手写体汉字识别(分割+卷积识别)[2021课设论文]
Posted Windalove
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手写体汉字识别(分割+卷积识别)[2021课设论文]相关的知识,希望对你有一定的参考价值。
本文为课设论文:对于汉字数字的识别,模型搭建和代码并不是难点,预处理才显得重要和困难。虽然模型准确率能达到90%~95%,但是也存在没解决的问题。
如有需要,可以私信提供完整代码工程及其数据集。(tensorflow2搭建模型 pandas数据处理 matplotlib可视化显示 )
文章目录
1选题背景
随着时代的不断进步和技术的发展,网络社交媒体的兴起也带来了图像数据的“爆炸性”增长。作为人们日常交流的主要方式之一,图像因其内容丰富,直观等优点而被广泛用作交流的载体。基于卷积神经网络的图像识别是图像识别领域中重要应用,通过使用图像进行特征值提取,识别和卷积等一系列算法运算来识别和分析不同的图像。人工智能的飞速发展使得机器学习在其研究领域中越来越重要。使用算法学习每条数据并预测结果。这已成为打开人工智能之门的重要钥匙。在机器视觉中,图像识别是基础,但是如何将图像中的低级信息与高级图像语义相关联成为图像识别的关键问题。
本文中所需要解决的问题是:针对含有若干汉字(0-10)的图像,能够自动检测并识别出图像中的汉字。
2卷积神经网络概述
卷积神经网络是在早些年提出的,近年来人工智能的快速发展使这种模型重新回到学者的视野。它在图像技术,生物医学技术,工业生产等领域起着重要作用。神经网络的最早概念是由科学家在人类神经系统中扩展的,它模仿了人类神经系统并提出了神经网络的概念。从神经网络的概念出发,卷积神经网络得到了进一步的改进,该模型的出现为机器视觉带来了好消息。
我们选择CNN卷积神经网络而不是选择传统机器学习方法在于卷积神经网络具备以下几点优势:首先CNN不需要人工去提取特征,传统的机器学习需要人工提取特征.;其次传统的机器学习表达能力有限,深度学习表达能力强;最后深度学习适合处理大数据,而数据量比较小的时候,用传统机器学习方法也许更合适。
3主要主要工具库说明
tensorflow2:我们选择TensorFlow 2.0 替代1.0版本,在于代码上的简洁性,可用性和灵活性,可以极大程度上增快我们的开发效率。
使用numpy,pandas进行基本的数据挖掘与处理。
使用 matplotlib,cv2进行图像的读取显示,转化处理。
4样本数据获取方式
数据网站:http://www.nlpr.ia.ac.cn/databases/handwriting/download.html

我们从网站中选择了如上图的四个部分的数据作为训练数据和测试数据,然后查询数字汉字字符的GB2312编码十进制格式。从所有汉字类别中选择出汉字(0-10)。
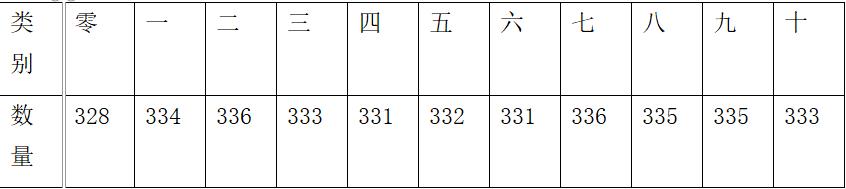
最终我们获取0-10共11个类别。样本数量如下:
5算法实现
5.1图片预处理
我们从训练集中随机选择40张原始样本图片显示如下:

紧接着我们判断图像是RGB三通道,所以我们需要将RGB三通道图像转为灰度。对图像进行灰度处理的同时我们Resize操作统一图片尺寸为(32,32),结果如下:

此时图片从三通道转换成一通道,随后设置阈值,对图片进行二值化处理,得到如下图:

我们可以明显看出,数字特征更为明显,并且像素点非0即1更有利于计算。同时我们考虑了进行腐蚀和膨胀,但从结果可知,对精度影响不大,在此不多做声明。
5.2模型搭建
由于数字类别过于简单,样本特征比较明显,初步没有考虑使用经典卷积神经网络,例如AlexNet、VGG、GoogLeNet、ResNet,如果选择了深层的经典神经网络那就意味着需要训练更多的参数以及更多的样本数量,如果后期的训练结果不理想可以考虑使用。
开始我们搭建了两个网络结构:
模型一:
在这个模型中,卷积核的大小都是33,步长都是采用默认的1。这是由于参考了经典模型vgg,两个33的卷积等价与55的卷积,三个33的卷积等价与7*7的卷积。这样的目的是为了减少训练参数的参数,同时增加层数可以提高分类结果的精度。但绝对不是层数越多效果一定越好,在RetNet模型论文中有提到可能产生退化问题,但是本模型的深度远远达不到,无需担心。模型中使用的激活函数都是relu。
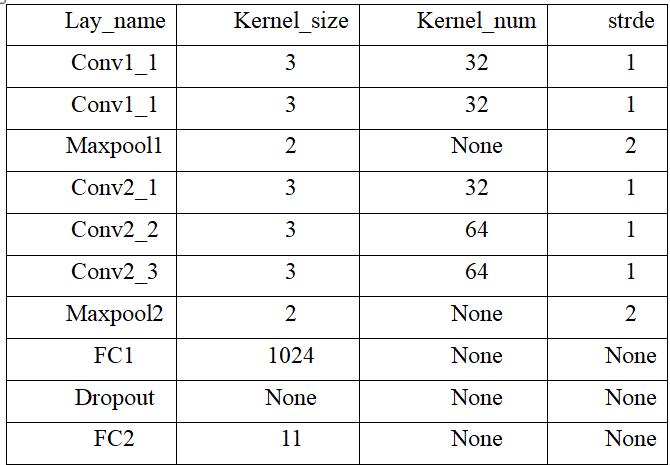
具体参数使用如上表所示,我们可以将模型一称为五层结构:
- 1.第一层:两个3*3的卷积核进行卷积。
- 2.第二层:最大池化(在AlexNet经典模型论文有提到,平均池化更为模糊,所以这边选择了最大池化)。
- 3.第三层:三个3*3的卷积核进行卷积。
- 4.第四层:最大池化操作。
- 5.第五层:两次全连接+Dropout 防止过拟合。
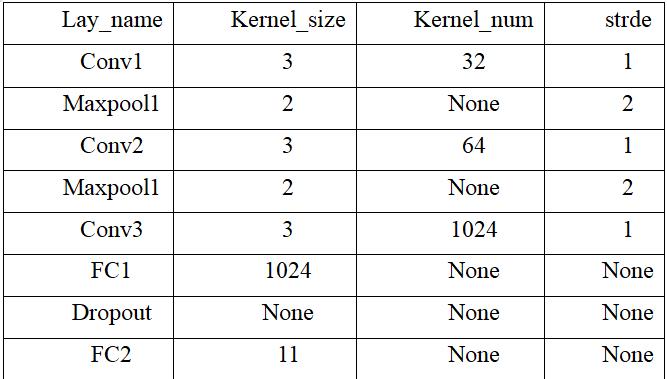
在第二个模型中,我们进行了三次卷积,两次最大池化,两次全连接以及Dropout 防止过拟合。具体参数使用如下表。
6结果说明
6.1 原始图形样本训练结果
模型一训练结果如下:
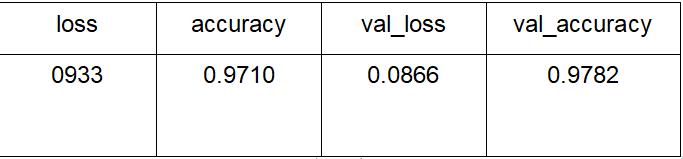
模型一 训练集和测试集的损失率及准确率迭代变化如下图:


我们随机取40个样本进行测试展示,其中红色标签为预测错误,结果如下图(补充说明:显示的为预处理后的图像):

模型二的训练结果如下:
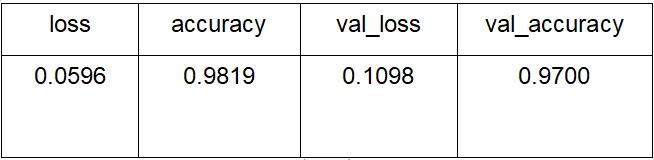
模型二训练集和测试集的损失率及准确率迭代变化如下图:
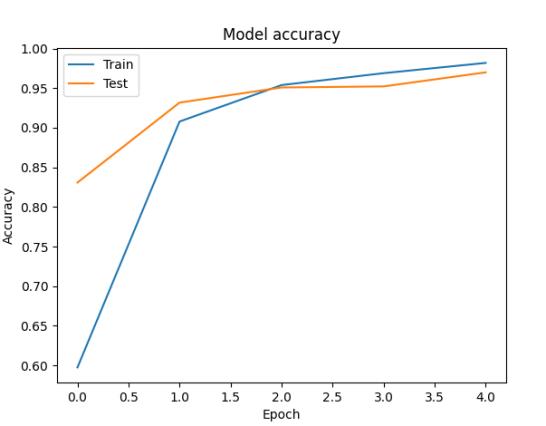

我们随机取40个样本进行测试展示,其中红色标签为预测错误,结果如下图:

总而言之,两个模型的预测准确率都能达到95%的准确率以上,无明显的差别,说明模型的网络结构较为合理。
6.1 手写体样本训练结果
我们分别在平板和手写纸上分别写了11个汉字(0-10),原始图样如下:


对所有汉字进行裁剪、预处理和放入模型预测,模型一预测结果如下,达到了20/22的准确率,结果如下:

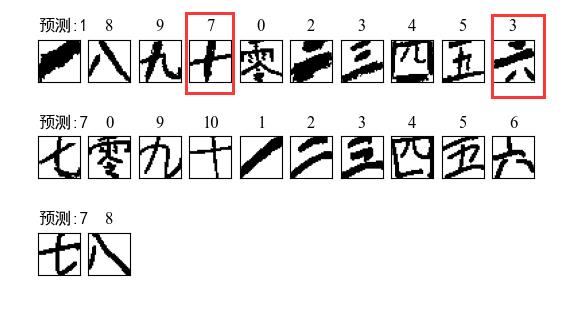
模型二的预测结果如下,达到了21/22的准确率,结果显示如下:

7设计中遇到的困难
7.1已解决
1、gnt格式转换成png格式,同时修改代码直接获取0-10汉字。
7.2未解决
1、对于汉字的裁剪,自己使用的方法比较简单,直接对二值化后的图片横向和纵向进行裁剪,局限性很高,如果汉字带有偏旁或者‘八’这种会被识别成两个部分。同时如果纸张倾斜也会造成错误。考虑了很多方法,但都存在缺陷
2、虽然懂得膨胀和腐蚀的使用,但是没有发现在这个题目中多大的用处。
8附录
8.1数据集的获取
import os
import numpy as np
import struct
from PIL import Image
# data文件夹存放转换后的.png文件
data_dir = 'E:/文档//手写汉字识别/data'
# 路径为存放数据集解压后的.gnt文件
train_data_dir = os.path.join(data_dir, 'E:/1_人工智能课设/1')
#test_data_dir = os.path.join(data_dir, 'E:/1_人工智能课设/test_gnt')
print(train_data_dir)
#print(test_data_dir )
def read_from_gnt_dir(gnt_dir=train_data_dir):
def one_file(f):
header_size = 10
while True:
header = np.fromfile(f, dtype='uint8', count=header_size)
if not header.size: break
sample_size = header[0] + (header[1] << 8) + (header[2] << 16) + (header[3] << 24)
tagcode = header[5] + (header[4] << 8)
width = header[6] + (header[7] << 8)
height = header[8] + (header[9] << 8)
if header_size + width * height != sample_size:
break
image = np.fromfile(f, dtype='uint8', count=width * height).reshape((height, width))
yield image, tagcode
i=0
for file_name in os.listdir(gnt_dir):
print(i)
if file_name.endswith('.gnt'):
file_path = os.path.join(gnt_dir, file_name)
with open(file_path, 'rb') as f:
for image, tagcode in one_file(f):
if((tagcode==49635) or (tagcode==53947) or (tagcode==46846) or (tagcode ==51453) or (tagcode ==52164) or (tagcode ==52965) or (tagcode ==49657) or (tagcode ==50911) or (tagcode ==45259) or (tagcode ==48837) or (tagcode ==51886)):
yield image, tagcode
char_set = set()
c=2
for _, tagcode in read_from_gnt_dir(gnt_dir=train_data_dir):
print(c)
tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312','ignore')
char_set.add(tagcode_unicode)
char_list = list(char_set)
char_dict = dict(zip(sorted(char_list), range(len(char_list))))
print(len(char_dict))
print("char_dict=", char_dict)
import pickle
f = open('char_dict', 'wb')
pickle.dump(char_dict, f)
f.close()
train_counter = 0
test_counter = 0
b=1
for image, tagcode in read_from_gnt_dir(gnt_dir=train_data_dir):
print(b)
tagcode_unicode = struct.pack('>H', tagcode).decode('gb2312','ignore')
im = Image.fromarray(image)
# 路径为data文件夹下的子文件夹,train为存放训练集.png的文件夹
dir_name = 'E:/1_人工智能课设/2/' + '%0.5d' % char_dict[tagcode_unicode]
if not os.path.exists(dir_name):
os.mkdir(dir_name)
im.convert('RGB').save(dir_name + '/' + str(train_counter) + '.png')
print("train_counter=", train_counter)
train_counter += 1
8.2 模型一(分割+搭建)
8.2 模型二
需要完整代码工程及数据,可私信。
如有错误,欢迎指出。

以上是关于手写体汉字识别(分割+卷积识别)[2021课设论文]的主要内容,如果未能解决你的问题,请参考以下文章