这40个Python可视化图表案例,强烈建议收藏!
Posted Python学习与数据挖掘
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这40个Python可视化图表案例,强烈建议收藏!相关的知识,希望对你有一定的参考价值。
原文:https://mp.weixin.qq.com/s/Dibp-nysRivcVsizPQfmeg
欢迎关注 ,专注Python、数据分析、数据挖掘、好玩工具!
大家好,数据可视化是数据科学中关键的一步。在以图形方式表现某些数据时,Python能够提供很大的帮助。不过有些小伙伴也会遇到不少问题,比如选择何种图表,以及如何制作,代码如何编写,这些都是问题!
今天给大家介绍一个 Python 图表大全,40个种类,总计约400个示例图表。 分为7个大系列,分布、关系、排行、局部整体、时间序列、地理空间、流程。欢迎收藏学习,喜欢点赞支持。

文档地址
https://www.python-graph-gallery.com
GitHub地址
https://github.com/holtzy/The-Python-Graph-Gallery
文中代码领取方式:
代码已打包,获取方法有两种:
- 方式一、发送如下图片至微信,进行长按识别,后台回复:20210912;
- 方式二、微信搜索公众号:Python学习与数据挖掘,后台回复:20210912

给大家提供了示例及代码,几分钟内就能构建一个你所需要的图表。
下面就给大家介绍一下~
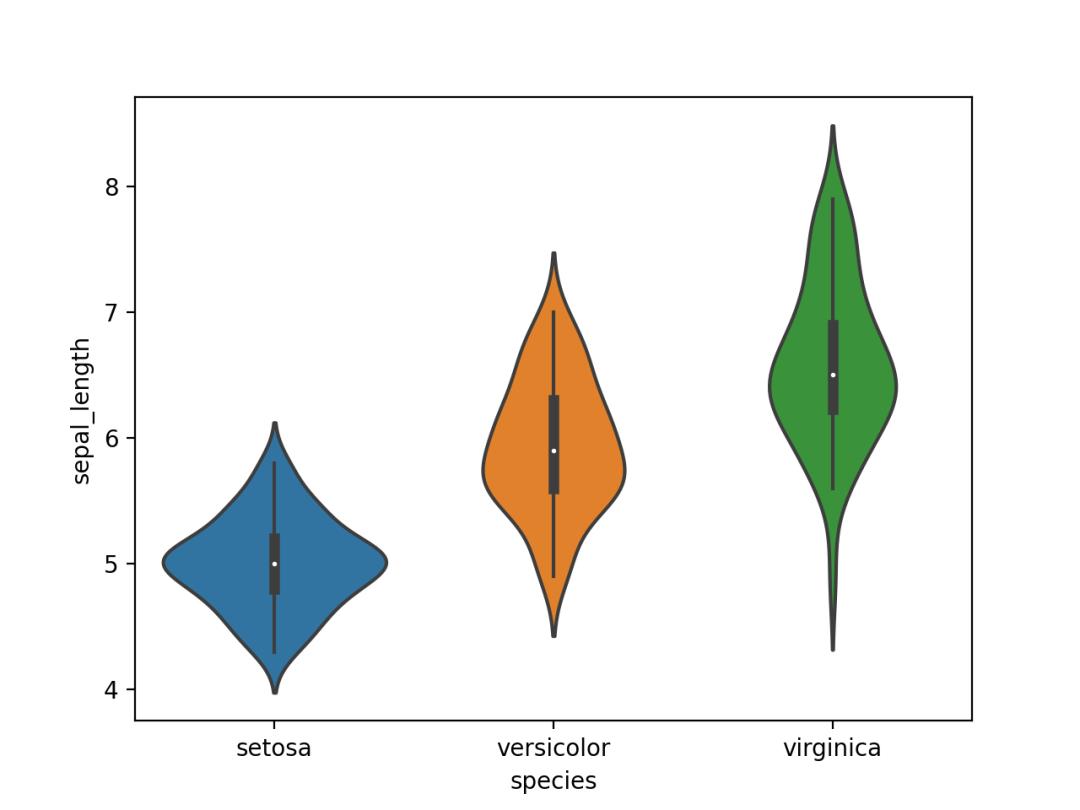
01. 小提琴图
小提琴图可以将一组或多组数据的数值变量分布可视化。
相比有时会隐藏数据特征的箱形图相比,小提琴图值得更多关注。
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
df = sns.load_dataset('iris', data_home='seaborn-data', cache=True)
# 绘图显示
sns.violinplot(x=df["species"], y=df["sepal_length"])
plt.show()
使用Seaborn的violinplot()进行绘制,结果如下。
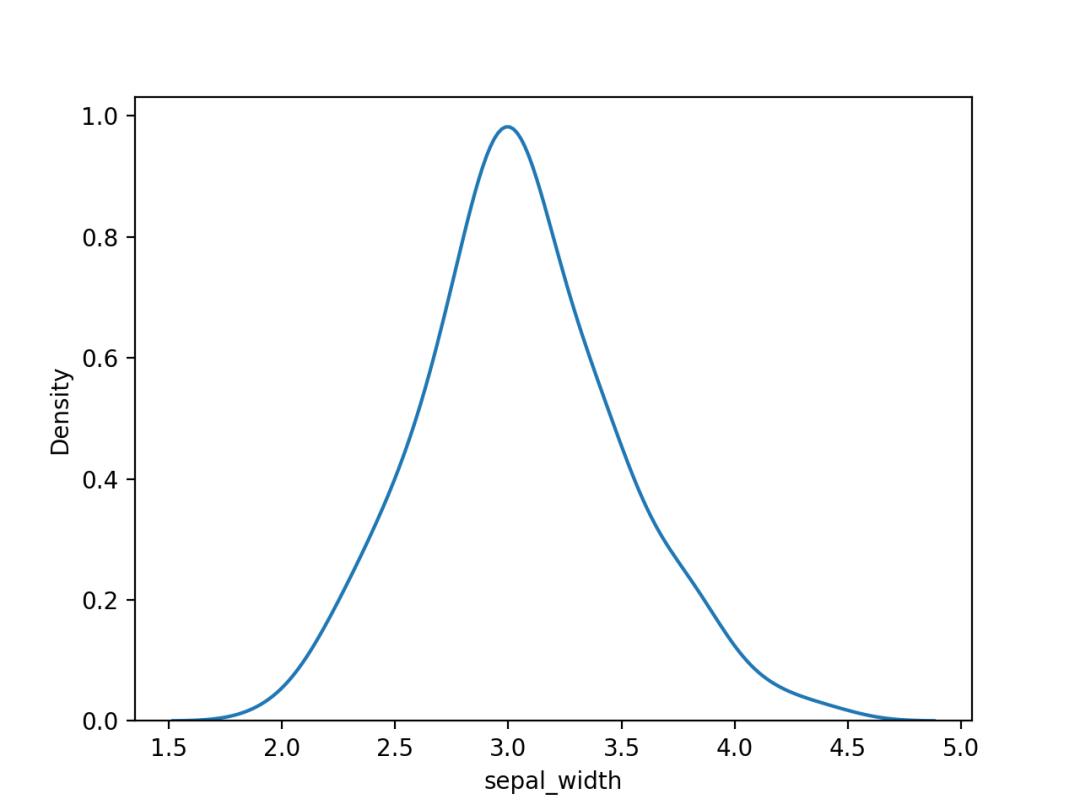
02. 核密度估计图
核密度估计图其实是对直方图的一个自然拓展。
可以可视化一个或多个组的数值变量的分布,非常适合大型数据集。
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
df = sns.load_dataset('iris', data_home='seaborn-data', cache=True)
# 绘图显示
sns.kdeplot(df['sepal_width'])
plt.show()
使用Seaborn的kdeplot()进行绘制,结果如下。
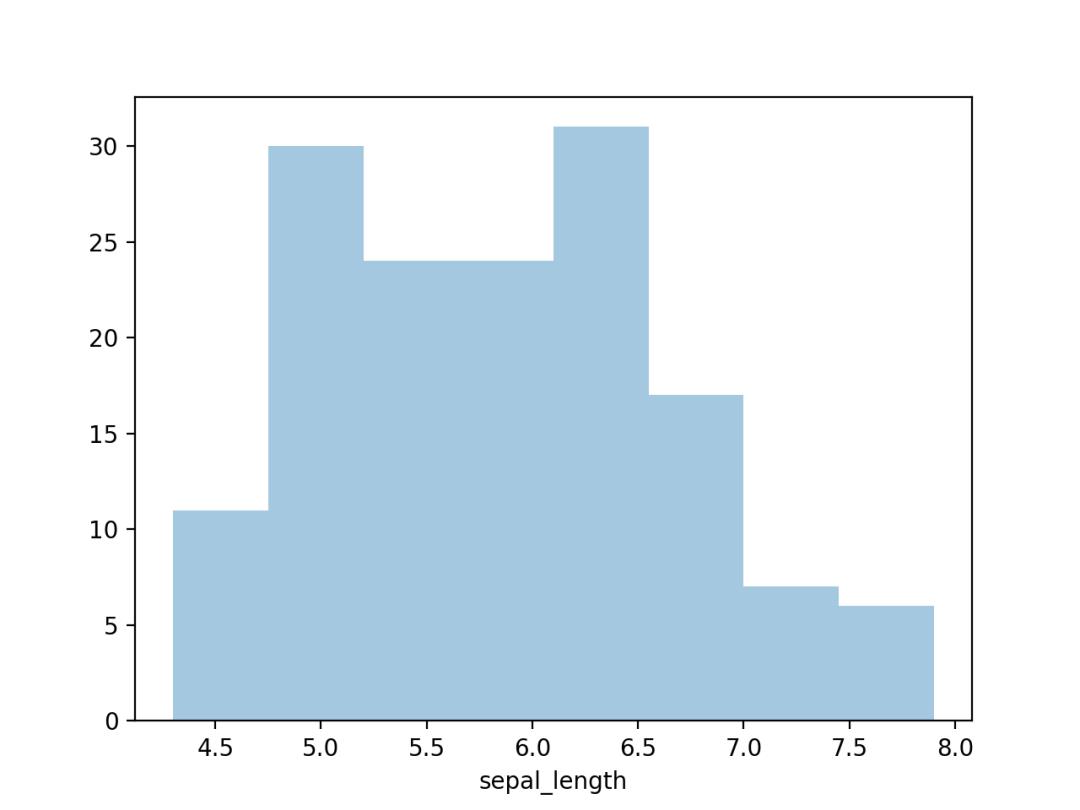
03. 直方图
直方图,可视化一组或多组数据的分布情况。
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
df = sns.load_dataset('iris', data_home='seaborn-data', cache=True)
# 绘图显示
sns.distplot(a=df["sepal_length"], hist=True, kde=False, rug=False)
plt.show()
使用Seaborn的distplot()进行绘制,结果如下。
04. 箱形图
箱形图,可视化一组或多组数据的分布情况。
可以快速获得中位数、四分位数和异常值,但也隐藏数据集的各个数据点。
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
df = sns.load_dataset('iris', data_home='seaborn-data', cache=True)
# 绘图显示
sns.boxplot(x=df["species"], y=df["sepal_length"])
plt.show()
使用Seaborn的boxplot()进行绘制,结果如下。

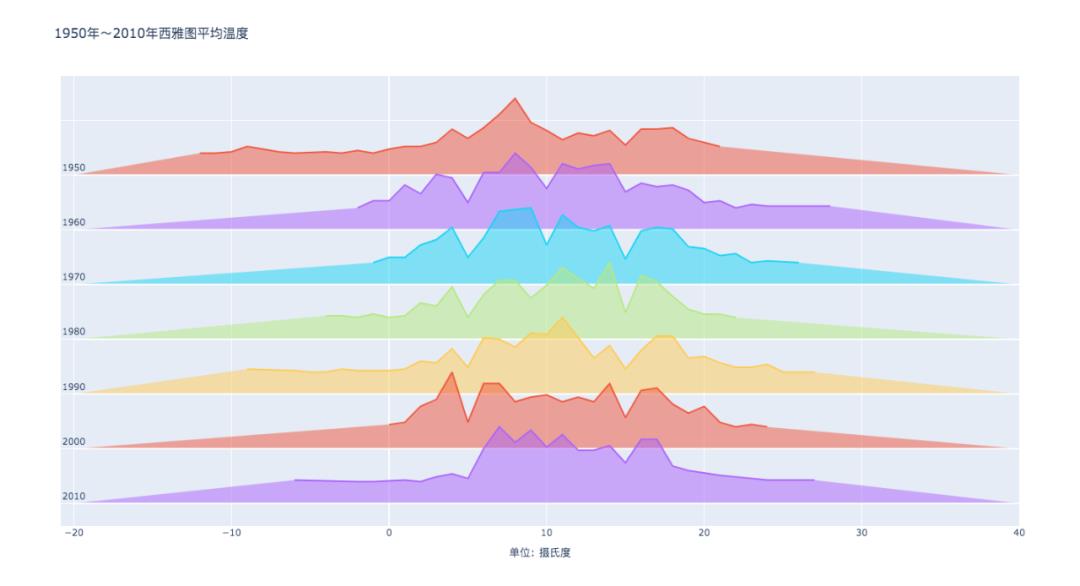
05. 山脊线图
山脊线图,总结几组数据的分布情况。
每个组都表示为一个密度图,每个密度图相互重叠以更有效地利用空间。
import plotly.graph_objects as go
import numpy as np
import pandas as pd
# 读取数据
temp = pd.read_csv('2016-weather-data-seattle.csv')
# 数据处理, 时间格式转换
temp['year'] = pd.to_datetime(temp['Date']).dt.year
# 选择几年的数据展示即可
year_list = [1950, 1960, 1970, 1980, 1990, 2000, 2010]
temp = temp[temp['year'].isin(year_list)]
# 绘制每年的直方图,以年和平均温度分组,并使用'count'函数进行汇总
temp = temp.groupby(['year', 'Mean_TemperatureC']).agg({'Mean_TemperatureC': 'count'}).rename(columns={'Mean_TemperatureC': 'count'}).reset_index()
# 使用Plotly绘制脊线图,每个轨迹对应于特定年份的温度分布
# 将每年的数据(温度和它们各自的计数)存储在单独的数组,并将其存储在字典中以方便检索
array_dict = {}
for year in year_list:
# 每年平均温度
array_dict[f'x_{year}'] = temp[temp['year'] == year]['Mean_TemperatureC']
# 每年温度计数
array_dict[f'y_{year}'] = temp[temp['year'] == year]['count']
array_dict[f'y_{year}'] = (array_dict[f'y_{year}'] - array_dict[f'y_{year}'].min()) \\
/ (array_dict[f'y_{year}'].max() - array_dict[f'y_{year}'].min())
# 创建一个图像对象
fig = go.Figure()
for index, year in enumerate(year_list):
# 使用add_trace()绘制轨迹
fig.add_trace(go.Scatter(
x=[-20, 40], y=np.full(2, len(year_list) - index),
mode='lines',
line_color='white'))
fig.add_trace(go.Scatter(
x=array_dict[f'x_{year}'],
y=array_dict[f'y_{year}'] + (len(year_list) - index) + 0.4,
fill='tonexty',
name=f'{year}'))
# 添加文本
fig.add_annotation(
x=-20,
y=len(year_list) - index,
text=f'{year}',
showarrow=False,
yshift=10)
# 添加标题、图例、xy轴参数
fig.update_layout(
title='1950年~2010年西雅图平均温度',
showlegend=False,
xaxis=dict(title='单位: 摄氏度'),
yaxis=dict(showticklabels=False)
)
# 跳转网页显示
fig.show()
Seaborn没有专门的函数来绘制山脊线图,可以多次调用kdeplot()来制作。
结果如下。
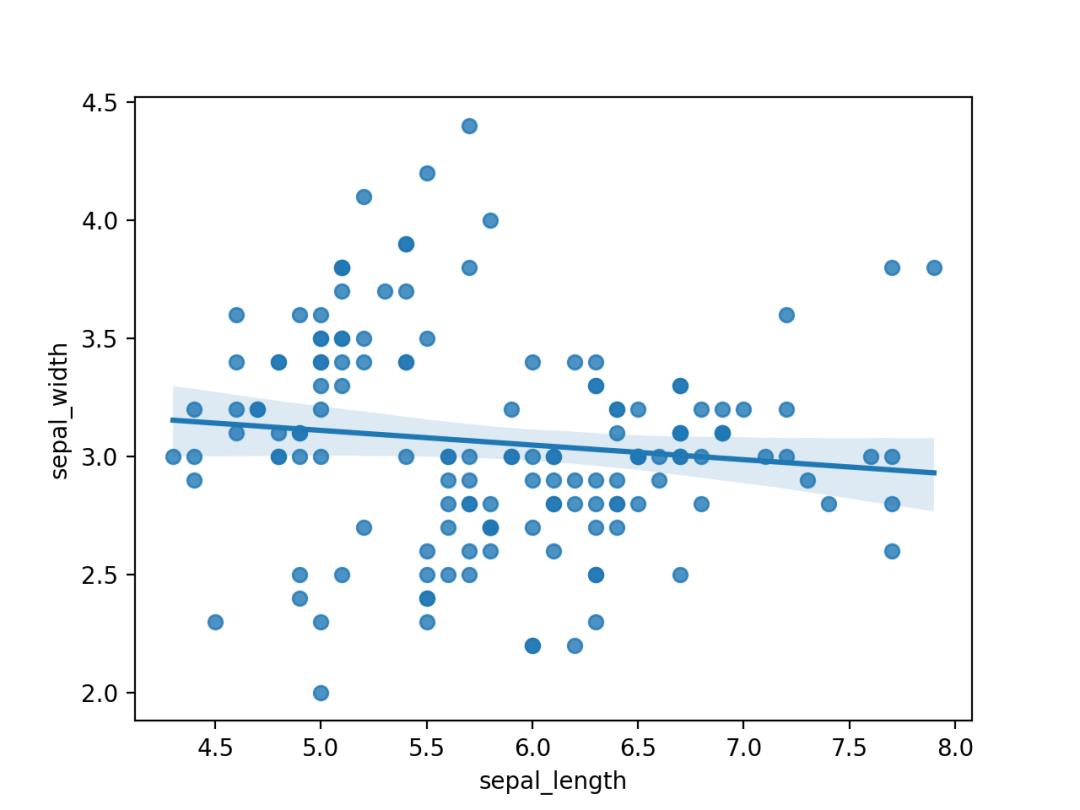
06. 散点图
散点图,显示2个数值变量之间的关系。
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
df = sns.load_dataset('iris', data_home='seaborn-data', cache=True)
# 绘图显示
sns.regplot(x=df["sepal_length"], y=df["sepal_width"])
plt.show()
使用Seaborn的regplot()进行绘制,结果如下。
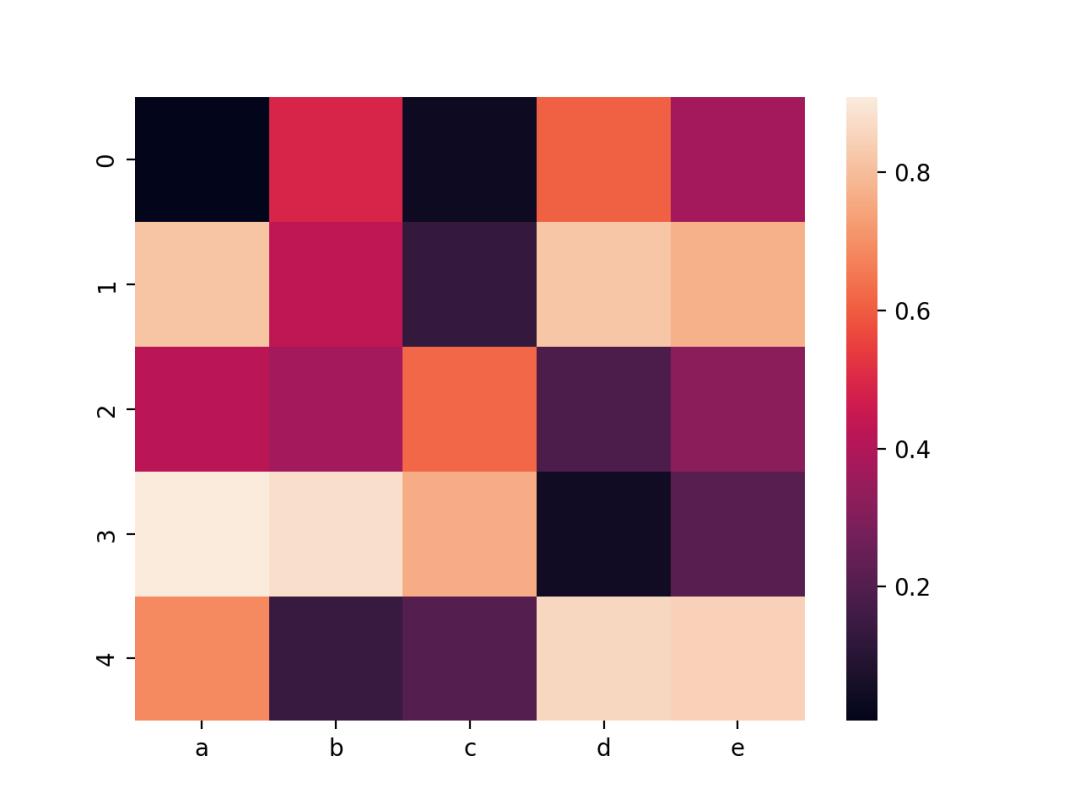
07. 矩形热力图
矩形热力图,矩阵中的每个值都被表示为一个颜色数据。
import seaborn as sns
import pandas as pd
import numpy as np
# Create a dataset
df = pd.DataFrame(np.random.random((5,5)), columns=["a","b","c","d","e"])
# Default heatmap
p1 = sns.heatmap(df)
使用Seaborn的heatmap()进行绘制,结果如下。
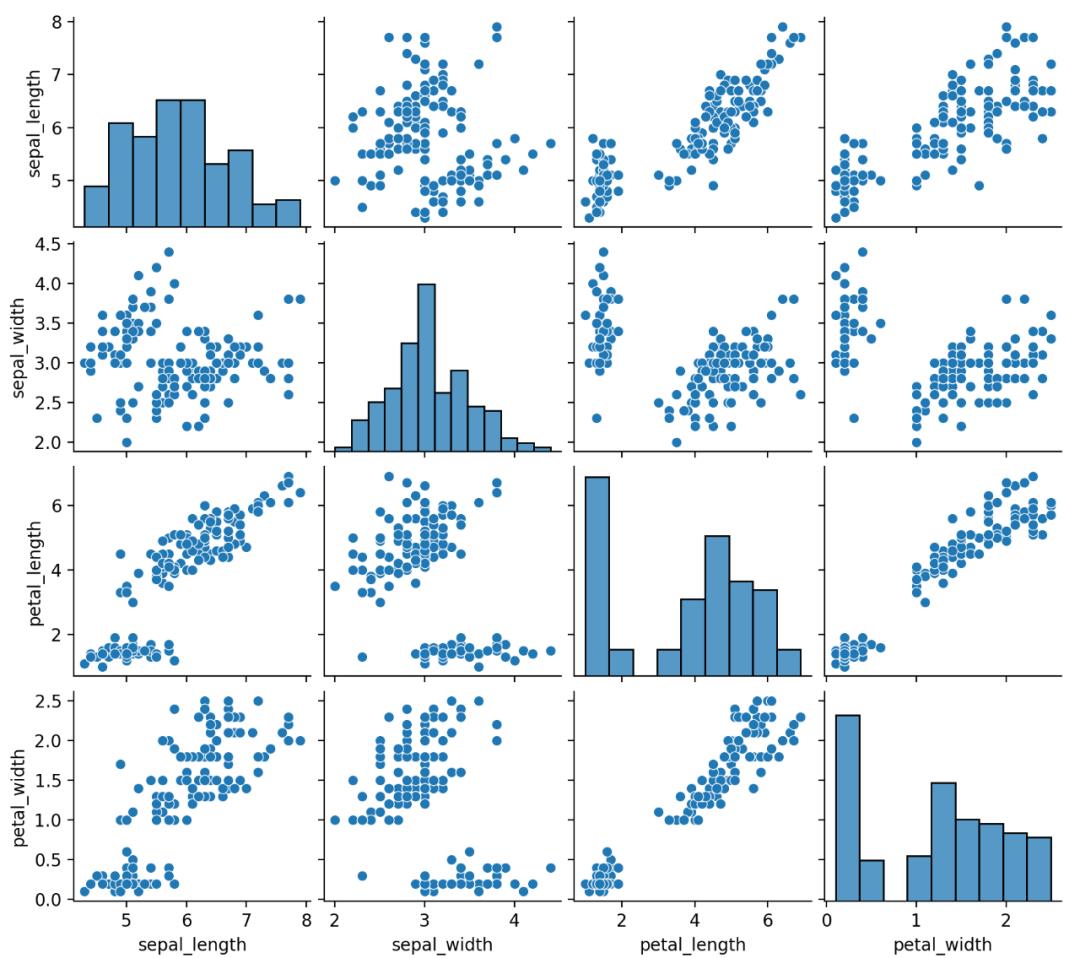
08. 相关性图
相关性图或相关矩阵图,分析每对数据变量之间的关系。
相关性可视化为散点图,对角线用直方图或密度图表示每个变量的分布。
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
df = sns.load_dataset('iris', data_home='seaborn-data', cache=True)
# 绘图显示
sns.pairplot(df)
plt.show()
使用Seaborn的pairplot()进行绘制,结果如下。
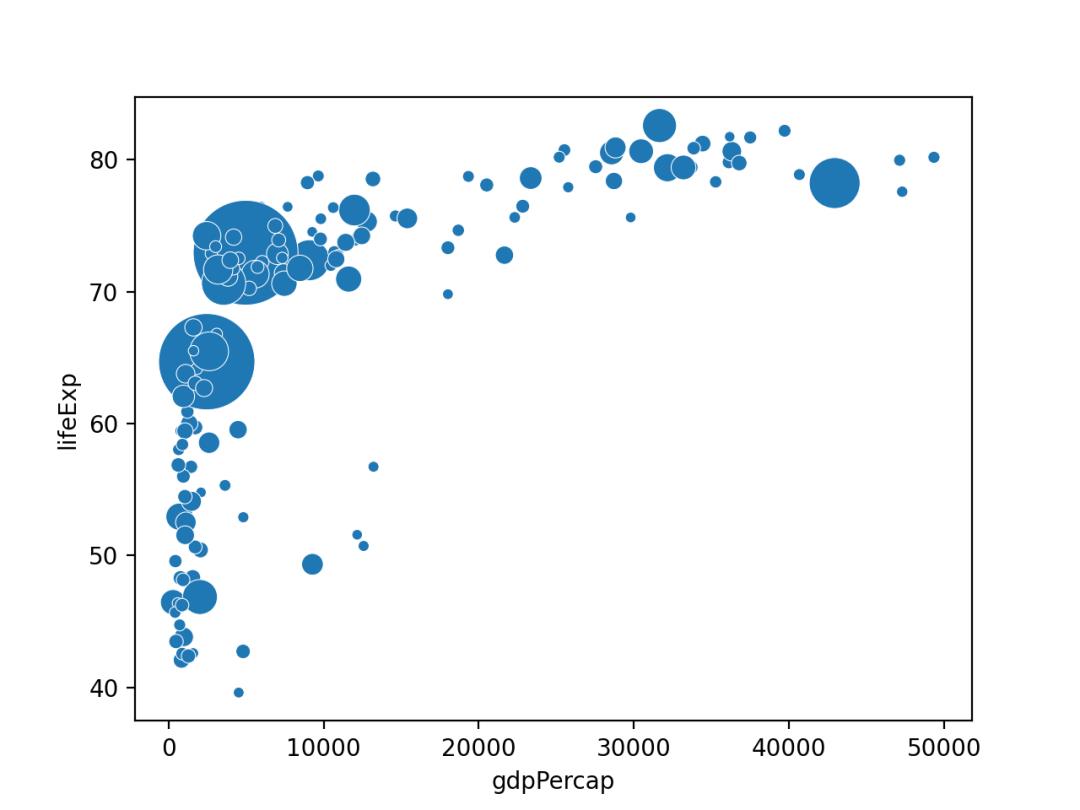
09. 气泡图
气泡图其实就是一个散点图,其中圆圈大小被映射到第三数值变量的值。
import matplotlib.pyplot as plt
import seaborn as sns
from gapminder import gapminder
# 导入数据
data = gapminder.loc[gapminder.year == 2007]
# 使用scatterplot创建气泡图
sns.scatterplot(data=data, x="gdpPercap", y="lifeExp", size="pop", legend=False, sizes=(20, 2000))
# 显示
plt.show()
使用Seaborn的scatterplot()进行绘制,结果如下。
10. 连接散点图
连接散点图就是一个线图,其中每个数据点由圆形或任何类型的标记展示。
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
# 创建数据
df = pd.DataFrame({'x_axis': range(1, 10), 'y_axis': np.random.randn(9) * 80 + range(1, 10)})
# 绘制显示
plt.plot('x_axis', 'y_axis', data=df, linestyle='-', marker='o')
plt.show()
使用Matplotlib的plot()进行绘制,结果如下。

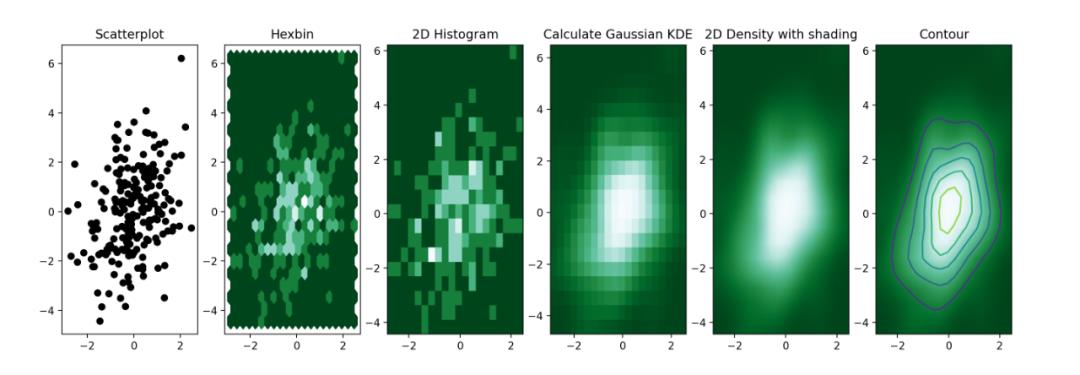
11. 二维密度图
二维密度图或二维直方图,可视化两个定量变量的组合分布。
它们总是在X轴上表示一个变量,另一个在Y轴上,就像散点图。
然后计算二维空间特定区域内的次数,并用颜色渐变表示。
形状变化:六边形a hexbin chart,正方形a 2d histogram,核密度2d density plots或contour plots。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import kde
# 创建数据, 200个点
data = np.random.multivariate_normal([0, 0], [[1, 0.5], [0.5, 3]], 200)
x, y = data.T
# 创建画布, 6个子图
fig, axes = plt.subplots(ncols=6, nrows=1, figsize=(21, 5))
# 第一个子图, 散点图
axes[0].set_title('Scatterplot')
axes[0].plot(x, y, 'ko')
# 第二个子图, 六边形
nbins = 20
axes[1].set_title('Hexbin')
axes[1].hexbin(x, y, gridsize=nbins, cmap=plt.cm.BuGn_r)
# 2D 直方图
axes[2].set_title('2D Histogram')
axes[2].hist2d(x, y, bins=nbins, cmap=plt.cm.BuGn_r)
# 高斯kde
k = kde.gaussian_kde(data.T)
xi, yi = np.mgrid[x.min():x.max():nbins * 1j, y.min():y.max():nbins * 1j]
zi = k(np.vstack([xi.flatten(), yi.flatten()]))
# 密度图
axes[3].set_title('Calculate Gaussian KDE')
axes[3].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='auto', cmap=plt.cm.BuGn_r)
# 添加阴影
axes[4].set_title('2D Density with shading')
axes[4].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r)
# 添加轮廓
axes[5].set_title('Contour')
axes[5].pcolormesh(xi, yi, zi.reshape(xi.shape), shading='gouraud', cmap=plt.cm.BuGn_r)
axes[5].contour(xi, yi, zi.reshape(xi.shape))
plt.show()
使用Matplotlib和scipy进行绘制,结果如下。
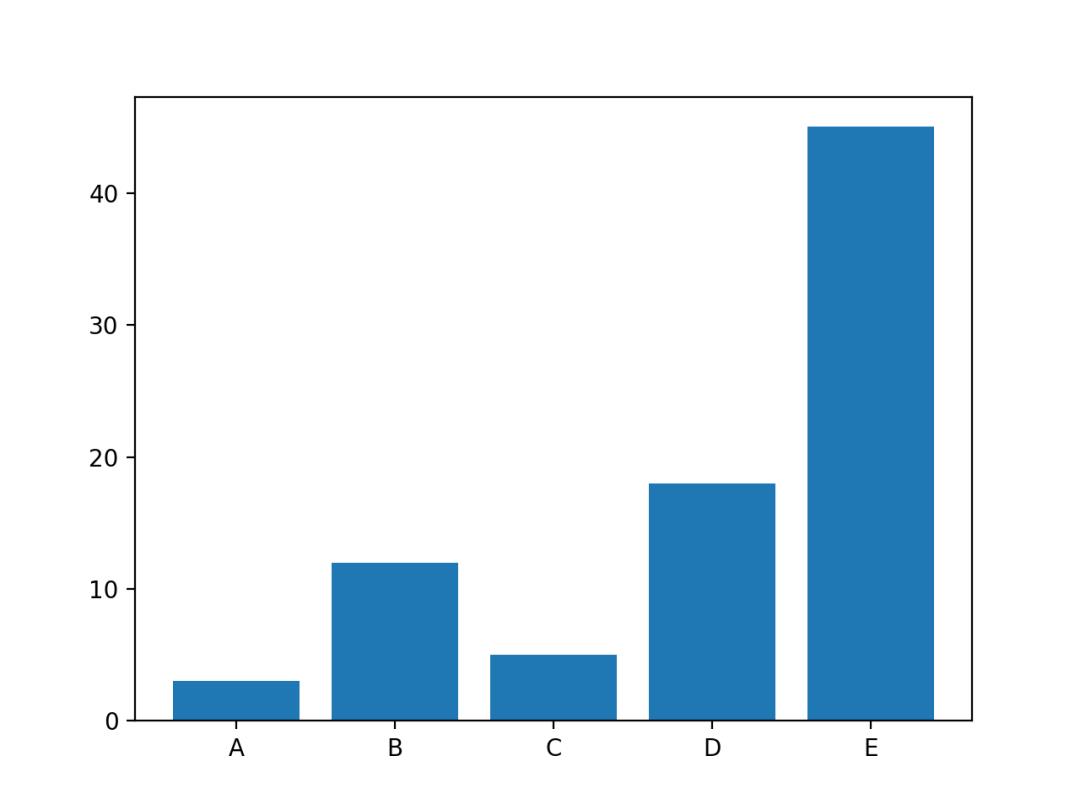
12. 条形图
条形图表示多个明确的变量的数值关系。每个变量都为一个条形。条形的大小代表其数值。
import numpy as np
import matplotlib.pyplot as plt
# 生成随机数据
height = [3, 12, 5, 18, 45]
bars = ('A', 'B', 'C', 'D', 'E')
y_pos = np.arange(len(bars))
# 创建条形图
plt.bar(y_pos, height)
# x轴标签
plt.xticks(y_pos, bars)
# 显示
plt.show()
使用Matplotlib的bar()进行绘制,结果如下。
13. 雷达图
雷达图,可以可视化多个定量变量的一个或多个系列的值。
每个变量都有自己的轴,所有轴都连接在图形的中心。
import matplotlib.pyplot as plt
import pandas as pd
from math import pi
# 设置数据
df = pd.DataFrame({
'group': ['A', 'B', 'C', 'D'],
'var1': [38, 1.5, 30, 4],
'var2': [29, 10, 9, 34],
'var3': [8, 39, 23, 24],
'var4': [7, 31, 33, 14],
'var5': [28, 15, 32, 14]
})
# 目标数量
categories = list(df)[1:]
N = len(categories)
# 角度
angles = [n / float(N) * 2 * pi for n in range(N)]
angles += angles[:1]
# 初始化
ax = plt.subplot(111, polar=True)
# 设置第一处
ax.set_theta_offset(pi / 2)
ax.set_theta_direction(-1)
# 添加背景信息
plt.xticks(angles[:-1], categories)
ax.set_rlabel_position(0)
plt.yticks([10, 20, 30], ["10", "20", "30"], color="grey", size=7)
plt.ylim(0, 40)
# 添加数据图
# 第一个
values = df.loc[0].drop('group').values.flatten().tolist()
values += values[:1]
ax.plot(angles, values, linewidth=1, linestyle='solid', label="group A")
ax.fill(angles, values, 'b', alpha=0.1)
# 第二个
values = df.loc[1].drop('group').values.flatten().tolist()
values += values[:1]
ax.plot(angles, values, linewidth=1, linestyle='solid', label="group B")
ax.fill(angles, values, 'r', alpha=0.1)
# 添加图例
plt.legend(loc='upper right', bbox_to_anchor=(0.1, 0.1))
# 显示
plt.show()
使用Matplotlib进行绘制,结果如下。

14. 词云图
词云图是文本数据的视觉表示。
单词通常是单个的,每个单词的重要性以字体大小或颜色表示。
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# 添加词语
text=("Python Python Python Matplotlib Chart Wordcloud Boxplot")
# 创建词云对象
wordcloud = WordCloud(width=480, height=480, margin=0).generate(text)
# 显示词云图
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.margins(x=0, y=0)
plt.show()
使用wordcloud进行绘制,结果如下。

15. 平行座标图
一个平行座标图,能够比较不同系列相同属性的数值情况。
Pandas可能是绘制平行坐标图的最佳方式。
import seaborn as sns
import matplotlib.pyplot as plt
from pandas.plotting import parallel_coordinates
# 读取数据
data = sns.load_dataset('iris', data_home='seaborn-data', cache=True)
# 创建图表
parallel_coordinates(data, 'species', colormap=plt.get_cma以上是关于这40个Python可视化图表案例,强烈建议收藏!的主要内容,如果未能解决你的问题,请参考以下文章