2000亿次开放学习后,DeepMind的智能体成精了
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2000亿次开放学习后,DeepMind的智能体成精了相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :量子位
有这样一批智能体,在完全没有见过的游戏任务里,也学会了游刃有余地解决目标。
譬如面对下面这样一个高地,它们要取到上面的紫色金字塔。
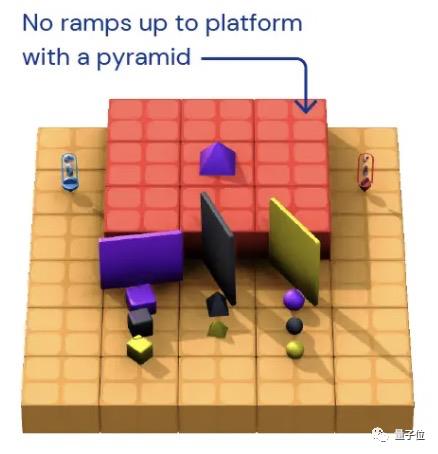
没有跳跃功能的它们,看似开始“焦躁”地乱扔起东西来,实则其中一块板子正好被“扔”成了楼梯,这不就巧了,目标完成!

你可能会说这只是“瞎猫撞死耗子”罢了,但多次实验发现,该智能体可以复现该方法的!

而且它还会不止一种方法,“我不上去,你下来”——直接借助板子把目标扒拉下来了!

这也行?

而这些成精了的智能体来自DeepMind。
现在,为了让AI更加多才多艺、举一反三,他们专门给智能体打造了一个包含了数十亿游戏任务的“元宇宙”XLand:让智能体在不断扩展、升级的开放世界中通过上亿次的训练练就了不俗的泛化能力。

最终效果就像前面看到的,无需在新游戏中从头训练,它们就能自主解决任务!
DeepMind也因此发表了一篇论文,就叫做:《从开放学习走出来的通用智能体》。

如何做到的呢?
“元宇宙”XLand
最功不可没之一的就是这个庞大的“元宇宙”模拟空间。
这是一个“游戏星系”,里面有无数个“游戏星球”,每个星球上的游戏按竞争性、平衡性、可选项、探索难度四个纬度进行区分。

比如图左上介绍的“抢方块”游戏:蓝色智能体需要把黄色的立方体放到白色区域,红色智能体需要把同一个立方体放在蓝色区域。
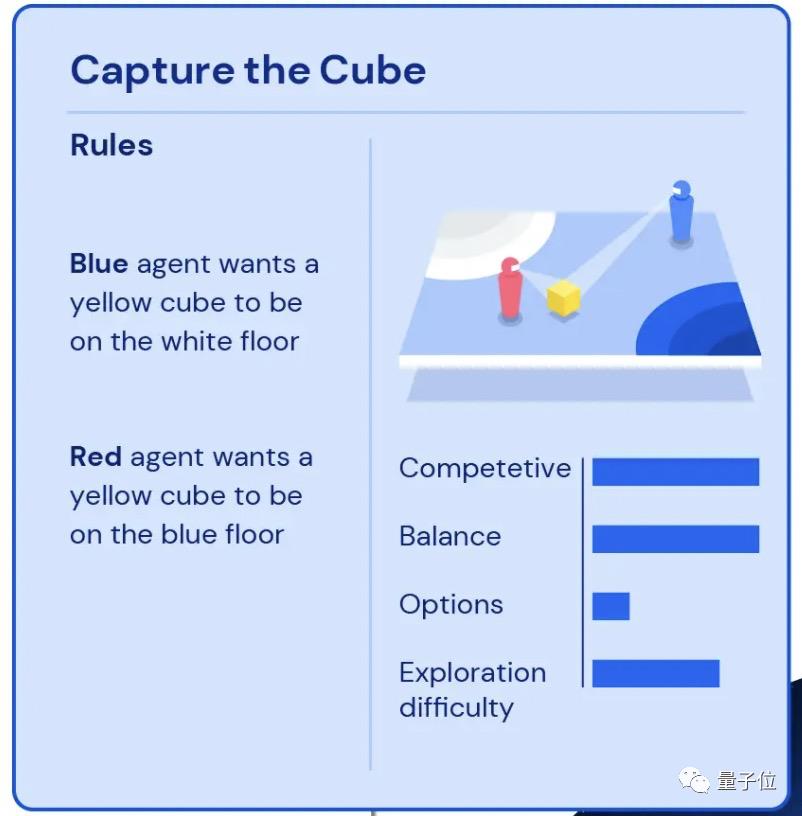
啊想想就头大,所以这个游戏的竞争性值都拉满了,而由于双方的条件/目标都一样,所以平衡性值也很高,因为需要定位目标区域,所以探索难度并不小。
再比如图右上的“将球体和立方体配对”:蓝色/红色智能体要将几何体按颜色归类到一起,完成任意一组配对就行。这个游戏的可选性值就拉满了,但竞争性就没那么强。

ps.蓝色游戏代表是完全竞争性的,粉色为完全合作性的。
不管是哪种游戏任务,这批智能体都从最简单的开始(比如仅“靠近紫色立方体”这种),一步步解锁复杂度升级的游戏(比如和另一个智能体“捉迷藏”),其中每一项游戏都有奖励,智能体们的目标就是将拿到的奖励最大化。
而智能体“玩家”们是通过阅读收到的目标的文字描述、观察RGB图像来感知周围环境来完成任务。
生成的新任务要基于旧任务,且难度要刚刚好
除了上面这个开放式的学习环境,训练方法也很重要。
研究人员使用的神经网络训练架构提供了一种针对智能体内部循环状态的注意力机制——通过估计所玩游戏的子目标,来持续引导智能体的注意力。
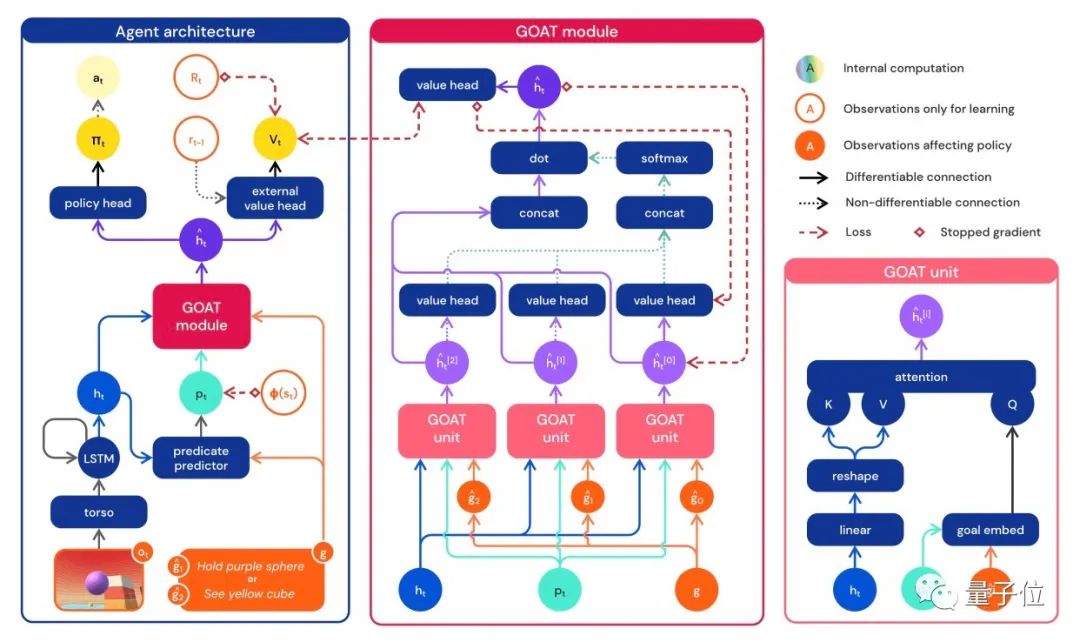
这种策略让智能体学习到更具普遍能力的策略。
还有一个问题:如此广阔的游戏环境,什么样的游戏任务分布能产出最善于泛化的智能体呢?
研究人员通过持续调整每个智能体的游戏分布发现,每个新任务都要基于通关的旧任务生成,不能太难,也不能太容易。
这个也基本符合一般认知。
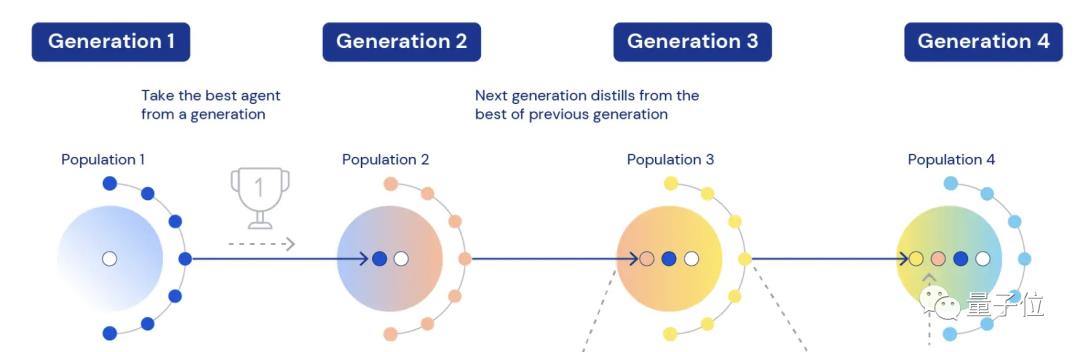
它们先经历了四次迭代:
每个任务由多个智能体参与竞争,在旧任务上适应得好的智能体,会带着权重、瞬时任务分布、超参数等参与到新一轮任务中继续学习。此时也会加入新的智能体让竞争“活”起来。
智能体表现出明显的零样本学习能力
最后生成的第五代智能体,在XLand 4000多个“星球”里玩了大约70万个游戏,每一个智能体都经历了2000亿次训练,完成了340万个独特任务。
到了这个时候,这些智能体已经能够顺利完成每一项评估任务(除了少数即使是人类也不可能完成的)。
整个实验也最终表明,通过开发像XLand这样的环境和这样开放式地训练方法,一些基于RL的智能体已表现出明显的零样本学习能力 (0-shot)。
比如使用工具、打拦(ridge-fencing)、“捉迷藏”、找立方体、数数、合作或竞争等。
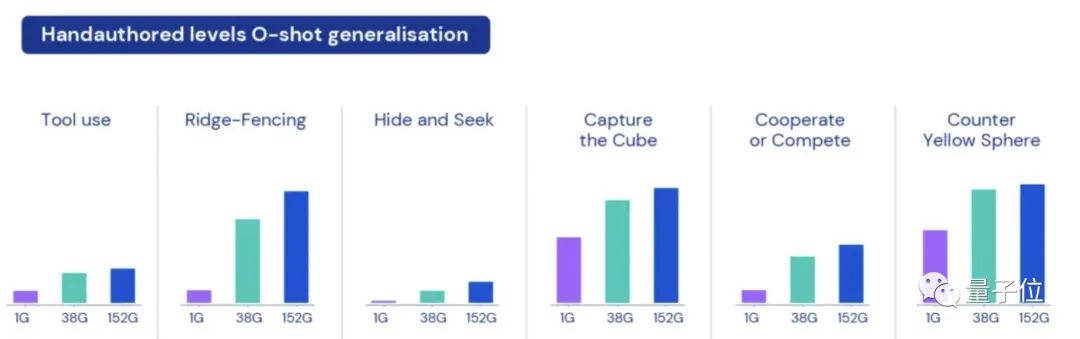
研究人员也观察到智能体们面对新任务时不知道“什么是最好的解决办法”,但它们会不断地试验直到达到目标。
这个过程中出现的有趣的”紧急启发式行为”,除了开头提到的搭梯子,还有这个临时更换更简易目标的例子——
在一个游戏中该智能体需要从3个目标中任选一个完成:
1、将黑色金字塔放到黄色球体旁边;
2、将紫色球体放到黄色金字塔旁边;
3、将黑色金字塔放到橙色区域。
它一开始找到了一个黑色金字塔,想去完成目标3,但在搬运过程中看到了黄色球体,于是它就在1秒内改变了主意,选择直接将金字塔放在黄色球体旁边完成目标1 。(整个过程一共耗时6秒)
。(整个过程一共耗时6秒)

最后,看完了DeepMind的研究,再抛给大家一个问题:我们离真正的通用人工智能还有多远?

(ps.你发现了吗,文章最开头高台取金字塔任务中的小红智障体就不行,一直打转,面对小蓝搭好的梯子甚至直接毁掉 )
)
论文地址:
https://arxiv.org/abs/2107.12808
参考链接:
https://deepmind.com/blog/article/generally-capable-agents-emerge-from-open-ended-play
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于2000亿次开放学习后,DeepMind的智能体成精了的主要内容,如果未能解决你的问题,请参考以下文章