基于MaxCompute+PAI的用户增长方案实践
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于MaxCompute+PAI的用户增长方案实践相关的知识,希望对你有一定的参考价值。
简介: 如何通过PAI+MaxCompute完成用户增长模型AARRR全链路,包含拉新、促活、留存、创收、分享。
本文作者 李博 阿里云智能 高级产品专家
在过去一年阿里云PAI机器学习团队做了很多偏业务的实践,其中有一条就是基于 MaxCompute+PAI的产品方案实践,解决客户遇到用户增长相关的问题。本文主要分享,阿里云团队在用户增长领域的一些探索和实践。希望可以通过本次分享给大家在用户增长方面带来一些帮助。
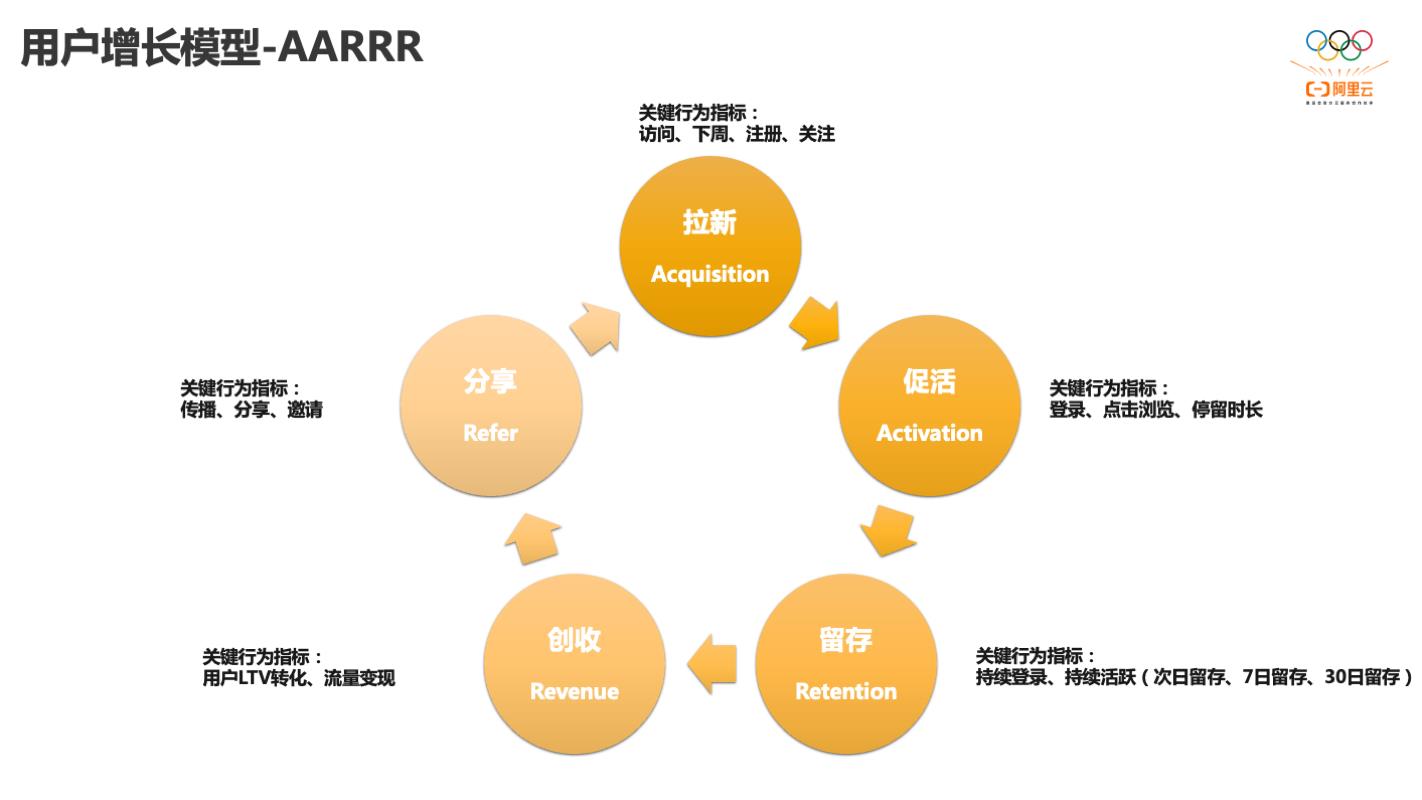
一、用户增长模型
AARRR
用户增长更多的是针对互联网类型的公司,互联网客户的业务本质上都是在解决用户增长的问题。用户增长从业务角度讲有很多的模型。今天主要针对AARRR用户增长模型进行讲解。
互联网APP运营同学应该是非常熟悉AARRR模型,这个模型是把整个互联网产品的用户增长做为一个环状结构,首先最上方是对业务比较重要的拉新,拉新对应到业务指标是访问、下载、注册、关注。之前几年拉新是非常火,是因为互联网用户红利还在。但现在中国互联网用户已经到了一个天花板,那我们的产品该如何增长,就对下面几部分尤为重要。比如现在小说类的APP是比较火的,因为当我们用户量不能增长的时候,做用户时长的增加尤为重要,所以小说业务有助于拉长用户在APP里面的停留时长。促活的指标是登录、点击浏览、停留时长。接下来就是留存,当我们没有办法获取新用户的时候,我们要尝试把我们的不活跃用户和流失用户召回。MaxCompute+PAI在留存方面有很多经典案例存在。互联网APP怎样基于流量和用户行为进行创收,这部分在AI领域也可以做很多工作。裂变型的APP会更加关注分享指标。
那在整个AARRR用户增长模型里面,MaxCompute+PAI能在哪个模块里面能做哪些工作?能给客户带来哪些价值?
MaxCompute+PAI业务支撑架构
MaxCompute+PAI做为底座支撑用户增长,产品架构如下图。
从计算引擎层是 MaxCompute,计算引擎之上就是AI的场景,我们重点介绍的是基于PAI机器学习的AI能力来赋能用户增长的业务场景。首先我们提供了开放框架,可以基于TensorFlow\\PYTorch,SQL\\PYSpark\\Spark开发自己的算法模型。再上面的产品层就是PAI机器学习的产品体系,整个产品体系也做为我们一个业务的支撑,包括PAI-DLC(云原生深度学习运行环境)可以把自己的code训练脚本打包成一个镜像包在DLC内运行、PAI-Studio(可视化建模)会将用户增长领域相关的算子做成模块化经过简单的拖拽,就可以来做整个用户增长的模型训练、PAI-DSW(交互式建模)对于技术能力比较强的开发者,可以自己开发相应的脚本,而不是使用我们封装好的脚本、PAI-EAS(模型在线服务)可以把studio和DSW生成的模型生成一个RESTful API,再通过HTTP请求的方式调用该服务。生成的RESTful请求就可以支撑解决方案,包括广告RTA解决方案、广告DSP方案、智能推荐方案、用户 召回方案、LTV计算方案。解决方案最终是要解决用户增长问题,包括拉新、促活、留存、创收、分享。

二、MaxCompute+PAI用户增长分类目详细方案
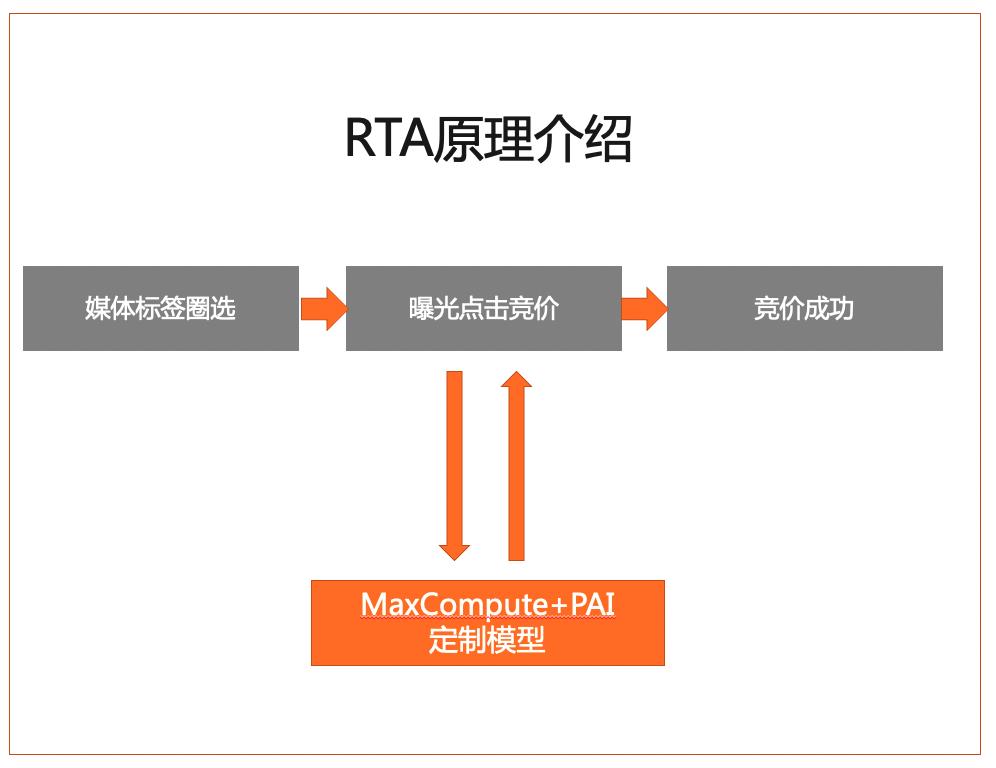
用户增长-拉新
当前通过广告拉新依然是互联网客户的一个核心重要的手段。在广告行业有一个比较流行的方案是RTA。在RTA方案里MaxCompute+PAI的作用是什么呢。首先看下RTA的原理,过去一个APP想要拉新用户,会把钱投放给DSP广告投放平台,由平台去圈选用户进行竞价。那RTA做了一件事情,就是当广告主希望能控制一些DSP人群,之前是没有办法的,在RTA技术支持下,开放一个接口,每一次广告平台在圈选用户时,会请求一个模型,这个模型的作用就是告诉平台,这个用户要不要。那MaxCompute+PAI就可以帮客户生成这样的模型。
通过MaxCompute做数据清理,通过PAI做竞价模型的训练,通过模型筛选值得投放的用户。
核心优势
1.强大的数据计算能力:MaxCompute提供PB级别的数据计算能力。
2.丰富的算法:PAI提供LR、GBDT等经典机器学习算法,同时也提供DeepFM、MultiTower等深度学习算法。
用户增长-促活
在新用户都比较少的情况下,我们希望存量客户能在我们平台上面浏览时长增加,更多的点击。打开一个互联网APP,70%以上的APP都有一个feed流推荐也可以叫相关性推荐,这个系统推荐率准确的高低是影响用户在平台上面的活跃度。如果推荐的内容都是用户喜欢看的,喜欢浏览的,会天然的增加平台上面的点击量,并且停留时长会增加。比如业内比较火的短视频APP,其实都是有比较好的个性化推荐系统。那么怎么基于MaxCompute+PAI构建一套推荐系统。如下图所示可以基于MaxCompute+PAI+DataWorks+Hologres+Flink做一套相关性推荐系统。更加具体信息可参考文章:PAI平台搭建企业级个性化推荐系统
做好一个推荐系统首先需要一个线上的服务模块,服务模块可以分为多路召回、过滤、排序、冷启动。召回模块是做一个粗筛,比如一个用户进来,我们平台存量有1000万个商品,拿这个用户跟1000万个商品去做比对,其实计算量非常大。那召回就是我先粗筛一下,比如选出几百个商品,这个时候我再做这个用户对这几百个商品的排序,整个计算的复杂性就会变的非常低。
那召回跟排序这两个模型怎么用MaxCompute+PAI训练出来?从架构图上来看,最底层我们要把用户的行为日志、用户画像数据、物料属性数据这三个核心的表,上传到MaxCompute中,利用DataWorks针对表做一个特征加工,加工出训练样本、用户特性数据、物料特征数据。接下来进入到PAI-Studio,一个内置的建模平台,里面内建了大量推荐领域的算法,比如PAI-EasyRec、GraphLearn、Alink。我们利用PAI-Studio里面的召回算法,生产一些基础的召回表,比如u2i、i2i、c2i,把这些结果放到Hologres里面,这个我们可以把多路召回服务跟Hologres做一个关联,解决了我们召回模型训练的问题。
排序服务可以在PAI-Studio里面选择排序算法,生产排序模型,排序模型可以部署到PAI-EAS里面,变成一个RESTful API,这样排序模块就可以请求排序模型的RESTful API,生产一个实时的排序结果返回。
经过我们的多路召回,把一些重复的商品过滤掉,在进行排序,就可以拿到一个TopN推荐列表。就可以展示到APP的feed流里面。那MaxCompute+PAI的价值就是完成整个排序业务的数据处理以及模型训练。这一整套相关性推荐系统,会有效提升我们APP里feed流的CTR、CVR的转化率,帮助APP提升用户的活跃度和停留时长。

用户增长-留存
当一个APP的存量用户做到百万、千万、上亿时,在数据库中存放大量历史用户,但是又有一段时间没有使用APP的用户。所以当下互联网拉新困难的情况下,我们需要对“沉睡”用户和流失用户做一个召回。当前互联网行业比较流行的方案还是通过短信召回,因为短信没有打电话的局限性,也不会像push那样被拦截。针对短信来讲,触达用户的效果和概率还是比较高的。
基于MaxCompute+PAI已经对很多行业用户,如小说、社交、游戏等行业,构建了流失用户短信召回解决方案。
大体的做法就是把用户埋点数据存到MaxCompute中,通过DataWorks做特征加工,用PAI机器学习平台训练一个流失用户召回模型,之后就可以针对已有的存量用户做一次预测,预测出哪些存量用户当用短信触达时,回到APP的概率比较高,这样我们就可以只针对这部分高概率用户进行短信召回,这样可以节省我们的召回成本,并且提升我们的召回率。
客户案例
客户为一家陌生人社交APP,库内有近千万级别的沉睡用户。通过短信实现流失用户的召回。
PAI核心价值:
用了PAI之后百万条短信召回比例从3%提升至8%,效果提升267%,变相降低成本2倍左右。

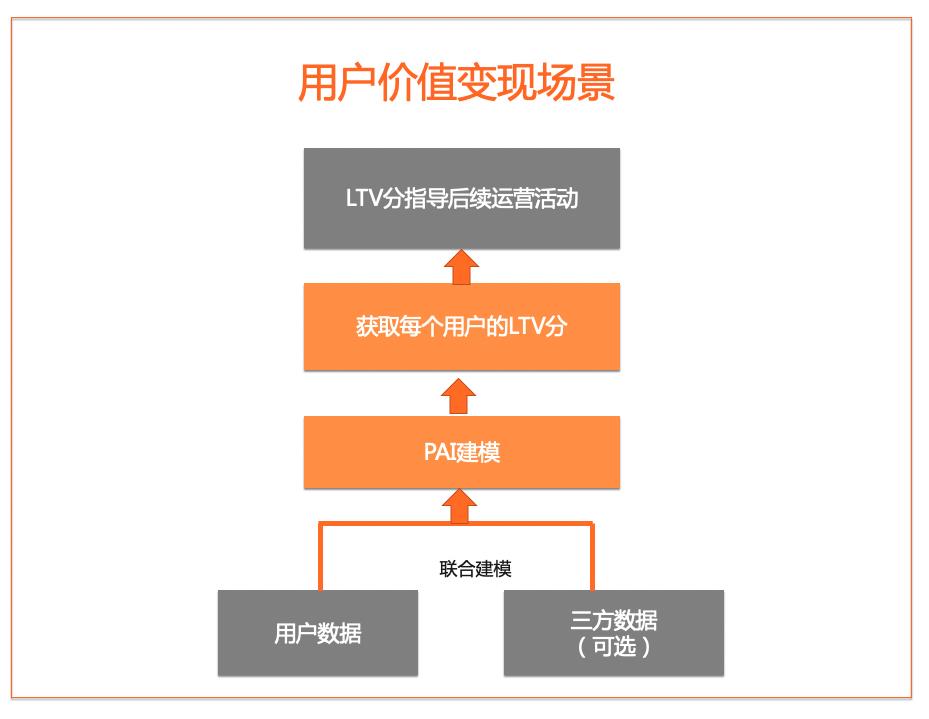
用户增长-LTV分计算&分享分计算
通过PAI+MaxCompute构建分数预测模型,可以对LTV分、分享概率分进行预测。
当APP通过广告带来一个用户时,都会关心这个用户会不会付费,或者说产生的APP值有多少。有的客户需要在新用户进来的同时,计算出未来这个用户在APP上的消费情况是多少。如果这个用户是一个高价值用户,那就需要通过优惠券或者补贴的的方式来进行用户激活。我们提供了LTV方案,举个例子,比如一个APP的新用户,我们怎么计算他的LTV分呢?
找一个第三方的数据源,因为新用户在APP内还没有任何行为日志产生。MaxCompute+PAI会提供一套联合建模的方案,符合可信计算标准。也就是说用户数据和第三方数据不会有任何接触,两方数据可以联邦建模,在PAI内生成模型,这个模型可以对每一个新用户进行LTV打分,针对LTV分指导后续运营活动。
客户案例
场景介绍:客户是一家小说平台,对于纯新用户,需要做30天内购买VIP服务的预测。以便在用户还几乎没有什么行为时,能够对用户未来购买VIP的行为进行预测,可以让新用户运营有的放矢,提高运营效率。
对于纯新用户购买VIP判断准确率提升明显,圈选出40%左右的用户作为训练数据,联邦建模生成的模型就可以将67%的会自然购买VIP的会员识别出来,提高67.5%的运营效率(和随机圈选用户进行比较)。
三、实操介绍-流失用户召回
数据上传到MaxCompute
通过MaxCompute的Tunnel命令上传数据到项目中:tunnelupload{file}{table};
文档链接:https://help.aliyun.com/document_detail/196187.html
构建Workflow
进入PAI-Studio完成workflow的构建。

构建训练样本:7天不登录的作为流失用户
通过筛选注册日期和最后一次登录时间可以确定哪些用户是7天不登录用户。
特征加工
通过加工把数据变成结构化数据。
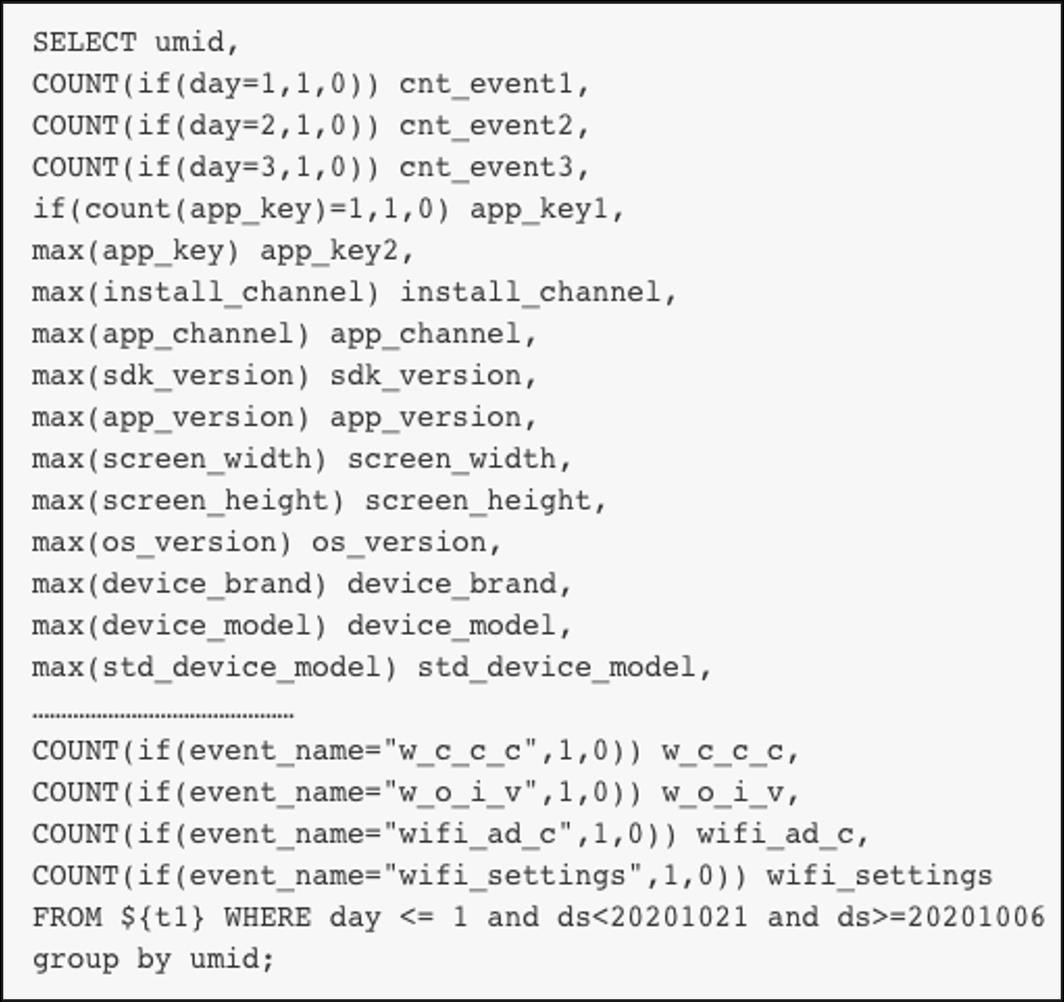
One-hot编码
One-Hot编码可以将类别变量转换为机器学习算法易于使用的形式,经过One-Hot转换后的格式如下图所示。

模型训练和评估
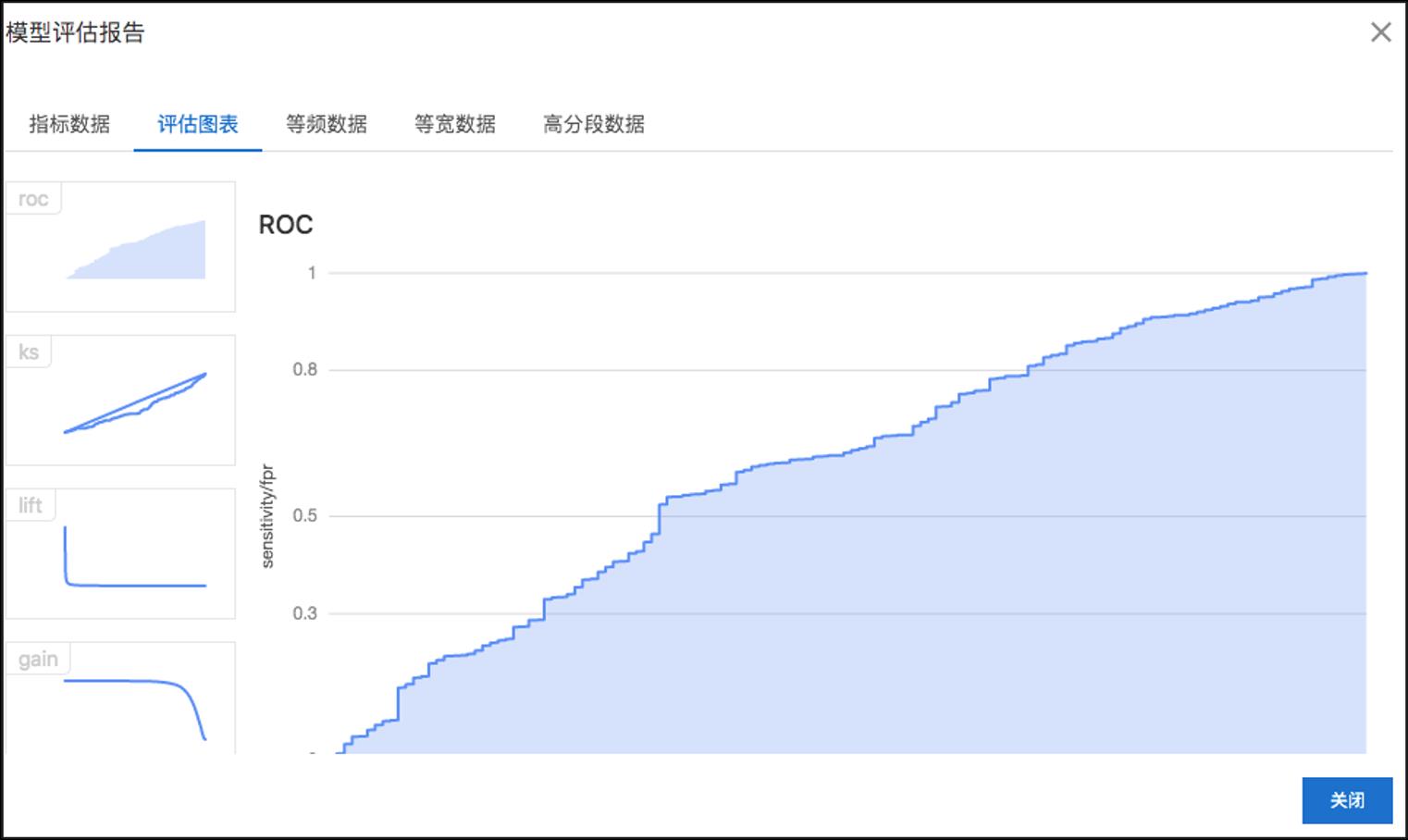
进行逻辑回归的模型训练,PAI平台上有几十种的分类模型,判断发短信是否能召回可以定义为二分类问题,yes/no。可以使用二分类算法,进行模型训练。逻辑模型训练完后,我们把一部分数据做为测试数据,就能获取到模型效果。我们在二分类评估下面生成一个模型评估报告。ROC值的面积越大说明模型效果越好。
模型预测
生成完模型后,我们可以把模型部署成RESTful服务,供业务方或者是运营同学去调用。调用格式如下图所示:

原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是关于基于MaxCompute+PAI的用户增长方案实践的主要内容,如果未能解决你的问题,请参考以下文章
基于MaxCompute+开放搜索的电商零售行业搜索开发实践