Java面试 —— MySQL相关
Posted JohnnyLin00
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java面试 —— MySQL相关相关的知识,希望对你有一定的参考价值。
mysql 相关
数据库基础
什么是事务?
事务(transaction)是作为一个单元的一组有序的数据库操作。如果组中的所有操作都成功,则认为事务成功。即使一个操作失败,事务也不会成功。如果所有操作成功则事务提交,其修改将作用于其他数据库进程。如果操作失败,则事务将回滚,该事务所有操作的影响都将被取消。
事务的特性:(ACID)
事务具有4个特征。分别是原子性、一致性、隔离性、持久性。简称事务的ACID特性
- 原子性(atomicity): 即不可分割性,事务要么全部执行,要么就全部不被执行。
- 一致性(consistency):事务的执行使得数据库从一种正确状态转换成另一种正确状态。如果数据库系统自运行过程中发生了故障,有些事务尚未完成就被迫中断,这些未完成的事务对数据库所做的修改有一部分已经写入物理数据库,这时数据库就处于一种不正确的状态,也就是不一致状态。即执行事务前后,数据保持一致。
- 隔离性(isolation): 在事务正确提交之前不允许把该事务对数据的任何改变提交给任何其他事务。即事务之间是互不干扰的,各并发事务之间是独立。
- 持久性(durability):事务正确提交后,其结果将永久保存在数据库中,即使在事务提交后有了其他故障,事务的处理结果也会得到保存。
ACID实现原理
ACID中,AID是手段,C是目的。
- 原子性(A)通过UNDO_LOG实现,UNDO_LOG记录数据修改过程。通过UNDO_LOG可以是实现事务失败或回滚时回滚,达到原子性目的。
- 隔离性(I)通过版本控制(MVCC)和锁实现。MVCC控制读取数据的时机。读已提交(RC)和可重复读(RR)两种隔离级别有些许差异。RC级别下,每次执行快照读生成一次ReadView,可以解决脏读,不能解决不可重复读、幻读问题。RR隔离级别下,可以解决不可重复读,能解决部分幻读问题。
快照读下可以解决幻读问题。当前读不能。 - 持久性(D),通过REDO_LOG实现。MySQL是硬盘性数据库,为了匹配上CPU速度。MySQL对数据的修改前,会将数据加载到内存来,修改后再写回磁盘。这个过程可能会由于数据库宕机,数据就会丢失,导致数据的不一致性。MySQL使用REDO_LOG解决这一问题,每次修改数据时,除了在内存中修改数据,还会在REDO_LOG 中记录这次操作。当事务提交时,会将redo_log进行刷盘。当数据库宕机重启时,会将REDO_LOG内容恢复到数据库中,在根据UNDO_LOG和BIN_LOG决定回滚还是提交数据。
事务隔离级别
并发事务分类
脏写
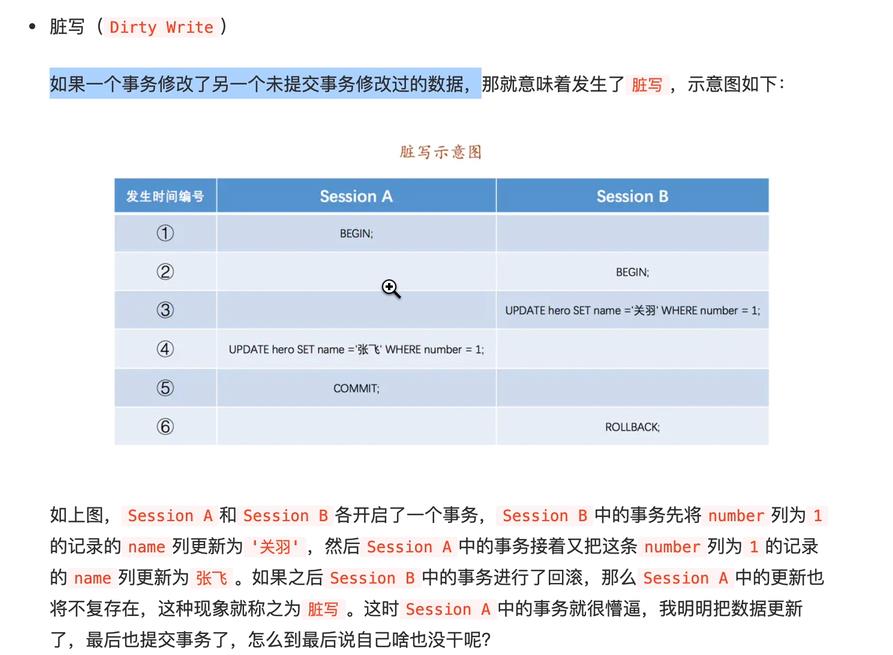
脏读
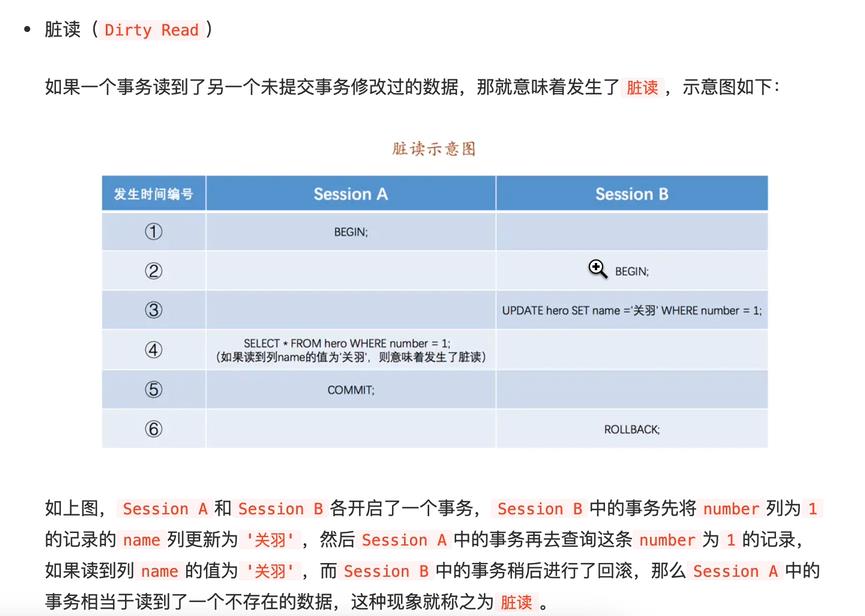
不可重复读

幻读

四种隔离级别
按问题的严重性:
脏写 > 脏读 > 不可重复读 > 幻读
舍弃一部分隔离性来换取一部分性能
READ UNCONMITTED 未提交读
READ COMMITTED 已提交读
REPEATABLE READ 可重复读
SERIALIZABLE 可串行化


Mysql默认事务隔离级别是可重复读

隔离级别的作用: 控制读取数据的时机
解决脏读、不可重复读、幻读问题

X锁和S锁

对于同一条记录来说,
S锁与S锁不互斥。
S锁与X锁互斥。
X锁与X锁互斥
上述说的是不同事务,但是**同一一个事务对某一个记录加S锁后这个仍可对这条记录加X锁 **
对记录加锁,不论对记录加的是S锁还是X 锁。正常的select * from table where查询条件仍可以访问。
解决超卖问题,在数据层面添加的是X锁
MVCC

UNDO_LOG版本链
UNDO_LOG 版本链记录数据变化
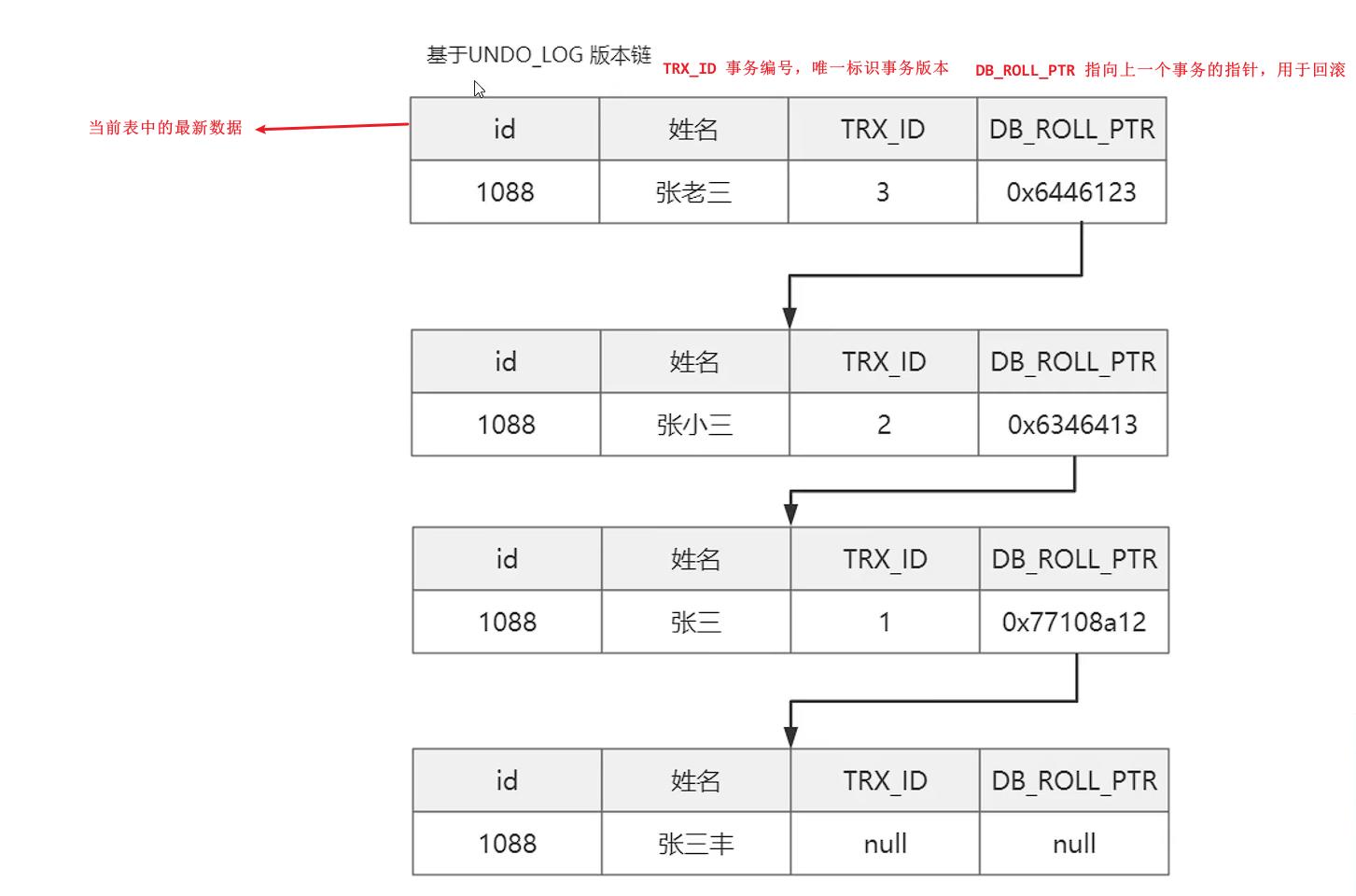 UNDO_LOG版本链不是立即删除,Mysql确保版本链数据不再被引用才会删除。
UNDO_LOG版本链不是立即删除,Mysql确保版本链数据不再被引用才会删除。
ReadView
ReadView,快照读。是SQL执行时MVCC提取数据的依据。快照读就是执行普通的select 查询语句时生成的视图。
当前读指代执行下列语句时进行数据读取的方式:
insert、update、 select for update、 select …… lock in share mode

读已提交(RC)隔离级别下
在每一次执行快照读时生成ReadView
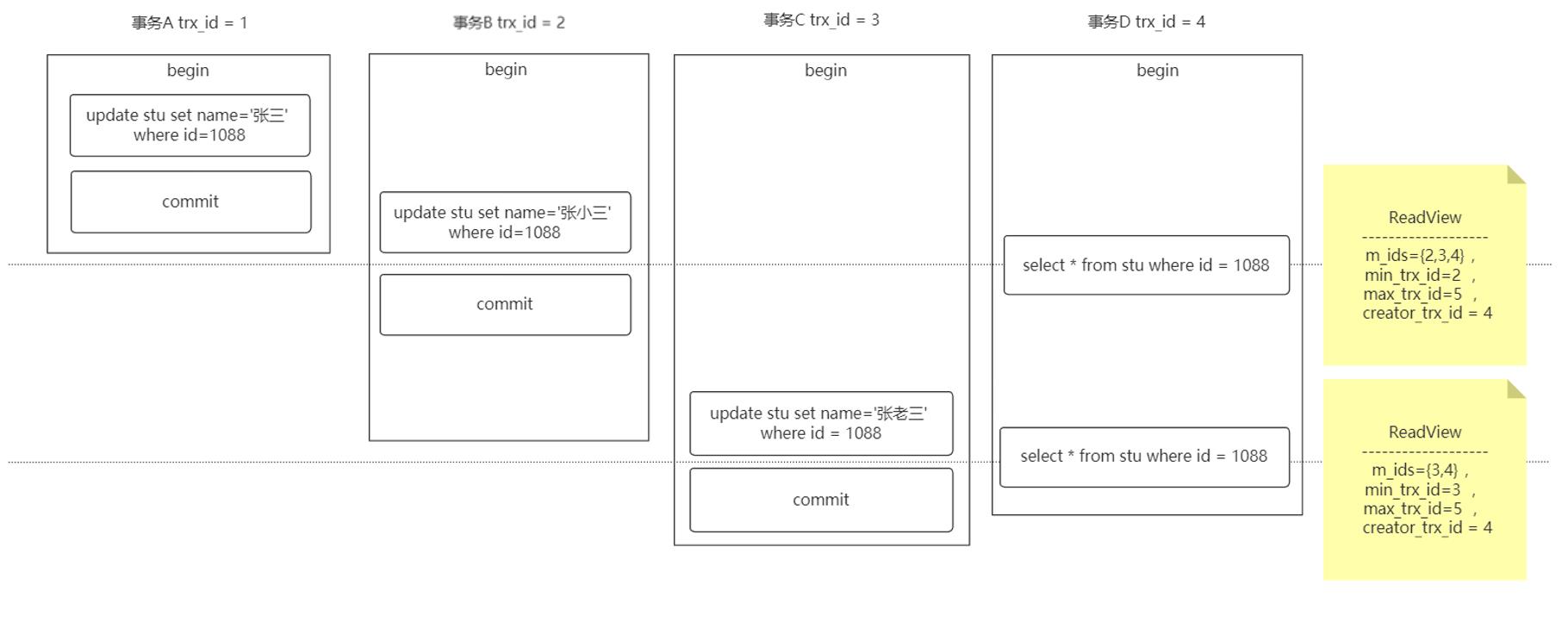 根据每个时机生成的ReadView按照读取规则从UNDO_LOG 中读取合适的数据。
根据每个时机生成的ReadView按照读取规则从UNDO_LOG 中读取合适的数据。
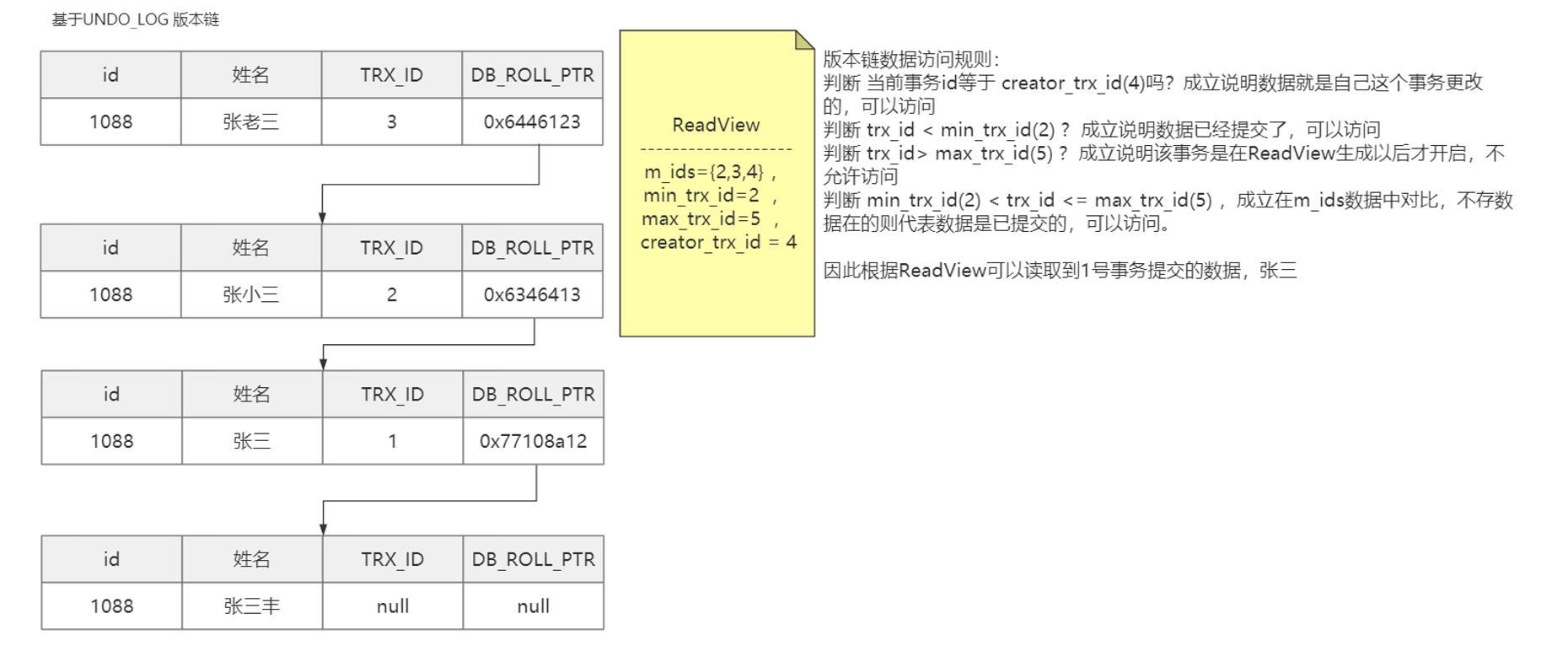
 从上面两个ReadView 生成的时机以及读取结果可以看出RC隔离级别不能解决可重复读问题。
从上面两个ReadView 生成的时机以及读取结果可以看出RC隔离级别不能解决可重复读问题。
RR

连续多次快照读,ReadView 会产生复用,没有幻读问题。
但是,但两次快照读之间存在当前读,ReadView会重新生成,导致幻读
MVCC优缺点
优点: MVCC使得大多数读操作都可以不用加锁,这样设计使得读数据操作变得很简单,性能也很好,并且也能 保证只会读取到符合标准的行。
缺点: 每行记录都需要额外的存储空间,需要做更多的行检查工作,以及一些额外的维护工作。
从思想上划分 乐观锁和悲观锁
Mysql 中都是悲观锁,没有乐观锁
Redis的Setnx 使用的是悲观锁
常用SQL 语句
使用mysql root -p 提示权限不够: Access denied for user 'ODBC'@'localhost' (using password: YES)
msyql -u root -p
use goodsadmin; -- 使用数据库
alter table person add column card_id int(12); --增加列card_id
create table IDCard(card_id int(12) primary key, card_code varchar(25)); --创建IDcard 表
alter table 表名 rename to 新表名; -- 修改表名
alter table 表名 character set 字符编码; --修改表格的字符编码
alter table person modify card_id varchar(16); --修改card_id的数据类型
alter table 表名 change 列名 新列名 新数据类型; --- 修改某一列的列名、数据类型
alter table 表名 drop 列名; --删除某一列
show tables; -- 查询当前数据的所有表
desc 表名; --查看表结构
-- 添加外键约束:alter table 从表 add constraint 外键(形如:FK_从表_主表) foreign key (从表外键字段) references 主表(主键字段);
alter table person add constraint fk_person_IDcard_card_id foreign key (card_id) references IDCard(card_id); --不加单引号
-- SELECT <字段名> FROM <表1> INNER JOIN <表2> [ON子句]
select p.* ,c.* from person p inner join idcard c on p.card_id = c.card_id where p.id = 1; --内连接查询
-- select <字段名> FROM<表1> LEFT JOIN <表2> [ON 子句]
-- 左连接 如果数据不存在,左表记录会出现,而右表为null填充
alter table person add column nation_id int(12);
create table nation(nation_id int(12) primary key, nation_name varchar(12));
alter table person add constraint fk_person_nation_nation_id foreign key (nation_id) references nation(nation_id);
---增加某列
ALTER TABLE skill ADD COLUMN createdTime TIMESTAMP not null DEFAULT now();
为什么索引使用B+树
- B+树中,所有数据记录节点都是按照键值大小顺序存放在同一层叶子结点上,而非叶子结点只存储key信息,这样可以大大加大每个节点存储的key值的数量,降低B+树的高度,从而减少磁盘IO访问次数。一般我们存储的数据在百万级别的话,B+树的高度都是三层左右。
- 除此之外,B+树每次都要访问到叶子结点,查询效率稳定为树的高度。
为什么B+树高度就小,是因为什么,B树为什么就高一些
这是因为B+树中,非叶子结点值存储键值和指向子节点的指针,叶子结点才存储数据。而B树中节点既存储键值、指向字节点的指针、也存储数据。所以在节点大小相同的条件下,B+树能存储的key就越多,因而B+树的高度就就,B树就高一些。
一般我们存储的数据在百万级别的话,B+树的高度都是三层左右
千万行的数据这个B+树索引大概也就3到4层吧。
InnoDB存储引擎操作最小数据大小为16K,B+树中,非叶子节点的占用14字节数据(非叶子节点=主键id为bigint类型占用8字节+索引6字节),因此每层可存储节点161024/14=1170。叶子节点存储数据,假设占用内存大小为1K,那么可存16个数据节点。综上,三层B+树可存数据为:11701170*16=21902400(两千万条数据)
Truncate
TRUNCATE与DELETE的区别
1、DELETE FROM 表名 # 逐行删除每一条记录、
TRUNCATE [TABLE] 表名 # 先删除表后在重新创建 表(效率高)
2、 TRUNCATE不知道删除了几条数据,官方文档的说明是:通常的结果是“ 0行受到影响 ”,这应该被解释为“ 没有信息。”。 而DELETE知道。
3、 TRUNCATE 重置auto_increment的值,delete不会。
为了实现高性能,TRUNCATE绕过了删除数据的DML方法。因此它不能被回滚,不会导致ON DELETE 触发器触发,并且不能对InnoDB具有父子外键关系的表执行
1、 数据库的三大范式
第一范式: 属性不可分。关系中每一个数据不可再分(不能以集合/序列等作为属性),也就是关系中没有重复的列(比如电话号码这个属性既存在一个手机号又存在一个家庭号码,这种情况就不属于第一范式,除非把手机号作为一个列,家庭号码也作为单独一列。);
第二范式: 消除部分依赖。在1NF基础之上,消除非主属性对键的部分依赖,则称它为符合2NF;(把学生编号,课程标号,成绩单独拿出来作为一个表)。属性完全依赖于主键。
第三范式: 在2NF基础之上,消除非主属性对键的传递依赖,称为符合3NF;(要确定这个学生的院系,首先要经过学号来确定班级,通过班级来确定院系,所以院系对学号存在传递依赖;把院系拿出来单独作为一个表就可以了)。
使属性不依赖于其它非主属性。 也就是说, 如果存在非主属性对于码的传递函数依赖
以上是关于Java面试 —— MySQL相关的主要内容,如果未能解决你的问题,请参考以下文章