大桥数据,国外大桥排行榜数据清单,Python爬虫120例第32例
Posted 梦想橡皮擦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大桥数据,国外大桥排行榜数据清单,Python爬虫120例第32例相关的知识,希望对你有一定的参考价值。
《爬虫 120 例》专栏第 32 例,本例开始学习 PyQuery 解析框架,该解析对从前端转 Python 的朋友非常友好,因为它模拟的是 JQuery 操作。
正式开始前,先安装 pyquery 到本地开发环境中。命令如下:pip install pyquery ,我使用的版本为 1.4.3。
基本使用如下所示,看懂也就掌握了 5 成了,就这么简单。
from pyquery import PyQuery as pq
s = '<html><title>橡皮擦的PyQuery小课堂</title></html>'
doc = pq(s)
print(doc('title'))
输出如下内容:
<title>橡皮擦的PyQuery小课堂</title>
也可以直接将要解析的网址 URL 传递给 pyquery 对象,代码如下所示:
from pyquery import PyQuery as pq
url = "https://www.bilibili.com/"
doc = pq(url=url,encoding="utf-8")
print(doc('title')) # <title>哔哩哔哩 (゜-゜)つロ 干杯~-bilibili</title>
相同的思路,还可以通过文件初始化 pyquery 对象,只需要修改参数为 filename 即可。
基础铺垫过后,就可以进入到实操环节,下面是本次要抓取的目标案例分析。
目标站点分析
本次要采集的为 :List of Highest International Bridges(最高国际桥梁名单),页面呈现的数据如下所示。
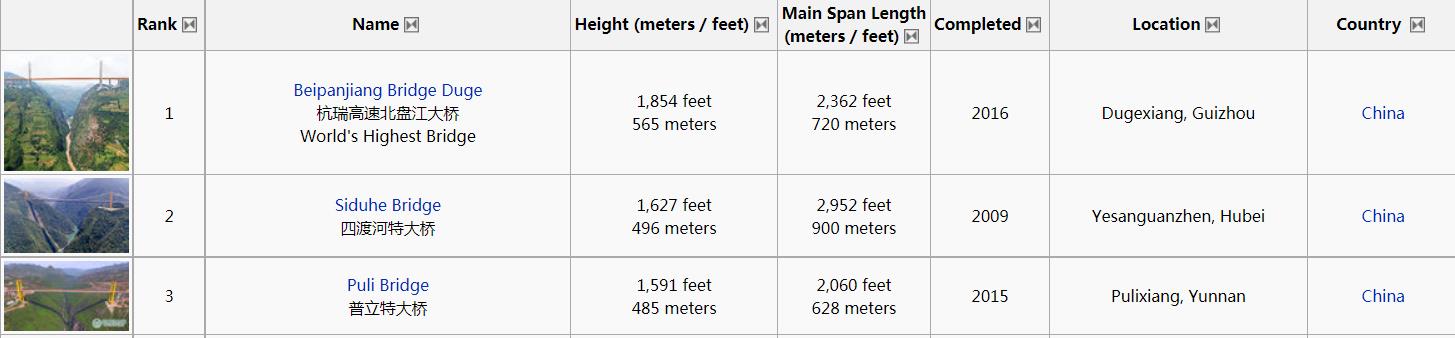
在翻阅过程中发现多数都是中国设计的,果然我们基建世界第一。
翻页规则如下所示:
http://www.highestbridges.com/wiki/index.php?title=List_of_Highest_International_Bridges/Page_1
http://www.highestbridges.com/wiki/index.php?title=List_of_Highest_International_Bridges/Page_2
# 实测翻到第 13 页数据就空了,大概1200座桥梁
http://www.highestbridges.com/wiki/index.php?title=List_of_Highest_International_Bridges/Page_13
由于目标数据以表格形式存在,故直接按照表头提取数据即可。
Rank,Name,Height (meters / feet),Main Span Length,Completed,Location,Country
编码时间
正式编码前,先拿第一页进行练手。
from pyquery import PyQuery as pq
url = "http://www.highestbridges.com/wiki/index.php?title=List_of_Highest_International_Bridges/Page_1"
doc = pq(url=url, encoding='utf-8')
print(doc('title'))
def remove(str):
return str.replace("<br/>", "").replace("\\n", "")
# 获取所有数据所在的行,下面使用的是 css 选择器,称作 jquery 选择器也没啥问题
items = doc.find('table.wikitable.sortable tr').items()
for item in items:
td_list = item.find('td')
rank = td_list.eq(1).find("span.sorttext").text()
name = td_list.eq(2).find("a").text()
height = remove(td_list.eq(3).text())
length = remove(td_list.eq(4).text())
completed = td_list.eq(5).text()
location = td_list.eq(6).text()
country = td_list.eq(7).text()
print(rank, name, height, length, completed, location, country)
代码整体写下来,发现依旧是对于选择器的依赖比较大,也就是需要熟练的操作选择器,选中目标元素,方便获取最终的数据。
将上述代码扩大到全部数据,修改成迭代采集。
from pyquery import PyQuery as pq
import time
def remove(str):
return str.replace("<br/>", "").replace("\\n", "").replace(",", ",")
def get_data(page):
url = "http://www.highestbridges.com/wiki/index.php?title=List_of_Highest_International_Bridges/Page_{}".format(
page)
print(url)
doc = pq(url=url, encoding='utf-8')
print(doc('title'))
# 获取所有数据所在的行,下面使用的是 css 选择器,称作 jquery 选择器也没啥问题
items = doc.find('table.wikitable.sortable tr').items()
for item in items:
td_list = item.find('td')
rank = td_list.eq(1).find("span.sorttext").text()
name = remove(td_list.eq(2).find("a").text())
height = remove(td_list.eq(3).text())
length = remove(td_list.eq(4).text())
completed = remove(td_list.eq(5).text())
location = remove(td_list.eq(6).text())
country = remove(td_list.eq(7).text())
data_tuple = (rank, name, height, length, completed, location, country)
save(data_tuple)
def save(data_tuple):
try:
my_str = ",".join(data_tuple) + "\\n"
# print(my_str)
with open(f"./data.csv", "a+", encoding="utf-8") as f:
f.write(my_str)
print("写入完毕")
except Exception as e:
pass
if __name__ == '__main__':
for page in range(1, 14):
get_data(page)
time.sleep(3)
其中发现存在英文的逗号,统一进行修改,即 remove(str) 函数的应用。
收藏时间
代码仓库地址:https://codechina.csdn.net/hihell/python120,去给个关注或者 Star 吧。
案例下载到的数据,下载地址:https://download.csdn.net/download/hihell/22032070
今天是持续写作的第 217 / 365 天。
可以关注,点赞、评论、收藏。
更多精彩
以上是关于大桥数据,国外大桥排行榜数据清单,Python爬虫120例第32例的主要内容,如果未能解决你的问题,请参考以下文章