「深度学习一遍过」必修23:基于ResNet18的MNIST手写数字识别
Posted 小泽yyds
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「深度学习一遍过」必修23:基于ResNet18的MNIST手写数字识别相关的知识,希望对你有一定的参考价值。
本专栏用于记录关于深度学习的笔记,不光方便自己复习与查阅,同时也希望能给您解决一些关于深度学习的相关问题,并提供一些微不足道的人工神经网络模型设计思路。
专栏地址:「深度学习一遍过」必修篇
目录
项目 GitHub 地址
 https://github.com/zhao302014/Classic_model_examples/tree/main/2015_ResNet18_MNIST
https://github.com/zhao302014/Classic_model_examples/tree/main/2015_ResNet18_MNIST项目心得
- 2015 年——ResNet:这是由微软研究院的 Kaiming He 等四名华人提出,通过使用 ResNet Unit 成功训练出了更深层次的神经网络。该项目自己搭建了 ResNet18 网络并在 MNIST 手写数字识别项目中得到了应用。通过此次实践,我终于知道了跳层连接是如何连接的了:ResNet “跳层链接” 的代码体现在相同大小和相同特征图之间用 “+” 相连,而不是 concat。concat 操作常用于 inception 结构中,具体而言是用于特征图大小相同二通道数不同的通道合并中,而看起来简单粗暴的 “+” 连接方式则是用于 ResNet 的 “跳层连接” 结构中,具体而言是用于特征图大小相同且通道数相同的特征图合并。这让我想到一句古诗:“绝知此事要躬行” 啊!
项目代码
下面这张图是网上找的,描述的细节是真的赞!
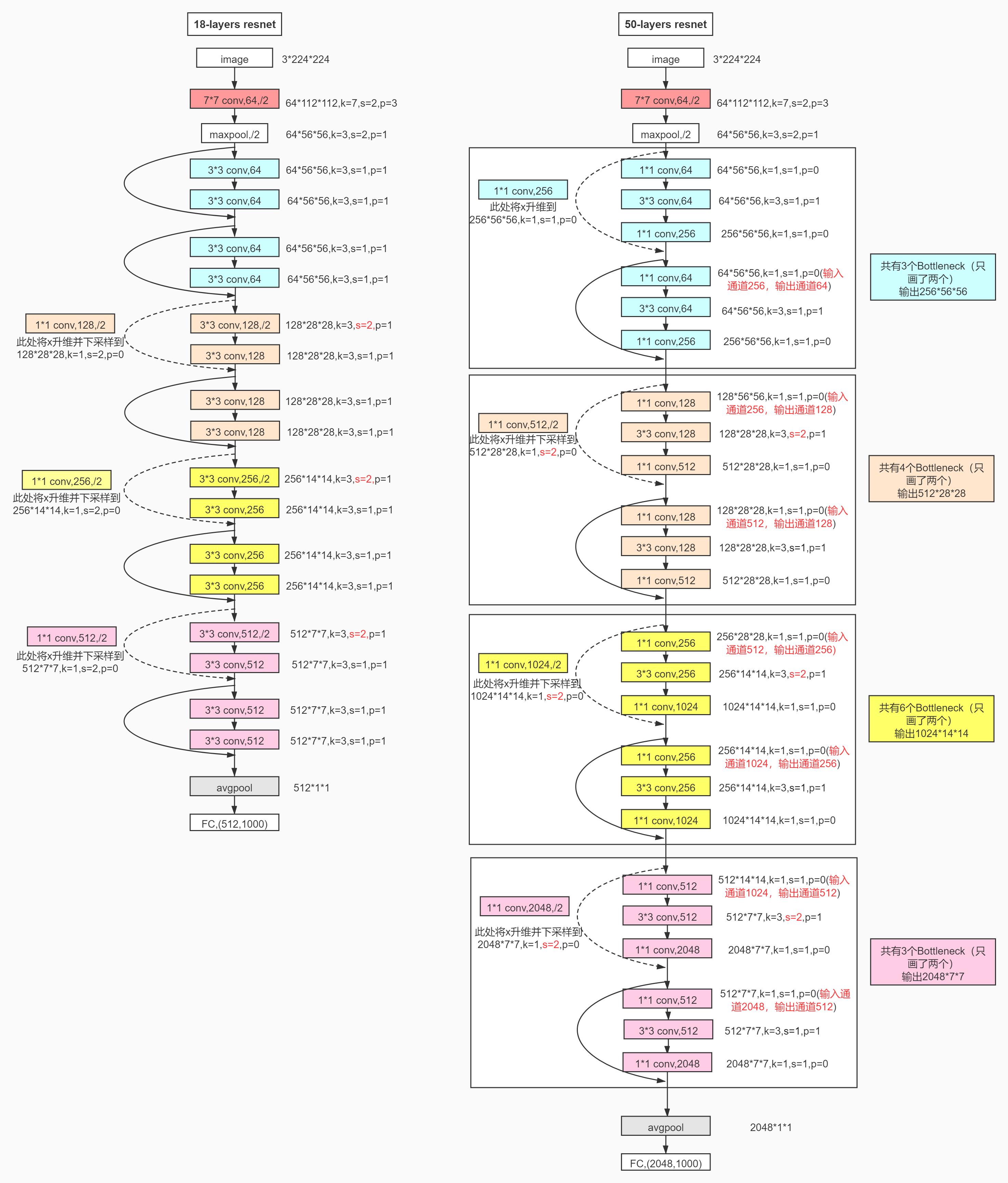
net.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
# ------------------------------------------------- #
# 作者:赵泽荣
# 时间:2021年9月10日(农历八月初四)
# 个人站点:1.https://zhao302014.github.io/
# 2.https://blog.csdn.net/IT_charge/
# 个人GitHub地址:https://github.com/zhao302014
# ------------------------------------------------- #
import torch
import torch.nn as nn
import torch.nn.functional as F
# --------------------------------------------------------------------------------- #
# 自己搭建一个 ResNet18 模型结构
# · 提出时间:2015 年(作者:何凯明)
# · ResNet 解决了深度 CNN 模型难训练的问题
# · ResNet 在 2015 名声大噪,而且影响了 2016 年 DL 在学术界和工业界的发展方向
# · ResNet 网络是参考了 VGG19 网络,在其基础上进行了修改,并通过短路机制加入了残差单元
# · 变化主要体现在 ResNet 直接使用 stride=2 的卷积做下采样,并且用 global average pool 层替换了全连接层
# · ResNet 的一个重要设计原则是:当 feature map 大小降低一半时,feature map 的数量增加一倍,这保持了网络层的复杂度
# · ResNet18 的 18 指定的是带有权重的 18 层,包括卷积层和全连接层,不包括池化层和 BN 层
# · ResNet “跳层链接” 的代码体现在相同大小和相同特征图之间用 “+” 相连,而不是 concat
# --------------------------------------------------------------------------------- #
class MyResNet18(nn.Module):
def __init__(self):
super(MyResNet18, self).__init__()
# 第一层:卷积层
self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3)
self.bn1 = nn.BatchNorm2d(64)
# Max Pooling 层
self.s1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 第二、三层:“实线”卷积层
self.conv2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
self.bn3 = nn.BatchNorm2d(64)
# 第四、五层:“实线”卷积层
self.conv4 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.conv5 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
self.bn5 = nn.BatchNorm2d(64)
# 第六、七层:“虚线”卷积层
self.conv6_1 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=2, padding=1)
self.bn6_1 = nn.BatchNorm2d(128)
self.conv7_1 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1)
self.bn7_1 = nn.BatchNorm2d(128)
self.conv7 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=1, stride=2, padding=0)
self.bn7 = nn.BatchNorm2d(128)
# 第八、九层:“实线”卷积层
self.conv8 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1)
self.bn8 = nn.BatchNorm2d(128)
self.conv9 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1)
self.bn9 = nn.BatchNorm2d(128)
# 第十、十一层:“虚线”卷积层
self.conv10_1 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=2, padding=1)
self.bn10_1 = nn.BatchNorm2d(256)
self.conv11_1 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)
self.bn11_1 = nn.BatchNorm2d(256)
self.conv11 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=1, stride=2, padding=0)
self.bn11 = nn.BatchNorm2d(256)
# 第十二 、十三层:“实线”卷积层
self.conv12 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)
self.bn12 = nn.BatchNorm2d(256)
self.conv13 = nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1)
self.bn13 = nn.BatchNorm2d(256)
# 第十四、十五层:“虚线”卷积层
self.conv14_1 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=2, padding=1)
self.bn14_1 = nn.BatchNorm2d(512)
self.conv15_1 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.bn15_1 = nn.BatchNorm2d(512)
self.conv15 = nn.Conv2d(in_channels=256, out_channels=512, kernel_size=1, stride=2, padding=0)
self.bn15 = nn.BatchNorm2d(512)
# 第十六 、十七层:“实线”卷积层
self.conv16 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.bn16 = nn.BatchNorm2d(512)
self.conv17 = nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1)
self.bn17 = nn.BatchNorm2d(512)
# avg pooling 层
self.s2 = nn.AvgPool2d(kernel_size=7, stride=1, padding=0)
# 第十八层:全连接层
self.Flatten = nn.Flatten()
self.f18 = nn.Linear(512, 1000)
# 为满足该实例另加 ↓
self.f_output = nn.Linear(1000, 10)
def forward(self, x): # shape: torch.Size([1, 3, 224, 224])
x = self.conv1(x) # shape: torch.Size([1, 64, 112, 112])
x = self.bn1(x) # shape: torch.Size([1, 64, 112, 112])
x = self.s1(x) # shape: torch.Size([1, 64, 56, 56])
x = self.conv2(x) # shape: torch.Size([1, 64, 56, 56])
x = self.bn2(x) # shape: torch.Size([1, 64, 56, 56])
x = self.conv3(x) # shape: torch.Size([1, 64, 56, 56])
x = self.bn3(x) # shape: torch.Size([1, 64, 56, 56])
x = self.conv4(x) # shape: torch.Size([1, 64, 56, 56])
x = self.bn4(x) # shape: torch.Size([1, 64, 56, 56])
x = self.conv5(x) # shape: torch.Size([1, 64, 56, 56])
x = self.bn5(x) # shape: torch.Size([1, 64, 56, 56])
x6_1 = self.conv6_1(x) # shape: torch.Size([1, 128, 28, 28])
x7_1 = self.conv7_1(x6_1) # shape: torch.Size([1, 128, 28, 28])
x7 = self.conv7(x) # shape: torch.Size([1, 128, 28, 28])
x = x7 + x7_1 # shape: torch.Size([1, 128, 28, 28])
x = self.conv8(x) # shape: torch.Size([1, 128, 28, 28])
x = self.conv9(x) # shape: torch.Size([1, 128, 28, 28])
x10_1 = self.conv10_1(x) # shape: torch.Size([1, 256, 14, 14])
x11_1 = self.conv11_1(x10_1) # shape: torch.Size([1, 256, 14, 14])
x11 = self.conv11(x) # shape: torch.Size([1, 256, 14, 14])
x = x11 + x11_1 # shape: torch.Size([1, 256, 14, 14])
x = self.conv12(x) # shape: torch.Size([1, 256, 14, 14])
x = self.conv13(x) # shape: torch.Size([1, 256, 14, 14])
x14_1 = self.conv14_1(x) # shape: torch.Size([1, 512, 7, 7])
x15_1 = self.conv15_1(x14_1) # shape: torch.Size([1, 512, 7, 7])
x15 = self.conv15(x) # shape: torch.Size([1, 512, 7, 7])
x = x15 + x15_1 # shape: torch.Size([1, 512, 7, 7])
x = self.conv16(x) # shape: torch.Size([1, 512, 7, 7])
x = self.conv17(x) # shape: torch.Size([1, 512, 7, 7])
x = self.s2(x) # shape: torch.Size([1, 512, 1, 1])
x = self.Flatten(x) # shape: shape: torch.Size([1, 512])
x = self.f18(x) # shape: torch.Size([1, 1000])
# 为满足该实例另加 ↓
x = self.f_output(x) # shape: torch.Size([1, 10])
x = F.softmax(x, dim=1) # shape: torch.Size([1, 10])
return x
if __name__ == '__main__':
x = torch.randn(1, 3, 224, 224)
model = MyResNet18()
y = model(x)train.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
# ------------------------------------------------- #
# 作者:赵泽荣
# 时间:2021年9月10日(农历八月初四)
# 个人站点:1.https://zhao302014.github.io/
# 2.https://blog.csdn.net/IT_charge/
# 个人GitHub地址:https://github.com/zhao302014
# ------------------------------------------------- #
import torch
from torch import nn
from net import MyResNet18
import numpy as np
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
data_transform = transforms.Compose([
transforms.Scale(224), # 缩放图像大小为 224*224
transforms.ToTensor() # 仅对数据做转换为 tensor 格式操作
])
# 加载训练数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_transform, download=True)
# 给训练集创建一个数据集加载器
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=8, shuffle=True)
# 加载测试数据集
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_transform, download=True)
# 给测试集创建一个数据集加载器
test_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=8, shuffle=True)
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else 'cpu'
# 调用 net 里定义的模型,如果 GPU 可用则将模型转到 GPU
model = MyResNet18().to(device)
# 定义损失函数(交叉熵损失)
loss_fn = nn.CrossEntropyLoss()
# 定义优化器(SGD:随机梯度下降)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)
# 学习率每隔 10 个 epoch 变为原来的 0.1
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
loss, current, n = 0.0, 0.0, 0
for batch, (X, y) in enumerate(dataloader):
# 单通道转为三通道
X = np.array(X)
X = X.transpose((1, 0, 2, 3)) # array 转置
image = np.concatenate((X, X, X), axis=0)
image = image.transpose((1, 0, 2, 3)) # array 转置回来
image = torch.tensor(image) # 将 numpy 数据格式转为 tensor
# 前向传播
image, y = image.to(device), y.to(device)
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred) / output.shape[0]
# 反向传播
optimizer.zero_grad()
cur_loss.backward()
optimizer.step()
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
print('train_loss:' + str(loss / n))
print('train_acc:' + str(current / n))
# 定义测试函数
def test(dataloader, model, loss_fn):
# 将模型转换为验证模式
model.eval()
loss, current, n = 0.0, 0.0, 0
# 非训练,推理期用到(测试时模型参数不用更新,所以 no_grad)
with torch.no_grad():
for batch, (X, y) in enumerate(dataloader):
# 单通道转为三通道
X = np.array(X)
X = X.transpose((1, 0, 2, 3)) # array 转置
image = np.concatenate((X, X, X), axis=0)
image = image.transpose((1, 0, 2, 3)) # array 转置回来
image = torch.tensor(image) # 将 numpy 数据格式转为 tensor
image, y = image.to(device), y.to(device)
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred) / output.shape[0]
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
print('test_loss:' + str(loss / n))
print('test_acc:' + str(current / n))
# 开始训练
epoch = 100
for t in range(epoch):
lr_scheduler.step()
print(f"Epoch {t + 1}\\n----------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
torch.save(model.state_dict(), "save_model/{}model.pth".format(t)) # 模型保存
print("Done!")test.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
# ------------------------------------------------- #
# 作者:赵泽荣
# 时间:2021年9月10日(农历八月初四)
# 个人站点:1.https://zhao302014.github.io/
# 2.https://blog.csdn.net/IT_charge/
# 个人GitHub地址:https://github.com/zhao302014
# ------------------------------------------------- #
import torch
from net import MyResNet18
import numpy as np
from torch.autograd import Variable
from torchvision import datasets, transforms
from torchvision.transforms import ToPILImage
data_transform = transforms.Compose([
transforms.Scale(224), # 缩放图像大小为 224*224
transforms.ToTensor() # 仅对数据做转换为 tensor 格式操作
])
# 加载训练数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_transform, download=True)
# 给训练集创建一个数据集加载器
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=8, shuffle=True)
# 加载测试数据集
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_transform, download=True)
# 给测试集创建一个数据集加载器
test_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=8, shuffle=True)
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else 'cpu'
# 调用 net 里定义的模型,如果 GPU 可用则将模型转到 GPU
model = MyResNet18().to(device)
# 加载 train.py 里训练好的模型
model.load_state_dict(torch.load("./save_model/99model.pth"))
# 获取预测结果
classes = [
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9",
]
# 把 tensor 转成 Image,方便可视化
show = ToPILImage()
# 进入验证阶段
model.eval()
# 对 test_dataset 里 10000 张手写数字图片进行推理
for i in range(len(test_dataset)):
x, y = test_dataset[i][0], test_dataset[i][1]
# tensor格式数据可视化
show(x).show()
# 扩展张量维度为 4 维
x = Variable(torch.unsqueeze(x, dim=0).float(), requires_grad=False).to(device)
# 单通道转为三通道
x = x.cpu()
x = np.array(x)
x = x.transpose((1, 0, 2, 3)) # array 转置
x = np.concatenate((x, x, x), axis=0)
x = x.transpose((1, 0, 2, 3)) # array 转置回来
x = torch.tensor(x).to(device) # 将 numpy 数据格式转为 tensor,并转回 cuda 格式
with torch.no_grad():
pred = model(x)
# 得到预测类别中最高的那一类,再把最高的这一类对应classes中的哪一个标签
predicted, actual = classes[torch.argmax(pred[0])], classes[y]
# 最终输出预测值与真实值
print(f'Predicted: "{predicted}", Actual: "{actual}"')
© 2021 GitHub, Inc.欢迎大家交流评论,一起学习
希望本文能帮助您解决您在这方面遇到的问题
感谢阅读
END
以上是关于「深度学习一遍过」必修23:基于ResNet18的MNIST手写数字识别的主要内容,如果未能解决你的问题,请参考以下文章