简单了解unordered_set和unordered_map底层
Posted 两片空白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了简单了解unordered_set和unordered_map底层相关的知识,希望对你有一定的参考价值。
目录
前言:
unordered_set和unordered_map底层都是由哈希表实现的,想了解哈希表的小伙伴可以看下一这篇博客哈希表(散列表)介绍。由于解决哈希冲突的方式开散列比闭散列更优。所以使用开散列的来实现哈希表。
一.哈希表(开散列)实现
1.1 介绍模板参数
//K:关键码
//T:保存数据,unordered_map是一个键值对,unordered_set是K
//KOFT:由于unordered_map和unordered_set保存值不同,KOFT是一个仿函数,取出关键码。。
//HASH:仿函数,将关键码Key不是整形类型转成整形。
//模板参数是由unordered_set和unordered_map传入的
template<class K, class T, class KOFT, class HASH>
class HashTable;1.2 代码实现
#pragma once
#include<iostream>
#include<vector>
using namespace std;
namespace CLOSE_TABLE{
enum State{
EXIT,
DELETE,
EMPTY,
};
//kv模型,KOFT是去出key的仿函数
template<class K, class T, class KofT>
class HashTable
{
public:
bool insert(const T& data){
//扩容
if (_ht.capacity() == 0 || _num * 10 / _ht.capacity() >= 7){
int newcapacity = (_ht.capacity() == 0 ? 10 : 2 * _ht.capacity());
HashTable<K, T, KofT> newht;
//size就是capacity
newht._ht.resize(newcapacity);
for (size_t i = 0; i < _ht.size(); i++){
if (_ht[i]._state == EXIT){
newht.insert(_ht[i]._data);
}
}
_ht.swap(newht._ht);
_num = newht._num;
}
KofT koft;
int i = 1;
int start = koft(data) % _ht.capacity();
size_t index = start;
while (_ht[index]._state != EMPTY){
if (koft(_ht[index]._data) == koft(data)){
return false;
}
//index++;
index = (start + i*i) % _ht.capacity();
i++;
if (index >= _ht.capacity()){
index = 0;
}
}
_ht[index]._data = data;
_ht[index]._state = EXIT;
_num++;
return true;
}
int find(const T& data){
KofT koft;
int index = koft(data) % _ht.capacity();
if (koft(_ht[index]._data) != koft(data)){
while (_ht[index]._state != EMPTY){
index++;
if (koft(_ht[index]._data) == koft(data)){
return index;
}
}
}
return index;
}
bool erase(const T& data){
KofT koft;
int index = find(data);
if (koft(_ht[index]._data) == koft(data)){
_ht[index]._state = DELETE;
_num--;
return true;
}
return false;
}
public:
struct Ele{
T _data;
State _state = EMPTY;
};
private:
vector<Ele> _ht;//数组里保存的是数据和状态
size_t _num = 0;//元素个数
};
}
namespace OPEN_TABLE{
//结点
template<class T>
struct HashNode{
HashNode(const T& data)
:_next(nullptr)
, _data(data)
{}
T _data;
HashNode *_next;
};
//装整形的类,默认整形,直接返回
template<class K>
struct hash{
int operator()(const K& k){
return k;
}
};
//特化string转int类型
template<>
struct hash<string>
{
int operator()(const string& s){
int hash = 0;
for (size_t i = 0; i < s.size(); i++){
hash *= 131;
hash += s[i];
}
return hash;
}
};
//声明,哈希桶类,定义在后面,需要在前面声明,迭代器才可以使用
template<class K, class T, class KOFT, class HASH >
class HashTable;
//迭代器
template<class K, class T, class KOFT, class HASH>//由于有哈希桶指针,所以也需要相同模板参数
struct _Iterator{
typedef HashNode<T> Node;
typedef HashTable<K, T, KOFT, HASH> HashTable;
typedef _Iterator<K, T, KOFT, HASH > Self;
Node *_node;
//方便找下一个哈希桶,指向哈希表
HashTable *_h;
_Iterator(Node *node,HashTable *h)
:_node(node)
, _h(h)
{}
Self operator++(){
HASH hash;
KOFT koft;
//下一个结点存在,返回下一个位置迭代器
if (_node->_next){
_node = _node->_next;
return _Iterator(_node->_next, _h);
}
//下一个结点不存在,返回哈希表中,找下一个哈希桶
else{
//求出当前迭代器在哈希表中的位置
size_t index = hash(koft(_node->_data)) % _h->_ht.capacity();
//下一个位置
index++;
for (; index < _h->_ht.capacity(); index++){
if (_h->_ht[index]){
_node = _h->_ht[index];
return _Iterator(_node, _h);
}
}
_node = nullptr;
return _Iterator(_node, _h);
}
}
T& operator*(){
return _node->_data;
}
T* operator->(){
return &(_node->_data);
}
bool operator!=(const Self& it){
return _node != it._node;
}
bool operator==(const Self& it){
return _node == it._node;
}
};
template<class K,class T,class KOFT,class HASH>
class HashTable{
//找下一个哈希桶会访问到哈希表的成员变量(私有),设置成友元
friend _Iterator<K, T, KOFT, HASH>;
typedef HashNode<T> Node;
public:
//迭代器
typedef _Iterator<K, T, KOFT, HASH> Iterator;
~HashTable(){
clean();
//vector会自己销毁
}
void clean(){
for (size_t i = 0; i < _ht.capacity(); i++){
Node *cur = _ht[i];
if (cur){
while (cur){
Node *next = cur->_next;
delete cur;
cur = next;
}
}
_ht[i] = nullptr;
}
}
Iterator begin(){
//找第一个不是空的结点
Node *cur = nullptr;
for (size_t i = 0; i < _ht.capacity(); i++){
cur = _ht[i];
if (cur){
break;
}
}
return Iterator(cur, this);
}
Iterator end(){
return Iterator(nullptr, this);
}
pair<Iterator,bool> Insert(const T& data)
{
HASH hash;//转整形
KOFT koft;//取出key
//检查扩容
if (_num == _ht.capacity()){
//新容量
int newcapacity = _ht.capacity() == 0 ? 10 : _ht.capacity() * 2;
//建立新指针数组,来保存链表头节点
vector<Node *> newht;
newht.resize(newcapacity);
//将旧数组里的链表结点,放到新数组中
for (size_t i = 0; i < _ht.capacity(); i++){
Node *cur = _ht[i];
while (cur){
//重新确定保存位置,可以减少冲突
int index = hash(koft(cur->_data)) % newcapacity;
//不用新创立结点,直接将旧结点重新链到新数组中
Node *next = cur->_next;
cur->_next = newht[index];
newht[index] = cur;
cur = next;
}
_ht[i] = nullptr;//防止野指针
}
//不需要交换_num,_num没变,HashTable没变,变的是里面的数组
_ht.swap(newht);
}
//插入位置
int index = hash(koft(data)) % _ht.capacity();
//检查是否存在。
Node *cur = _ht[index];
while (cur){
if (koft(cur->_data) == koft(data)){
return pair<Iterator, bool>(Iterator(cur,this), false);
}
cur = cur->_next;
}
//插入结点
Node *newnode = new Node(data);
newnode->_next = _ht[index];
_ht[index] = newnode;
_num++;
return pair<Iterator, bool>(Iterator(newnode,this), true);
}
Node *find(const T& data){
HASH hash;
KOFT koft;
int index = hash(koft(data)) % _ht.capacity();
Node *cur = _ht[index];
while (cur){
if (koft(cur->_data) == koft(data)){
return cur;
}
cur = cur->_next;
}
return nullptr;
}
bool erase(const T& data){
KOFT koft;
HASH hash;
//求位置
int index = hash(koft(data)) % _ht.capacity();
Node *prev = nullptr;//保存cur的前一个结点,方便删除
Node *cur = _ht[index];
//找结点
while (cur&&koft(cur->_data) != koft(data)){
prev = cur;
cur = cur->_next;
}
//删除结点
if (cur){
if (prev){//不是头节点
prev->_next = cur->_next;
}
else{//是头节点
_ht[index] = cur->_next;
}
delete cur;
}
return false;
}
private:
vector<Node *> _ht;
size_t _num = 0;
};
}
二.迭代器
这里实现的迭代器的++,是在哈希桶中找到第一个桶的,遍历完桶的结点,再找下一个桶遍历。
由于当遍历完当前桶要找下一个桶的位置。迭代器中还需要添加一个哈希桶指针,指向当前哈希桶。
实现operator++操作:
1. 如果当前结点下一个结点不为空,走向下一个结点。
2.如果当前结点的下一个结点为空,找到当前结点在哈希桶中的位置(利当前结点的值和哈希函数求出)。再在哈希桶里找下一个桶。这里会访问到哈希桶的成员变量(私有),需要将迭代器设为哈希桶的友元类。
由于unordered_setheunordered_map无反向迭代器,所以不需要operator--
//声明,哈希桶类,定义在后面,需要在前面声明,迭代器才可以使用
template<class K, class T, class KOFT, class HASH >
class HashTable;
//迭代器
template<class K, class T, class KOFT, class HASH>//由于有哈希桶指针,所以也需要相同模板参数
struct _Iterator{
typedef HashNode<T> Node;
typedef HashTable<K, T, KOFT, HASH> HashTable;
typedef _Iterator<K, T, KOFT, HASH > Self;
Node *_node;
//方便找下一个哈希桶,指向哈希表
HashTable *_h;
_Iterator(Node *node,HashTable *h)
:_node(node)
, _h(h)
{}
Self operator++(){
HASH hash;
KOFT koft;
//下一个结点存在,返回下一个位置迭代器
if (_node->_next){
_node = _node->_next;
return _Iterator(_node->_next, _h);
}
//下一个结点不存在,返回哈希表中,找下一个哈希桶
else{
//求出当前迭代器在哈希表中的位置
size_t index = hash(koft(_node->_data)) % _h->_ht.capacity();
//下一个位置
index++;
for (; index < _h->_ht.capacity(); index++){
if (_h->_ht[index]){
_node = _h->_ht[index];
return _Iterator(_node, _h);
}
}
_node = nullptr;
return _Iterator(_node, _h);
}
}
T& operator*(){
return _node->_data;
}
T* operator->(){
return &(_node->_data);
}
bool operator!=(const Self& it){
return _node != it._node;
}
bool operator==(const Self& it){
return _node == it._node;
}
};三.HASH转整形的类
在该代码放在了哈希桶所在文件中(为了比用在unordered_set和unordered_map中都需要编写代码),缺省有直接是整形和string类型的模板特化。
//装整形的类,默认整形,直接返回
template<class K>
struct hash{
int operator()(const K& k){
return k;
}
};
//特化string转int类型
template<>
struct hash<string>
{
int operator()(const string& s){
int hash = 0;
for (size_t i = 0; i < s.size(); i++){
hash *= 131;
hash += s[i];
}
return hash;
}
};如果不是这两种,则需要在用户自己编写,传入模板参数。
四.unordered_map简单实现
这里只是简单实现了迭代器,插入和operator[]。
如想实现查找,删除,可直接调用哈希用的查找和删除,只需要改变返回值类型。
#pragma once
#include"HashTable.h"
using namespace OPEN_TABLE;
namespace wy{
template<class K, class T, class HASH = OPEN_TABLE::hash<K>>
class unordered_map{
private:
struct MapKofT{
const K& operator()(const pair<K,T>& data){
return data.first;
}
};
//typedef _Iterator<K, pair<K, T>, MapKofT, hash> iterator;
typedef HashNode<T> Node;
public:
typedef typename HashTable<K, pair<K, T>, MapKofT, OPEN_TABLE::hash<K>>::Iterator iterator;
iterator begin(){
return _table.begin();
}
iterator end(){
return _table.end();
}
T& operator[](const K& k){
pair<iterator, bool> res = _table.Insert(make_pair(k, T()));
return res.first->second;//res是迭代器->,吊桶迭代器operator->
}
pair<iterator, bool> insert(const pair<K, T>& data){
return _table.Insert(data);
}
private:
HashTable<K, pair<K, T>, MapKofT, HASH> _table;
};
}
五.unordered_map简单实现
#pragma once
#include"HashTable.h"
using namespace OPEN_TABLE;
namespace wy{
template<class K, class HASH = OPEN_TABLE::hash<K>>
class unordered_set{
private:
struct SetKofT{
const K& operator()(const K& k){
return k;
}
};
public:
typedef typename HashTable<K, K, SetKofT, OPEN_TABLE::hash<K>>::Iterator iterator;
iterator begin(){
return _table.begin();
}
iterator end(){
return _table.end();
}
pair<iterator, bool> insert(const K& k){
return _table.Insert(k);
}
private:
HashTable<K, K, SetKofT, HASH> _table;
};
}六.验证
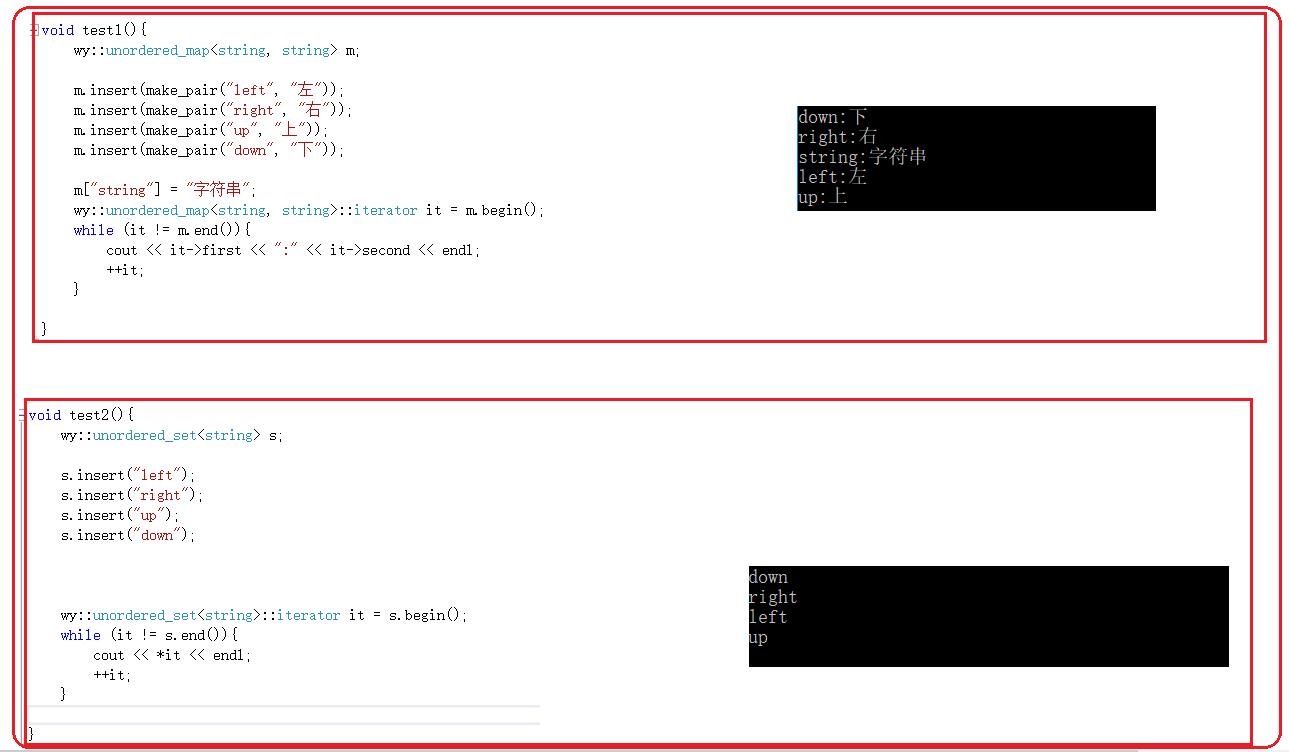
注意:stl库中遍历时是按插入顺序的方式遍历的,这样的话该怎么设计呢?(了解,整形是这样)
在结点中增加两个指针,一个指针linknext,指向下一个插入结点,遍历按照这个指针指向方向遍历即可。一个指针linkprev指向上一个结点,方便删除。
这样的话,插入和删除可能麻烦一些。
以上是关于简单了解unordered_set和unordered_map底层的主要内容,如果未能解决你的问题,请参考以下文章