❤️StringStringBuilderStringBuffer详解❤️(附原理测试case建议收藏)
Posted 哪 吒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❤️StringStringBuilderStringBuffer详解❤️(附原理测试case建议收藏)相关的知识,希望对你有一定的参考价值。
一、String类简介
String类位于java.lang包下,是Java语言的核心类,提供了字符串的比较、查找、截取、大小写转换等操作,可以使用“+”连接其他对象,String类的部分源码如下
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
/** Cache the hash code for the string */
private int hash; // Default to 0
...
}从上面可以看出
- String类被final关键字修饰,意味着String类不能被继承,并且它的成员方法都默认为final方法;字符串一旦创建就不能再修改;
- String类实现了Serializable、CharSequence、 Comparable接口;
- tring实例的值是通过字符数组实现字符串存储的;
二、“+”连接符
1、“+”连接符的实现原理
字符串连接是通过 StringBuilder(或 StringBuffer)类及其append 方法实现的,对象转换为字符串是通过 toString 方法实现的,该方法由 Object 类定义,并可被 Java 中的所有类继承。
我们可以通过反编译验证一下:
public class Test {
public static void main(String[] args) {
int i = 10;
String s = "哪吒";
System.out.println(s + i);
}
}
/**
* 反编译后
*/
public class Test {
public static void main(String args[]) {
...
byte byte0 = 10;
String s = "哪吒";
System.out.println((new StringBuilder()).append(s).append(byte0).toString());
}
}从上面的代码就可以看出“+”连接字符串的底层,实际上就是StringBuilder对象通过append,再调用toString完成的。
2、“+”连接符的效率
使用“+”连接符时,JVM会隐式的创建StringBuilder对象,这种方式在大部分情况下不会造成效率的损失,但是,在循环中进行字符串拼接时就不一样了。
因为会创建大量的StringBuilder对象在堆内存中,这肯定是不允许的,所以这时就建议在循环外创建一个StringBuilder对象,然后循环内调用append方法进行手动拼接。
还有一种特殊情况,如果“+”拼接的是字符串常量中的字符串时,编译器会进行优化,直接将两个字符串常量拼接好。
所以,“+”连接符对于直接相加的字符串常量效率很高,因为在编译期间便确定了它的值;但对于间接相加的情况效率就会变低,建议单线程时使用StringBuilder,多线程时使用StringBuffer替代。
三、String、StringBuilder和StringBuffer
1、主要区别
- String是不可变字符序列,StringBuilder和StringBuffer是可变字符序列。
- 执行速度StringBuilder > StringBuffer > String。
- StringBuilder是非线程安全的,StringBuffer是线程安全的。
2、效率测试
import java.util.ArrayList;
import java.util.List;
import java.util.StringJoiner;
public class StringTest {
private static void test01() {
String str = "哪吒,";
String ret = "";
System.out.println("+字符串拼接开始...");
long start = System.currentTimeMillis();
// + 在循环中的效率太低,用10万条测试吧
for (int i = 0; i < 100000; i++) {
ret += str;
}
long end = System.currentTimeMillis();
System.out.println("+号拼接10万条数据耗时:"+(end-start)+"ms");//18288ms
System.out.println("************");
}
private static void test02() {
String str = "哪吒,";
StringBuilder builder = new StringBuilder();
System.out.println("StringBuilder,字符串拼接开始...");
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
builder.append(str);
}
long end = System.currentTimeMillis();
System.out.println("StringBuilder拼接1000万条数据耗时:"+(end-start)+"ms");//168ms,173ms,239ms
System.out.println("************");
}
private static void test03() {
String str = "哪吒,";
StringBuffer buffer = new StringBuffer();
System.out.println("StringBuffer,字符串拼接开始...");
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
buffer.append(str);
}
long end = System.currentTimeMillis();
System.out.println("StringBuffer拼接1000万条数据耗时:"+(end-start)+"ms");//527ms,343ms,398ms
System.out.println("************");
}
/**
* StringJoiner的效率明显高于List + StringJoiner
*/
private static void test04() {
String str = "哪吒";
StringJoiner join = new StringJoiner(",");
System.out.println("StringJoiner,字符串拼接开始...");
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
join.add(str);
}
long end = System.currentTimeMillis();
System.out.println("StringJoiner拼接1000万条数据耗时:"+(end-start)+"ms");//184ms,316ms,243ms
System.out.println("************");
}
private static void test05() {
String str = "哪吒";
List<String> list = new ArrayList<String>();
System.out.println("List + StringJoiner,字符串拼接开始...");
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
list.add(str);
}
String ret = String.join(",", list);
long end = System.currentTimeMillis();
System.out.println("List + StringJoiner拼接1000万条数据耗时:"+(end-start)+"ms");//563ms,477ms,585ms
System.out.println("************");
}
public static void main(String[] args) {
test02();
}
}
3、控制台输出
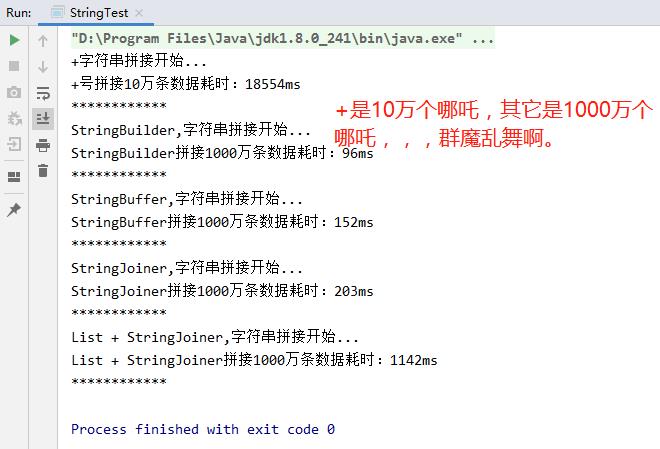
总结:StringBuilder效率最高,+拼接效率最低。
4、源码分析
StringBuilder的源码
@Override
public StringBuilder append(char[] str) {
super.append(str);
return this;
} StringBuilder继承AbstractStringBuilder类
public final class StringBuilder
extends AbstractStringBuilder
implements java.io.Serializable, CharSequence
{
...
}public AbstractStringBuilder append(String str) {
if (str == null)
return appendNull();
int len = str.length();
ensureCapacityInternal(count + len);
str.getChars(0, len, value, count);
count += len;
return this;
}append会直接拷贝字符到内部的字符数组中,如果字符数组长度不够,会进行扩展。
StringBuffer和StringBuilder的情况类似,只不过StringBuffer是线程安全的而已。
四、字符串常量池
1、百度百科
常量池在java用于保存在编译期已确定的,已编译的class文件中的一份数据。它包括了关于类,方法,接口等中的常量,也包括字符串常量,如String s = "java"这种申明方式;当然也可扩充,执行器产生的常量也会放入常量池,故认为常量池是JVM的一块特殊的内存空间。
2、字符串的对象分配
字符串的对象分配是需要消耗大量的时间和空间的,而且字符串使用的非常多,很多初级程序员,会将所有的变量都定义为String,不知你年轻的时候是不是这样,哈哈。
JVM为了提高性能和减少内存的开销,在实例化字符串的时候进行了一系列的优化,那就是字符串常量池。JVM会先检查字符串常量池,如果已经存在,就直接返回字符串常量池中的实例引用,如果不存在,就会实例化该字符串并将其放到字符串常量池中。由于String的不可变性,常量池中一定不存在两个相同的字符串。
3、内存区域
在HotSpot VM中字符串常量池是通过一个StringTable类实现的,它是一个Hash表,默认值大小长度是1009;这个StringTable在每个HotSpot VM的实例中只有一份,被所有的类共享;字符串常量由一个一个字符组成,放在了StringTable上。要注意的是,如果放进String Pool的String非常多,就会造成Hash冲突严重,从而导致链表会很长,而链表长了后直接会造成的影响就是当调用String.intern时性能会大幅下降。
4、举个例子一目了然
public class StringTest {
public static void main(String[] args) {
// 1. 新建一个引用s1指向堆中的对象s1,值为"CSDN哪吒"
String s1=new String("CSDN")+new String("哪吒");
// 2. 新建一个引用s2指向堆中的对象s2,值为"CSDN哪吒"
String s2=new String("CS")+new String("DN哪吒");
// 3. 执行s1.intern()会在字符串常量池中新建一个引用"CSDN哪吒",该引用指向s1在堆中的地址,并新建一个引用s3指向字符串常量池中的"CSDN哪吒"
String s3=s1.intern();
// 4. 执行s2.intern()不会在字符串常量池中创建新的引用,因为"CSDN哪吒"已存在,因此只执行了新建一个引用s4指向字符串常量池中"CSDN哪吒"的操作
String s4=s2.intern();
// s3和s4指向的都是字符串常量池中的"CSDN哪吒",而这个"CSDN哪吒"都指向堆中s1的地址
System.out.println(s1==s3); // true
System.out.println(s1==s4); // true
// s3和s4最终关联堆中的地址是对象s1
System.out.println(s2 == s3);// false
System.out.println(s2 == s4);// false
}
}
五、intern()方法
直接使用双引号声明出来的String对象会直接存储在字符串常量池中,如果不是用双引号声明的String对象,可以使用String提供的intern方法。intern 方法是一个native方法,intern方法会从字符串常量池中查询当前字符串是否存在,如果存在,就直接返回当前字符串;如果不存在就会将当前字符串放入常量池中,之后再返回。
JDK1.7的改动:
- 将String常量池 从 Perm 区移动到了 Java Heap区
- String.intern() 方法时,如果存在堆中的对象,会直接保存对象的引用,而不会重新创建对象。
🔥联系作者,或者扫描主页二维码加群,加入我们吧🔥
往期精彩内容
Java学习路线总结❤️搬砖工逆袭Java架构师❤️(全网最强,建议收藏)
❤️连续面试失败后,我总结了57道面试真题❤️,如果时光可以倒流...(附答案,建议收藏)
以上是关于❤️StringStringBuilderStringBuffer详解❤️(附原理测试case建议收藏)的主要内容,如果未能解决你的问题,请参考以下文章