Pytorch Note55 迁移学习实战猫狗分类
Posted 风信子的猫Redamancy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch Note55 迁移学习实战猫狗分类相关的知识,希望对你有一定的参考价值。
Pytorch Note55 迁移学习实战猫狗分类
文章目录
全部笔记的汇总贴: Pytorch Note 快乐星球
在这一部分,我会用迁移学习的方法,实现kaggle中的猫狗分类,这是一个二分类的问题,我们可以直接使用修改我们的预训练的网络卷积部分提取我们自己图片的特征,对于我们的猫狗二分类,我们就用自己的分类全连接层就可以了。
加载数据集
数据集可以去https://www.kaggle.com/c/dogs-vs-cats/data下载,一个是训练集文件夹,一个是测试集文件夹。这两个文件内部都有两个文件夹:一个文件夹放狗的图片,一个文件夹中放猫的图片
下载完成后,我这里需要将我们的图片移动成以下格式,方便我们加载数据,如果还不清楚加载数据的话,具体可以看Note52 灵活的数据读取介绍
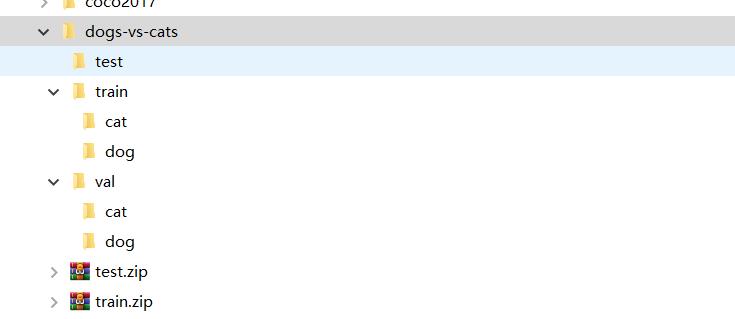
接着我们就可以用我们的代码载入数据了
首先导入我们需要的包
# import
import torch
import torchvision
from torchvision import transforms
from PIL import Image
import numpy as np
import torch.nn as nn
import torchvision.models as models
import os
import time
定义对数据的transforms,标准差和均值都是取ImageNet的标准差和均值,保持一致
transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
读入数据,如果要换自己的路径,可以换root
root = 'D:/data/dogs-vs-cats/'
trainset = torchvision.datasets.ImageFolder('D:/data/dogs-vs-cats/train',transform=transform)
valset = torchvision.datasets.ImageFolder('D:/data/dogs-vs-cats/val',transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,shuffle=True,num_workers=8)
valloader = torch.utils.data.DataLoader(valset, batch_size=64,shuffle=False,num_workers=8)
我设定我们的训练集中,我们猫狗图片各10000张,验证集图片猫狗各2500张。总共就是训练集有20000张,验证集有5000张
print(u"训练集个数:", len(trainset))
print(u"验证集个数:", len(valset))
训练集个数: 20000 验证集个数: 5000
trainset
Dataset ImageFolder Number of datapoints: 20000 Root location: D:/data/dogs-vs-cats/train StandardTransform Transform: Compose( Resize(size=256, interpolation=bilinear) CenterCrop(size=(224, 224)) ToTensor() Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) )
trainset.class_to_idx
{'cat': 0, 'dog': 1}
trainset.classes
['cat', 'dog']
trainset.imgs[0][0]
'D:/data/dogs-vs-cats/train\\\\cat\\\\cat.0.jpg'
随机打开一张图片
n = np.random.randint(0,20000)
Image.open(trainset.imgs[n][0])

trainset[0][0].shape
torch.Size([3, 224, 224])
迁移学习网络
import torch
import torch.nn as nn
import torchvision.models as models
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
定义训练模型的函数
def get_acc(outputs, label):
total = outputs.shape[0]
probs, pred_y = outputs.data.max(dim=1) # 得到概率
correct = (pred_y == label).sum().data
return correct / total
def train(net,path = './model.pth',epoches = 10, writer = None, verbose = False):
optimizer = torch.optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
criterion = nn.CrossEntropyLoss()
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,patience=3,factor=0.5,min_lr=1e-6)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
best_acc = 0
train_acc_list, val_acc_list = [],[]
train_loss_list, val_loss_list = [],[]
lr_list = []
for i in range(epoches):
start = time.time()
train_loss = 0
train_acc = 0
val_loss = 0
val_acc = 0
if torch.cuda.is_available():
net = net.to(device)
net.train()
for step,data in enumerate(trainloader,start=0):
im,label = data
im = im.to(device)
label = label.to(device)
optimizer.zero_grad()
# 释放内存
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
# formard
outputs = net(im)
loss = criterion(outputs,label)
# backward
loss.backward()
# 更新参数
optimizer.step()
train_loss += loss.data
train_acc += get_acc(outputs,label)
# 打印下载进度
rate = (step + 1) / len(trainloader)
a = "*" * int(rate * 50)
b = "." * (50 - int(rate * 50))
print('\\r train {:3d}|{:3d} {:^3.0f}% [{}->{}] '.format(i+1,epoches,int(rate*100),a,b),end='')
train_loss = train_loss / len(trainloader)
train_acc = train_acc * 100 / len(trainloader)
if verbose:
train_acc_list.append(train_acc)
train_loss_list.append(train_loss)
# print('train_loss:{:.6f} train_acc:{:3.2f}%' .format(train_loss ,train_acc),end=' ')
# 记录学习率
lr = optimizer.param_groups[0]['lr']
if verbose:
lr_list.append(lr)
# 更新学习率
scheduler.step(train_loss)
net.eval()
with torch.no_grad():
for step,data in enumerate(valloader,start=0):
im,label = data
im = im.to(device)
label = label.to(device)
# 释放内存
if hasattr(torch.cuda, 'empty_cache'):
torch.cuda.empty_cache()
outputs = net(im)
loss = criterion(outputs,label)
val_loss += loss.data
# probs, pred_y = outputs.data.max(dim=1) # 得到概率
# test_acc += (pred_y==label).sum().item()
# total += label.size(0)
val_acc += get_acc(outputs,label)
rate = (step + 1) / len(valloader)
a = "*" * int(rate * 50)
b = "." * (50 - int(rate * 50))
print('\\r test {:3d}|{:3d} {:^3.0f}% [{}->{}] '.format(i+1,epoches,int(rate*100),a,b),end='')
val_loss = val_loss / len(valloader)
val_acc = val_acc * 100 / len(valloader)
if verbose:
val_loss_list.append(val_loss)
val_acc_list.append(val_acc)
end = time.time()
print(
'\\rEpoch [{:>3d}/{:>3d}] Train Loss:{:>.6f} Train Acc:{:>3.2f}% Val Loss:{:>.6f} Val Acc:{:>3.2f}% Learning Rate:{:>.6f}'.format(
i + 1, epoches, train_loss, train_acc, val_loss, val_acc,lr), end='')
time_ = int(end - start)
h = time_ / 3600
m = time_ % 3600 /60
s = time_ % 60
time_str = "\\tTime %02d:%02d" % ( m, s)
# ====================== 使用 tensorboard ==================
if writer is not None:
writer.add_scalars('Loss', {'train': train_loss,
'valid': val_loss}, i+1)
writer.add_scalars('Acc', {'train': train_acc ,
'valid': val_acc}, i+1)
# writer.add_scalars('Learning Rate',lr,i+1)
# =========================================================
# 打印所用时间
print(time_str)
# 如果取得更好的准确率,就保存模型
if val_acc > best_acc:
torch.save(net,path)
best_acc = val_acc
Acc = {}
Loss = {}
Acc['train_acc'] = train_acc_list
Acc['val_acc'] = val_acc_list
Loss['train_loss'] = train_loss_list
Loss['val_loss'] = val_loss_list
Lr = lr_list
return Acc, Loss, Lr
定义一个测试的函数
import matplotlib.pyplot as plt
def test(path, model):
# 读取要预测的图片
img = Image.open(path).convert('RGB') # 读取图像
data_transform = transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
class_indict = ["cat", "dog"]
plt.imshow(img)
img = data_transform(img)
img = img.to(device)
img = torch.unsqueeze(img, dim=0)
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img))
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).data.cpu().numpy()
print(class_indict[predict_cla], predict[predict_cla].data.cpu().numpy())
plt.show()
if not os.path.exists('./model/'):
os.mkdir('./model')
1.AlexNet
# 导入Pytorch封装的AlexNet网络模型
alexnet = models.alexnet(pretrained=True)
# 固定卷积层参数
for param in alexnet.parameters():
param.requires_grad = False
# 获取最后一个全连接层的输入通道数
num_input = alexnet.classifier[6].in_features
# 获取全连接层的网络结构
feature_model = list(alexnet.classifier.children())
# 去掉原来的最后一层
feature_model.pop()
# 添加上适用于自己数据集的全连接层
feature_model.append(nn.Linear(num_input, 2))
# 仿照这里的方法,可以修改网络的结构,不仅可以修改最后一个全连接层
# 还可以为网络添加新的层
# 重新生成网络的后半部分
alexnet.classifier = nn.Sequential(*feature_model)
for param in alexnet.classifier.parameters():
param.requires_grad = True
alexnet = alexnet.to(device)
#打印一下
print(alexnet)
AlexNet( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) (1): ReLU(inplace=True) (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU(inplace=True) (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU(inplace=True) (8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU(inplace=True) (10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(6, 6)) (classifier): Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(i以上是关于Pytorch Note55 迁移学习实战猫狗分类的主要内容,如果未能解决你的问题,请参考以下文章