“ShardingCore”是如何针对分表下的分页进行优化的
Posted dotNET跨平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了“ShardingCore”是如何针对分表下的分页进行优化的相关的知识,希望对你有一定的参考价值。
首先还是要给自己的开原框架打个广告 sharding-core 针对efcore 2+版本的分表组件,首先我们来快速回顾下目前市面上分表下针对分页常见的集中解决方案
分表解决方案
| 解决方案 | skip<=100 | skip<10000 | skip>10000 | 优点 | 缺点 |
|---|---|---|---|---|---|
| 内存分表 | 速度快O(n),n=skip*分表数 | 速度快O(n),n=skip*分表数,内存暴涨 | O(n),n=skip*分表数,内存爆炸,速度越来越慢 | 实现简单,支持分库 | skip过大内存暴涨 |
| union all | 速度快 | 速度一般 | 死慢死慢的 | 实现简单 | 仅支持同库,不好优化,索引会失效 |
| 流式分表 | 速度快O(n),n=skip | 速度快O(n),n=skip | O(n),n=skip 速度越来越慢 | 支持分库 | 实现复杂 |
1.内存分页
顾名思义就是将各个表的结果集合并到内存中进行排序后分页
2.union all
使用的是数据库本身的聚合操作,用过匿名表来实现和操作当前表一样无感知
3.流式分表
和名字一样就是通过next来一次一次获取,和datareader类似只有在next后才可以获取到客户端
通过上面的简单对照我们可以清楚地发现,其实我们可以选择的基本上就内存分表和流式分表而已,又以为内存分表的限制其实最优解就是流式分表。
上篇文章我们简单的介绍了流式分表这次我们在针对流式分表的原理进行介绍,并且提出针对流式分表下的分页“最优解”。
流式分表原理
我们先简单的假设一个场景,我们有一个订单表,针对订单表我们进行了分表,根据订单的创建时间按月分表。
如果我们执行 select * from order limit 100,2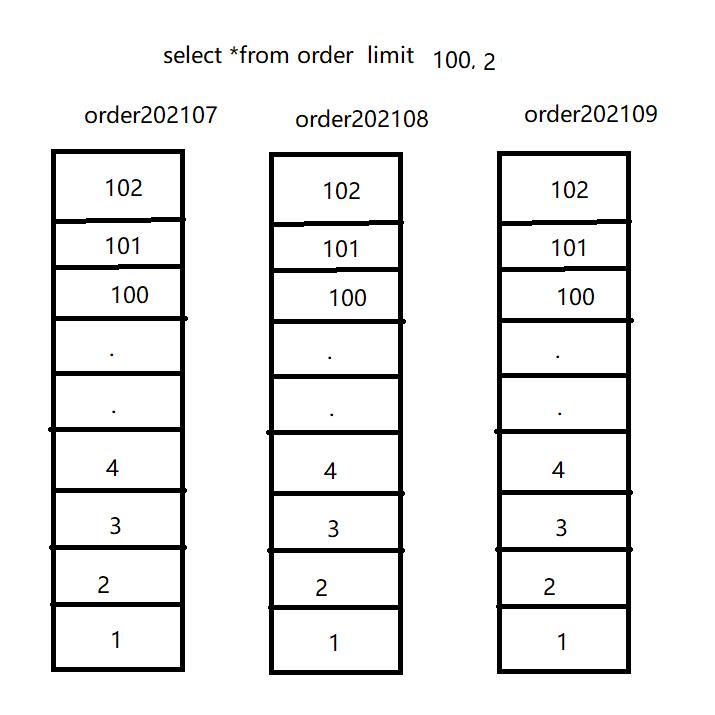
内存分页
在这种情况下如果我们需要分页跳过前 100条记录获取第101-102条记录,现在如果内存分表情况下我们该如何操作
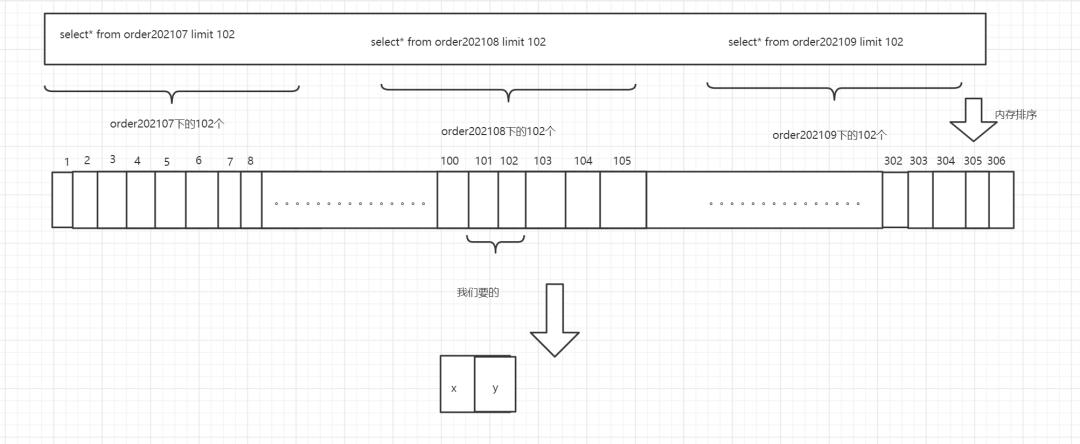
流式分页
上述就是内存排序的实现,通过上图发现我们需要获取102*3条数据,并且进行排序后获取第101和102条数据,所以说上述表格里已经体现了内存分表的优劣 那么如果是流式分页我们是如何操作的呢
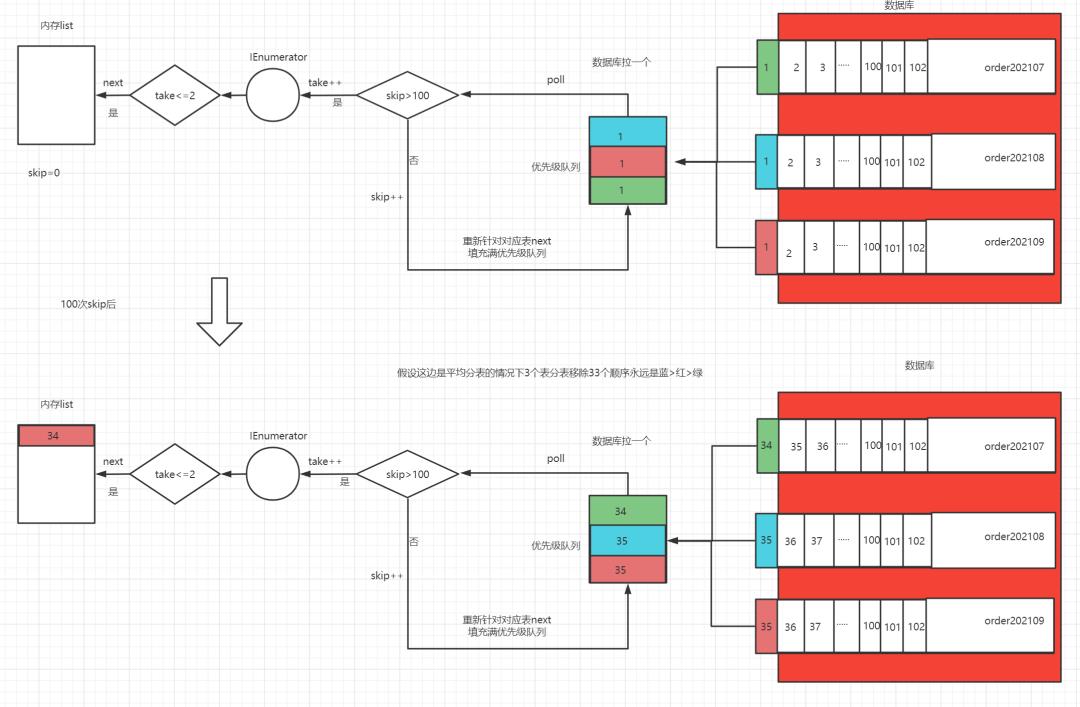
简单解释下这张图,右边为数据库在数据库外面的分别是next了一次的数据,其他数据都是在数据库里面只是结果集有了但是结果还不没有取到client,
通过100次next后我们可以取到真实的数据所以对于任何分页都是只需要O(n)的时间复杂度,其中n=skip+take就是跳过多少条和获取多少条
注意:不要以为next了100次就是查询了100次数据库,结果集生成后就不会再查询数据库里,next可以理解为是对结果集的客户端获取。
sharding-core的优化
至此流式分表获取数据的原理基本上就是这样,针对这种情况下我们该如何进行对分页数据进行优化,因为上图数据库模块内部的区域是未知的也就是说我们是不知道索引“1”后面的索引“2”和其他语句下的当前索引大小情况,我们只知道索引“1”和索引“2”在本张表里面的排序情况,
针对这种情况我们应该是没办法进行程序的优化了,可以理解为目前情况下已经是最优解了。但是如果我们仔细一想可以发现事情并不简单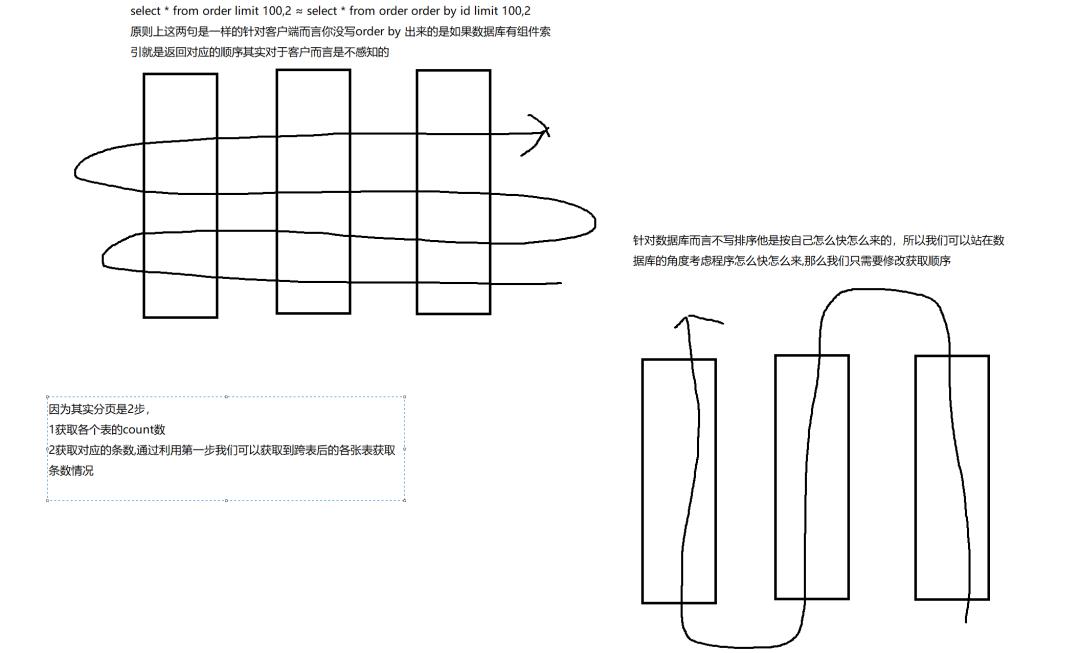
大家能看懂吗我们只需要让程序的获取方式按顺序那么就可以保证性能最佳 O(1),所以针对时间分表或者顺序分表的情况下我们一般情况下使用时间倒序或者顺序,那么就可以告诉程序如何排序,又可以得知,在对应顺序的情况下每张表都是顺序的又因为只要保证如下就可以了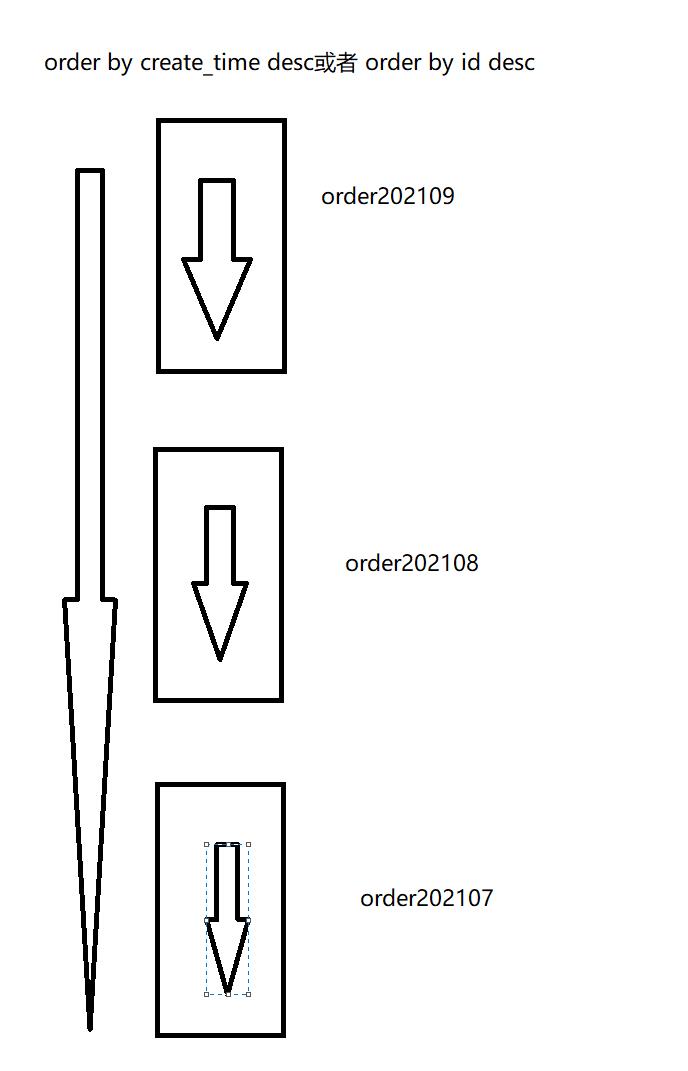
有些朋友可能会有疑问,为什么order by id也可以这样,其实order by id是不可以这样的,但是如果你这样又会怎么样?难道数据库用它最优解排序返回是正确,程序用最优解排序返回就不是正确了?
sharding-core的优化升阶
可能有些喷友认为优化到这里就是差不多了但是其实sharding-core针对优化还不止如此,
因为这种排序需要让程序知道以某种情况排序可以按表顺序排序达到性能最优,但是如果我是Id取模或者范围就会导致这个排序仅仅只适合id排序如果需要按别的来排序就没办法了还是得走流式分表.
那么该如何优化呢还是一样我们忽略了分页是2步操作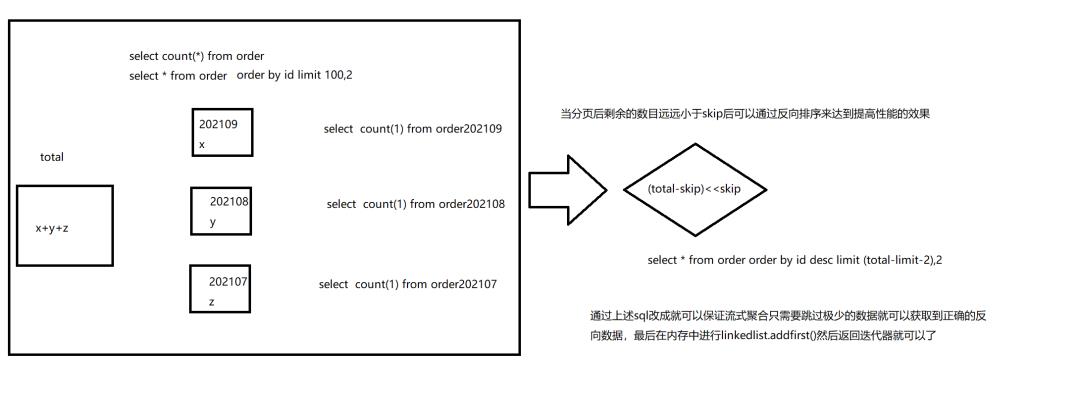
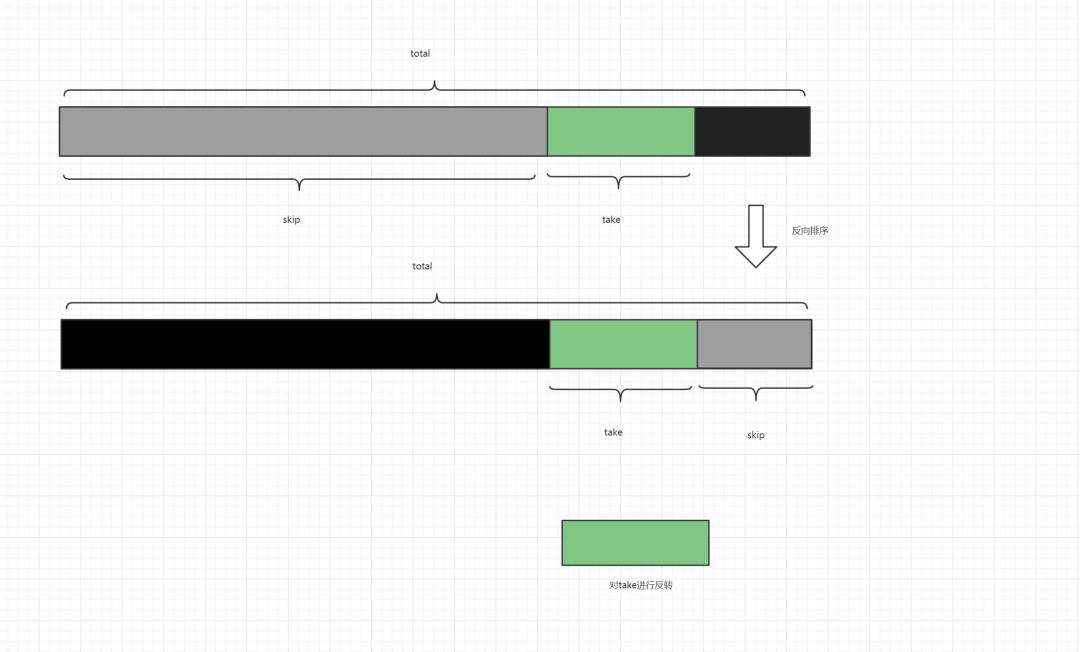
这种排序仅仅需要的是第一存在order by 第二告诉系统skip多少后需要启用反排,并且该情况适用于任何的分表规则id取模或者别的其他情况都是可以支持的
你以为sharding-core的优化结束了吗?
sharding-core已经实现了以上所有的解决方案,并且已经在实现第三种优化,就是极不规则情况下的分页,具体就是当表查询坐落到3张表后其中2张表或者1张表的count极少的情况下直接取到内存然后剩余的1张表可以直接通过skip+take获取数据后内存排序,
因为时间原因目前还没实现后续会针对这个情况进行实现。
以上就是我为大家带来的理论和干货,
具体的理论听得爽了干货我再发一遍吧 sharding-core
sharding-core如何启用高性能分页
高性能分页
sharding-core本身使用流式处理获取数据在普通情况下和单表的差距基本没有,但是在分页跳过X页后,性能会随着X的增大而减小O(n)
目前该框架已经实现了一套高性能分页可以根据用户配置,实现分页功能。
支持版本x.2.0.16+
1.如何开启分页配置 比如我们针对用户月新表进行分页配置,先实现IPaginationConfiguration<>接口,该接口是分页配置接口
public class SysUserSalaryPaginationConfiguration:IPaginationConfiguration<SysUserSalary>
{
public void Configure(PaginationBuilder<SysUserSalary> builder)
{
builder.PaginationSequence(o => o.Id)
.UseTailCompare(Comparer<string>.Default)
.UseQueryMatch(PaginationMatchEnum.Owner | PaginationMatchEnum.Named | PaginationMatchEnum.PrimaryMatch);
builder.PaginationSequence(o => o.DateOfMonth)
.UseQueryMatch(PaginationMatchEnum.Owner | PaginationMatchEnum.Named | PaginationMatchEnum.PrimaryMatch).UseAppendIfOrderNone(10);
builder.PaginationSequence(o => o.Salary)
.UseQueryMatch(PaginationMatchEnum.Owner | PaginationMatchEnum.Named | PaginationMatchEnum.PrimaryMatch).UseAppendIfOrderNone();
builder.ConfigReverseShardingPage(0.5d,10000L);
}
}
2.添加配置
在对应的用户月薪路由中添加配置
public override IPaginationConfiguration<SysUserSalary> CreatePaginationConfiguration()
{
return new SysUserSalaryPaginationConfiguration();
}
3.Configure内部为什么意思?
builder.PaginationSequence(o => o.Id) 配置当分页orderby 字段为Id时那么分表所对应的表结构为顺序,顺序的规则通过
UseTailCompare来设置,其中string为表tail,
具体什么意思就是说如果本次分页设计3张表分别是table1,table2,table3,如果我没配置id的情况下那么需要查询3张表然后分别进行流式聚合,如果我配置了id的情况下,如果本次sql查询带上了id作为order by字段
那么就不需要分别查询3张表,可以直接查询table1如果table1的count大于你要跳过的页数,假设分页查询先查询多少条,table1:100条,table2:200条,table3:300条
如果你要跳过90条获取10条原先的时间就是O(100)现在的时间就是O(10)因为table1跳过了90条还剩余10条;UseQueryMatch是什么意思,这个就是表示你要匹配的规则,是必须是当前这个类下的属性还是说只需要排序名称一样即可,因为有可能select new{}匿名对象类型就会不一样,PrimaryMatch表示是否只需要第一个主要的
orderby匹配上就行了,UseAppendIfOrderNone表示是否需要开启在没有对应order查询条件的前提下添加本属性排序,这样可以保证顺序排序性能最优builder.ConfigReverseShardingPage表示是否需要启用反向排序,因为正向排序在skip过多后会导致需要跳过的数据过多,尤其是最后几页,如果开启其实最后几页就是前几页的反向排序,其中第一个参数表示跳过的因子,就是说
skip必须大于分页总total*该因子(0-1的double),第二个参数表示最少需要total多少条必须同时满足两个条件才会开启(必须大于500),并且反向排序优先级低于顺序排序,
4.如何使用
var shardingPageResultAsync = await _defaultTableDbContext.Set<SysUserMod>().OrderBy(o=>o.Age).ToShardingPageAsync(pageIndex, pageSize);
注意:如果你是按时间排序无论何种排序建议开启并且加上时间顺序排序,如果你是取模或者自定义分表,建议将Id作为顺序排序,如果没有特殊情况请使用id排序并且加上反向排序作为性能优化
测试
首先我们使用 EFCore.BulkExtensions
本机环境 AMD3900X 12核24线程,32GDDR4 3200内存 980pro固态 sqlserver2012
针对数据进行创建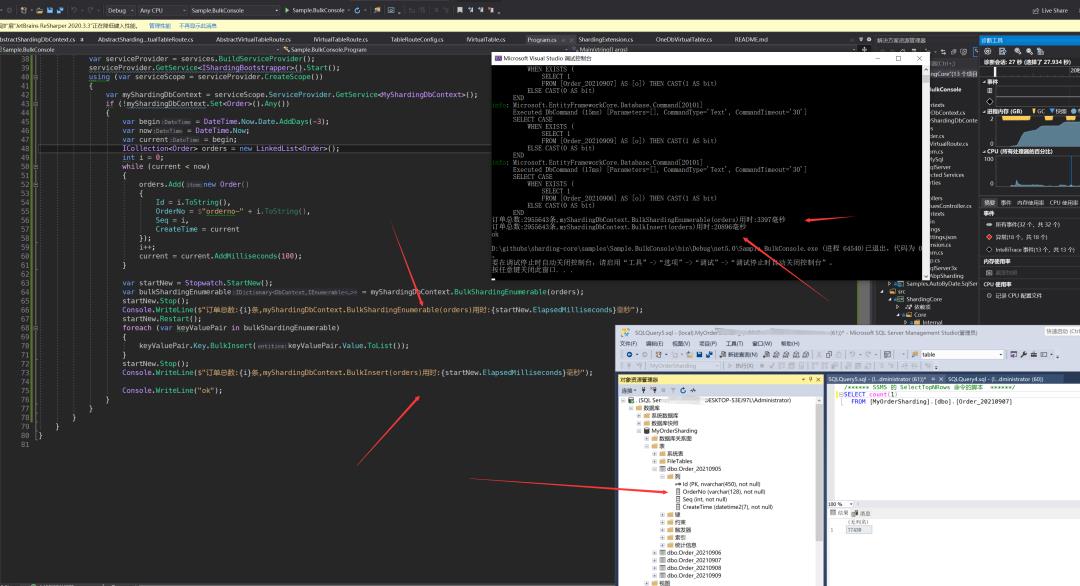
一共近295.5w数据耗时24.2秒其中解析表路由耗时3.4秒,插入到本地20.8秒,实际300w订单肯定要比这个时间长因为测试原因所以创建的订单表字段比较少
再不起用高性能分表的情况下我们看下
流式分页
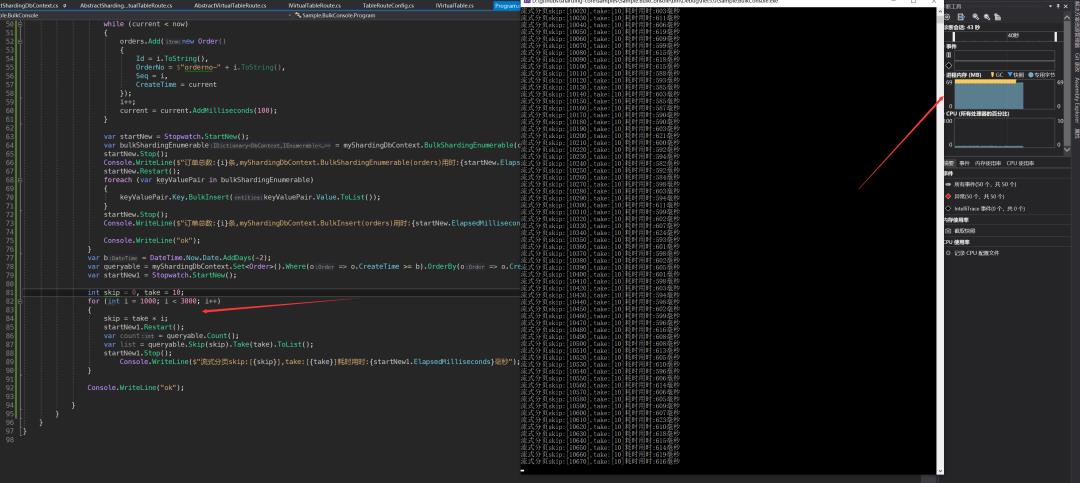
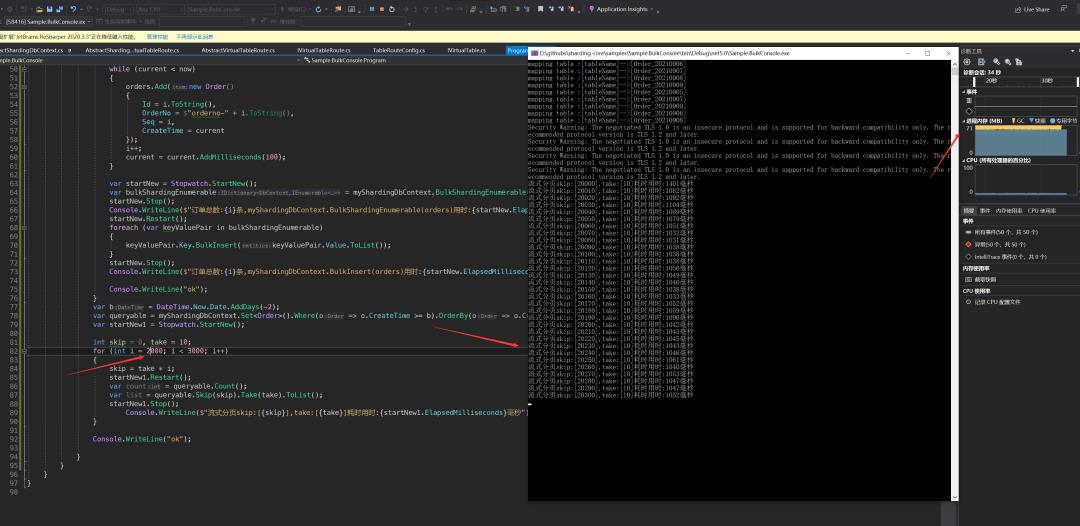
基本在skip 1w后还是可以保持在500ms,skip2w后虽然内存波动不大但是基本上耗时也有显著增加那么如果开启了高性能分表呢
高性能分页
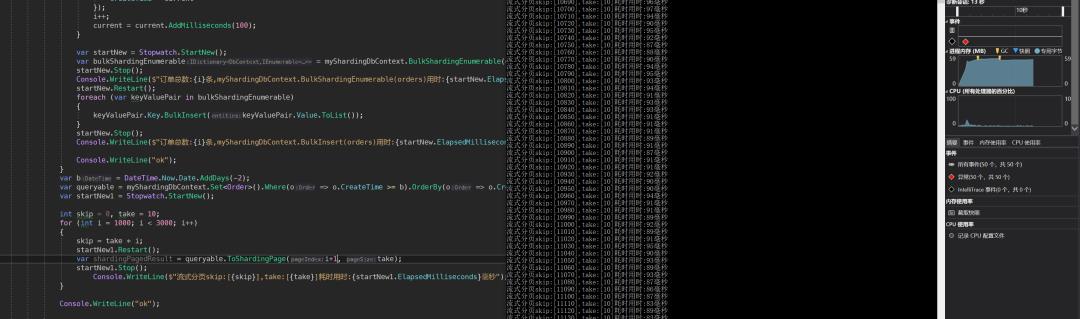
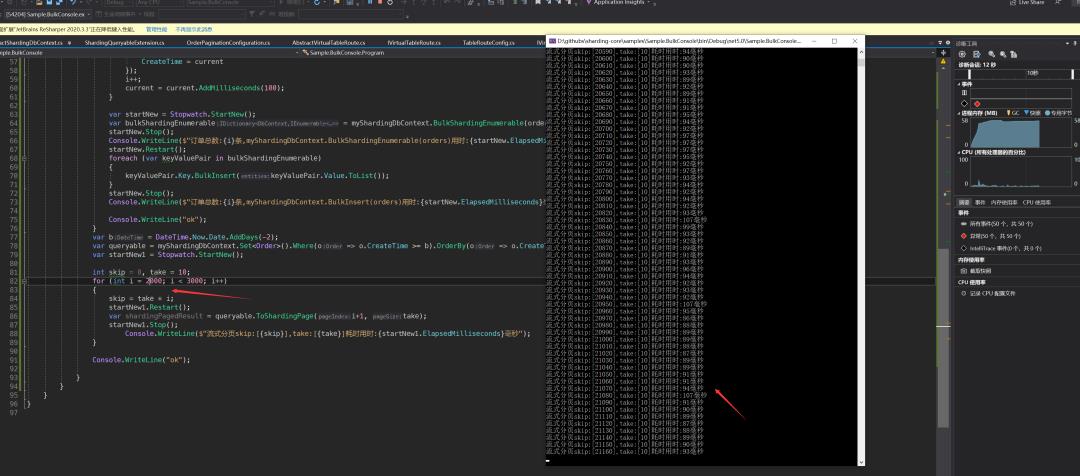
直接爆杀有没有
如果需要使用请在nuget安装ShardingCore记得勾选预览版本哦安装最新版
最后的最后
如果本文章对您有帮助请点下推荐,如果本框架对您有帮助请点下start,Thanks♪(・ω・)ノ github sharding-core:https://github.com/xuejmnet/sharding-core
以上是关于“ShardingCore”是如何针对分表下的分页进行优化的的主要内容,如果未能解决你的问题,请参考以下文章