OpenCV-字典法实现数字识别(尺寸归一化+图像差值)
Posted 翟天保Steven
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV-字典法实现数字识别(尺寸归一化+图像差值)相关的知识,希望对你有一定的参考价值。
作者:Steven
版权声明:著作权归作者所有,商业转载请联系作者获得授权,非商业转载请注明出处
实现原理
数字识别是图像处理学在现实生活中较多的应用之一,比如车牌识别、银行卡号识别、执照识别、文档文字OCR识别等等。如何实现数字识别呢?目前最为流行的就是运用AI、机器学习等技术结合图像处理学,大量训练数据集,以实现智能且精确的识别。说到人工智能,很多人可能觉得它非常深奥和复杂,其实说白了它最底层的识别逻辑还是基于普通的图像分析,像特征提取、轮廓分析、比对分析等等,再在庞大的数据集中按照相似程度,分析出一个最可能的结果。
本文提供了一种相对简单的思路来实现数字识别,适合初学图像处理的新人研究参考。该方法为字典法:首先对图像进行阈值二值化处理,并适当清理微小噪声区;再结合轮廓分析,分割识别图像中的图形区域(不一定全是数字,也可能有其他的图形),并将图形区域尺寸归一化;对字典数字图同样进行分割和尺寸归一化;运用图像差值法,将识别图像的子区域分别比对字典中所有的数字子图,取其中差值最低的数字作为识别数字,若识别完成所有的差值均高于阈值,则识别错误;最后,在原图中给识别成功的子区域绘制最小包围矩形,并在上方书写所识别的数字。
下方介绍具体流程。
具体流程
1)读取识别图像的原图和灰度图,读取字典图(灰度图)。将灰度图和字典图进行二值化处理。
cv::Mat src = imread("number.jpg");
cv::Mat gray = imread("number.jpg",0);
cv::Mat Template= imread("num.jpg", 0);
// 二值化
cv::Mat thresh,thresh_t;
cv::threshold(gray, thresh, 200, 255, THRESH_BINARY);
cv::threshold(Template, thresh_t,200, 255, THRESH_BINARY);

2)若识别图像中数字为深色,背景为白色,则反相;若同字典类似,数字为白,背景为黑,则不动。
// 反相
vector<Point> points;
findNonZero(thresh, points);
if (points.size() > (gray.rows*gray.cols / 2))
{
thresh = 255 - thresh;
}3)Clear_MicroConnected_Areas函数清除二值图中的微小噪声区,函数具体介绍见:
4)确认识别图像和字典图的轮廓区。
// 寻找轮廓
vector<vector<Point>> contour,contour_t;
vector<Vec4i> hierarchy, hierarchy_t;
findContours(thresh, contour, hierarchy, RETR_EXTERNAL, CHAIN_APPROX_NONE);
findContours(thresh_t, contour_t, hierarchy_t, RETR_EXTERNAL, CHAIN_APPROX_NONE);5)用GetSubarea函数实现子区域提取。
// 获取子区域集合
vector<cv::Mat> GetSubarea(cv::Mat src, vector<vector<Point>> contour, vector<Vec4i> hierarchy)
{
vector<cv::Mat> result;
if (!contour.empty() && !hierarchy.empty())
{
std::vector<std::vector<cv::Point> >::const_iterator itc = contour.begin();
// 遍历所有轮廓
while (itc != contour.end())
{
// 定位当前轮廓所在位置
cv::Rect rect = cv::boundingRect(cv::Mat(*itc));
cv::Mat temp = src(rect).clone();
result.push_back(temp);
itc++;
}
}
return result;
}6)用UniformSize函数实现子区域尺寸归一化。
// 统一尺寸
vector<cv::Mat> UniformSize(vector<cv::Mat> in)
{
vector<cv::Mat> result;
for (auto it = in.begin(); it != in.end(); ++it)
{
cv::Mat temp;
resize(*it,temp,Size(48,48));
result.push_back(temp);
}
return result;
}7)用NumberRecognition函数实现数字识别。该函数输入四个参数,分别为识别图像原图、识别图像尺寸归一后子区域容器、字典图尺寸归一后子区域容器和阈值参数。其中阈值参数用来判断两图的差异性。
// 数字识别
cv::Mat NumberRecognition(cv::Mat Thresh, vector<cv::Mat> sub_size, vector<cv::Mat> sub_t_size, vector<vector<Point>> contour,int thresh)
{
cv::Mat result = Thresh.clone();
for (int i = 0; i < sub_size.size(); ++i)
{
int min = 999999;
int idx = 0;
for (int j = 0; j < sub_t_size.size(); ++j)
{
int d = calcDiff(sub_size[i], sub_t_size[j]);
if (d < min)
{
min = d;
idx = j;
}
}
if (min < thresh)
{
cout << "第" << i + 1 << "个轮廓数字识别为:" << a[idx] << endl;
cv::Rect rect = cv::boundingRect(contour[i]);
rectangle(result, rect, Scalar(255,0,0), 1, 8);
putText(result, to_string(a[idx]), Point(rect.x, rect.y - 20), 1, 2, Scalar(0,0,255));
}
else {
cout << "第" << i + 1 << "个轮廓数字识别为: 空" << endl;
}
}
return result;
}// 对比图像差值
int calcDiff(cv::Mat src1, cv::Mat src2)
{
CV_Assert(src1.size() == src2.size());
cv::Mat dif;
cv::absdiff(src1, src2, dif);
Scalar Sum=cv::sum(dif);
return int(Sum[0] / 255);
}C++测试代码
#include <opencv2/opencv.hpp>
#include <iostream>
#include <algorithm>
#include <time.h>
using namespace cv;
using namespace std;
vector<cv::Mat> UniformSize(vector<cv::Mat> in);
vector<cv::Mat> GetSubarea(cv::Mat src,vector<vector<Point>> contour, vector<Vec4i> hierarchy);
int calcDiff(cv::Mat src1, cv::Mat src2);
void Clear_MicroConnected_Areas(cv::Mat src, cv::Mat &dst, double min_area);
cv::Mat NumberRecognition(cv::Mat Thresh, vector<cv::Mat> sub_size, vector<cv::Mat> sub_t_size, vector<vector<Point>> contour, int thresh);
int a[10] = { 7,0,9,8,6,5,4,3,2,1 };
int main()
{
cv::Mat src = imread("number.jpg");
cv::Mat gray = imread("number.jpg",0);
cv::Mat Template= imread("num.jpg", 0);
// 二值化
cv::Mat thresh,thresh_t;
cv::threshold(gray, thresh, 200, 255, THRESH_BINARY);
cv::threshold(Template, thresh_t,200, 255, THRESH_BINARY);
// 反相
vector<Point> points;
findNonZero(thresh, points);
if (points.size() > (gray.rows*gray.cols / 2))
{
thresh = 255 - thresh;
}
// 清除噪声区
Clear_MicroConnected_Areas(thresh, thresh, 200);
// 寻找轮廓
vector<vector<Point>> contour,contour_t;
vector<Vec4i> hierarchy, hierarchy_t;
findContours(thresh, contour, hierarchy, RETR_EXTERNAL, CHAIN_APPROX_NONE);
findContours(thresh_t, contour_t, hierarchy_t, RETR_EXTERNAL, CHAIN_APPROX_NONE);
// 分割子区域
vector<cv::Mat> sub = GetSubarea(thresh, contour, hierarchy);
vector<cv::Mat> sub_t = GetSubarea(thresh_t, contour_t, hierarchy_t);
// 子区域尺寸统一化
vector<cv::Mat> sub_size = UniformSize(sub);
vector<cv::Mat> sub_t_size = UniformSize(sub_t);
// 数字识别(字典法比对)
int t = 400;
cv::Mat result = NumberRecognition(src, sub_size, sub_t_size, contour, t);
imshow("original", src);
imshow("thresh", thresh);
imshow("result", result);
waitKey(0);
return 0;
}
// 获取子区域集合
vector<cv::Mat> GetSubarea(cv::Mat src, vector<vector<Point>> contour, vector<Vec4i> hierarchy)
{
vector<cv::Mat> result;
if (!contour.empty() && !hierarchy.empty())
{
std::vector<std::vector<cv::Point> >::const_iterator itc = contour.begin();
// 遍历所有轮廓
while (itc != contour.end())
{
// 定位当前轮廓所在位置
cv::Rect rect = cv::boundingRect(cv::Mat(*itc));
cv::Mat temp = src(rect).clone();
result.push_back(temp);
itc++;
}
}
return result;
}
// 统一尺寸
vector<cv::Mat> UniformSize(vector<cv::Mat> in)
{
vector<cv::Mat> result;
for (auto it = in.begin(); it != in.end(); ++it)
{
cv::Mat temp;
resize(*it,temp,Size(48,48));
result.push_back(temp);
}
return result;
}
// 对比图像差值
int calcDiff(cv::Mat src1, cv::Mat src2)
{
CV_Assert(src1.size() == src2.size());
cv::Mat dif;
cv::absdiff(src1, src2, dif);
Scalar Sum=cv::sum(dif);
return int(Sum[0] / 255);
}
// 清除小区域
void Clear_MicroConnected_Areas(cv::Mat src, cv::Mat &dst, double min_area)
{
// 备份复制
dst = src.clone();
std::vector<std::vector<cv::Point> > contours; // 创建轮廓容器
std::vector<cv::Vec4i> hierarchy;
// 寻找轮廓的函数
// 第四个参数CV_RETR_EXTERNAL,表示寻找最外围轮廓
// 第五个参数CV_CHAIN_APPROX_NONE,表示保存物体边界上所有连续的轮廓点到contours向量内
cv::findContours(src, contours, hierarchy, cv::RETR_EXTERNAL, cv::CHAIN_APPROX_NONE, cv::Point());
if (!contours.empty() && !hierarchy.empty())
{
std::vector<std::vector<cv::Point> >::const_iterator itc = contours.begin();
// 遍历所有轮廓
while (itc != contours.end())
{
// 定位当前轮廓所在位置
cv::Rect rect = cv::boundingRect(cv::Mat(*itc));
// contourArea函数计算连通区面积
double area = contourArea(*itc);
// 若面积小于设置的阈值
if (area < min_area)
{
// 遍历轮廓所在位置所有像素点
for (int i = rect.y; i < rect.y + rect.height; i++)
{
uchar *output_data = dst.ptr<uchar>(i);
for (int j = rect.x; j < rect.x + rect.width; j++)
{
// 将连通区的值置0
if (output_data[j] == 255)
{
output_data[j] = 0;
}
}
}
}
itc++;
}
}
}
// 数字识别
cv::Mat NumberRecognition(cv::Mat Thresh, vector<cv::Mat> sub_size, vector<cv::Mat> sub_t_size, vector<vector<Point>> contour,int thresh)
{
cv::Mat result = Thresh.clone();
for (int i = 0; i < sub_size.size(); ++i)
{
int min = 999999;
int idx = 0;
for (int j = 0; j < sub_t_size.size(); ++j)
{
int d = calcDiff(sub_size[i], sub_t_size[j]);
if (d < min)
{
min = d;
idx = j;
}
}
if (min < thresh)
{
cout << "第" << i + 1 << "个轮廓数字识别为:" << a[idx] << endl;
cv::Rect rect = cv::boundingRect(contour[i]);
rectangle(result, rect, Scalar(255,0,0), 1, 8);
putText(result, to_string(a[idx]), Point(rect.x, rect.y - 20), 1, 2, Scalar(0,0,255));
}
else {
cout << "第" << i + 1 << "个轮廓数字识别为: 空" << endl;
}
}
return result;
}测试效果
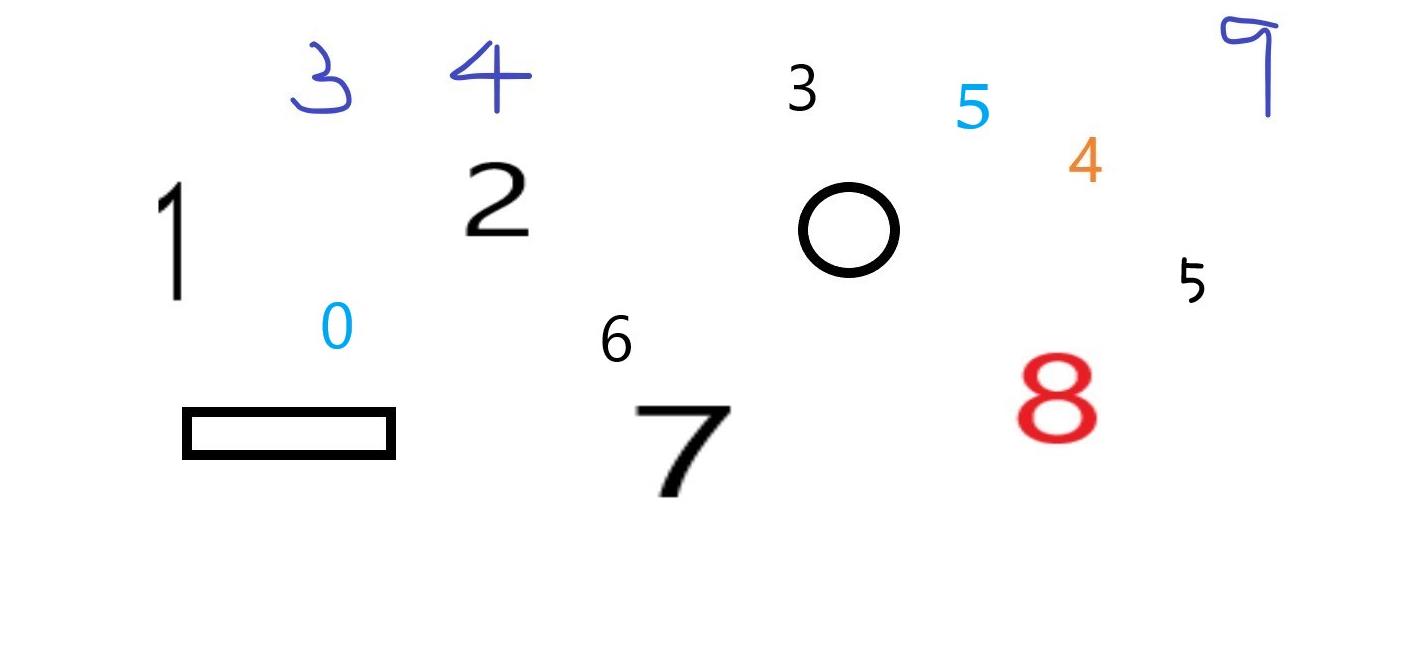

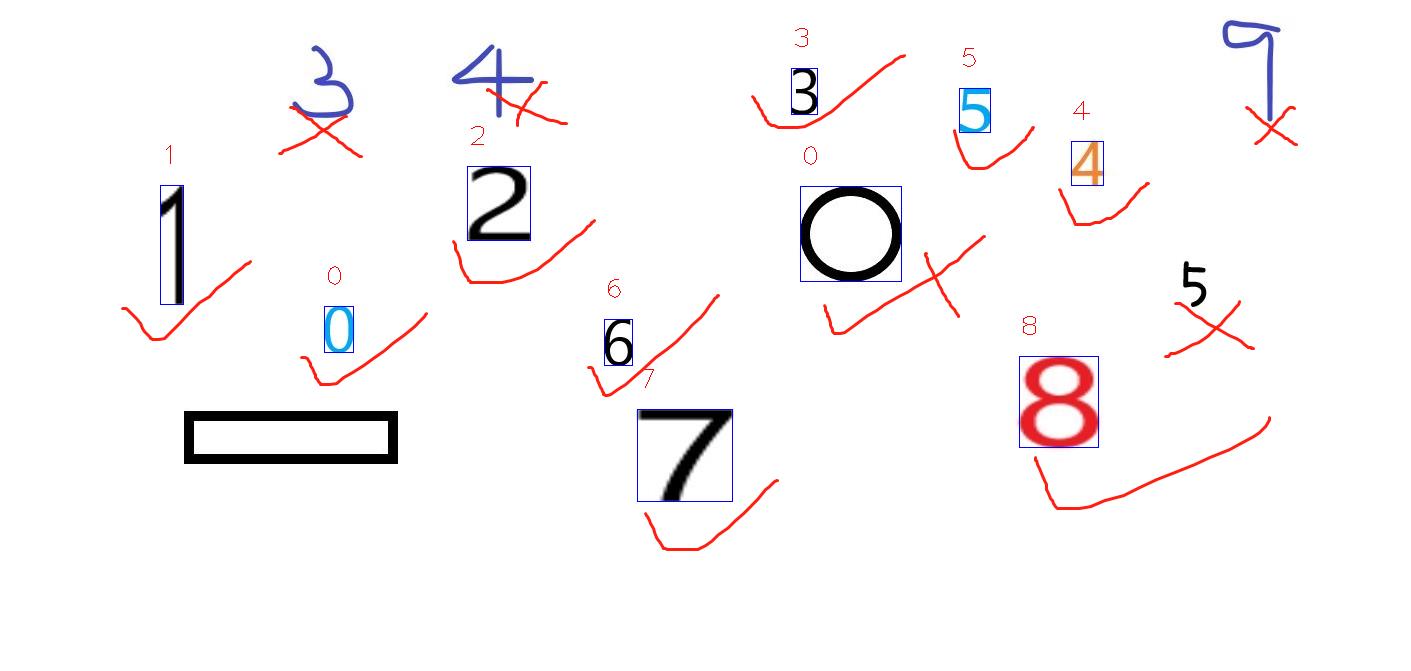
不难看出,字典的丰富性影响了识别的准确程度,当字体同字典数字字体类似,即使数字压缩变形也能识别出来,反之则不行。画了个圆识别为了0,emm哈哈哈。手写体用字典法很难做到,毕竟千人千样,字典量过大,程序计算时间就飞上去了。所以,该方法适合标准数字类型,即使是车牌或者信用卡卡号这种,只要提前做好字典都是可以实现的。
如果函数有什么可以改进完善的地方,非常欢迎大家指出,一同进步何乐而不为呢~
如果文章帮助到你了,可以点个赞让我知道,我会很快乐~加油!
以上是关于OpenCV-字典法实现数字识别(尺寸归一化+图像差值)的主要内容,如果未能解决你的问题,请参考以下文章