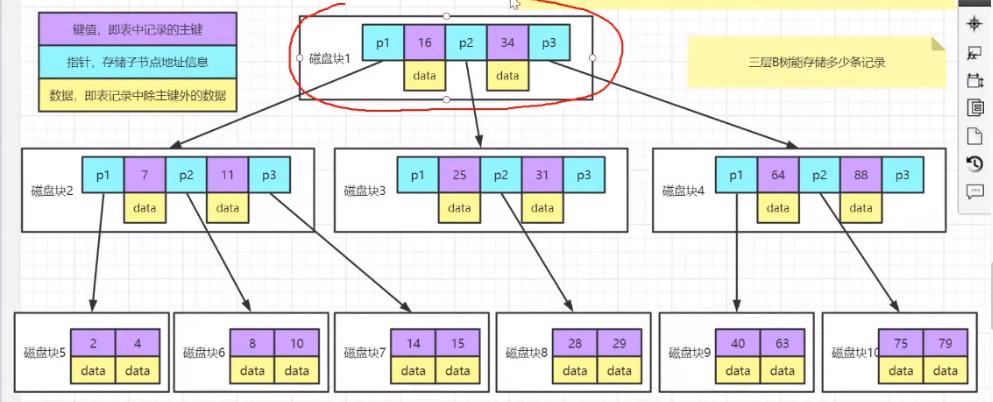
- B树
每个节点都存储数据,所有节点组成这棵树,并且叶子节点指针为null; - B树中叶节点包含的关键字和其他节点包含的关键字是
不重复的。
2.5.1 优点
- B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此
访问也更迅速。(可能访问一下就能得到我要的节点数据)
2.5.2 缺点
- 每个非叶子节点都存储数据,意味着每一层能存储的数据量就变少了。
三层B树,假设一个节点的内存空间大小是16KB,一个数据占用了1KB。那么三层就是 16 * 16 * 16 = 4096,对于数据库来说这个数据量太小了。
- 需要遍历整条树才能获取到所有数据。
解决思路:
- 继续加多一层,但是IO量变大了
- 非叶子节点不存储数据data,那么继续进化,B树变成B+树
- 加多一条链表支持范围查询
2.6 B+树
- B+树
只有叶子节点存储数据(B+数中有两个头指针:一个指向根节点,另一个指向关键字最小的叶节点),叶子节点包含了这棵树的所有数据,所有的叶子结点使用链表相连,便于区间查找和遍历,所有非叶节点起到索引作用。 - B+树的索引项只包含对应子树的最大关键字和指向该子树的指针,
不含有该关键字对应记录的存储地址。 - B+树中查找,无论查找是否成功,每次都是一条从根节点到叶节点的路径。
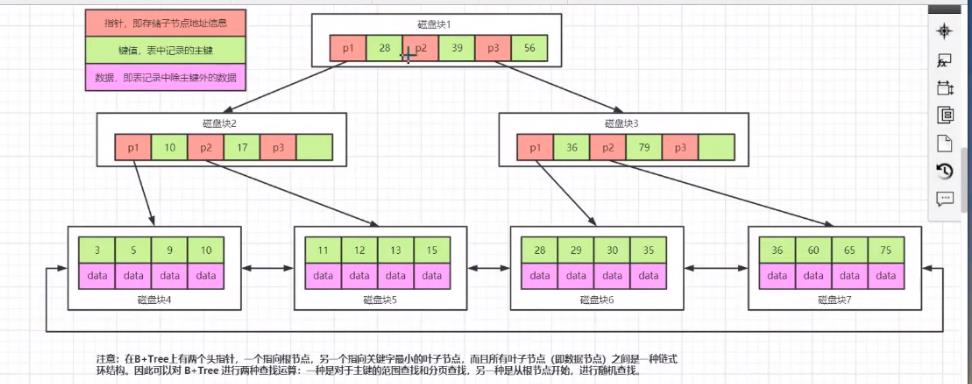
2.6.1 优点
- 存储数据量大
三层B+树,假设一个节点的内存空间大小是16KB,一个数据占用了10B。那么三层大概就是 1600 * 1600 * 1600 = 4096000000,4千万数据。。。。
(一般情况下mysql B+树 3-4层。超过4层需要考虑分库分表)
延伸思考点:
- 索引系统中,每个数据占用数据量越小越好,那么索引字段用int还是vachar?
key 值占用存储空间尽量少,取决于int或者vachar的长度。不过一般情况下都选择int。
- 叶子节点组成
双向链表,支持范围查询
3、索引知识点
3.1 聚簇索引与非聚簇索引
是否是聚簇索引取决于数据与索引是否放在一起
3.1.1 innodb只能有一个聚簇索引,多个非聚簇索引
向innodb插入数据的时候,必须包含一个索引key值。这个索引key值可以是
主键。如果没有主键,那么就是唯一键。如果没有唯一键,那么就是一个自生成的6字节的Rowid。
延伸思考点
- 为什么只有一个聚簇索引?
数据冗余 - 可以有很多非聚簇索引,那么data存什么?
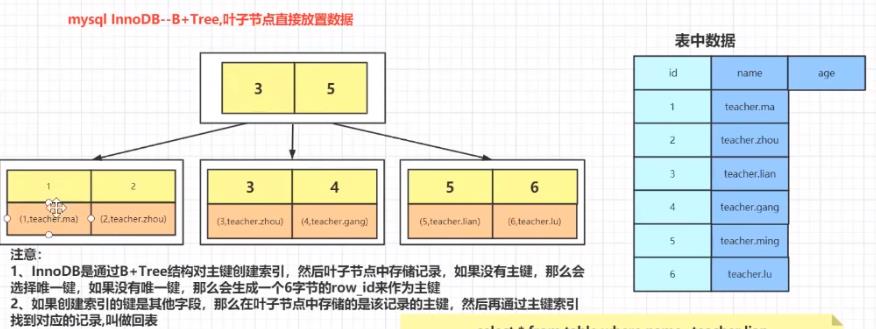
3.1.2 MyISAM多个非聚簇索引
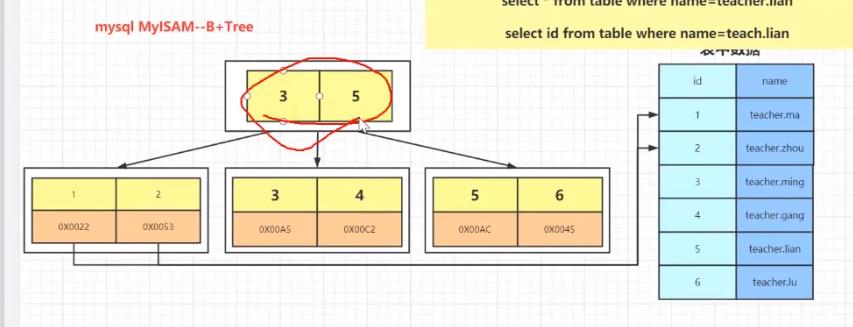
数据字段指向数据表记录地址。
3.2 回表(查询多个索引,走了多棵B+树)
- 当根据普通索引查询到聚簇索引的key值之后,再根据key值在聚簇索引中获取所有行记录,走了多棵B+树。
3.3 索引覆盖(重点,组合索引)
- 通过一个索引就能获取到想要的数据,不需要从聚簇索引查询任何数据。
延伸思考点:
- 是不是尽量用到聚簇索引?
3.4 最左匹配
假如创建一个(a,b)的联合索引,那么它的索引树是这样的
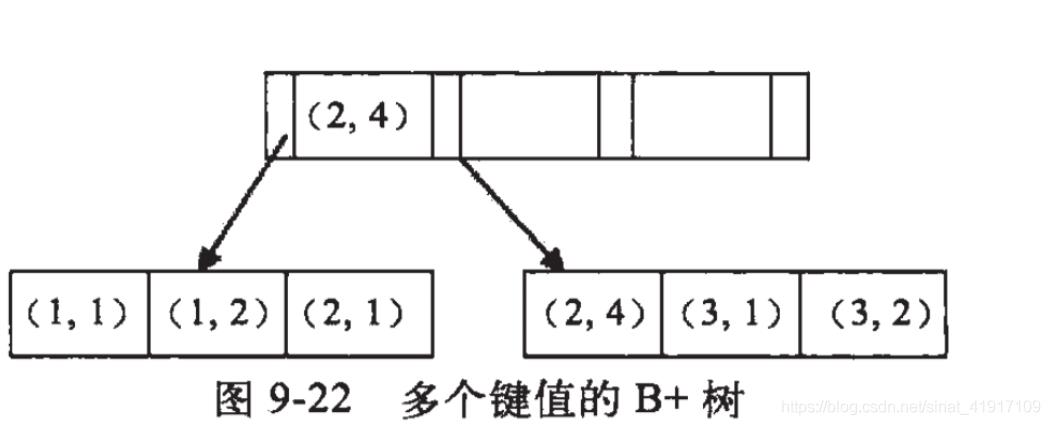
可以看到a的值是有顺序的,1,1,2,2,3,3,而b的值是没有顺序的1,2,1,4,1,2。所以b = 2这种查询条件没有办法利用索引,因为联合索引首先是按a排序的,b是无序的。
同时我们还可以发现在a值相等的情况下,b值又是按顺序排列的,但是这种顺序是相对的。所以最左匹配原则遇上范围查询就会停止,剩下的字段都无法使用索引。例如a = 1 and b = 2 a,b字段都可以使用索引,因为在a值确定的情况下b是相对有序的,而a>1and b=2,a字段可以匹配上索引,但b值不可以,因为a的值是一个范围,在这个范围中b是无序的。
最左匹配原则:最左优先,以最左边的为起点任何连续的索引都能匹配上。同时遇到范围查询(>、<、between、like)就会停止匹配。
假如建立联合索引(a,b,c)
- a
- a,b
- a,b,c
参考:https://blog.csdn.net/sinat_41917109/article/details/88944290
3.4.1 全值匹配查询
select * from table_name where a = '1' and b = '2' and c = '3'
select * from table_name where b = '2' and a = '1' and c = '3'
select * from table_name where c = '3' and b = '2' and a = '1'
......
where子句几个搜索条件顺序调换不影响查询结果,因为Mysql中有查询优化器,会自动优化查询顺序
3.4.2 匹配左边列
select * from table_name where a = '1'
select * from table_name where a = '1' and b = '2'
select * from table_name where a = '1' and b = '2' and c = '3'
都从最左边开始连续匹配,用到了索引.
select * from table_name where b = '2'
select * from table_name where c = '3'
select * from table_name where b = '1' and c = '3'
没有从最左边开始,最后查询没有用到索引,用的是全表扫描 .
select * from table_name where a = '1' and c = '3'
只用到了a列的索引,b列和c列都没有用到 .
3.4.3 匹配列前缀
select * from table_name where a like 'As%'; //前缀都是排好序的,走索引查询
select * from table_name where a like '%As'//全表查询
select * from table_name where a like '%As%'//全表查询
3.4.4 匹配范围值
select * from table_name where a > 1 and a < 3 and b > 1;
多个列同时进行范围查找时,只有对索引最左边的那个列进行范围查找才用到B+树索引,也就是只有a用到索引,在1<a<3的范围内b是无序的,不能用索引,找到1<a<3的记录后,只能根据条件 b > 1继续逐条过滤
3.4.5 精确匹配某一列并范围匹配另外一列
select * from table_name where a = 1 and b > 3;
a=1的情况下b是有序的,进行范围查找走的是联合索引
3.4.6 排序
select * from table_name order by a,b,c limit 10;
因为b+树索引本身就是按照上述规则排序的,所以可以直接从索引中提取数据,然后进行回表操作取出该索引中不包含的列就好了
order by的子句后面的顺序也必须按照索引列的顺序给出,比如
select * from table_name order by b,c,a limit 10;
这种颠倒顺序的没有用到索引
以上是关于理解MySql索引与优化的主要内容,如果未能解决你的问题,请参考以下文章