大数据运维 Hadoop完全分布式环境搭建
Posted 脚丫先生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据运维 Hadoop完全分布式环境搭建相关的知识,希望对你有一定的参考价值。
文章目录
一、准备工作
1.1 安装VMware并设置网络
下载vmvare软件,配置NAT网络模式。NAT是网络地址转换,是在宿主机和虚拟机之间增加一个地址转换服务,负责外部和虚拟机之间的通讯转接和IP转换。

1.2.安装centos虚拟机(这里就不详细说了,网上太多了)
安装完后克隆虚拟机,产生三台虚拟机共集群使用。

三台虚拟机的ip:
192.168.239.128
192.168.239.129
192.168.239.130
1.3 虚拟机配置(三台虚拟机同理)
- (1) 永久修改主机名
修改配置文件 /etc/hostname 保存退出。
[root@xxxx ~]# vi /etc/hostname
spark1
~
~
~
~
:wq
[root@xxxx ~]# reboot
- (2) 修改host
[root@spark1 ~]# vi /etc/hosts
192.168.239.128 spark1
192.168.239.129 spark2
192.168.239.130 spark3
注意: 需要把以上hosts配置到windows的hosts文件中,才能使用http://spark1:port 的形式进行访问HDFS的界面。当然也可以用服务器的ip进行访问。
- (3) 关闭防火墙和selinux(Centos7)
停止防火墙命令:
systemctl stop firewalld
开机禁止启动防火墙命令:
systemctl disable firewalld
- (4) 关闭selinux
vim /etc/sysconfig/selinux

- (5) ssh设置 免密登陆
集群之间的机器需要相互通信,我们需要先配置免密码登录。
[root@spark1 ~]# ssh-keygen -t rsa
拷贝生成的公钥到另外两台虚拟机:
[root@spark1 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub spark2
[root@spark1 ~]# ssh-copy-id -i ~/.ssh/id_rsa.pub spark3
另外两台虚拟机(spark1,spark2)也需要执行上述步骤
测试:
[root@spark1 ~]# ssh spark2
Last login: Mon Aug 2 11:27:04 2021 from 192.168.239.1
[root@spark2 ~]#
二、集群规划
所有下载资源的地址:华为开源镜像站
| 主机名 | IP | NameNode | DataNode | ResourceManager | NodeManager | SecondaryNameNode |
|---|---|---|---|---|---|---|
| spark1 | 192.168.239.128 | √ | √ | √ | ||
| spark2 | 192.168.239.129 | √ | √ | |||
| spark3 | 192.168.239.130 | √ | √ |
2.1 编写同步脚本xsync
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for i in spark1 spark2 spark3
do
#echo $pdir/$fname $user@hadoop$host:$pdir
echo --------------- $i ----------------
rsync -rvl $pdir/$fname $user@$i:$pdir
done
并把xsync设置为全局命令:
[root@spark1 bin]# ln -s /usr/local/datawork/bin/xsync /usr/bin/xsync
2.2 安装JAVA 环境JDK
在华为资源站下载jdk-8u191-linux-x64.tar.gz,上传spark1虚拟机 /usr/java目录下,并解压:
[root@spark1 java]# ls
jdk1.8.0_191
配置环境变量:
vim /etc/profile
#添加如下内容
export JAVA_HOME=/usr/java/jdk1.8.0_191
export JRE_HOME=/usr/java/jdk1.8.0_191/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
使用source命令生效
source /etc/profile
查看Java环境变量配置是否成功:
[root@spark1 ~]# java -version
openjdk version "1.8.0_282"
OpenJDK Runtime Environment (build 1.8.0_282-b08)
OpenJDK 64-Bit Server VM (build 25.282-b08, mixed mode)
``
`
到此jdk已经安装成功。
其他两台虚拟机可以按照上述方式安装,也可以使用快捷方式,通过以下命令同步这两台虚拟机
```java
rsync -av /usr/java/jdk1.8.0_191 spark2:/usr/java/jdk1.8.0_191
rsync -av /usr/java/jdk1.8.0_191 spark3:/usr/java/jdk1.8.0_191
rsync -av /etc/profile spark2:/etc/profile
rsync -av /etc/profile spark3:/etc/profile
然后分别在另外两台虚拟机上执行source命令,使配置文件生效。
2.3 hadoop安装
在华为资源站下载压缩包,上传spark1虚拟机 /usr/local/datawork目录下
并解压后:

配置环境变量
vim /etc/profile
#添加如下内容
export HADOOP_HOME=/usr/local/datawork/hadoop-2.8.5
export PATH=.:${JAVA_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
使用source命令生效
source /etc/profile

2.3.1 配置 hadoop
进入hadoop文件夹查看目录:

etc目录存放配置文件
sbin目录下存放服务的启动命令
share目录下存放jar包与文档
- (1) 配置hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/data/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/data/datanode</value>
</property>
<property>
<name>dfs.tmp.dir</name>
<value>/home/data/tmp</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
- (2) 配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://spark1:8020</value>
</property>
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
</configuration>
- (3) 配置mapred-env.sh
`#添加
export JAVA_HOME=/usr/java/jdk1.8.0_191
- (4) 配置yarn-env.sh
`#添加
export JAVA_HOME=/usr/java/jdk1.8.0_191
- (5) 配置yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>spark1</value>
</property>
</configuration>
- (6) 配置mapred-site.xml,如果没有就拷贝mapred-site.xml.template然后重命名为mapred-site.xml
<configuration>
<property>
<name>mapreduce.jobhistory.address</name>
<value>spark1:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>spark1:19888</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置从节点的主机名,前面配置host的时候已经ip和hostname做了映射就可以使用hostname,如果没有就需要写对应的ip
vi etc/hadoop/slaves
[root@spark1 hadoop]# cat slaves
spark1
spark2
spark3
同理我们也可以通过命令去同步另外两台虚拟机,减少安装hadoop时间
rsync -av /usr/local/datawork/hadoop-2.8.5 spark2:/usr/local/datawork/
rsync -av /usr/local/datawork/hadoop-2.8.5 spark3:/usr/local/datawork/
rsync -av /etc/profile spark2:/etc/profile
rsync -av /etc/profile spark3:/etc/profile
然后分别在两台虚拟机上执行source命令,使得环境变量有效。
2.4 启动hadoop集群
启动hdfs,首次启动需格式化hdfs。
[root@spark1 ~]# hdfs namenode -format
格式化完毕后可以使用以下命令开启集群.
[root@spark1~]# start-all.sh
启动完后,执行jps查看执行情况
主节点(spark1):
[root@spark1~]# jps
9814 Jps
4374 SecondaryNameNode
3176 NameNode
3545 ResourceManager
3645 NodeManager
从节点(spark2):
[root@spark2~]# jps
2933 NodeManager
5062 DataNode
7784 Jps
从节点(spark3):
[root@spark2 ~]# jps
5020 DataNode
7629 Jps
2926 NodeManager
到此集群已搭建成功,接着继续看一下控制台的一些情况
输入http://192.168.239.128:50070/,查看hdfs运行情况:

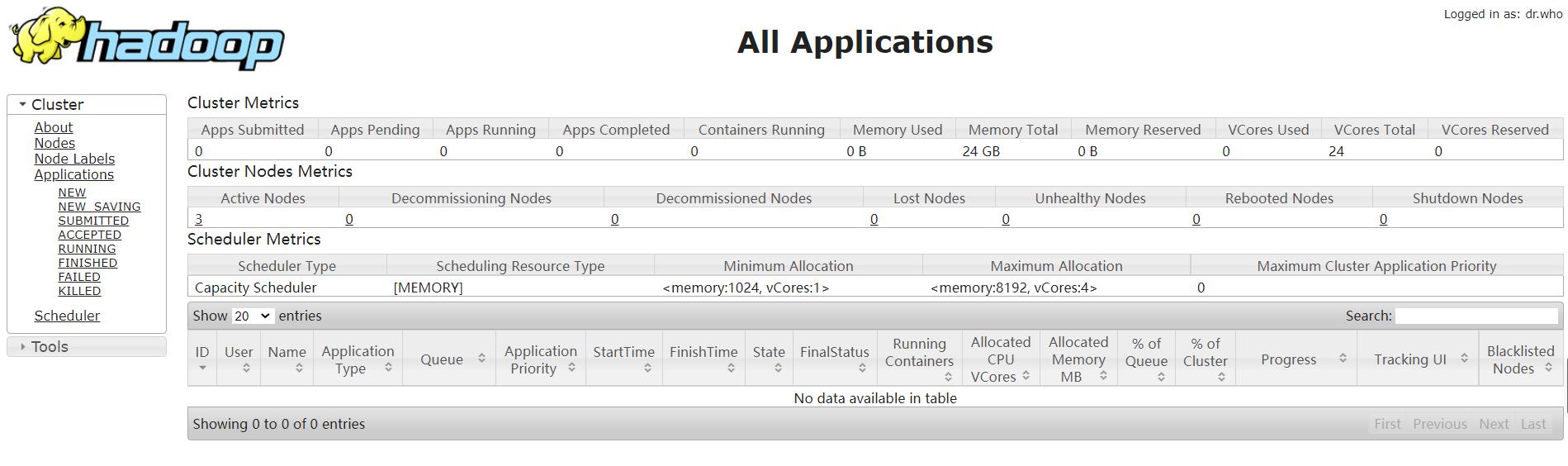
输入http://192.168.239.128:8088查看YARN运行情况
以上是关于大数据运维 Hadoop完全分布式环境搭建的主要内容,如果未能解决你的问题,请参考以下文章