测试总复习
Posted 逍遥ovo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了测试总复习相关的知识,希望对你有一定的参考价值。
答疑
测试
概念:验证软件是否满足用户需求
测试和开发的区别
调试和测试
-
目的
测试:检查软件是否实现了应该实现的功能;
调试:是程序员检查软件是否实现了该代码应该实现的功能。 -
角色
开发:程序员
测试:测试人员和开发人员 -
阶段
开发:只在开发阶段调试
测试:在软件开发的整个生命周期
技术
测试:技术要求广,但是深度低一些。要求使用各种工具和懂一些语言
开发:技术要求专一,深度高
为什么选择软件测试
- 兴趣
- 技能
- 抗压能力
- 责任感
为什么不做开发,而做测试
学习了开发知识 ==> 了解到软件测试 ==> 感兴趣 ==> 学习开发更好地进行测试
概念
需求
概念:满足用户需求或正式文档所需的权限和技能
测试人员在需求阶段就介入了测试
用户需求:用户想干什么,吃红烧肉
软件需求:做红烧肉需要干什么?买肉、买佐料等
BUG
概念:当且仅当规格说明存在且合理的情况下,软件的功能和需求规格说明不符合,说明是软件错误;
当软件规格说明不存在,用户需求合理,软件功能和需求规格不相符,说明软件错误。
也就是说,不管规格说明存在与否,只要用户需求合理,但是软件功能和需求规格说明不符合,则是 bug
测试用例
概念:向测试系统发起的一组集合;包含:测试环境、测试步骤、测试数据、预期结果、标题、测试功能模块、优先级、重要性等。
开发模型
瀑布模型
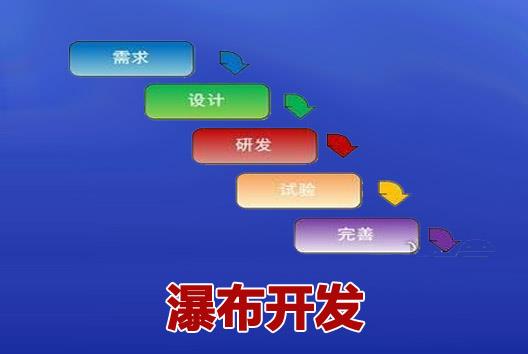
螺旋模型
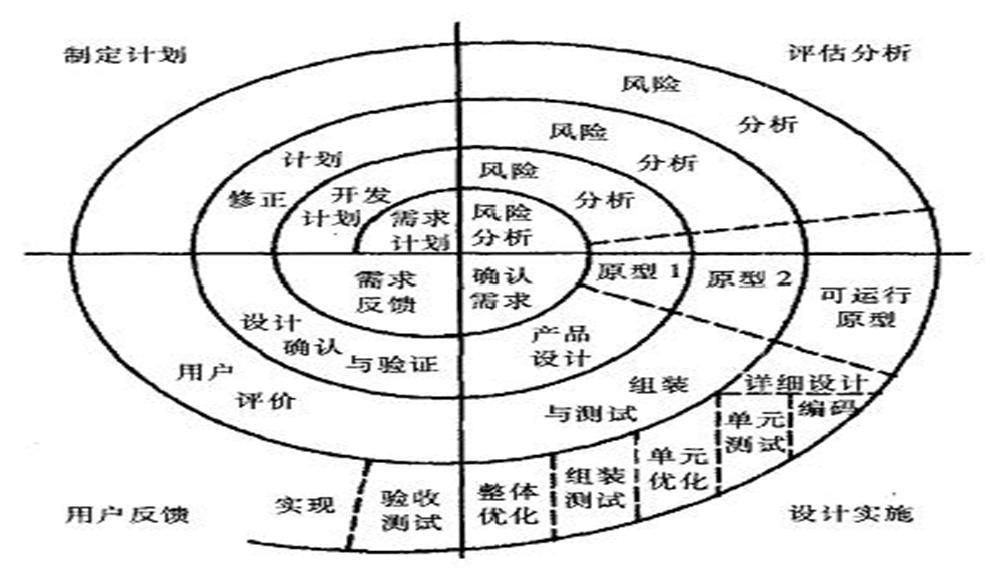
迭代、增量模型

敏捷模型

角色:产品经理(PO)、项目经理(SM)、研发团队(ST)
产品发布会议 ==> 迭代计划会议 ==> 开发期间每日站会 ==> 演示会议 ==> 回顾会议
软件测试模型
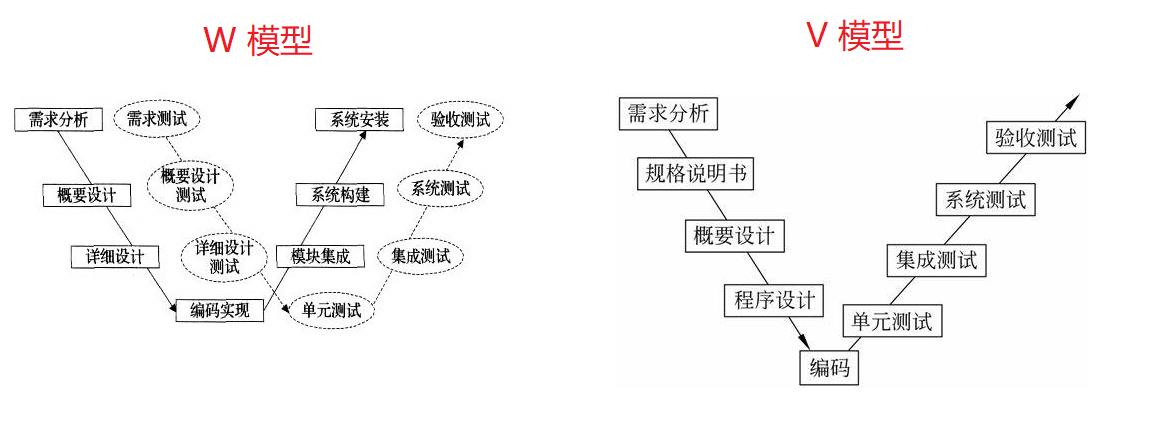
测试人员什么时候开始介入测试的?
- W 模型中,在需求分析时介入;
缺点:串行执行,不支持敏捷开发;
V 模型中,在编码后介入。
缺点:无法在需求阶段介入
基础
软件测试流程(软件测试生命周期)
需求分析 ==> 测试计划 ==> 测试设计 / 开发 ==> 测试执行 ==> 测试报告
如何描述一个 BUG
测试版本(系统版本) + 测试环境(浏览器版本等) + 测试步骤 + 测试数据 + 预期结果 + 实际结果 + 附件(错误截图、错误日志)
BUG 级别
崩溃
严重
一般
建议
系统新功能上线,发现用户在使用某一个功能时崩溃了,且无法修复,这个时候测试人员如何处理?
- 回退版本(系统稳定的版本)
- 抓紧实现修复问题
BUG 的生命周期

开发人员修复一个 BUG 后,测试的时候任然发现 BUG 存在,可能的原因
- 开发检查,修复代码后是否提交新代码;
- 测试人员没有重新提取测试环境的代码;
- 确实是开发人员没有修改成功。
如何处理测试人员和开发人员因为 BUG 产生冲突怎么办?
- 检查自身 BUG 描述是否清楚,BUG 检查是否正确;
- 站在用户的角度去说服开发人员;
- BUG 的定级有理有据,不要夸大其词;
- 测试人员不断提高自己的水平,能够发现 BUG 及其产生的原因,还有解决方案;
- 开三方会议(产品经理、开发人员、测试人员)一起讨论 BUG 解决方案。
用例
设计测试用例依据
根据需求来设计测试用例
分析需求、细化需求、从需求中提取功能点 / 测试点,然后再用设计测试的具体方法设计测试用例;
黑盒测试设计测用例方法
等价类、边界值、因果图、场景设计法、错误猜测法、正交法
测试用例设计方法
等价类
概念:把输入(特殊情况才考虑输出)划分成若干个等价类,从每一个等价类当中选取一个测试用例进行测试,如果这个测试用例通过,就说明这个测试用例代表的等价类测试通过。
使用情况:测试用例太多无法穷举
有效等价类:对该功能输入有意义的输入(输入合法的用户名)
无效等价类:对该功能输入无意义的输入(输入不合法的用户名)
边界值
概念:针对输入的边界进行测试用例的设计
因果图
使用情况:输入有多个条件,并且输入不同组合对应着不同输入
逻辑关系:与 或 非 恒等
使用步骤:分析可能的输入和输出 ==> 找出输入与输出之间的优惠 ==> 画出因果图 ==> 将因果图画出判定表 ==> 根据判定表写测试用例
-
分析可能的输入输出
输入:订单提交、金额大于 300、有红包
输出:有优惠、无优惠 -
找出输入与输出之间的优惠

-
画因果图

-
画判定表:有 3 个输入,2 个输出,对应的列数 2^3 = 8

场景法
概念:把系统中一个一个孤立的功能点按照一定的逻辑组合起来,形成一个场景 / 业务,针对场景进行测试
首先确定场景中的每一个功能点,确定功能点可能的输入和不同的输出
错误猜测法
概念:根据测试人员的直觉、经验、知识去判断系统某一模块的问题,有针对性的设计测试用例
正交法
概念:研究多因素(不同的输入)多水平(不同输入不同的取值)的一种测试用例设计方法,根据正交性,选出最优的输入组合进行试验,分析试验结果,用结果衡量整体试验的结果
TCP 和 UDP 协议怎么测试?
分别分析 TCP 与 UDP 的作用以及特点
TCP
作用:传输数据
特点:可靠(是否收到 ACK),三次握手(根据三次握手每次发送的信号不同进行测试),数据流,四次挥手等UDP
作用:传输数据
特点:数据报、不可靠、速度快。
进阶
按照开发阶段划分
单元测试
分类:Junit 单元测试框架(白盒)、unittest 单元测试框架(黑盒)
依据:详细设计文档
集成测试
概念:集成测试也称联合测试(联调)、组装测试,将程序模块采用适当的集成策略组装起来,对系统的接口及集成后的功能进行正确性检测的测试工作。集成主要目的是检查软件单位之间的接口是否正确。
测试方法:白盒测试
冒烟测试
冒烟测试的对象是每一个新编译的需要正式测试的软件版本,目的是确认软件基本功能正常,可以进行后续的正式测试工作,也就是系统测试。冒烟测试的执行者是版本编译人员。
系统测试
将软件系统看成是一个系统的测试。包括对功能、性能以及软件所运行的软硬件环境进行测试。时间大部分在系统测试执行阶段,包括回归测试和冒烟测试。
测试方法:黑盒测试
回归测试
概念:查看新引入的代码对旧的功能是否有影响
验收测试
验收测试是部署软件之前的最后一个测试操作。它是技术测试的最后一个阶段,也称为交付测试。验收测试的目的是确保软件准备就绪,按照项目合同、任务书、双方约定的验收依据文档,向软件购买都展示该软件系统满足原始
需求。
按实施组织划分
α测试
非测试、非开发人员进行测试
β测试
真实用户不分时间地点进行测试(内测)
按照是否手工划分
手工测试
手工测试就是由人去一个一个的输入用例,然后观察结果,和机器测试相对应,属于比较原始但是必须的一个。
优点:自动化无法替代探索性测试、发散思维结果的测试。
缺点:执行效率慢,量大易错。
自动化测试
编写自动化脚本,把设计的测试用例进行测试
自动化测试无法代替手工测试
是否运行代码
静态测试
不运行代码,分析代码进行测试
动态测试
运行代码,检查预期结果与实际结果的异同分析差异、运行效率、正确性等
按是否查看代码划分
黑盒测试(unittest)
把软件看成一个黑色盒子,不关心软件内部代码的逻辑结构实现,只关心输入输出
白盒测试(Junit)
测试程序的内部逻辑、结构的实现,是否实现了相应的功能
测试方法:语句覆盖、逻辑覆盖(判定覆盖 / 条件覆盖 / 判定组合 / 条件组合 / 判定和条件组合) 、路径覆盖(if / else / try / catch)、循环覆盖(for / while)
按照测试对象划分
业务测试
概念:是测试人员把系统各个模块串接起来运行、模拟真实用户实际的工作流程,满足用户需求定义的功能来进行测试的
过程。
界面测试
- 布局排盘
- 字体大小、粗细等
- 图片是否清晰
- 页面的控件(按钮、滚动条、CheckBox 等)
容错性测试
概念:当系统由于外界原因发生异常时,能自我处理,不把异常直接展现给用户,给用户一个友好的提示
易用性测试
易用性(Useability)是交互的适应性、功能性和有效性的集中体现。易用性属于人体工程学的范畴,人体工程学(ergonomics)是一门将日常使用的东西设计为易于使用和实用性强的学科
兼容性
兼容性主要是指软件之间能否很好的运做,会不会有影响、软件和硬件之间能否发挥很好的效率工作,会不会影响导致系统的崩溃。
文档测试
在实际的测试中,最常见的是用户文件的测试,例如:手册说明书等。也会有一些公司对需求文档进行测试,来保证需求文档的质量。
性能测试
检查系统是否满足需求规格说明书中规定的性能。
安全性测试
安全测试是一个相对独立的领域,需要更多的专业知识。例如web的安全测试,需要熟悉各种网络协议
TCP\\HTTP,防火墙,CDN,熟悉各种操作系统的漏洞,熟悉路由器等。从软件来说,熟悉各种攻击手段,例如 SQL 注入、Xss 等。
内存泄漏测试
用户在分配了内存空间,没有回收,导致占用的内存越来越多。
自动化测试(selenium)
webdriver 基本使用
定位元素的方式
# 用 id 定位
输入框 id = kw 发送 张嘉文 到输入框
driver.find_element_by_id("kw").send_keys("张嘉文")
# 百度一下(提交搜索) click 点击
driver.find_element_by_id("su").click()
# 用 name 定位
driver.find_element_by_name("wd").send_keys("张嘉文")
driver.find_element_by_id("su").click()
# class name 定位
driver.find_element_by_class_name("s_ipt").send_keys("张嘉文")
driver.find_element_by_class_name("bg s_btn").click()
# link text 定位
driver.find_element_by_link_text("贴吧").click()
# partial 定位
driver.find_element_by_partial_link_text("吧").click()
# tag name 定位
driver.find_element_by_tag_name("")
# xpath 定位
driver.find_element_by_xpath("//*[@id='kw']").send_keys("张嘉文")
driver.find_element_by_xpath("//*[@id='su']").click()
# css selector
driver.find_element_by_css_selector("#kw").send_keys("张嘉文")
driver.find_element_by_css_selector("#su").click()
等待
time.sleep(3)
driver.implicitly_wait(3)
异同
同:与 time.wait(10) 相同的是, 两者如果等待 10s 都没有找到下一个需要的元素, 那么就会抛出异常
异:time.sleep() 是固定等待;而 driver.implicotly_wait() 则是等到找到就继续执行,而不是死等
得到浏览器标题和 URL
# 获得标题
driver.title
# 获得 URL
driver.current_url
浏览器窗口大小
# 设置浏览器窗口
driver.set_window_size(600,1000)
# 浏览器最大化
driver.maximize_window()
前进后退
# 前进
driver.forward()
# 后退
driver.back()
键盘
# 需要的包
from selenium.webdriver.common.keys import Keys
# 用法
driver.find_element_by_name("username").send_keys(Keys.CONTROL,'a')
driver.find_element_by_name("username").send_keys(Keys.CONTROL,'c')
driver.find_element_by_name("password").send_keys(Keys.ENTER)
鼠标
# 需要的包
from selenium.webdriver.common.action_chains import ActionChains
# 右击
name = driver.find_element_by_id("su")
ActionChains(driver).context_click(name).perform()
# 双击
ActionChains(driver).double_click(name1).perform()
多选 (CheckBox)
for input in inputs:
if input.get_attribute('type') == 'checkbox':
input.click()
下拉框
# 通过 css selector 定位
driver.find_element_by_css_selector("#ShippingMethod > option:nth-child(5)").click()
# 数组下标
options[2].click()
弹出框
driver.switch_to.alert.accept()
上传文件
driver.find_element_by_tag_name("input").send_keys("F:\\\\图片\\\\0.jpg")
层级框架

从默认框架到 f2,需要先到 f1;
从 f2 到默认框架,也需要先到 f1;
unittest 框架
测试固件
from selenium import webdriver
import unittest
import time
import os
# unittest.TestCase 的作用:Unit 这个类继承了 unittest.TestCase
class Unit(unittest.TestCase):
def setUp(self):
print("run setUp")
self.driver = webdriver.Chrome()
self.url = "https://www.baidu.com/"
self.driver.maximize_window()
def tearDown(self):
print("run tearDown")
self.driver.quit()
if __name__=="__main__":
unittest.main()
测试套件
from Test import unitDemo
from Test import unitDemo1
import unittest
def createsuite():
# addTest 每次把一个测试脚本的一个测试用例加载到测试套件
suite = unittest.TestSuite()
suite.addTest(unitDemo.Unit("test_Abaidu"))
suite.addTest(unitDemo.Unit("test_abaidu"))
suite.addTest(unitDemo1.Unit("test_cbaidu"))
suite.addTest(unitDemo1.Unit("test_Dbaidu"))
def createsuite1():
# 把一个测试脚本中的所有测试用例加载进入套件
suite = unittest.TestSuite()
suite.addTest(unittest.makeSuite(unitDemo.Unit))
suite.addTest(unittest.makeSuite(unitDemo1.Unit))
return suite
def createsuite2():
# TestLoader
# 把一个测试脚本中的所有测试用例加载进入套件
suite1 = unittest.TestLoader().loadTestsFromTestCase(unitDemo.Unit)
suite2 = unittest.TestLoader().loadTestsFromTestCase(unitDemo1.Unit)
suite = unittest.TestSuite([suite1, suite2])
return suite
def createsutie3():
# 把一个文件夹下所有以某种形式命名的测试脚本全部加入到测试套件
discover = unittest.defaultTestLoader.discover("../Test", pattern="unitDemo*.py",top_level_dir=None)
return discover
if __name__=="__main__":
suite = createsuite1()
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suite)
忽略测试用例执行
@unittest.skip("skipping")
# 注解:忽略测试用例执行
def test_abaidu(self):
driver = self.driver
url = "https://www.baidu.com/"
self.driver.get(url)
driver.find_element_by_id("kw").send_keys("猪头")
driver.find_element_by_id("su").click()
time.sleep(3)
title = driver.title
try:
self.assertEqual("猪头_百度一下", title, msg="不相等")
except:
self.saveScreenShot(self,driver,"猪头.png")
time.sleep(3)
断言
作用:判断预期结果与实际结果是否一致
# 断言
def test_abaidu(self):
driver = self.driver
url = "https://www.baidu.com/"
self.driver.get(url)
driver.find_element_by_id("kw").send_keys("猪头")
driver.find_element_by_id("su").click()
time.sleep(3)
title = driver.title
try:
self.assertEqual("猪头_百度一下", title, msg="不相等")
except:
self.saveScreenShot(self,driver,"猪头.png")
time.sleep(3)
截图
# 运行顺序 0-9 A-Z a-z
# 截图
def test_Abaidu(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element_by_id("kw").send_keys("是你")
driver.find_element_by_id("su").click()
time.sleep(3)
title = driver.title
print(title)
try:
self.assertEqual("123是你_百度一下",title,msg="不相等")
except:
self.saveScreenShot(driver,"是你.png")
time.sleep(3)
html
作用:所有结果输出到 HTML 报告中
import os
import sys
import time
import unittest
import HTMLTestRunner
def createsuite():
discovers = unittest.defaultTestLoader.discover("../Test", pattern="unitDemo*.py", top_level_dir=None)
print(discovers)
return discovers
if __name__=="__main__":
#1,创建一个文件夹
# 当前的路径
curpath = sys.path[0]
# sys.path 是一个路径集合数组
print(sys.path)
print(sys.path[0])
# 当前路径下resultreport文件夹不存在的时候,就创建一个
if not os.path.exists(curpath+'/resultreport'):
os.makedirs(curpath+'/resultreport')
# 2,解决重复命名的问题
now = time.strftime("%Y-%m-%d-%H %M %S", time.localtime(time.time()))
print(time.time())
print(time.localtime(time.time()))
# 文件名是路径加上文件的名称
# 准备HTML报告输出的文件
filename = curpath + '/resultreport/'+ now + 'resultreport.html'
# 打开 HTML 文件, wb 以写的方式
with open(filename, 'wb') as fp:
# 括号里的参数是 HTML 报告里面的参数
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u"测试报告",
description=u"用例执行情况", verbosity=2)
suite = createsuite()
runner.run(suite)
数据驱动
安装工具包:pip install ddt
from selenium import webdriver
import unittest
import time
from ddt import ddt, unpack, file_data, data
import sys, csv
def getTxt(file_name):
# ([猫, 猫_百度搜索], [狗, 狗_百度搜索], [猪, 猪_百度搜索])
rows = []
path = sys.path[0]
with open(path + '/data/' + file_name, 'rt',encoding='utf-8') as f:
readers = csv.reader(f, delimiter=',', quotechar='|')
next(readers, None)
for row in readers:
temprows=[]
# 猫, 猫_百度搜索
for i in row:
temprows.append(i)
rows.append(temprows)
return rows
def getCsv():
# 读取 csv 文件
values = []
with open('data/test_help_json.csv', encoding='utf-8') as f:
f_scv = csv.reader(f)
next(f_scv)
for i in f_scv:
values.append(i)
return values
@ddt
class Baidu(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.base_url = "http://www.baidu.com/"
self.driver.maximize_window()
self.verificationErrors=[]
self.accept_next_alert=True
def tearDown(self):
self.driver.quit()
self.assertEqual以上是关于测试总复习的主要内容,如果未能解决你的问题,请参考以下文章
什么是在 C++ 中获取总内核数量的跨平台代码片段? [复制]