ClickHouse 极简教程分布式下的 IN/JOIN 及 GLOBAL关键字
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse 极简教程分布式下的 IN/JOIN 及 GLOBAL关键字相关的知识,希望对你有一定的参考价值。

GLOBAL 关键字
ClickHouse 的 HASH JOIN算法实现比较简单:
- 从right_table 读取该表全量数据,在内存中构建HASH MAP;
- 从left_table 分批读取数据,根据JOIN KEY到HASH MAP中进行查找,如果命中,则该数据作为JOIN的输出;
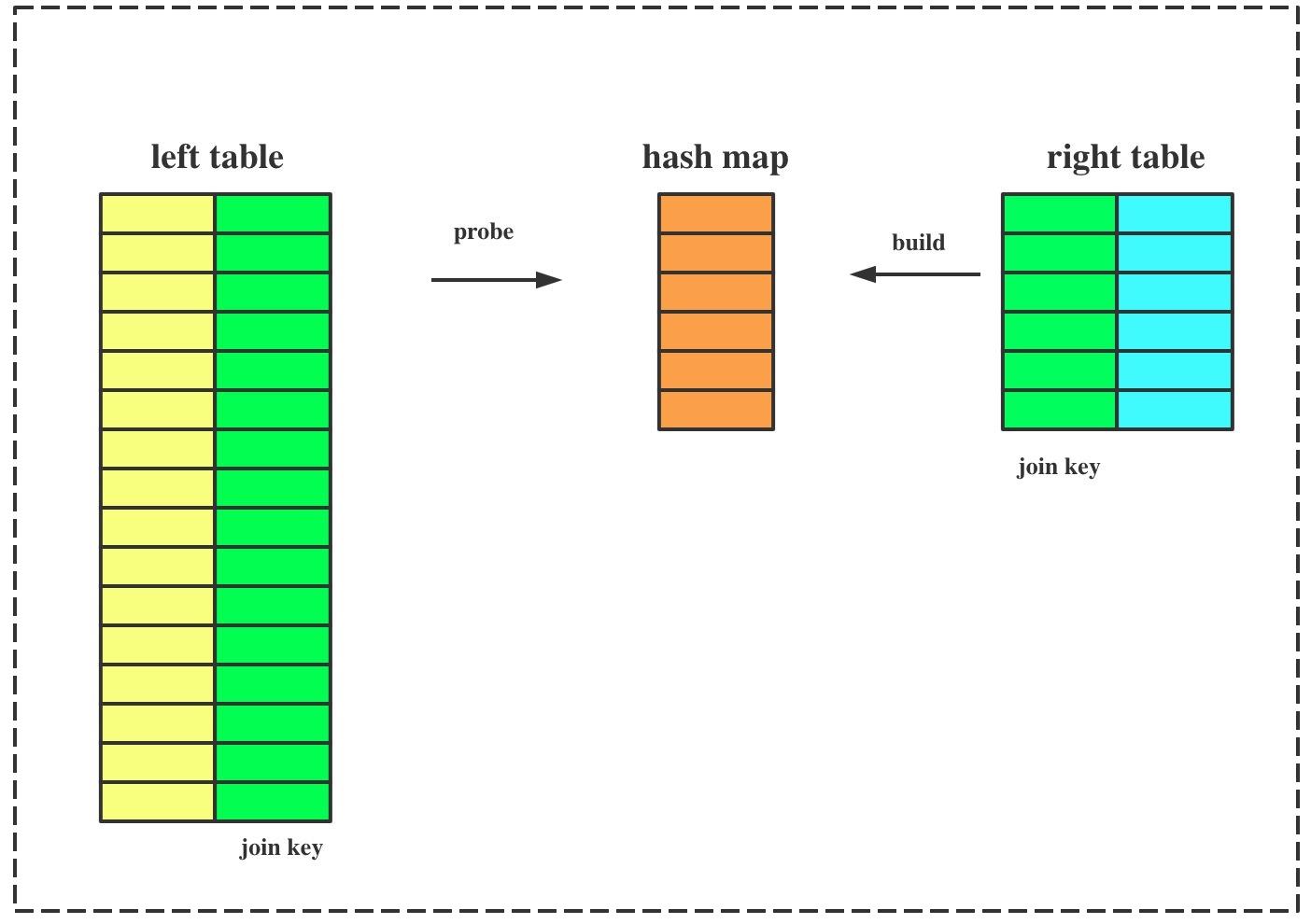
从这个实现中可以看出,如果right_table的数据量超过单机可用内存空间的限制,则JOIN操作无法完成。通常,两表JOIN时,将较小表作为right_table.
2. ClickHouse分布式JOIN实现
ClickHouse 是去中心化架构,非常容易水平扩展集群。当以集群模式提供服务时候,分布式JOIN查询就无法避免。这里的分布式JOIN通常指,JOIN查询中涉及到的left_table 与 right_table 是分布式表。
通常,分布式JOIN实现机制无非如下几种:
- Broadcast JOIN
- Shuffle Join
- Colocate JOIN
ClickHouse集群并未实现完整意义上的Shuffle JOIN,实现了类Broadcast JOIN,通过事先完成数据重分布,能够实现Colocate JOIN。
ClickHouse 的分布式JOIN查询可以分为两类,带GLOBAL关键字的,和不带GLOBAL关键字的情况。
GLOBAL JOIN 实现
GLOBAL JOIN 计算过程如下:
- a. 若右表为子查询,则initiator完成子查询计算;
- b. initiator 将右表数据发送给集群其他节点;
- c. 集群节点将左表本地表与右表数据进行JOIN计算;
- d. 集群其他节点将结果发回给initiator节点;
- e. initiator 将结果汇总,发给客户端;
GLOBAL JOIN 可以看做一个不完整的Broadcast JOIN实现。如果JOIN的右表数据量较大,就会占用大量网络带宽,导致查询性能降低。
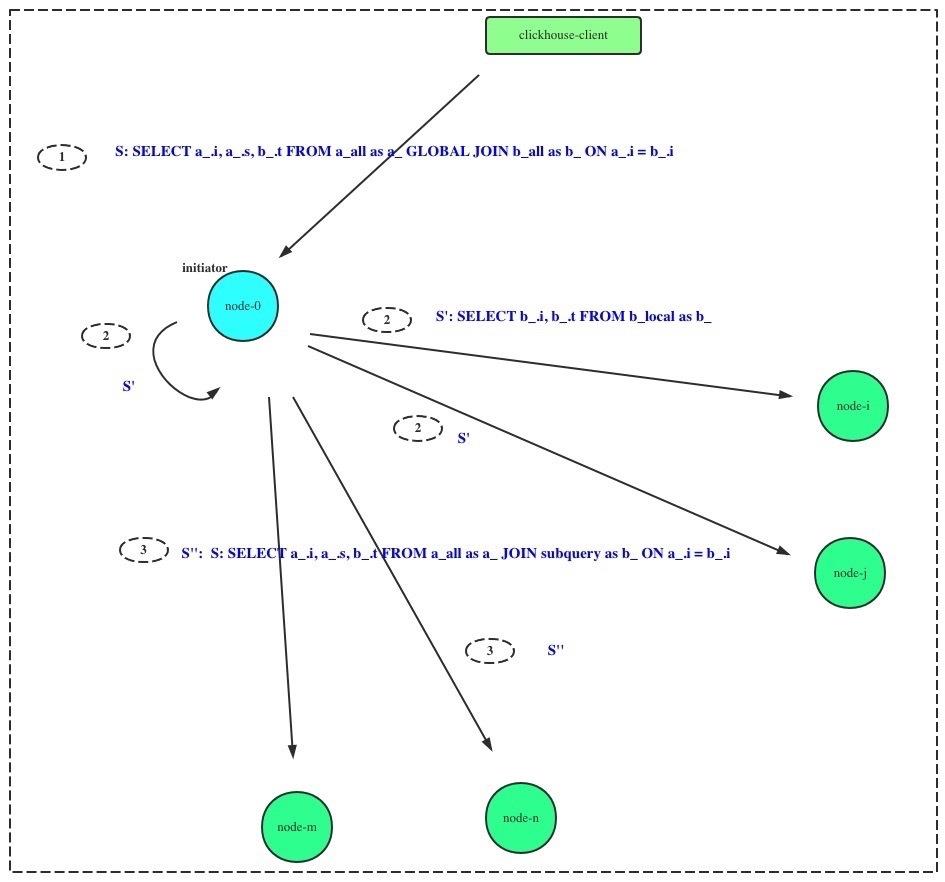
如图所示,执行的SQL为:
SELECT a_.i, a_.s, b_.t FROM a_all as a_ GLOBAL JOIN b_all AS b_ ON a_.i = b_.i其中,a_all, b_all为分布式表,对应的本地表名为a_local, b_local。则改SQL在分布式执行的时序为:
-
- initiator 收到查询请求SELECT b_.i, b_.t FROM b_local AS b_即左表分布式表更改为本地表名。该SQL在集群范围内并行执行。汇总结果,记录为subquery。
-
- initiator 和集群其他节点均执行
- 3)initiator 将2)中subquery发送到集群中其他节点,并触发分布式查询:SELECT a_.i, a_.s, b_.t FROM a_local AS a_ JOIN subquery as b_ ON a_.i = b_.i其中subquery表示2)中执行的结果
-
- 各节点执行完成JOIN计算后,向initiator节点发送数据
可以看出,GLOBAL JOIN 将右表的查询在initiator节点上完成后,通过网络发送到其他节点,避免其他节点重复计算,从而避免查询放大。
为什么要用 GLOBAL关键字?
因为产生了查询放大,而且放大倍数非常大,为了解决这个问题,引入了GLOBAL关键字。
使用GLOBAL修饰后,会将子查询在初始执行节点进行查询汇总,存储为临时表,并在SQL分发时携带该临时表数据到各个节点进行查询,最终汇总结果到初始查询节点。
这种情况下,如果有n个节点,就会仅有2*n次查询操作。大限度的降低了查询放大问题。
补充:
在使用GLOBAL关键字时,虽然最大限度的降低了查询放大,但是如果数据量过大,产生的临时表就会很大,也会受到网络稳定性和网络带宽的限制。ck在做JOIN时都是采用发送右表,所以ck在做分布式IN/JOIN时的效率不太好,所以在编写SQL时一定要多考虑这部分影响。
ck不支持数据的重分布,并不能将join key相同的数据落到同一节点,所以还不能支持将分布式join转换为本地join并汇总的方式。
分布式下的IN/JOIN
如果是在单机情况下,涉及到IN/JOIN时是没有什么问题的,但是在分布式情况下就不一样了,ClickHouse是支持多分片多副本的,创建表也提供了友好的ON CLUSTER [name]的方式,所以就是建议使用者将数据进行分片处理增加读的效率,但也随之产生了单节点数据不完整的问题。如果SQL中涉及子查询就不得不有特殊的处理方式。
ClickHouse中的分布式子查询
在ClickHouse中为了方便做分布式查询,特意提供了Distributed表引擎,这个表引擎实际上是不存储数据的,单查这个表时,实际上是将SQL分发到该表引擎所关联的本地及远程节点执行,并把结果再汇总回来,类似一种分布式视图的效果。所以针对Distributed表的分布式查询情况做个汇总。
1.主子查询都查询本地表
例如:
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM local_table WHERE CounterID = 34)
这种情况不会涉及网络数据传输,所有查询操作仅仅涉及执行节点,也仅仅会返回执行节点上的匹配数据。
2.主查询使用分布式表,子查询使用本地表
例如:
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM local_table WHERE CounterID = 34)
这种情况ck就会对SQL进行重写,将分布式表转换成本地表,并将SQL分发到存在local_table表的所有节点进行执行,再将结果进行汇总回传。其实可以理解成在每个存在local_table表的节点上都分别执行一遍第一种查询情况,最后进行合并回传。这种方式会因为数据不全导致结果错误,如果数据冗余,也会造成结果重复。
这种情况下,如果有n个节点,就会有n次查询操作。
3.主查询本地表,子查询使用使用分布式表
例如:
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)
这种情况ck同样会对SQL进行重写,但此时不是将分布式表转换为本地表,而是直接分发这个SQL语句到存在local_table表的所有节点,在子查询是分布式表的情况下,每个接收到分发请求的节点先进行子查询,即到各个存在local_table表的节点执行SELECT UserID FROM local_table WHERE CounterID = 34再汇总回来,再和主查询语句继续执行查询,即每个被分发的节点都需要走一次这个流程,将最终的结果回传给初始执行节点,由初始执行节点将结果集合并,完成查询。
好像稍微有点绕,可以把这个SQL的主查询当作A,子查询当作B,假设有3个分片节点,那么需要先考虑第一个节点的执行情况,第一个节点为了能拿到子查询所有的数据,会先上自己上执行B,再去第二个节点执行B,再去第三个节点上执行B,然后再自己上执行A。同样,换到第二个节点,它同样会去一和三以及自己上执行B,再执行A。第三个几点以此类推,最终回传到初始执行节点进行汇总。
这种情况下,如果有n个节点,就会有n*n次查询操作。
4.主子查询都查询分布式表
例如:
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)
这种情况其实和第三种情况类似,但是主查询中也使用了分布式表,所以又多了一次查询汇总,所以如果有n个几点,那么会产生2nn次查询操作。
5.主子查询都查询分布式表,且使用GLOBAL关键字
例如:
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID GLOBAL IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)
clickhouse global 用法
global 介绍
global 有两种用法: GLOBAL in /GLOBAL join
分布式查询
SELECT uniq(UserID) FROM distributed_table将会被发送到所有远程服务器
SELECT uniq(UserID) FROM local_table然后并行运行,直到达到中间结果可以结合的阶段。然后,中间结果将被返回给请求者服务器并在其上合并,最终的结果将被发送到客户端。
in/join 的问题
当使用 in 的时候,查询被发送到远程服务器,并且每个服务器都在 IN 或 JOIN 子句中运行子查询
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)这个查询将发送到所有服务器,子查询的分布式表名会替换成本地表名
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)子查询将开始在每个远程服务器上运行。由于子查询使用分布式表,所以每个远程服务器上的子查询将会对每个远程服务器都感到不满,如果您有一个 100 个服务器集群,执行整个查询将需要 10000 个基本请求,这通常被认为是不可接受的。
使用 GLOBAL in /GLOBAL join
SELECT uniq(UserID) FROM distributed_table WHERE CounterID = 101500 AND UserID GLOBAL IN (SELECT UserID FROM distributed_table WHERE CounterID = 34)服务器将运行子查询
SELECT UserID FROM distributed_table WHERE CounterID = 34结果将被放在 RAM 中的临时表中。然后请求将被发送到每个远程服务器
SELECT uniq(UserID) FROM local_table WHERE CounterID = 101500 AND UserID GLOBAL IN _data1临时表 “data1” 将连同查询一起被发送到每个远程服务器(临时表的名称是实现定义的)。
使用注意
创建临时表时,数据不是唯一的,为了减少通过网络传输的数据量,请在子查询中使用 DISTINCT(你不需要在普通的 IN 中这么做)
临时表将发送到所有远程服务器。其中传输不考虑网络的拓扑结构。例如,如果你有 10 个远程服务器存在与请求服务器非常远的数据中心中,则数据将通过通道发送数据到远程数据中心 10 次。使用 GLOBAL IN 时应避免大数据集。
当使用 global…JOIN,首先会在请求者服务器运行一个子查询来计右表 (right table)。将此临时表传递给每个远程服务器,并使用传输的临时数据在其上运行查询。会出现网络传输,因此尽量将小表放在右表。
参考资料:
https://clickhouse.tech/docs/en/sql-reference/operators/in/https://blog.csdn.net/weixin_39992480/article/details/108228613https://cloud.tencent.com/developer/article/1831229
以上是关于ClickHouse 极简教程分布式下的 IN/JOIN 及 GLOBAL关键字的主要内容,如果未能解决你的问题,请参考以下文章