Android FrameWork开发之binder驱动的源码分析1
Posted learnframework
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android FrameWork开发之binder驱动的源码分析1相关的知识,希望对你有一定的参考价值。
csdn在线学习课程,课程咨询答疑和新课信息:QQ交流群:422901085进行课程讨论
[android跨进程通信实战视频课程(加群获取优惠)](https://edu.csdn.net/course/detail/35911)
上一节已经讲过ServiceManager其实也是属于一个普通的应用程序,它也需要与binder驱动进行通信,他在跨进程通信中CS模式中扮演的
Server端,普通进程需要添加获取Service就是Client端,如下图:
具体过程如下:

上节课把与驱动通信这一部分完全当作一个黑盒子,本节讲带大家源码层面进行分析,当然因为代码实在太多,这里
主要就把几个主要流程梳理。
1、首先第一步进程要与ServiceManager进程通信,肯定要 获取它的远程代理对象
代码如下:
int main() {
sp <IServiceManager> sm = defaultServiceManager();
..省略
return 0;
}看看defaultServiceManager方法,路径:frameworks/native/libs/binder/IServiceManager.cpp
sp<IServiceManager> defaultServiceManager()
{
if (gDefaultServiceManager != NULL) return gDefaultServiceManager;
{
AutoMutex _l(gDefaultServiceManagerLock);
while (gDefaultServiceManager == NULL) {
gDefaultServiceManager = interface_cast<IServiceManager>(
ProcessState::self()->getContextObject(NULL));
if (gDefaultServiceManager == NULL)
sleep(1);
}
}
return gDefaultServiceManager;
}这里其实调用 ProcessState::self()->getContextObject(NULL)),到ProcessState看看,路径:frameworks/native/libs/binder/ProcessState.cpp
sp<IBinder> ProcessState::getContextObject(const sp<IBinder>& /*caller*/)
{
return getStrongProxyForHandle(0);
}这里又调用的 getStrongProxyForHandle(0),注意这个0非常非常关键,代表了servicemanager的handle
sp<IBinder> ProcessState::getStrongProxyForHandle(int32_t handle)
{
sp<IBinder> result;
..省略
if (e != NULL) {
IBinder* b = e->binder;
if (b == NULL || !e->refs->attemptIncWeak(this)) {
if (handle == 0) {
..省略
Parcel data;
status_t status = IPCThreadState::self()->transact(
0, IBinder::PING_TRANSACTION, data, NULL, 0);
//这里主要看看servicemanager是否可以正常通信
if (status == DEAD_OBJECT)
return NULL;
}
b = new BpBinder(handle); //直接就可以创建对应的BpBinder对象
e->binder = b;
if (b) e->refs = b->getWeakRefs();
result = b;
}
..省略
}
return result;
}这里大家可以看出其实它最后就是new BpBinder(0),这个就成了最后的ServiceManager的本地代理对象IBinder,ps:因为系统默认servicemanager的handle固定就是0,所以本地代理创建就非常非常简单
获取了BpBinder后,在经过interface_cast<IServiceManager>的转换成对应的具体IServiceManager接口,这里其实java中IBinder对象转具体口对象的的asInterface一样,具体这里不做分析,和java上的基本类似。就是把BpBinder作为IServiceManager的一个成员变量remote()。
2、再来看看A进程已经获取了ServiceManager的远程对象,使用简单的一次addService进行通信,先来看下面图:
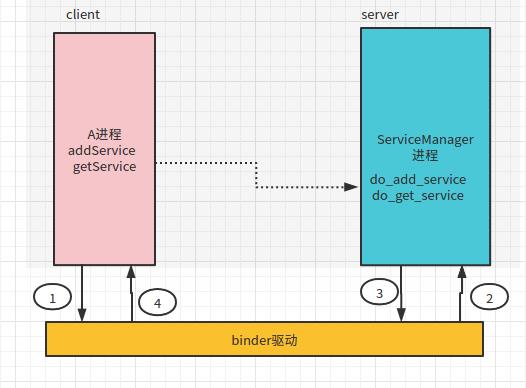
其实主要分为以下4个步骤:
1、A进程调用ServiceManagre代理的addService方法(方法中携带了了自己本地定义业务IBinder,及这个业务IBinder的名字),经过一系列调用会调用到IPCThreadState::transact
status_t ret = sm->addService(String16(SAMPLE_SERIVCE_DES), samServ);
这里调用IServiceManager的addService
virtual status_t addService(const String16& name, const sp<IBinder>& service,
bool allowIsolated)
{
Parcel data, reply;
data.writeInterfaceToken(IServiceManager::getInterfaceDescriptor());
data.writeString16(name);
data.writeStrongBinder(service);
data.writeInt32(allowIsolated ? 1 : 0);
status_t err = remote()->transact(ADD_SERVICE_TRANSACTION, data, &reply);
return err == NO_ERROR ? reply.readExceptionCode() : err;
}这里组装Parcel等数据然后调用remote()的transact方法,这里前面已经提过其实remote()返回就是BpBinder对象故其实调用到了BpBinder的transact
status_t BpBinder::transact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
// Once a binder has died, it will never come back to life.
if (mAlive) {
status_t status = IPCThreadState::self()->transact(
mHandle, code, data, reply, flags);
if (status == DEAD_OBJECT) mAlive = 0;
return status;
}
return DEAD_OBJECT;
}所以就到了IPCThreadState的transact
status_t IPCThreadState::transact(int32_t handle,
uint32_t code, const Parcel& data,
Parcel* reply, uint32_t flags)
{
..省略
if (err == NO_ERROR) {//把handle和code等一系列数据需要打包成传输数据,但cmd这里固定BC_TRANSACTION
err = writeTransactionData(BC_TRANSACTION, flags, handle, code, data, NULL);
}
if ((flags & TF_ONE_WAY) == 0) {
..省略
} else {
err = waitForResponse(NULL, NULL);
}
return err;
}
status_t IPCThreadState::writeTransactionData(int32_t cmd, uint32_t binderFlags,
int32_t handle, uint32_t code, const Parcel& data, status_t* statusBuffer)
{
binder_transaction_data tr;
tr.target.ptr = 0; /* Don't pass uninitialized stack data to a remote process */
tr.target.handle = handle;
tr.code = code;
tr.flags = binderFlags;
tr.cookie = 0;
tr.sender_pid = 0;
tr.sender_euid = 0;
const status_t err = data.errorCheck();
if (err == NO_ERROR) {
tr.data_size = data.ipcDataSize();
tr.data.ptr.buffer = data.ipcData();
tr.offsets_size = data.ipcObjectsCount()*sizeof(binder_size_t);
tr.data.ptr.offsets = data.ipcObjects();
} else if (statusBuffer) {
tr.flags |= TF_STATUS_CODE;
*statusBuffer = err;
tr.data_size = sizeof(status_t);
tr.data.ptr.buffer = reinterpret_cast<uintptr_t>(statusBuffer);
tr.offsets_size = 0;
tr.data.ptr.offsets = 0;
} else {
return (mLastError = err);
}
mOut.writeInt32(cmd);
mOut.write(&tr, sizeof(tr));
return NO_ERROR;
}首先writeTransactionData把handle和code等一系列数据需要打包成传输数据,但cmd这里固定BC_TRANSACTION,其次调用waitForResponse
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult)
{
uint32_t cmd;
int32_t err;
while (1) {//注意这里是一个循环,而不是单独的一次哦
if ((err=talkWithDriver()) < NO_ERROR) break;
if (mIn.dataAvail() == 0) continue;//写完之后就要一直循环的读取数据,直到读取到BR_REPLY
cmd = (uint32_t)mIn.readInt32();
..省略
switch (cmd) {
case BR_TRANSACTION_COMPLETE:
if (!reply && !acquireResult) goto finish;
break;
case BR_REPLY:
{
binder_transaction_data tr;
err = mIn.read(&tr, sizeof(tr));
if (reply) {
if ((tr.flags & TF_STATUS_CODE) == 0) {
reply->ipcSetDataReference(
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t),
freeBuffer, this);
} else {
err = *reinterpret_cast<const status_t*>(tr.data.ptr.buffer);
freeBuffer(NULL,
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t), this);
}
} else {
}
}
goto finish;
default:
err = executeCommand(cmd);
if (err != NO_ERROR) goto finish;
break;
}
}
finish:
if (err != NO_ERROR) {
if (acquireResult) *acquireResult = err;
if (reply) reply->setError(err);
mLastError = err;
}
return err;
}这里其实又是调用的talkwithDriver,就是和binder驱动进行通信,但它不是单独一次talkwithDriver哦,写完之后就会一直talkwithDriver读取返回结果
status_t IPCThreadState::talkWithDriver(bool doReceive)
{
bwr.write_size = outAvail;
bwr.write_buffer = (uintptr_t)mOut.data();
bwr.write_consumed = 0;
bwr.read_consumed = 0;
status_t err;
do {
if (ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr) >= 0)
err = NO_ERROR;
else
err = -errno;
} while (err == -EINTR);
return NO_ERROR;
}
return err;
}这里其实又到了一个与驱动交互的核心方法ioctl,一旦调用到了ioctl,那接下来就需要分析binder的驱动部分代码的ioctl
2、binder驱动接受到了A进程的ioctl,并做出把数据拷贝到ServiceManager进程并传递给ServiceManager进行处理
binder驱动的ioctl对应方法为binder_ioctl
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
..省略
switch (cmd) {
case BINDER_WRITE_READ:
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
..省略
default:
ret = -EINVAL;
goto err;
}
ret = 0;
..省略
return ret;
}这里刚才应用传递cmd为BINDER_WRITE_READ,接下来调用的是ret = binder_ioctl_write_read(filp, cmd, arg, thread);
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
if (size != sizeof(struct binder_write_read)) {
ret = -EINVAL;
goto out;
}
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {//拷贝用户空间数据到内核
ret = -EFAULT;
goto out;
}
。。省略
if (bwr.write_size > 0) {//调用binder_thread_write
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
trace_binder_write_done(ret);
if (ret < 0) {
bwr.read_consumed = 0;
if (copy_to_user(ubuf, &bwr, sizeof(bwr)))
ret = -EFAULT;
goto out;
}
}
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}这里简单把应用传递的一个结构体拷贝到内核,然后调用binder_thread_write
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
struct binder_context *context = proc->context;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error.cmd == BR_OK) {
int ret;
if (get_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
。。省略
switch (cmd) {
。。省略
case BC_TRANSACTION:
case BC_REPLY: {
struct binder_transaction_data tr;
if (copy_from_user(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
binder_transaction(proc, thread, &tr,
cmd == BC_REPLY, 0);
break;
}
。。省略
}
*consumed = ptr - buffer;
}
return 0;
}这里最后调用到了binder_transaction,代码过长省略大部分。。
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply,
binder_size_t extra_buffers_size)
{
int ret;
struct binder_transaction *t;
struct binder_work *tcomplete;
binder_size_t *offp, *off_end, *off_start;
binder_size_t off_min;
u8 *sg_bufp, *sg_buf_end;
struct binder_proc *target_proc = NULL;
struct binder_thread *target_thread = NULL;
struct binder_node *target_node = NULL;
struct binder_transaction *in_reply_to = NULL;
struct binder_transaction_log_entry *e;
。。省略
e = binder_transaction_log_add(&binder_transaction_log);
e->debug_id = t_debug_id;
e->call_type = reply ? 2 : !!(tr->flags & TF_ONE_WAY);
e->from_proc = proc->pid;
e->from_thread = thread->pid;
e->target_handle = tr->target.handle;
e->data_size = tr->data_size;
e->offsets_size = tr->offsets_size;
e->context_name = proc->context->name;
if (reply) {
。。省略
} else {
if (tr->target.handle) {
。。省略
} else {
target_node = context->binder_context_mgr_node;
if (target_node)
target_node = binder_get_node_refs_for_txn(
target_node, &target_proc,
&return_error);
。。省略
}
。。省略
if (!(tr->flags & TF_ONE_WAY) && thread->transaction_stack) {
。。省略
}
}
。。省略
t->buffer = binder_alloc_new_buf(&target_proc->alloc, tr->data_size,
tr->offsets_size, extra_buffers_size,
!reply && (t->flags & TF_ONE_WAY));
。。省略
//用户空间拷贝出对应数据,这个后面再进行详细分析
if (copy_from_user(t->buffer->data, (const void __user *)(uintptr_t)
tr->data.ptr.buffer, tr->data_size)) {
。。省略
}
if (copy_from_user(offp, (const void __user *)(uintptr_t)
tr->data.ptr.offsets, tr->offsets_size)) {
。。省略
}
。。省略
for (; offp < off_end; offp++) {
struct binder_object_header *hdr;
size_t object_size = binder_validate_object(t->buffer, *offp);
。。省略
hdr = (struct binder_object_header *)(t->buffer->data + *offp);
off_min = *offp + object_size;
switch (hdr->type) {
。。省略
case BINDER_TYPE_HANDLE:
case BINDER_TYPE_WEAK_HANDLE: {
struct flat_binder_object *fp;
fp = to_flat_binder_object(hdr);
ret = binder_translate_handle(fp, t, thread);
。。省略
} break;
。。省略
}
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
t->work.type = BINDER_WORK_TRANSACTION;
if (reply) {
。。省略
} else if (!(t->flags & TF_ONE_WAY)) {
BUG_ON(t->buffer->async_transaction != 0);
binder_inner_proc_lock(proc);
/*
* Defer the TRANSACTION_COMPLETE, so we don't return to
* userspace immediately; this allows the target process to
* immediately start processing this transaction, reducing
* latency. We will then return the TRANSACTION_COMPLETE when
* the target replies (or there is an error).
*/
binder_enqueue_deferred_thread_work_ilocked(thread, tcomplete);
t->need_reply = 1;
t->from_parent = thread->transaction_stack;
thread->transaction_stack = t;
binder_inner_proc_unlock(proc);
//这里发起唤醒服务进程等待队列
if (!binder_proc_transaction(t, target_proc, target_thread)) {
binder_inner_proc_lock(proc);
binder_pop_transaction_ilocked(thread, t);
binder_inner_proc_unlock(proc);
goto err_dead_proc_or_thread;
}
} else {
。。省略
}
。。省略
return;
。。省略
}代码实在太多,这里只说说最核心的,最后一切数据准备好了,也找到了目标进程了,会binder_proc_transaction
static bool binder_proc_transaction(struct binder_transaction *t,
struct binder_proc *proc,
struct binder_thread *thread)
{
struct binder_node *node = t->buffer->target_node;
..省略
if (!thread && !pending_async)//对方的进程中寻找到一个线程进行传输
thread = binder_select_thread_ilocked(proc);
if (thread) {
binder_transaction_priority(thread->task, t, node_prio,
node->inherit_rt);
binder_enqueue_thread_work_ilocked(thread, &t->work);//把对应任务放入线程执行队列
} else if (!pending_async) {
binder_enqueue_work_ilocked(&t->work, &proc->todo);
} else {
binder_enqueue_work_ilocked(&t->work, &node->async_todo);
}
if (!pending_async)//如果同步调用,则唤醒目标线程
binder_wakeup_thread_ilocked(proc, thread, !oneway /* sync */);
return true;
}这里的目标线程当然就是servicemanager的loop的那个主线程,上节课已经知道他是一直ioctl方式在读取驱动数据,所以它的进程应该执行的是
static int binder_thread_read(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed, int non_block)
{
。。省略
if (non_block) {
。。省略
} else {
//等待有任务
ret = binder_wait_for_work(thread, wait_for_proc_work);
}
。。省略
while (1) {
uint32_t cmd;
。。省略
//取出任务
w = binder_dequeue_work_head_ilocked(list);
if (binder_worklist_empty_ilocked(&thread->todo))
thread->process_todo = false;
switch (w->type) {
case BINDER_WORK_TRANSACTION: {
binder_inner_proc_unlock(proc);
t = container_of(w, struct binder_transaction, work);
} break;
。。省略
BUG_ON(t->buffer == NULL);
if (t->buffer->target_node) {
struct binder_node *target_node = t->buffer->target_node;
struct binder_priority node_prio;
tr.target.ptr = target_node->ptr;
tr.cookie = target_node->cookie;
node_prio.sched_policy = target_node->sched_policy;
node_prio.prio = target_node->min_priority;
binder_transaction_priority(current, t, node_prio,
target_node->inherit_rt);
cmd = BR_TRANSACTION;
} else {
。。省略
}
tr.code = t->code;
tr.flags = t->flags;
tr.sender_euid = from_kuid(current_user_ns(), t->sender_euid);
。。省略
tr.data_size = t->buffer->data_size;
tr.offsets_size = t->buffer->offsets_size;
tr.data.ptr.buffer = (binder_uintptr_t)
((uintptr_t)t->buffer->data +
binder_alloc_get_user_buffer_offset(&proc->alloc));
tr.data.ptr.offsets = tr.data.ptr.buffer +
ALIGN(t->buffer->data_size,
sizeof(void *));
//拷贝cmd到用户空间
if (put_user(cmd, (uint32_t __user *)ptr)) {
..省略
}
ptr += sizeof(uint32_t);
//拷贝真实实体数据
if (copy_to_user(ptr, &tr, sizeof(tr))) {
..省略
}
ptr += sizeof(tr);
binder_stat_br(proc, thread, cmd);
。。省略
if (cmd == BR_TRANSACTION && !(t->flags & TF_ONE_WAY)) {
binder_inner_proc_lock(thread->proc);
t->to_parent = thread->transaction_stack;
t->to_thread = thread;
thread->transaction_stack = t;
binder_inner_proc_unlock(thread->proc);
}
。。省略
return 0;
}大家可以注释大概可以看出binder驱动read数据是怎么一个过程,
1.等待挂起直到有任务唤醒
2.唤醒后取出任务及拼好数据
3.对携带数据拷贝写回到用户空间,这样一个read的ioctl就执行完毕
3、ServiceManager已经读取了数据,进行addService完成,返回数据给驱动,让驱动告知A进程结果
3.1、读取数据进行addService部分 代码路径:frameworks/native/cmds/servicemanager/binder.c(注意和驱动的binder.c路径不一样哦)
void binder_loop(struct binder_state *bs, binder_handler func)
{
。。省略
for (;;) {
bwr.read_size = sizeof(readbuf);
bwr.read_consumed = 0;
bwr.read_buffer = (uintptr_t) readbuf;
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);
。。省略
res = binder_parse(bs, 0, (uintptr_t) readbuf, bwr.read_consumed, func);
。。省略
}
}主要循环读取数据其实主要是binder_parse方法:
int binder_parse(struct binder_state *bs, struct binder_io *bio,
uintptr_t ptr, size_t size, binder_handler func)
{
。。省略
switch(cmd) {
。。省略
case BR_TRANSACTION: {
struct binder_transaction_data *txn = (struct binder_transaction_data *) ptr;
if ((end - ptr) < sizeof(*txn)) {
ALOGE("parse: txn too small!\\n");
return -1;
}
binder_dump_txn(txn);
if (func) {
。。省略
res = func(bs, txn, &msg, &reply);//其实就是执行svcmgr_handler,里面会进行对应的do_add_service,这里上节课已经分析就不予分析了
if (txn->flags & TF_ONE_WAY) {
。。省略
} else {
binder_send_reply(bs, &reply, txn->data.ptr.buffer, res);
//add完成后就会发一个回复给驱动
}
}
ptr += sizeof(*txn);
break;
}
。。省略
}
}
return r;
}
这里大家可以看会执行svcmgr_handler,里面会进行do_add_service,执行完成后调用一个 binder_send_reply(bs, &reply, txn->data.ptr.buffer, res)方法
void binder_send_reply(struct binder_state *bs,
struct binder_io *reply,
binder_uintptr_t buffer_to_free,
int status)
{
。。省略
data.cmd_free = BC_FREE_BUFFER;
data.buffer = buffer_to_free;
data.cmd_reply = BC_REPLY;//关键地方设置了BC_REPLY
。。省略
binder_write(bs, &data, sizeof(data));//进行binder数据写入binder驱动
}
这里设置了一个cmd为BC_REPLY,然后把它写入binder驱动,写入方法是binder_write。实际他就是调用ioctl方法,那么其实接下来流程就又回到了binder驱动
int binder_write(struct binder_state *bs, void *data, size_t len)
{
..省略
res = ioctl(bs->fd, BINDER_WRITE_READ, &bwr);//最后还是调用ioctl方法与binder驱动进行通信
..省略
return res;
}4、A进程接受到返回结果,这个addService过程成功结束
这里因为已经看到了servicemanager调用到了ioctl来写入BC_REPLY数据,这个写入过程就又是一个前面分析的binder_thread_write,实际又会调用到binder_transaction(proc, thread, &tr,cmd == BC_REPLY, 0);不过这次的cmd为BC_REPLY。这里目标进程就变成A进程,而且A进程前面分析的在waitForResponse我们也说过,在ioctl写入数据完成后,A进程的调用并没有结束,而是一直不断循环获取返回结果,知道返回BR_REPLY等它才会退出循环
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult)
{
while (1) {
if ((err=talkWithDriver()) < NO_ERROR) break;
。。省略
if (mIn.dataAvail() == 0) continue;
//在talkWithDriver写入数据完成后,A进程的调用并没有结束,而是一直不断循环获取返回结果,知道返回BR_REPLY等它才会退出循环
。。省略
switch (cmd) {
case BR_REPLY:
goto finish;
}
。。省略
},
以上是关于Android FrameWork开发之binder驱动的源码分析1的主要内容,如果未能解决你的问题,请参考以下文章