哈量数据处理面试题(哈希切割,位图,布隆过滤器)
Posted 两片空白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了哈量数据处理面试题(哈希切割,位图,布隆过滤器)相关的知识,希望对你有一定的参考价值。
目录
前言
海量数据处理,顾名思义。就是数据两很大,内存不足以保存这么多数据的问题该如何解决。
一般可以使用位图(整形),布隆过滤器(非整形),哈希切割的方法。
一.位图应用
- 给定100亿个整数,设计算法找到知出现一次的整数?
首先估算,100亿整数保存需要多少空间?1个整数4字节,100亿整数400亿字节。1G10亿字节,所以这里差不多要10G。内存无法将数据全部保存,只能将数据保存在硬盘中。
这里该如何计算呢?
方案一:我们可以使用位图,一般的位图用一位来表示一个数组是否存在。但是这里需要找出知出现一次的整数。这里仔细分析,有三种状态,存在,存在只出现一次和存在出现多次。我们可以在位图种用两个位来表示一个整数的状态,(00表示不存在,01表示存在且只出现一次,11表示存在且出现多次)。无符号整形的最大范围为2^32-1(42亿多),100亿个整数,肯定有很大重复的值。位图只需要开空间2*(2^32-1)个位,差不多1G空间。
方案二:还是用上面的思想,但是不是在一个位图种。定义两个位图,它们的哈希函数一样,两位图同一位置,一个位图是高位,一个位图是低位。依旧是00表示不存在,01表示存在且只出现一次,11表示存在且出现多次。
- 给定100亿个整数,1G内存,设计算法找到知出现不超过两次的整数?
上面题目的变形,情况相同还是用两位状态00表示不存在,01表示存在一次,10表示存在两次,11表示存在两次以上。
- 给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件的交集?
方案一:假设两个文件一个是文件A,一个是文件B。将文件A数据映射到位图种,需要消耗500M内存。读取文件B中的数据,在位图中找存不存在。
方案二:将文件A映射到位图中,将文件B映射到位图中。然后将两位图按位&,得到的位图,再按照哈希函数反推到交集数据。
位图保存的是整形,是直接定址法,不会有哈希冲突。
二.布隆过滤器
- 给两个文件,分别由100亿个query(query是sql的查询语句或者是网络请求url,一般是字符串),我们只有1G内存,如何找到交集?给出精确算法和近似算法。
首先由于query是字符串,不能使用位图,得使用布隆过滤器。
分析一个100亿个query占多少空间?一般一个query占30~60字节,100亿query大概占用300~600G内空间。内存无法保存。
方案一(近似算法):假设两个文件分别是文件A和文件B,用一个布隆过滤器保存文件A的数据,字符串转换函数将字符串转为整形,整形最多大范围也只有42亿多,所以布隆过滤器只需要开500M左右空间。再将文件B保存到布隆过滤器中,两布隆过滤器按位&,得到交集。
但是这样会有一个缺陷:就是不同的query通过几个字符串转换函数可能会得到相同的值,会导致交集里出现不是交集的query。交集数据不准确。
方案二(精确算法):利用分割 + 红黑树
首先将文件A和文件B分割成n个内存可以放下的文件。比如上面大概占用300G~600G,将文件A和文件B分割成1000个小文件,每一个小文件大概占用300~600M,可以保存在内存中。
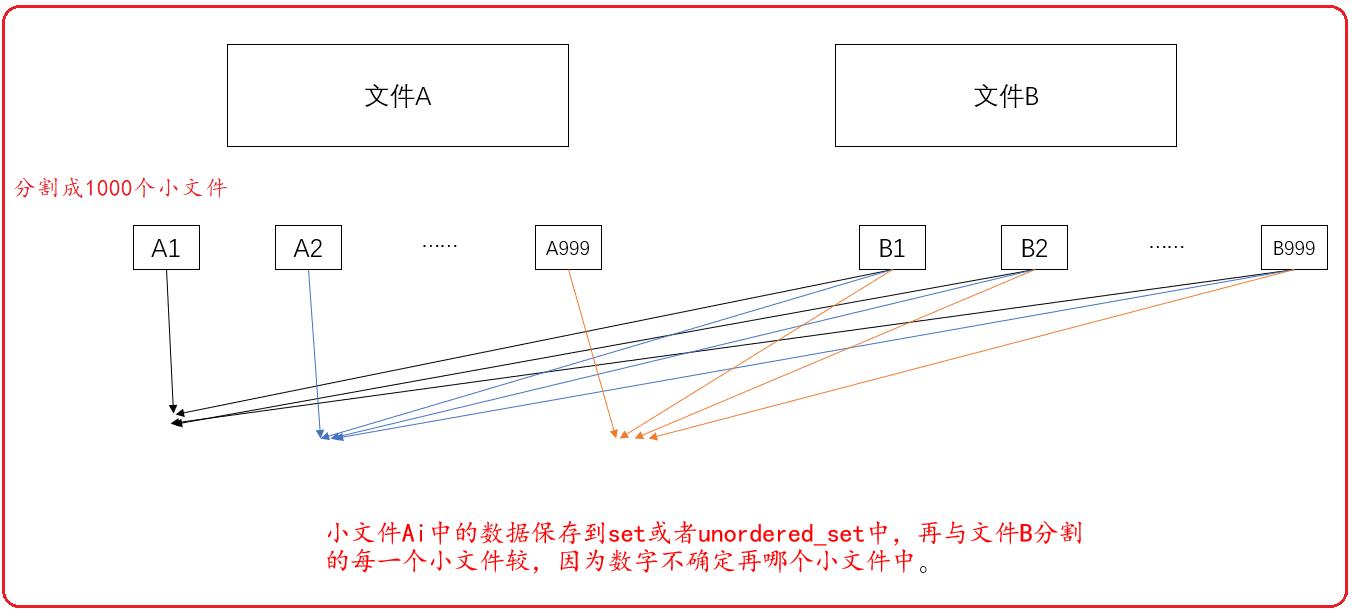
再将文件A中的一个小文件中保存到set或者unordered_set中,再将文件B中的每一个小文件与set或者unordered_set中的数据比较,找交集。再保存文件A中的另一个小文件保存到set或者unordered_set中,再将文件B中的每一个小文件与set或者unordered_set中的数据比较,找交集。如此,可以得到交集。
此时需要文件A的一个小文件,都和文件B的每一个小文件比较。
方案三(精确算法):利用哈希分割 + 红黑树
依旧是将文件A和文件B分割成n个小文件,这里分割成1000个小文件。每个文件就是300~600M。
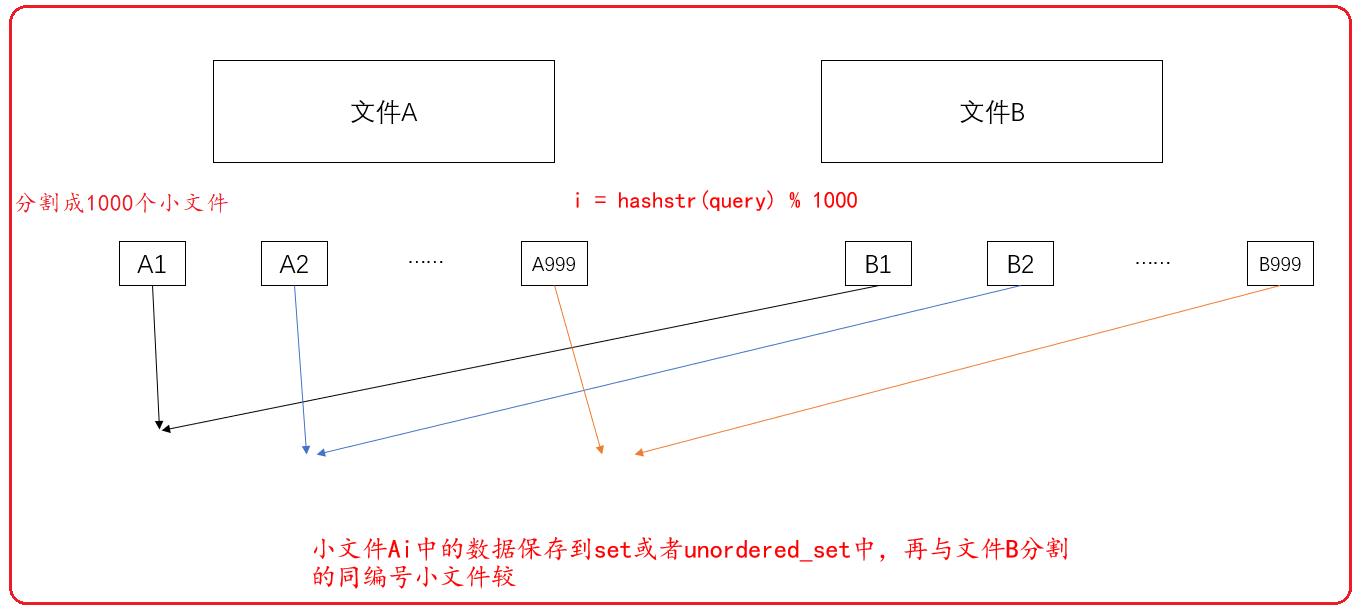
利用哈希分割:利用哈希字符串转整形函数:i = hashstr(query) % n,hashstr是字符串转整形函数,query是文件A和文件B中的query。n是文件个数,这里是1000。求出来的i是将对应的query保存到对应第i个文件中。
文件A和文件B求query放到哪个文件的hashstr用的是同一个。这时通过hashstr求出来的相同的值一定在A和B同一个编号小文件中,也就是Ai和Bi中。
文件A和文件B的交集一定都保存到了同样编号的小文件中,其中可能也保存了不是交集的值。
此时将小文件Ai保存到set中,只需要和对应小文件Bi比较皆可,不需要和文件B的每一个小文件比较。
- 如何扩展布隆过滤器使它支持删除操作?
通过使用计数器,使用多个位来表示一个计数器。1个位可以表示0和1,2个位表示0~3,3个位表示0~7.....
但是使用空间过小,如使用一字节最多表示256个数,当多余256时,就溢出了。但是使用空间过大,布隆过滤器就没有优势了。
使用多少位取决于会重复多少数据。建议使用两个字节大小,也就是16个位。
三.哈希切割
- 给一个超过100G的log file(日志文件),log里保存着IP地址,设计一算法找出出现次数最多的IP?与上题想同找到top K IP?
利用哈希切割,先将log file分割成多个小文件。分割的小文件只要可以保存到内存即可。假设我这里分割成1000个小文件,每个文件最小100M。
在将每个小文件的IP保存到map<string,int>中来进行计数,设置一个遍历pair<string,int> max,来保存每个小文件中出现次数最多的键值对。就可以得到出现次数最多的IP。
以上是关于哈量数据处理面试题(哈希切割,位图,布隆过滤器)的主要内容,如果未能解决你的问题,请参考以下文章