开源数据湖方案选型:HudiDeltaIceberg深度对比
Posted 宝哥大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源数据湖方案选型:HudiDeltaIceberg深度对比相关的知识,希望对你有一定的参考价值。
文章目录
这篇文章主要向大家介绍开源数据湖方案选型:Hudi、Delta、Iceberg深度对比,主要内容包括基础应用、实用技巧、原理机制等方面,希望对大家有所帮助。
目前市面上流行的三大开源数据湖方案分别为: delta、Apache Iceberg和Apache Hudi。
其中,因为 Apache Spark 在商业化上取得巨大成功,因此由其背后商业公司 Databricks 推出的 delta 也显得格外亮眼。
Apache Hudi 是由 Uber 的工程师为其内部数据分析的需求而设计的数据湖项目,它提供的 fast upsert/delete以及compaction等功能能够说是精准命中广大人民群众的痛点,加上项目各成员积极地社区建设,包括技术细节分享、国内社区推广等等,也在逐步地吸引潜在用户的目光。
Apache Iceberg 目前看则会显得相对平庸一些,简单说社区关注度暂时比不上 delta,功能也不如 Hudi 丰富,但倒是一个野心勃勃的项目,由于它具备高度抽象和很是优雅的设计,为成为一个通用的数据湖方案奠基了良好基础。
前言: 共同点
定性上讲,三者均为 Data Lake 的数据存储中间层,其数据管理的功能均是基于一系列的 meta 文件。meta 文件的角色类似于数据库的 catalog/wal,起到 schema 管理、事务管理和数据管理的功能。与数据库不同的是,这些 meta 文件是与数据文件一起存放在存储引擎中的,用户可以直接看到。这种做法直接继承了大数据分析中数据对用户可见的传统,但是无形中也增加了数据被不小心破坏的风险。一旦某个用户不小心删了 meta 目录,表就被破坏了,想要恢复难度非常大。
Meta 文件包含有表的 schema 信息。因此系统可以自己掌握 Schema 的变动,提供 Schema 演化的支持。Meta 文件也有 transaction log 的功能(需要文件系统有原子性和一致性的支持)。所有对表的变更都会生成一份新的 meta 文件,于是系统就有了 ACID 和多版本的支持,同时可以提供访问历史的功能。在这些方面,三者是相同的。
不少用户会想,看着三大项目奇光异彩,到底应该在什么样的场景下,选择合适数据湖方案呢?今天咱们就来解构数据湖的核心需求,深度对比三大产品,帮助用户更好地针对自身场景来作数据湖方案选型。
首先,咱们来逐一分析为什么各技术公司要推出他们的开源数据湖解决方案,他们碰到的问题是什么,提出的方案又是如何解决问题的。咱们但愿客观地分析业务场景,来理性判断到底哪些功能才是客户的痛点和刚需。
一、Databricks 和 Delta
1.1、Delta的意图,解决的疼点
以 Databricks 推出的 delta 为例,它要解决的核心问题基本上集中在下图 :
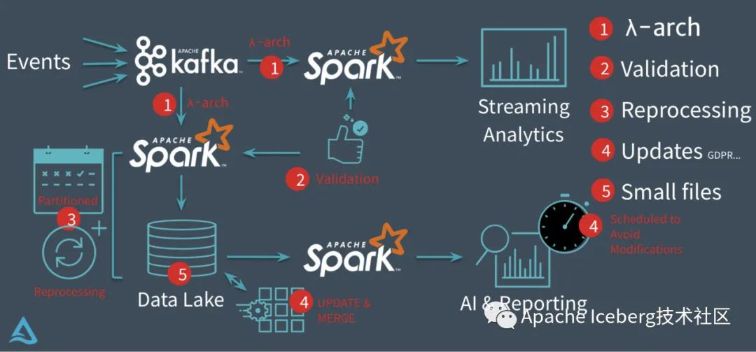
图片来源:https://www.slideshare.net/databricks/making-apache-spark-better-with-delta-lake
在没有 delta 数据湖以前,Databricks 的客户通常会采用经典的 lambda 架构来构建他们的流批处理场景。
以用户点击行为分析为例,点击事件经 Kafka 被下游的 Spark Streaming 做业消费,分析处理(业务层面聚合等)后获得一个实时的分析结果,这个实时结果只是当前时间所看到的一个状态,没法反应时间轴上的全部点击事件。
因此为了保存全量点击行为,Kafka 还会被另一个 Spark Batch 做业分析处理,导入到文件系统上(通常就是 parquet 格式写 HDFS 或者 S3,能够认为这个文件系统是一个简配版的数据湖),供下游的 Batch 做业作全量的数据分析以及 AI 处理等。
1、没有 Delta 数据湖之前存在的问题 :
-
1、批量导入到文件系统的数据通常都缺少全局的严格 schema 规范,下游的 Spark 做业作分析时碰到格式混乱的数据会很麻烦,每个分析做业都要过滤处理错乱缺失的数据,成本较大。
-
2、数据写入文件系统这个过程没有ACID保证,用户可能读到导入中间状态的数据。因此上层的批处理做业为了躲开这个坑,只能调度避开数据导入时间段,能够想象这对业务方是多么不友好;同时也没法保证屡次导入的快照版本,例如业务方想读最近5次导入的数据版本,实际上是作不到的。
-
3、用户没法高效
upsert/delete历史数据,parquet文件一旦写入HDFS文件,要想改数据,就只能全量从新写一份的数据,成本很高。事实上,这种需求是普遍存在的,例如因为程序问题,致使错误地写入一些数据到文件系统,如今业务方想要把这些数据纠正过来;线上的mysql binlog不断地导入update/delete增量更新到下游数据湖中;某些数据审查规范要求作强制数据删除,例如欧洲出台的GDPR隐私保护等等。 -
4、频繁地数据导入会在文件系统上产生大量的小文件,致使文件系统不堪重负,尤为是HDFS这种对文件数有限制的文件系统。
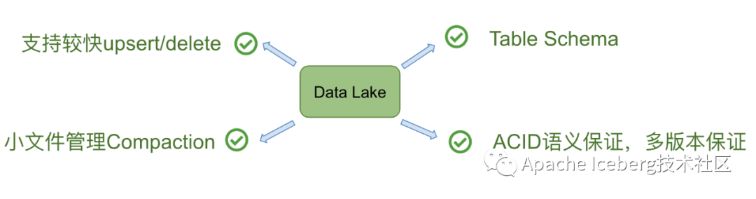
因此,在 Databricks 看来,如下四个点是数据湖必备的:
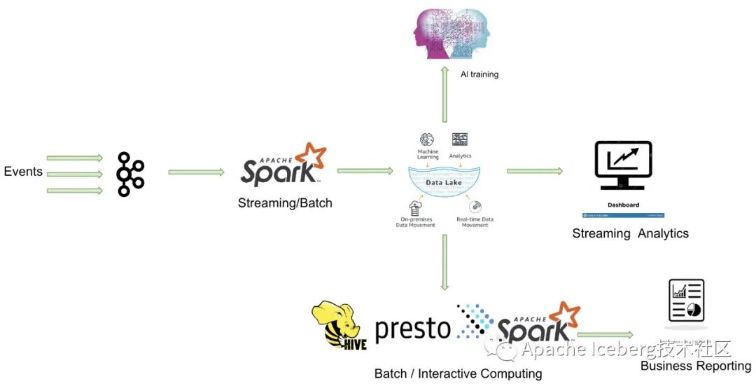
事实上, Databricks 在设计 delta 时,但愿作到流批做业在数据层面作到进一步的统一(以下图)。业务数据通过Kafka导入到统一的数据湖中(不管批处理,仍是流处理),上层业务能够借助各类分析引擎作进一步的商业报表分析、流式计算以及AI分析等等。
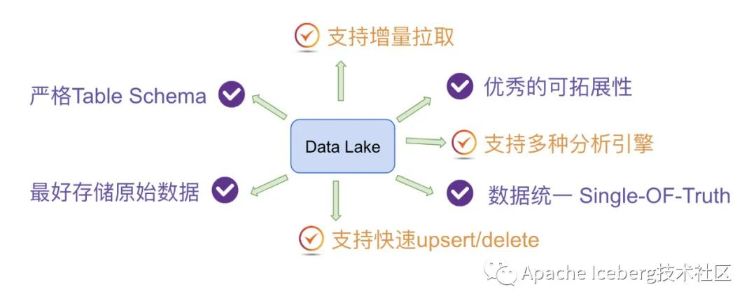
因此,总结起来,我认为 databricks 设计 delta 时主要考虑实现如下核心功能特性:
二、Uber和Apache Hudi
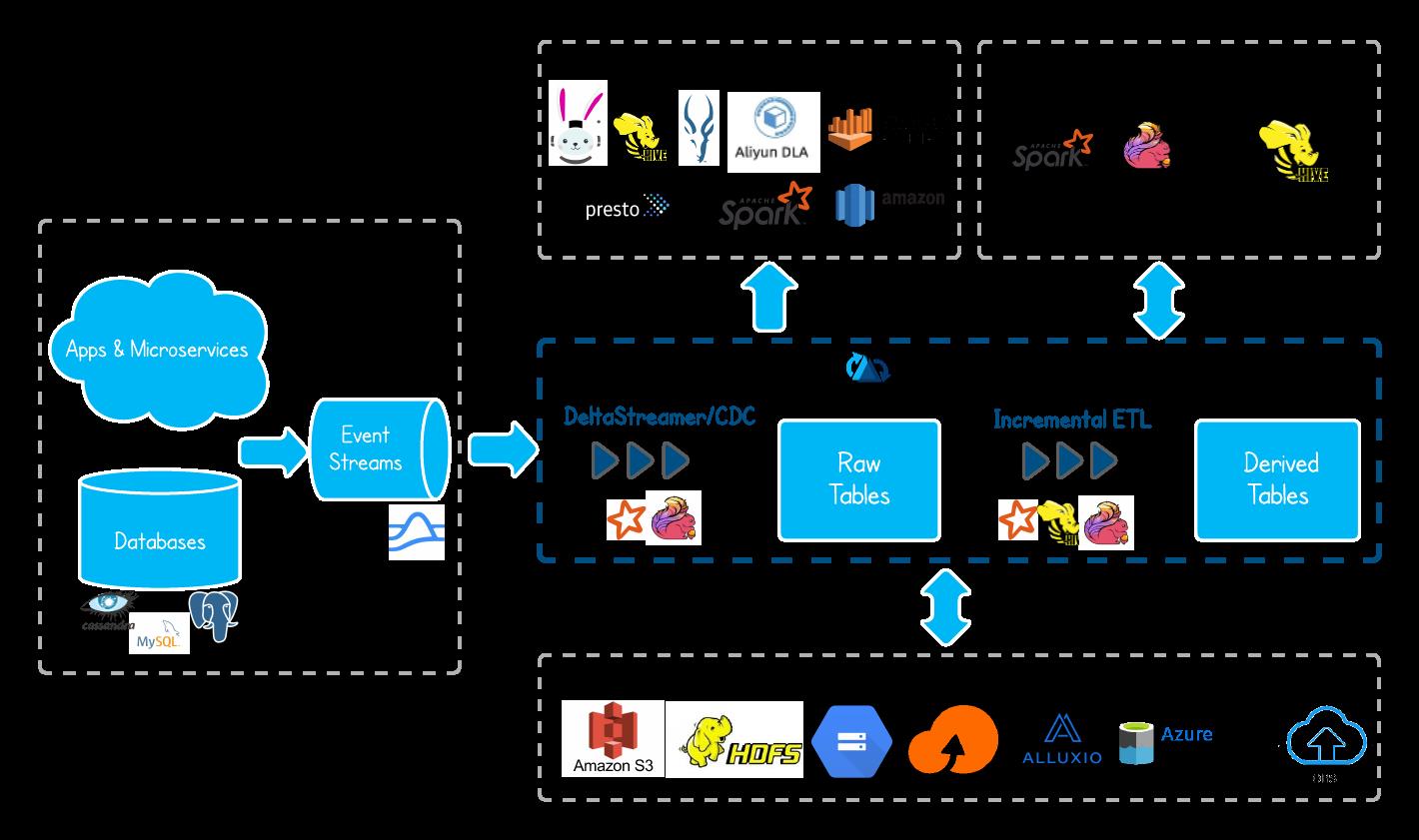
Uber的业务场景主要为:将线上产生的行程订单数据,同步到一个统一的数据中心,而后供上层各个城市运营同事用来作分析和处理。
在2014年的时候,Uber的数据湖架构相对比较简单,业务日志经由Kafka同步到S3上,上层用EMR作数据分析;线上的关系型数据库以及NoSQL则会经过ETL(ETL任务也会拉去一些Kakfa同步到S3的数据)任务同步到闭源的Vertica分析型数据库,城市运营同窗主要经过 Vertica SQL 实现数据聚合。当时也碰到数据格式混乱、系统扩展成本高(依赖收 Vertica 商业收费软件)、数据回填麻烦等问题。
后续迁移到开源的 Hadoop 生态,解决了扩展性问题等问题,但依然碰到Databricks 上述的一些问题,其中最核心的问题是没法快速upsert存量数据。
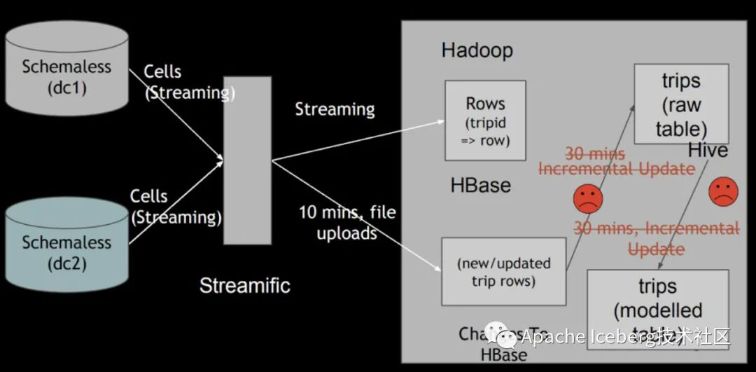
如上图所示,ETL 任务每隔30分钟按期地把增量更新数据同步到分析表中,所有改写已存在的全量旧数据文件,致使数据延迟和资源消耗都很高。
此外,在数据湖的下游,还存在流式做业会增量地消费新写入的数据,数据湖的流式消费对他们来讲也是必备的功能。因此,他们就但愿设计一种合适的数据湖方案,在解决通用数据湖需求的前提下,还能实现快速的 upsert 以及流式增量消费。
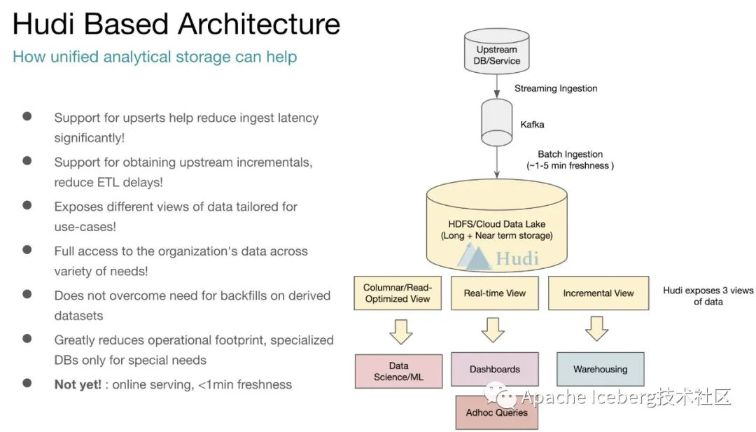
Uber团队在Hudi上同时实现了Copy On Write和Merge On Read的两种数据格式,其中Merge On Read就是为了解决他们的fast upsert而设计的。
简单来讲,就是每次把增量更新的数据都写入到一批独立的delta文件集,按期地经过compaction合并delta文件和存量的data文件。同时给上层分析引擎提供三种不一样的读取视角:仅读取delta增量文件、仅读取data文件、合并读取delta和data文件。知足各类业务方对数据湖的流批数据分析需求。
最终,咱们能够提炼出Uber的数据湖需求为以下图,这也正好是Hudi所侧重的核心特性:
三、Netflix和Apache Iceberg
Netflix的数据湖原先是借助Hive来构建,但发现Hive在设计上的诸多缺陷以后,开始转为自研Iceberg,并最终演化成Apache下一个高度抽象通用的开源数据湖方案。
Netflix用内部的一个时序数据业务的案例来讲明Hive的这些问题,采用Hive时按照时间字段作partition,他们发现仅一个月会产生2688个partition和270万个数据文件。他们执行一个简单的select查询,发现仅在分区裁剪阶段就耗费数十分钟。

他们发现Hive的元数据依赖一个外部的MySQL和HDFS文件系统,经过MySQL找到相关的parition以后,须要为每一个partition去HDFS文件系统上按照分区作目录的list操做。在文件量大的状况下,这是一个很是耗时的操做。
同时,因为元数据分属MySQL和HDFS管理,写入操做自己的原子性难以保证。即便在开启Hive ACID状况下,仍有不少细小场景没法保证原子性。另外,Hive Metastore没有文件级别的统计信息,这使得filter只能下推到partition级别,而没法下推到文件级别,对上层分析性能损耗无可避免。
最后,Hive对底层文件系统的复杂语义依赖,使得数据湖难以构建在成本更低的S3上。
因而,Netflix为了解决这些痛点,设计了本身的轻量级数据湖Iceberg。在设计之初,做者们将其定位为一个通用的数据湖项目,因此在实现上作了高度的抽象。
虽然目前从功能上看不如前面二者丰富,但因为它牢固坚实的底层设计,一旦功能补齐,将成为一个很是有潜力的开源数据湖方案。
整体来讲,Netflix设计Iceberg的核心诉求能够概括为以下:
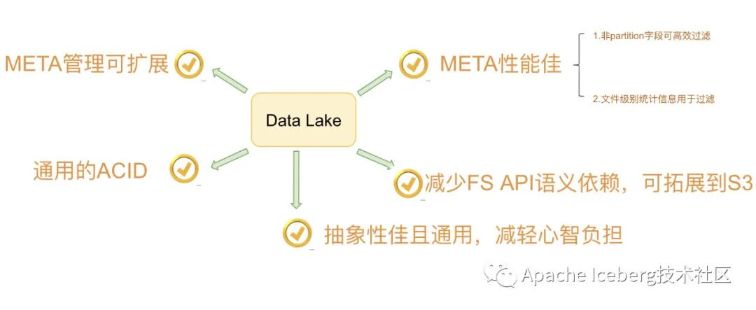
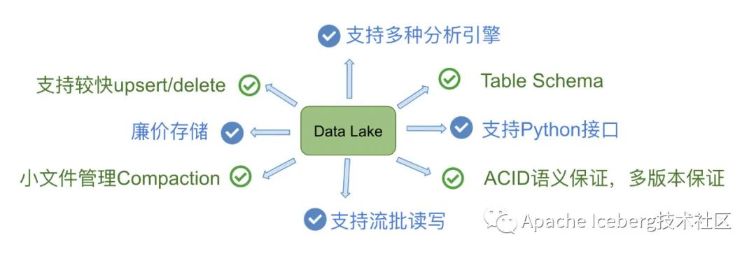
四、痛点小结
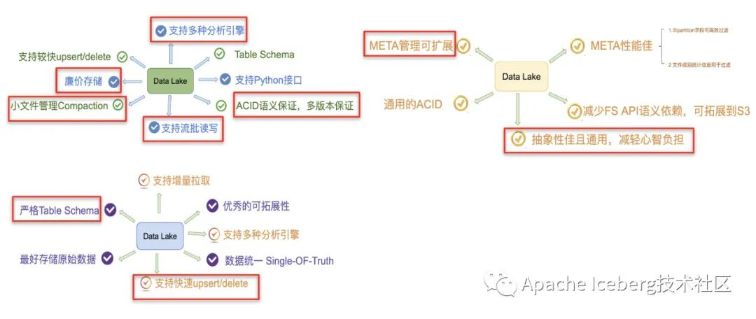
咱们能够把上述三个项目针对的痛点,放到一张图上来看。能够发现标红的功能点,基本上是一个好的数据湖方案应该去作到的功能点:
4.1、七大维度对比
在理解了上述三大方案各自设计的初衷和面向的痛点以后,接下来咱们从7个维度来对比评估三大项目的差别。一般人们在考虑数据湖方案选型时,Hive ACID也是一个强有力的候选人,由于它提供了人们须要的较为完善功能集合,因此这里咱们把Hive ACID归入到对比行列中。
4.1.1、ACID和隔离级别支持

这里主要解释下,对数据湖来讲三种隔离分别表明的含义:
-
Serialization 是说全部的reader和writer都必须串行执行;
-
Write Serialization: 是说多个writer必须严格串行,reader和writer之间则能够同时跑;
-
Snapshot Isolation: 是说若是多个writer写的数据无交集,则能够并发执行;不然只能串行。Reader和writer能够同时跑。
综合起来看,Snapshot Isolation 隔离级别的并发性是相对比较好的。
4.1.2、Schema 变动支持和设计
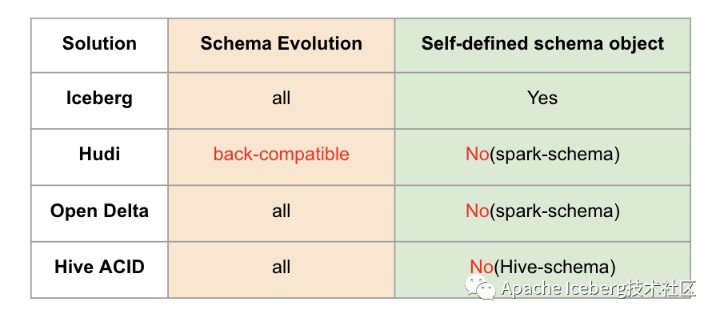
这里有两个对比项,一个是 schema 变动的支持状况,个人理解是hudi仅支持添加可选列和删除列这种向后兼容的 DDL 操做,而其余方案则没有这个限制。另一个是数据湖是否自定义 schema 接口,以期跟计算引擎的 schema 解耦。这里 iceberg 是作的比较好的,抽象了本身的 schema,不绑定任何计算引擎层面的 schema。
4.1.3、流批接口支持
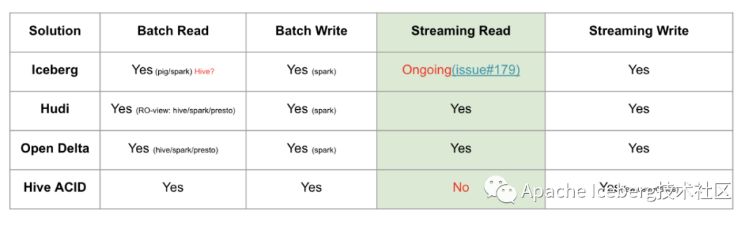
目前 Iceberg 和 Hive 暂时不支持流式消费,不过 Iceberg 社区正在issue 179上开发支持。
4.1.4、接口抽象程度和插件化

这里主要从计算引擎的写入和读取路径、底层存储可插拔、文件格式四个方面来作对比。这里 Iceberg 是抽象程度作得最好的数据湖方案,四个方面都作了很是干净的解耦。delta是databricks背后主推的,必须自然绑定spark;hudi的代码跟delta相似,也是强绑定spark。
存储可插拔的意思是说,是否方便迁移到其余分布式文件系统上(例如S3),这须要数据湖对文件系统API接口有最少的语义依赖,例如若数据湖的ACID强依赖文件系统 rename 接口原子性的话,就难以迁移到 S3 这样廉价存储上,目前来看只有Hive没有太考虑这方面的设计;文件格式指的是在不依赖数据湖工具的状况下,是否能读取和分析文件数据,这就要求数据湖不额外设计本身的文件格式,统一用开源的parquet和avro等格式。这里,有一个好处就是,迁移的成本很低,不会被某一个数据湖方案给绑死。
4.1.5、查询性能优化
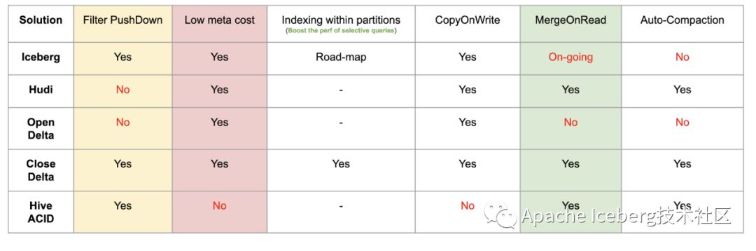
4.1.6、其余功能
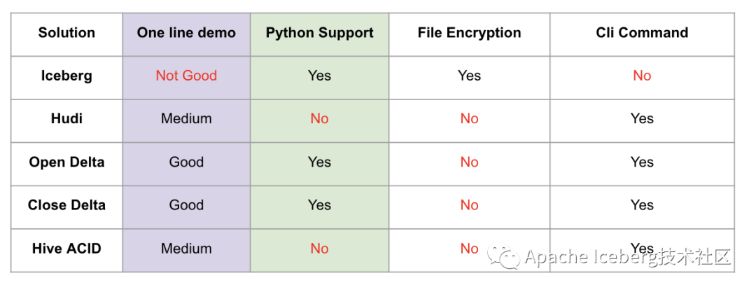
这里One line demo指的是,示例demo是否足够简单,体现了方案的易用性,Iceberg 稍微复杂一点(我认为主要是Iceberg本身抽象出了 schema,因此操做前须要定义好表的 schema)。作得最好的实际上是 delta,由于它深度跟随 spark 易用性的脚步。
Python支持实际上是不少基于数据湖之上作机器学习的开发者会考虑的问题,能够看到Iceberg和Delta是作的很好的两个方案。
出于数据安全的考虑,Iceberg 还提供了文件级别的加密解密功能,这是其余方案不曾考虑到的一个比较重要的点。
4.1.7、社区现状
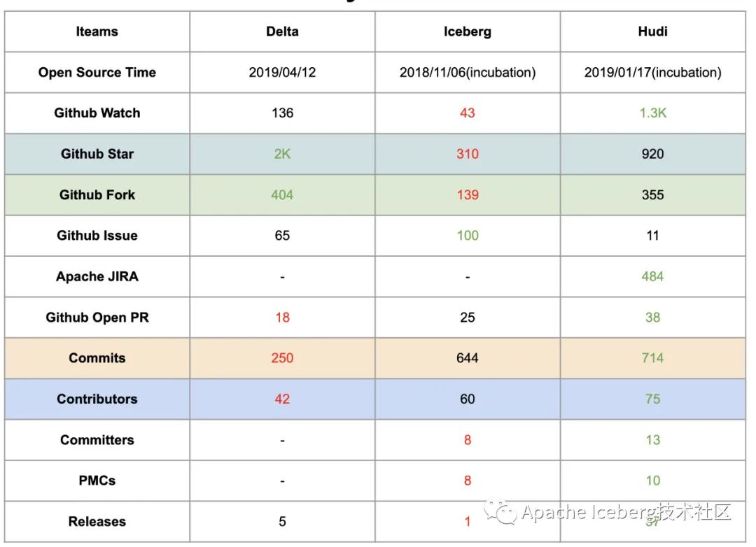
这里须要说明的是,Delta和Hudi两个项目在开源社区的建设和推进方面,做的比较好。Delta 的开源版和商业版本,提供了详细的内部设计文档,用户很是容易理解这个方案的内部设计和核心功能,同时Databricks还提供了大量对外分享的技术视频和演讲,甚至邀请了他们的企业用户来分享Delta的线上经验。
Uber的工程师也分享了大量Hudi的技术细节和内部方案落地,研究官网的近10个PPT已经能较为轻松理解内部细节,此外国内的小伙伴们也在积极地推进社区建设,提供了官方的技术公众号和邮件列表周报。
Iceberg 相对会平静一些,社区的大部分讨论都在 Github 的 issues 和 pull request 上,邮件列表的讨论会少一点,不少有价值的技术文档要仔细跟踪 issues 和 PR 才能看到,这也许跟社区核心开发者的风格有关。
五、总结
咱们把三个产品(其中 delta 分为 databricks 的开源版和商业版)总结成以下图:
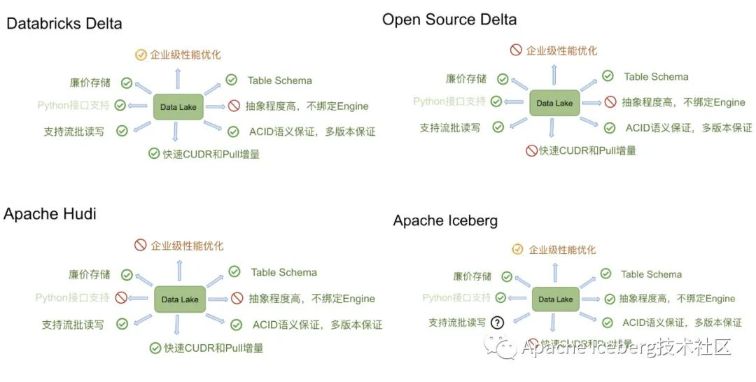
若是用一个比喻来讲明delta、iceberg、hudi、hive-acid四者差别的话,能够把四个项目比作建房子。因为开源的delta是databricks闭源delta的一个简化版本,它主要为用户提供一个table format的技术标准,闭源版本的 delta 基于这个标准实现了诸多优化,这里咱们主要用闭源的delta来作对比。
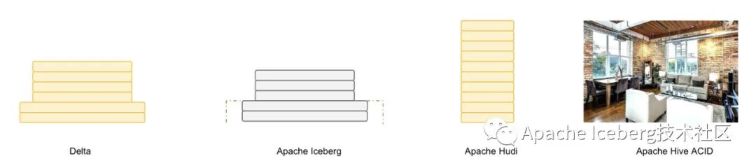
Delta的房子底座相对结实,功能楼层也建得相对比较高,但这个房子其实能够说是databricks的,本质上是为了更好地壮大Spark生态,在delta上其余的计算引擎难以替换Spark的位置,尤为是写入路径层面。
Iceberg的建筑基础很是扎实,扩展到新的计算引擎或者文件系统都很是的方便,可是如今功能楼层相对低一点,目前最缺的功能就是 upsert 和 compaction 两个,Iceberg 社区正在以最高优先级推进这两个功能的实现。
Hudi 的状况要相对不同,它的建筑基础设计不如 iceberg 结实,举个例子,若是要接入 Flink 做为 Sink 的话,须要把整个房子从底向上翻一遍,把接口抽象出来,同时还要考虑不影响其余功能,固然 Hudi 的功能楼层仍是比较完善的,提供的 upsert 和compaction 功能直接命中广大群众的痛点。
Hive的房子,看起来是一栋豪宅,绝大部分功能都有,把它作为数据湖有点像靠着豪宅的一堵墙建房子,显得相对重量级一点,另外正如 Netflix 上述的分析,细看这个豪宅的墙面是实际上是有一些问题的。
参考:
https://www.shangmayuan.com/a/a1b9f3ce84db45a6ab0e35d1.html
https://blog.csdn.net/u011598442/article/details/104403990
https://www.cnblogs.com/huaweiyun/p/13896955.html
http://hudi.apache.org/
http://iceberg.apache.org/#
以上是关于开源数据湖方案选型:HudiDeltaIceberg深度对比的主要内容,如果未能解决你的问题,请参考以下文章
深度对比 DeltaIceberg 和 Hudi 三大开源数据湖方案
数据湖09:开源框架DeltaLakeHudiIceberg深度对比