ElasticSearch暗转与基础知识
Posted 尚墨1111
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch暗转与基础知识相关的知识,希望对你有一定的参考价值。
ElasticSearch安装与基础知识
ElasticSearch
1 安装
1.1 相关
- 大数据对于搜索、模糊搜索,效率低
- Lucene是一套搜索引擎工具包jar,不包含搜索引擎,有索引结构,读写索引、排序索引的工具类。可以用于:全文搜索、结构化搜索、分析(权重、高亮)
相关笔记:https://www.cnblogs.com/DAYceng/p/14755532.html
1.2 环境、安装
1.2.1 环境
安装ElaticSearch 需要Java环境、NodeJs环境
参考文章:nodejs zip压缩版安装与配置
1.2.2 安装 ElasticSearch
下载地址:https://www.elastic.co/cn/downloads/elasticsearch
注意:千万不要下载最新版本!!!搞了半天,发现ik插件没有这个版本的,重新安装一遍,哭死。。


1.2.3 安装Elastic-Head插件
下载地址:https://github.com/mobz/elasticsearch-head
1、下载安装ElasticSearch-head插件
2、安装nodeJs的环境,nodejs zip压缩版安装与配置
3、进入插件目录打卡cmd,输入npm run start启动成功
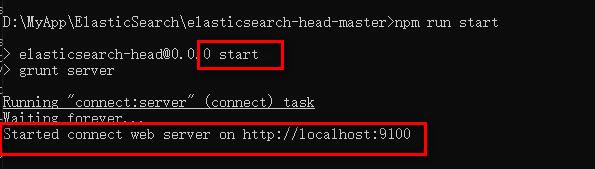
4、修改配置 elasticsearch.yml 新增head插件连接上ElasticSearch
http.cors.enabled: true
http.cors.allow-origin: "*"
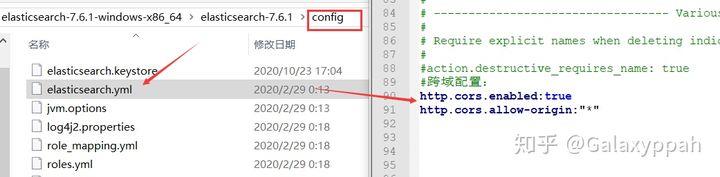
5、再次打开elasticsearch、head,浏览器访问地址 ,127.0.0.1:9100进行可视化

1.2.4 其他
启动时通过cmd直接在elasticsearch的bin目录下执行elasticsearch ,这样直接启动的话集群名称会默认为elasticsearch,节点名称会随机生成。 ,停止就直接在cmd界面按Ctrl+C ,可以将elasticsearch设置为windows系统服务
1.3 ELK
ELK是三个工具的集合,Elasticsearch + Logstash + Kibana,这三个工具组合形成了一套实用、易用的监控架构,很多公司利用它来搭建可视化的海量日志分析平台
【ElasticSearch】索引
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。【Logstash】收集
Logstash是一个用于管理日志和事件的工具,你可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如搜索、存储等。【Kibana】可视化
Kibana是一个优秀的前端日志展示框架,它可以非常详细的将日志转化为各种图表,为用户提供强大的数据可视化支持。
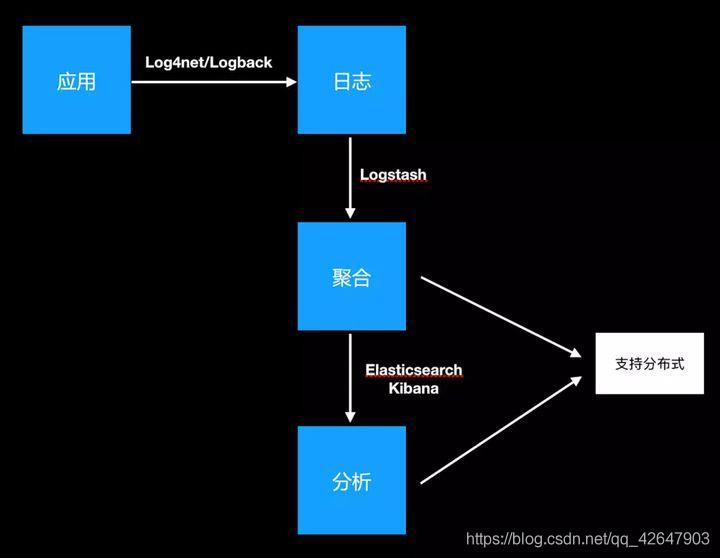
1.3.1 下载kibana:可视化工具
参考教程:https://zhuanlan.zhihu.com/p/268065286
1、下载地址:https://mirrors.huaweicloud.com/kibana/?C=N&O=D,注意kibana的版本一定要与elasticsearch版本对应,解压的时间会比较久,下载完成解压,双击kibana.bat即可启动
2、汉化,在Kibana目录下的config中修改Kibana.yml文件,最后一行加上
i18n.locale: "zh-CN"
2、打开ElasticSearch.bat,head插件
3、点击 kbana.bat,启动cmd窗口之后,访问 http://localhost:5601 打开kbana的网页

出现的问题:google浏览器版本太低,一直显示loading Elastic
解决方案:更新google浏览器、换浏览器访问
4、连接的过程比较慢,还可能会报Times out的问题
注意,首先打开ES,然后再连接head插件,最后打开kbana,打开kbana之后,再对ES回车操作,这个事就kbana才会往下走,不然就是一直循环报错 Timeout
5、必须先打开ES,再点击开发工具,可以进行测试
2 ES核心概念
2.1 索引、类型、文档
可以将ElasticSearch理解成数据库,索引(表)+文件(数据),而这个文件是以json的格式存储的
| 关系型数据库 | ElasticSearch |
|---|---|
| 数据库 | 索引 |
| 表 | type(映射) |
| 行 | document |
| 列 | field |
Elasticsearch(一般为集群)中可以包含多个索引(对应数据库) ,每个索引中可以包含多个类型(对应表) ,每个类型下又包含多个文档(对应行),每个文档中又包含多个字段(对应列)。
2.1.1 文档
Elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,一条数据在ElasticSearch就是一个文档。一篇文档同时包含字段和对应的值,也就是同时包含key:value,比如:
//类型中对于字段的定义称为映射,比如name映射为string类型.我们说文档是无模式的,他们不需要拥有映射中所定义的所有字段,当新增加一个字段时,es会自动的将新字段加入映射,但是这个字段不确定他是什么类型,所以最安全的方式是提前定义好所需要的映射。
{
"name" : "John",//索引和搜索数据的最小单位是文档
"sex" : "Male",
"age" : 25,
"birthDate": "1990/05/01",
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
2.1.2 类型
类型是文档的逻辑容器,就像表格是行的容器。
类型中对于字段的定义称为映射,比如name可以映射为字符串类型。新增一个字段,elasticsearch会自动的将新字段加入映射,猜测。所以最好新增字段的时候就加上映射。像建表时设定数据类型

2.1.3 索引
elasticsearch中的索引是一个非常大的文档集合(即数据库)。索引存储了映射类型的字段和其他设置。 然后它们被存储到了各个分片上了。存在数据库的数据可以通过不同的分片放在不同的集群上。
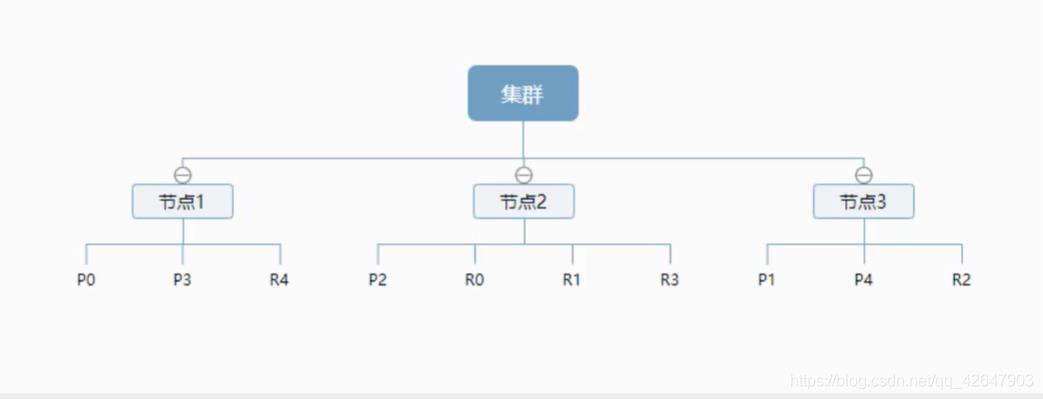
一个集群至少有一个节点**,而一个节点就是一个elasticsearch进程**,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个主分片构成,每一个主分片会有一个副本
分片:因为ES是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配
副本:ES默认为一个索引创建5个主分片, 并分别为其创建一个副本分片. 也就是说每个索引都由5个主分片成本, 而每个主分片都相应的有一个copy.
一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。
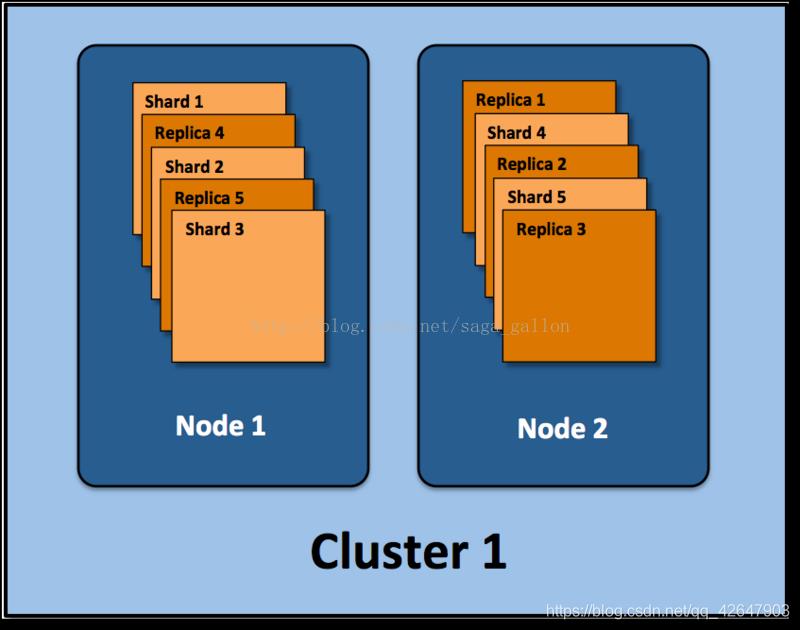
如下:ElasticSearch集群有两个节点, 并使用了默认的分片配置. ES自动把这5个主分片分配到2个节点上, 而它们分别对应的副本则在完全不同的节点上.
2.2 倒排索引
参考文章:Elasticsearch倒排索引结构
PUT一个JSON的对象,这个对象有多个字段,在插入这些数据到索引的同时,Elasticsearch还为这些字段建立索引——倒排索引,因为Elasticsearch最核心功能是搜索。

Term(单词):一段文本经过分析器分析以后就会输出一串单词,这一个一个的就叫做Term(直译为:单词)
Term Dictionary(单词字典):顾名思义,它里面维护的是Term,可以理解为Term的集合
Term Index(单词索引):为了更快的找到某个单词,我们为单词建立索引
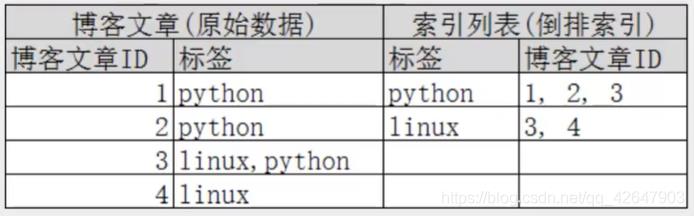
Posting List(倒排列表):倒排列表记录了出现过某个单词的所有文档的文档列表及单词在该文档中出现的位置信息,每条记录称为一个倒排项(Posting)。根据倒排列表,即可获知哪些文档包含某个单词。
为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens) ,建立字段的倒序索引,通过ID号找到文章,类似于数据库的底层索引原理。
要对字符串进行切分,引入IK分词器插件,帮助ElasticSearch进行拆分
2.3 IK分词插件
1、下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases,注意一定要下载对应的版本
问题:版本不对应导致闪退

2、解压后放入es的插件目录plugins下即可

3、重启ES、启动kbana,过程会比较慢,可能还会报Timeout的异常。
4、连接之后打开127.0.0.1:5601,点击开发工具,设置analysis可以进行分词操作
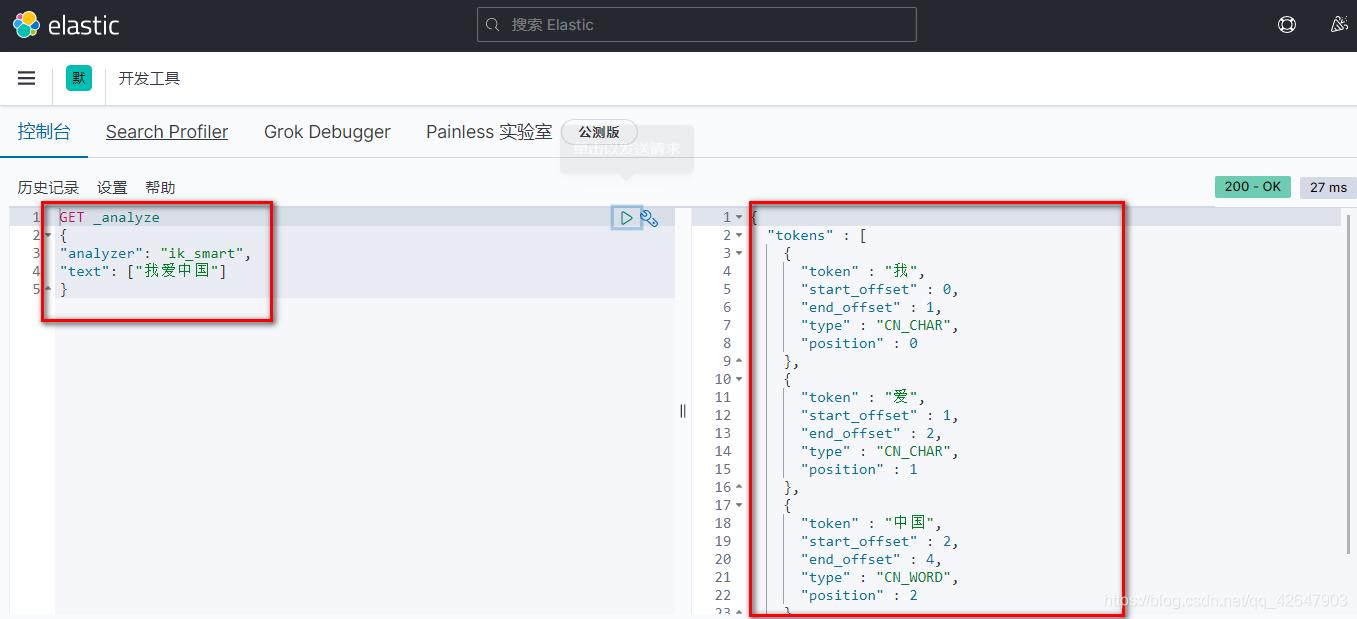
Ik分词器有两种分词算法
-
ik_smart
-
ik_max_word,最细粒度划分会把所有可能的组合都划分出来(划分方式由某个字典规定)
扩展:自定义字典,让最细粒划分不要把有意义的词细分了
在
ik/config/IKAnalyzer.cfg.xml,在config目录下新建一个自己的.dic字典文件并录入IKAnalyzer.cfg.xml中然后重启es即可
3 ES的CRUD
3.1 索引
3.1.1 创建索引 PUT
PUT /索引名/类型/文档ID
{
请求体
}
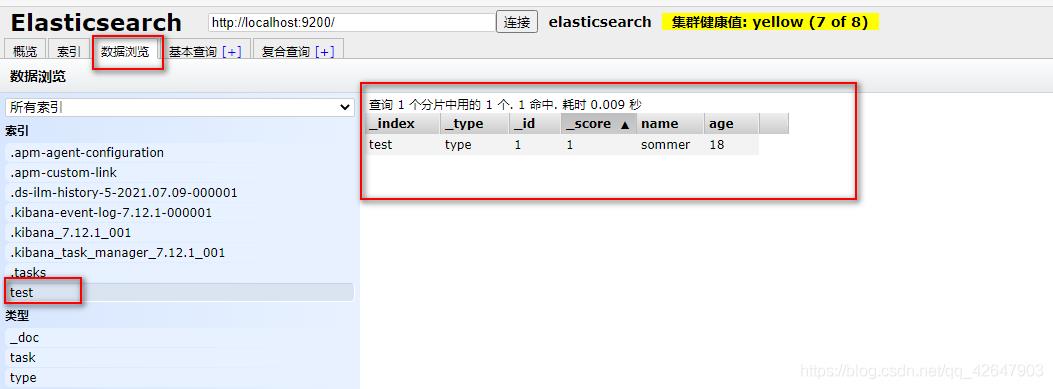
PUT /test/_doc/1
{
"name":"sommer",
"age":18
}
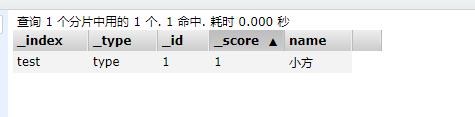
3.1.2 更新索引 POST
//result里面可以看到更新的影响,version可以看到更新的次数
POST /test/_doc/1
{
"name":"小方"
}

3.1.3 删除索引
DELETE test1(索引名或文档记录ID)
4 实战
一条数据对应一个文档,可以理解成一个实例
当我们需要创建一个文档时,要索引到这个文档,必定要考虑放在哪个索引的什么类型的节点号是多少
PUT megacorp/employee/1
{
"first_name":"tom",
"last_name":"jerry",
"age":21,
"about":"I like to go runing",
"likes":["sports","music"]
}
4. 1 搜索
4.1.1 索引文档
GET /megacorp/employee/1
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "1",
"_version" : 1,
"found" : true,
"_source" : {
"first_name" : "John",
"last_name" : "Smith",
"age" : 25,
"about" : "I love to go rock climbing",
"interests": [ "sports", "music" ]
}
}
4.1.2 高级搜索_search:
1、 _search
类似于Url中传参的操作
GET /megacorp/employee/_search
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests" : [
"music"
]
}
},
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"first_name" : "tom",
"last_name" : "jerry",
"age" : 21,
"about" : "I like to go runing",
"likes" : [
"sports",
"music"
]
}
},
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"first_name" : "Douglas",
"last_name" : "Smith",
"age" : 35,
"about" : "I like to build cabinets",
"interests" : [
"forestry"
]
}
}
]
}
}
2、搜索带参数
GET /megacorp/employee/_search?q=last_name:Smith
{
"took" : 20,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.6931471,
"hits" : [
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "2",
"_score" : 0.6931471,
"_source" : {
"first_name" : "Jane",
"last_name" : "Smith",
"age" : 32,
"about" : "I like to collect rock albums",
"interests" : [ "music" ]
}
},
{
"_index" : "megacorp",
"_type" : "employee",
"_id" : "3",
"_score" : 0.6931471,
"_source" : {
"first_name" : "Douglas",
"last_name" : "Smith",
"age" : 35,
"about" : "I like to build cabinets",
"interests" : [ "forestry"]
}
}
]
}
}
3、查询表达式 DSL Query-string
上面的查询语句相当于下面这
GET /megacorp/employee/_search
{
"query": {
"match": {
"last_name":"Smith"
}
}
}
4.2 结构化搜索
4.2.1 精确值查找时, 我们会使用过滤器(filters)。
过滤器很重要,因为它们执行速度非常快,不会计算相关度(直接跳过了整个评分阶段)而且很容易被缓存。请尽可能多的使用过滤式查询。
最为常用的 term 查询, 可以用它处理数字(numbers)、布尔值(Booleans)、日期(dates)以及文本(text)。
GET /my_store/products/_search
{
"query":{//查询的DSL结构化语句
"constant_score": {//以非评分模式来执行 term 查询并以一作为统一评分
"filter": {//过滤式查询
"term":{//term查询
"price":20
}
}
}
}
}
自定义映射,防止对某些字段进行分词,设置properties为not_analyzed
查找多个 terms
范围查询 range
gt:>大于(greater than)lt:<小于(less than)gte:>=大于或等于(greater than or equal to)lte:<=小于或等于(less than or equal to)
GET /my_store/products/_search
{
"query" : {
"constant_score" : {
"filter" : {
"terms" : {
"price" : [20, 30]
},
"range" : {
"price" : {
"gte" : 20,
"lt" : 40
}
}
}
}
}
}
4.2.2 复合过滤器:布尔过滤器
bool 查询运行每个 match 查询,再把评分加在一起,然后将结果与所有匹配的语句数量相乘,除以所有的语句数量。得到score
{
"bool" : {
"must" : [],//表示and
"should" : [],//表示或
"must_not" : [],//表示not
}
}
GET /my_store/products/_search
{
"query":{
"bool":{
"should" : [
{ "term" : {"price" : 20}},
{ "term" : {"productID" : "XHDK-A-1293-#fJ3"}}
],
"must_not" : {
"term" : {"price" : 30}
}
}
}
}
4.2.3 其他
- 判断是否为空:
exists - 判断是否不为空:
missing
4.3 全文搜索
4.3.1 匹配查询match
高级 全文查询 ,这表示它既能处理全文字段,又能处理精确字段。 match 查询都应该会是首选的查询方式。
GET /my_index/my_type/_search
{
"query": {
"match": {
"title": {
"query": "BROWN DOG!",//支持多词查询
"operator": "and" //设置多词的满足关系,或者用下面这个语句来控制精度
"minimum_should_match": "75%"//控制精度,即四条 should 语句中至少有三条必须匹配。
"boost": 2//设置此条query的权重
}
}
}
}
4.3.2 批量的增删改 _bulk
参考文章:https://gyoomi.blog.csdn.net/article/details/109237175
bulk是es提供的一种批量增删改的操作API
{ action: { metadata }}
{ request body }
{ action: { metadata }}
{ request body }
为索引批量插入文档
POST example/docs/_bulk
{"index": {"_id": 1}}//操作是插入id
{"id":1, "name": "admin", "counter":"10", "tags":["red", "black"]}//id的内容
{"index": {"_id": 2}}
{"id":2, "name": "张三", "counter":"20", "tags":["green", "purple"]}
{"index": {"_id": 3}}
{"id":3, "name": "李四", "counter":"30", "tags":["red", "blue"]}
{"index": {"_id": 4}}
{"id":4, "name": "tom", "counter":"40", "tags":["orange"]}
//得到结果:
{
"took": 18,
"errors": false,
"items": [
{
"index": {
"_index": "example",
"_type": "docs",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1,
"status": 201
}
},.....
4.4 聚合查询
4.4.1 概念
桶:类似于分组,通过国家、性别、年龄段进行划分
指标:数据统计,(例如最小值、平均值、最大值,还有汇总
4.4.2 实例
学习聚合的最佳途径就是用实例来说明。 一旦我们获得了聚合的思想,以及如何合理地嵌套使用它们,那么语法就变得不那么重要了
es对没有加入索引的是不支持聚合查询的,如果需要聚合查询执行下面的语句
"error" : {
"root_cause" : [{
"type" : "illegal_argument_exception",
"reason" : "Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [color] in order to load field data by uninverting the inverted index. Note that this can use significant memory."
}],
以上是关于ElasticSearch暗转与基础知识的主要内容,如果未能解决你的问题,请参考以下文章