今天终于把爬虫的Ajax请求搞懂了
Posted 江 月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了今天终于把爬虫的Ajax请求搞懂了相关的知识,希望对你有一定的参考价值。
今天终于把爬虫的Ajax请求搞懂了
一、案例分析及存在的问题
首先,我们是想要爬取http://www.fintechdb.cn/这个网站中的各个不同省份的一些数据,但是如果像普通的请求方式那样:(注意是不同省份的数据)
直接撸出代码来:
import requests
url = 'http://www.fintechdb.cn/request/loadmore'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41',
# 'X-Requested-With': 'XMLHttpRequest'
}
data = {
'csrf_weiyangx_token': 'a8c2eafab6bd8f2041b6c2e0c8a3811b',
'city': '台湾省,四川省',
'financing': '0',
'field': '0',
'timestart': '0',
'timeend': '0',
'offset': '0',
'sort': '1',
'order': 'desc'
}
res = requests.post(url=url, data=data, headers=headers)
print(res.status_code)
print(res)
print(res.content.decode())
好了,敲完代码,自己还以为万事大吉了,谁知道右击然后,点击运行:
结果一看,傻眼了;

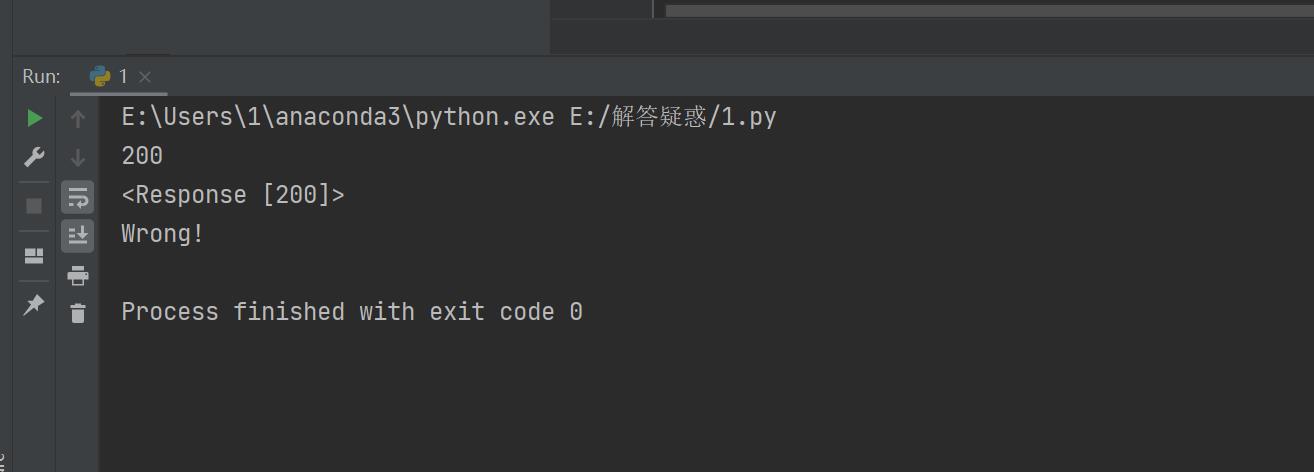
我说:诶,真是奇怪了,我的请求不都是返回来了状态码 200 嘛?怎么给我一个Wrong啊?是不是他故意返回一个 200 ,让我以为请求成功了啊?
带着这些疑问,我打开了网页,点进去了我的那个网址,发现;
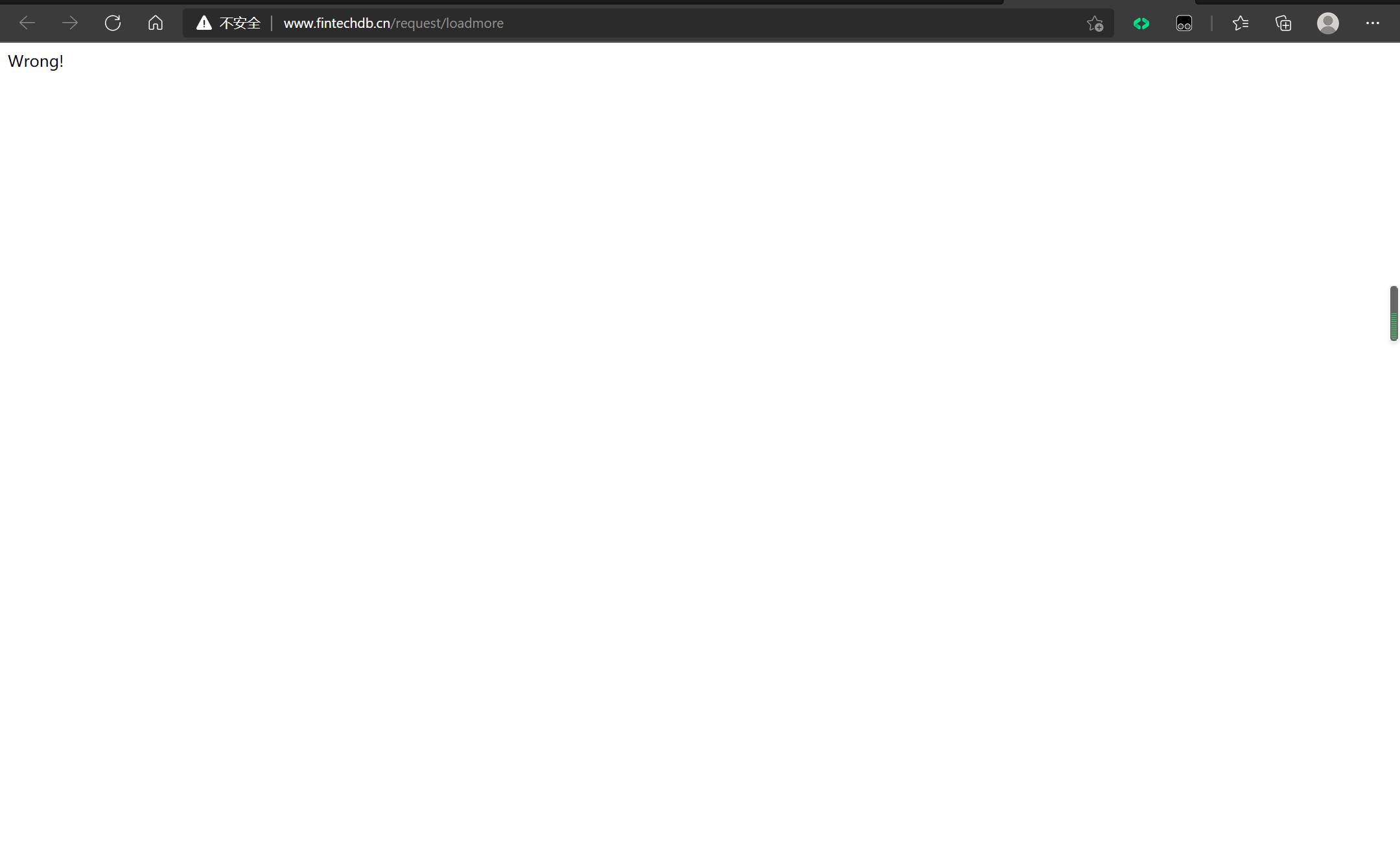
啊,原来网页本身的内容就是Wrong啊,看来是请求正确的啦。
那么,问题又来了,那那些请求的数据又是放在了哪里了呢?
明明是可以看到的啊
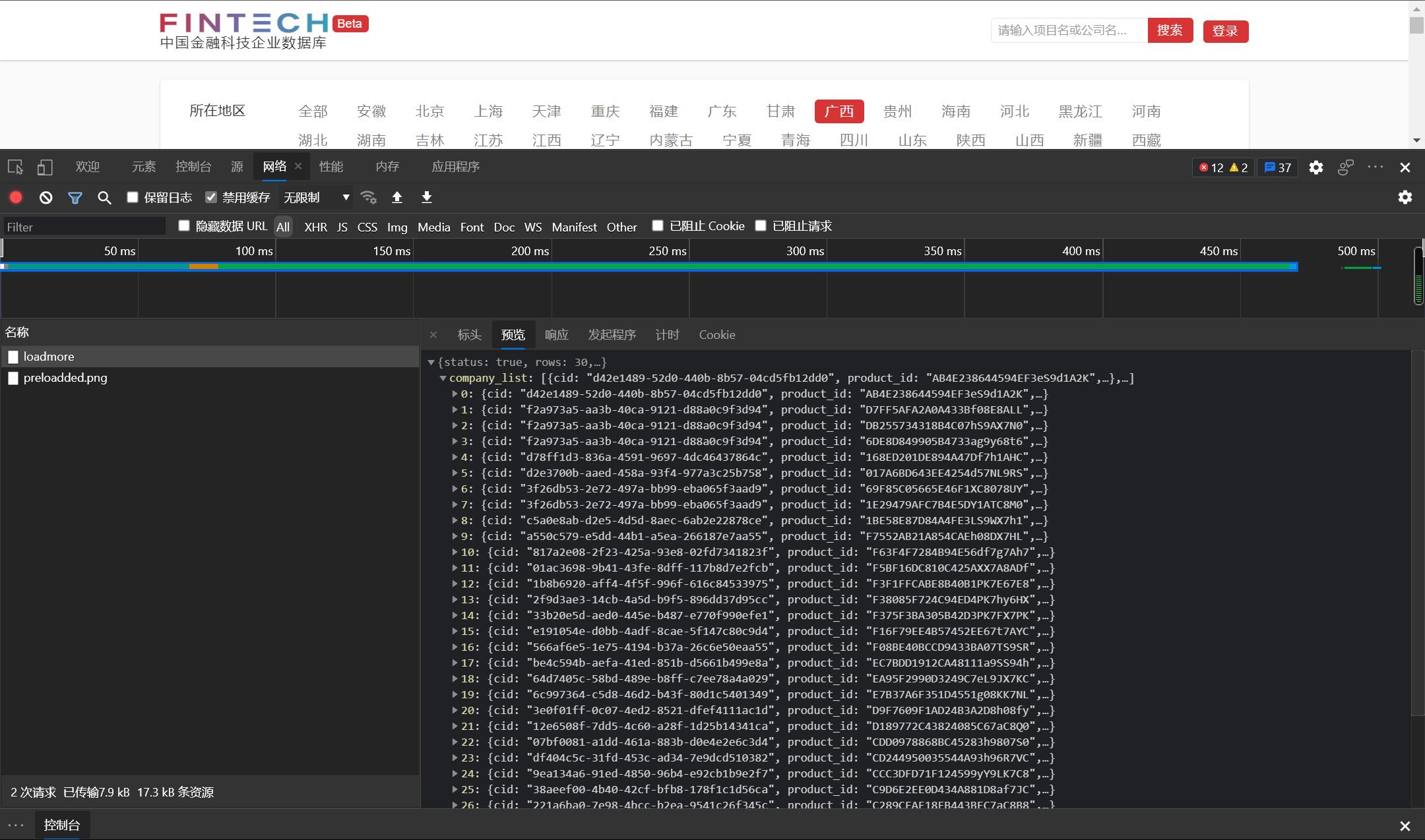
真的是邪门了啊???
二、问题的解决
后来,我查阅各种资料。。。。。。

最后发现,原来原因在于这个网站是用Ajax来写的,
Ajax简介
AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。
AJAX 不是新的编程语言,而是一种使用现有标准的新方法。
AJAX 是一种用于创建快速动态网页的技术。
总之一句话:
Ajax就是不需要重新加载页面就可以使得网页的一部分内容进行一定的更新,而 XMLHttpRequest 对象是实现Ajax的基础环节, XMLHttpRequest 对象对象是实现浏览器(Html)与数据进行交互的。
下面回到原本的 额问题
问题解决
我们重新进行一下网页的捕获,发现,诶,果然有一个 XMLHttpRequest 对象对象这个请求的头的参数

那好办,我们直接就把这个请求的参数也带进请求头里面去就好了,对不对?
代码如下:
import requests
url = 'http://www.fintechdb.cn/request/loadmore'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36 Edg/91.0.864.41',
'X-Requested-With': 'XMLHttpRequest'
}
data = {
'csrf_weiyangx_token': 'a8c2eafab6bd8f2041b6c2e0c8a3811b',
'city': '台湾省,四川省',
'financing': '0',
'field': '0',
'timestart': '0',
'timeend': '0',
'offset': '0',
'sort': '1',
'order': 'desc'
}
res = requests.post(url=url, data=data, headers=headers)
print(res.status_code)
print(res)
print(res.content.decode())
(这里其实就是比上一个代码多了一个请求头参数:
‘X-Requested-With’: ‘XMLHttpRequest’
然后就ok啦~)
果然,如我所愿,最终还是得到了我那梦寐以求的数据(^ _ ^)啦~:
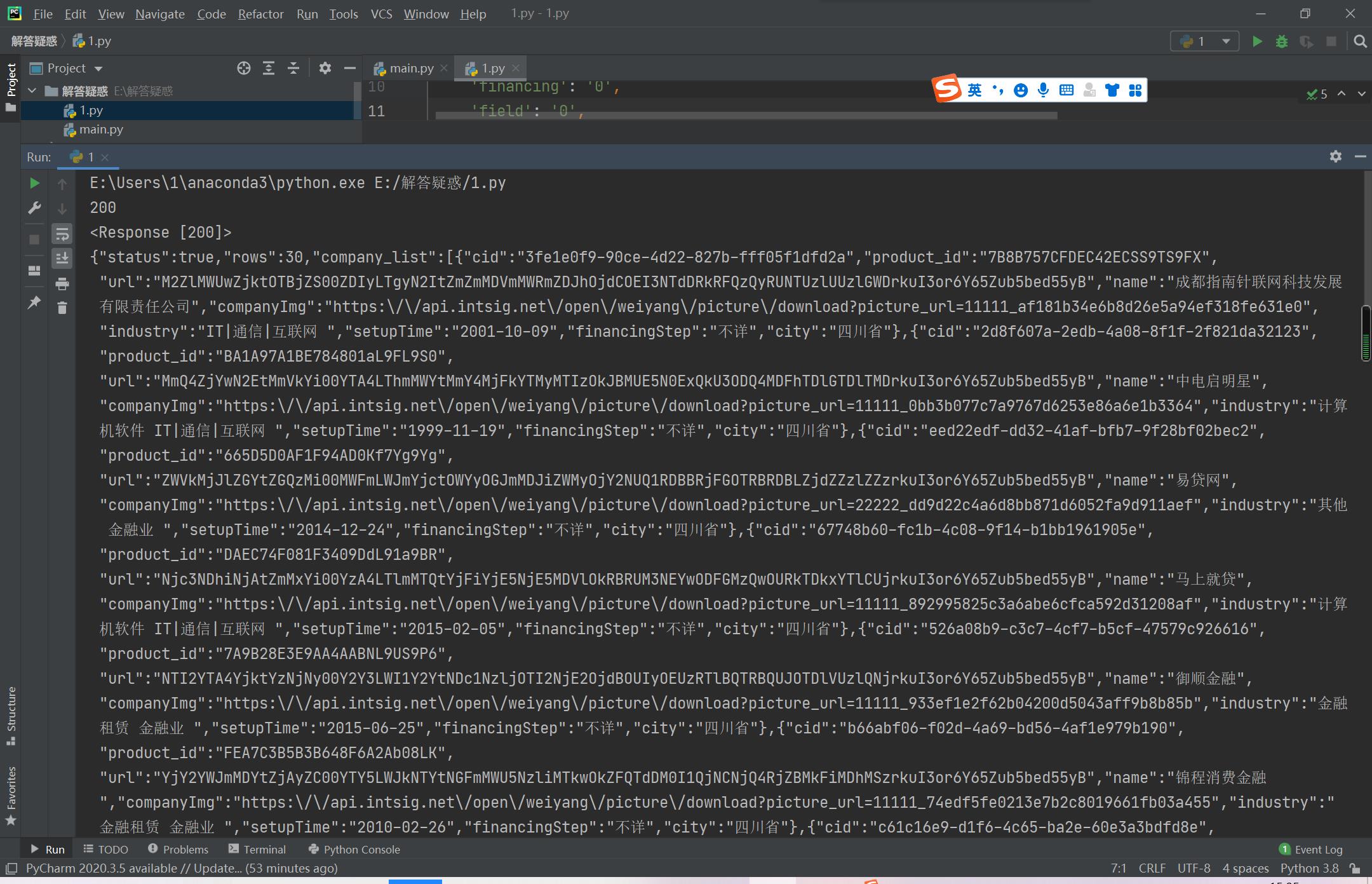
反正呢,至少现在不是什么Wrong了啦。
然后你现在想要那个省份的就直接修改一下post请求就可以实现了啦,后面不用多说大家也都懂的。
三、总结
1、Ajax
Ajax前面结束过了,就是实现异步的js和xml的,Ajax的英文全程为:
Asynchronous javascript and XML
翻译一下;
AJAX = 异步 JavaScript 和 XML
就是说把网页的呈现和数据的存储分开来进行,js专门负责实行页面的呈现、调用其他的资源等功能,而xml呢,自己搞自己的数据存储以及传输 去吧,二者是异步的,就是说,他们之间是独立进行的额,彼此互不干扰,互不相干。
最后再说一遍:
Ajax请求:
AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术。
2、XMLHttpRequest
为了实现Ajax这种技术,我们必须要有一定的基础的其他技术来作为支撑,所以就有了XMLHttpRequest对象的存在。XMLHttpRequest是为了实现异步的存储与传输等功能,当然,我们也可以通过一个网页的请求头是否有XMLHttpRequest来判断,这个网页是不是使用了Ajax技术呢。
3、解决问题
如果我们发现了这个网页使用Ajax来实现的话,那么,我们直接在请求头(headers)里面加入一个XMLHttpRequest的请求参数即就可以啦。
最后,感谢大家的阅读,希望对大家有一定的帮助了啦。
以上是关于今天终于把爬虫的Ajax请求搞懂了的主要内容,如果未能解决你的问题,请参考以下文章