设计模式---迭代器模式
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了设计模式---迭代器模式相关的知识,希望对你有一定的参考价值。
迭代器模式
前言
很早之前,我们的电视调节频道是需要用电视上的按钮去控制的,那时并没有遥控器,如果我们想要调台,只能一次又一次的拧按钮。

越来越高级的电视机相继出现,现在的电话机,我们有了电视遥控器,我们使用电视遥控器来调台,这个时候,无需直接操作电视。


我们可以将电视机看成一个存储电视频道的集合对象,通过遥控器可以对电视机中的电视频道集合进行操作,如返回上一个频道、跳转到下一个频道或者跳转至指定的频道。遥控器为我们操作电视频道带来很大的方便,用户并不需要知道这些频道到底如何存储在电视机中。
介绍
迭代器模式(Iterator Pattern):提供一种方法来访问聚合对象,而不用暴露这个对象的内部表示,其别名为游标(Cursor)。迭代器模式是一种对象行为型模式。
角色
Iterator(抽象迭代器):它定义了访问和遍历元素的接口,声明了用于遍历数据元素的方法,例如:用于获取第一个元素的first()方法,用于访问下一个元素的next()方法,用于判断是否还有下一个元素的hasNext()方法,用于获取当前元素的currentItem()方法等,在具体迭代器中将实现这些方法。
ConcreteIterator(具体迭代器):它实现了抽象迭代器接口,完成对聚合对象的遍历,同时在具体迭代器中通过游标来记录在聚合对象中所处的当前位置,在具体实现时,游标通常是一个表示位置的非负整数。
Aggregate(抽象聚合类):它用于存储和管理元素对象,声明一个createIterator()方法用于创建一个迭代器对象,充当抽象迭代器工厂角色。
ConcreteAggregate(具体聚合类):它实现了在抽象聚合类中声明的createIterator()方法,该方法返回一个与该具体聚合类对应的具体迭代器ConcreteIterator实例。
在迭代器模式中,提供了一个外部的迭代器来对聚合对象进行访问和遍历,迭代器定义了一个访问该聚合元素的接口,并且可以跟踪当前遍历的元素,了解哪些元素已经遍历过而哪些没有。迭代器的引入,将使得对一个复杂聚合对象的操作变得简单。
迭代器模式中的工厂模式
在迭代器模式中应用了工厂方法模式,抽象迭代器对应于抽象产品角色,具体迭代器对应于具体产品角色,抽象聚合类对应于抽象工厂角色,具体聚合类对应于具体工厂角色。
学院遍历的案例
编写程序展示一个学校院系结构:需求是这样,要在一个页面中展示出学校的院系 组成, 一个学校有多个学院,一个学院有多个系。
分析
每一个学院都有添加系的功能,如果我们将遍历的方法hasNext() next()等写入。这将导致聚合类的职责过重,它既负责存储和管理数据,又负责遍历数据,违反了“单一职责原则”,由于聚合类非常庞大,实现代码过长,还将给测试和维护增加难度。
那么这个时候,我们也许会这样想,因为有多个学院,我们不妨将学院封装为接口,但是在这个接口中充斥着大量方法,不利于子类实现,违反了“接口隔离原则”。
解决方案
解决方案之一就是将聚合类中负责遍历数据的方法提取出来,封装到专门的类中,实现数据存储和数据遍历分离,无须暴露聚合类的内部属性即可对其进行操作,而这正是迭代器模式的意图所在。
基本介绍
- 迭代器模式(Iterator Pattern)是常用的设计模式,属于行为型模式
- 如果我们的集合元素是用不同的方式实现的,有数组,还有java的集合类,或者还有其他方式,当客户端要遍历这些集合元素的时候就要使用多种遍历 方式,而且还会暴露元素的内部结构,可以考虑使用迭代器模式解决。
- 迭代器模式,提供一种遍历集合元素的统一接口,用一致的方法遍历集合元素, 不需要知道集合对象的底层表示,即:不暴露其内部的结构。
原理类图
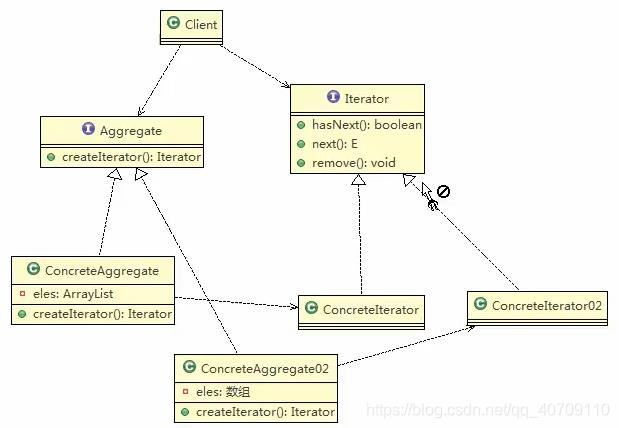
上面案例的类图
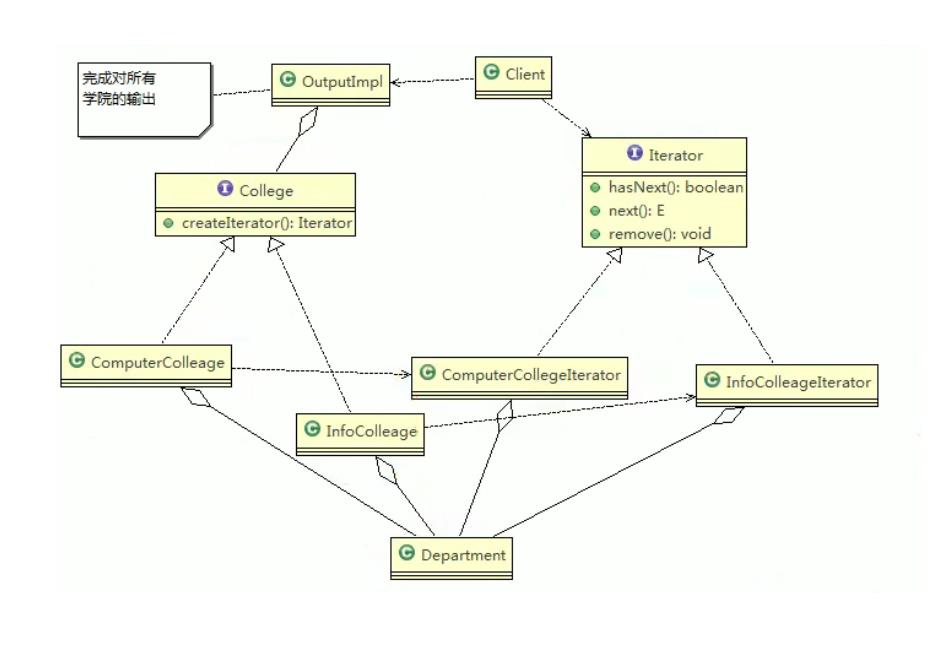
案例实现代码
顶层迭代器接口为Java内部提供的Iterator接口:

计算机学院迭代器类,负责遍历计算机学院类下面的系集合
public class ComputerCollegeIterator implements Iterator {
//以数组的方式存放计算机学院下面的各个系
private Department[] departments;
//当前遍历到的位置
private Integer position=0;
//通过构造器获得要遍历的集合
public ComputerCollegeIterator(Department[] departments)
{
this.departments=departments;
}
//判断是否还存在下一个元素
@Override
public boolean hasNext() {
if(position>departments.length-1||departments[position]==null)
{
return false;
}
return true;
}
//返回下一个元素
@Override
public Object next() {
return departments[position++];
}
//删除的方法默认空实现
@Override
public void remove()
{}
}
信息学院迭代器类,负责遍历信息学院下面的系集合
//信息学院
public class InfoCollegeIterator implements Iterator
{
//以list的方式存放系
private List<Department> departments;
//索引
private Integer index=0;
//构造器得到要遍历的集合
InfoCollegeIterator(List<Department> departments)
{
this.departments=departments;
}
//判断list集合中是否还有下一个元素
@Override
public boolean hasNext() {
if(index>departments.size()-1)
{
return false;
}
return true;
}
@Override
public Object next() {
return departments.get(index++);
}
@Override
public void remove() {
}
}
这里对应的各个学院的迭代器类,单独负责遍历当前学院下面系集合的逻辑
这里的优化措施可以将两个迭代器里面重复内容抽取出来,放到CollegeIterator类里面进行默认实现,该类继承Iterator接口,而上面两个学院迭代器类继承该默认实现类
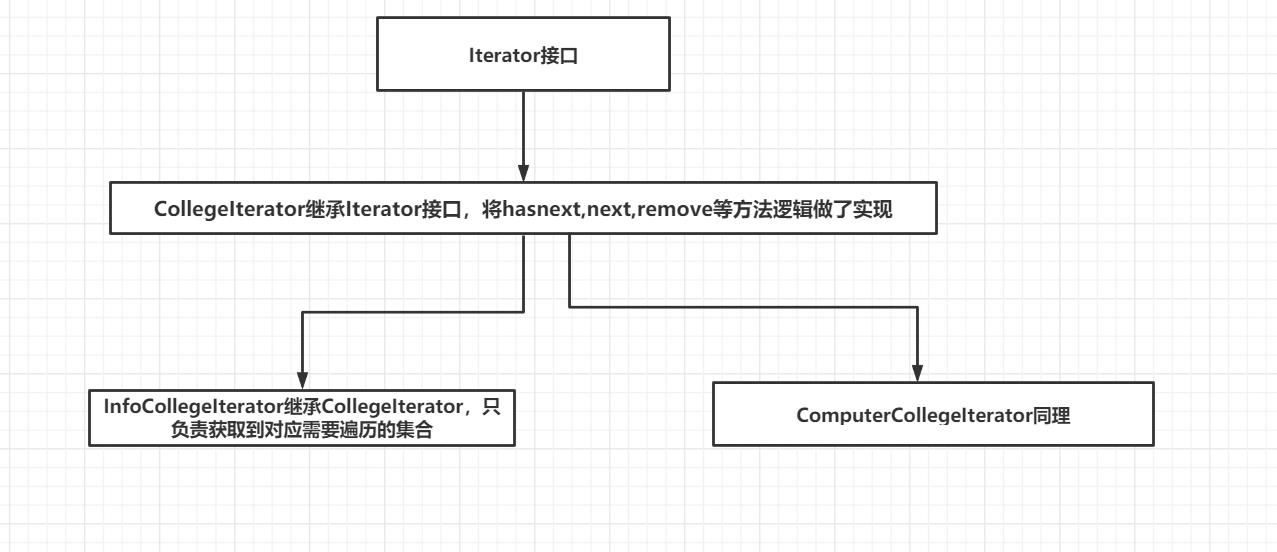
迭代器遍历集合里面存放的元素:
@Data
@AllArgsConstructor
@NoArgsConstructor
//学院下面的各个系--也是迭代器需要遍历的对象
public class Department
{
private String name;//名字
private Integer score;//分数线
}
顶层抽象学院接口
//抽象学院接口
public interface College
{
//获取当前系的名字
void getName();
//增加系
void addDepartment(String name,Integer score);
//返回一个迭代器,负责遍历
Iterator createIterator();
}
计算机学院,管理学院下面的各个系
public class ComputerCollege implements College{
//数组默认大小为10
private Department[] departments=new Department[10];
private Integer numOfDepartment=0;//当前数组中保存的对象个数
@Override
public void getName() {
System.out.println("计算机学院");
}
//获取到对应的系集合
public ComputerCollege(Department[] departments)
{
int i=0;
for (Department department : departments) {
this.departments[i++]=department;
}
}
//增加系
@Override
public void addDepartment(String name,Integer score)
{
Department department=new Department(name,score);
departments[numOfDepartment++]=department;
}
//创建对应的迭代器,并传入要遍历的集合给迭代器
@Override
public Iterator createIterator() {
return new ComputerCollegeIterator(departments);
}
}
信息学院,负责管理下面的各个系:
//信息学院
public class InfoCollegeIterator implements Iterator
{
//以list的方式存放系
private List<Department> departments;
//索引
private Integer index=0;
InfoCollegeIterator(List<Department> departments)
{
this.departments=departments;
}
//判断list集合中是否还有下一个元素
@Override
public boolean hasNext() {
if(index>departments.size()-1)
{
return false;
}
return true;
}
@Override
public Object next() {
return departments.get(index++);
}
@Override
public void remove() {
}
}
输出类,主要负责输出功能:
public class OutputImp
{
//学院集合
private List<College> collegeList;
public OutputImp(List<College> collegeList)
{
this.collegeList=collegeList;
}
//输出所有学院,以及学院下面的所有系
public void printColleges()
{
//获取到遍历学院集合需要用到的迭代器
//list集合实现了iterator接口
Iterator<College> collegeIterator = collegeList.iterator();
while(collegeIterator.hasNext())
{
College college = collegeIterator.next();
System.out.println("当前学院:");
college.getName();
System.out.println("当前学院下面的系:");
//如果要遍历当前学院下面的所有系,需要获取对应的迭代器
printDeparts(college.createIterator());
System.out.println("=============================");
}
}
//输出当前学院的所有系
protected void printDeparts(Iterator iterator)
{
while(iterator.hasNext())
{
Department department=(Department)iterator.next();
System.out.println(department.getName());
}
}
}
客户端调用:
public static void main(String[] args) {
List<College> collegeList=new ArrayList<>();
Department[] departments=new Department[3];
departments[0]=new Department("c++",520);
departments[1]=new Department("java",521);
College college=new ComputerCollege(departments);
List<Department> departmentList=new ArrayList<>();
departmentList.add(new Department("密码学",520));
College college1=new InfoCollege(departmentList);
collegeList.add(college);
collegeList.add(college1);
OutputImp outputImp=new OutputImp(collegeList);
outputImp.printColleges();
}

案例总结
如果需要增加一个新的具体聚合类,只需增加一个新的聚合子类和一个新的具体迭代器类即可,原有类库代码无须修改,符合“开闭原则”;
如果需要为聚合类更换一个迭代器,只需要增加一个新的具体迭代器类作为抽象迭代器类的子类,重新实现遍历方法,原有迭代器代码无须修改,也符合“开闭原则”;
但是如果要在迭代器中增加新的方法,则需要修改抽象迭代器源代码,这将违背“开闭原则”。
应用实例
Java集合中的迭代器模式
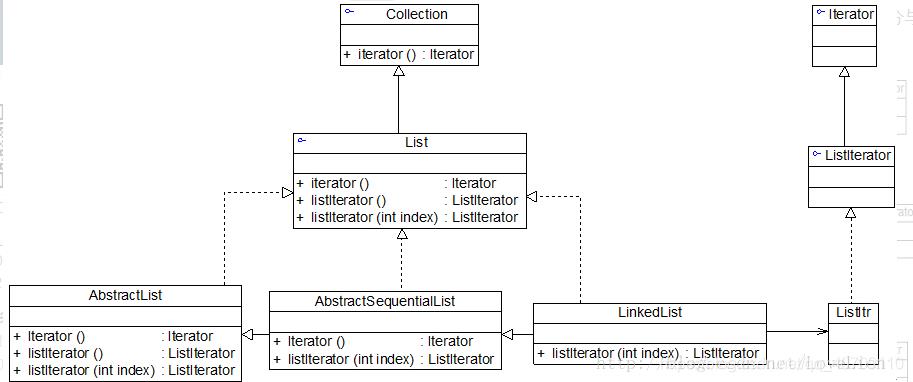
看 java.util.ArrayList 类
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
transient Object[] elementData; // non-private to simplify nested class access
private int size;
public E get(int index) {
rangeCheck(index);
return elementData(index);
}
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
public ListIterator<E> listIterator() {
return new ListItr(0);
}
public ListIterator<E> listIterator(int index) {
if (index < 0 || index > size)
throw new IndexOutOfBoundsException("Index: "+index);
return new ListItr(index);
}
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size;
}
public E next() {
//...
}
public E next() {
//...
}
public void remove() {
//...
}
//...
}
private class ListItr extends Itr implements ListIterator<E> {
public boolean hasPrevious() {
return cursor != 0;
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor - 1;
}
public E previous() {
//...
}
public void set(E e) {
//...
}
public void add(E e) {
//...
}
//...
}
从 ArrayList 源码中看到了有两个迭代器 Itr 和 ListItr,分别实现 Iterator 和 ListIterator 接口;
第一个当然很容易看明白,它跟我们示例的迭代器的区别是这里是一个内部类,可以直接使用 ArrayList 的数据列表;第二个迭代器是第一次见到, ListIterator 跟 Iterator 有什么区别呢?
先看 ListIterator 源码
public interface ListIterator<E> extends Iterator<E> {
boolean hasNext();
E next();
boolean hasPrevious(); // 返回该迭代器关联的集合是否还有上一个元素
E previous(); // 返回该迭代器的上一个元素
int nextIndex(); // 返回列表中ListIterator所需位置后面元素的索引
int previousIndex(); // 返回列表中ListIterator所需位置前面元素的索引
void remove();
void set(E var1); // 从列表中将next()或previous()返回的最后一个元素更改为指定元素e
void add(E var1);
}
接着是 Iterator 的源码
public interface Iterator<E> {
boolean hasNext();
E next();
default void remove() {
throw new UnsupportedOperationException("remove");
}
// 备注:JAVA8允许接口方法定义默认实现
default void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
while (hasNext())
action.accept(next());
}
}
通过源码我们看出:ListIterator 是一个功能更加强大的迭代器,它继承于 Iterator 接口,只能用于各种List类型的访问。可以通过调用 listIterator() 方法产生一个指向List开始处的 ListIterator, 还可以调用 listIterator(n) 方法创建一个一开始就指向列表索引为n的元素处的 ListIterator。
Iterator 和 ListIterator 主要区别概括如下:
- ListIterator 有 add() 方法,可以向List中添加对象,而 Iterator 不能
- ListIterator 和 Iterator 都有 hasNext() 和 next() 方法,可以实现顺序向后遍历,但是ListIterator 有 hasPrevious() 和 previous()方法,可以实现逆向(顺序向前)遍历。Iterator 就不可以。
- ListIterator 可以定位当前的索引位置,nextIndex() 和 previousIndex()可以实现。Iterator 没有此功能。
- 都可实现删除对象,但是 ListIterator 可以实现对象的修改,set() 方法可以实现。Iierator仅能遍历,不能修改。
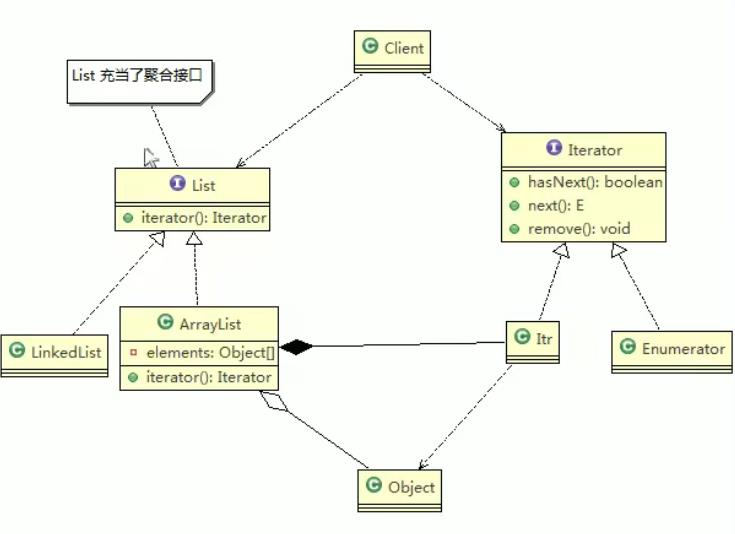
角色说明
- 内部类Itr 充当具体实现迭代器Iterator 的类, 作为ArrayList 内部类
- List 就是充当了聚合接口,含有一个iterator() 方法,返回一个迭代器对象
- ArrayList 是实现聚合接口List 的子类,实现了iterator()
- Iterator 接口系统提供
- 迭代器模式解决了 不同集合(ArrayList ,LinkedList) 统一遍历问题
Mybatis中的迭代器模式
当查询数据库返回大量的数据项时可以使用游标 Cursor,利用其中的迭代器可以懒加载数据,避免因为一次性加载所有数据导致内存奔溃,Mybatis 为 Cursor 接口提供了一个默认实现类 DefaultCursor,代码如下
public interface Cursor<T> extends Closeable, Iterable<T> {
boolean isOpen();
boolean isConsumed();
int getCurrentIndex();
}
public class DefaultCursor<T> implements Cursor<T> {
private final DefaultResultSetHandler resultSetHandler;
private final ResultMap resultMap;
private final ResultSetWrapper rsw;
private final RowBounds rowBounds;
private final ObjectWrapperResultHandler<T> objectWrapperResultHandler = new ObjectWrapperResultHandler<T>();
// 游标迭代器
private final CursorIterator cursorIterator = new CursorIterator();
protected T fetchNextUsingRowBound() {
T result = fetchNextObjectFromDatabase();
while (result != null && indexWithRowBound < rowBounds.getOffset()) {
result = fetchNextObjectFromDatabase();
}
return result;
}
@Override
public Iterator<T> iterator() {
if (iteratorRetrieved) {
throw new IllegalStateException("Cannot open more than one iterator on a Cursor");
}
iteratorRetrieved = true;
return cursorIterator;
}
private class CursorIterator implements Iterator<T> {
T object;
int iteratorIndex = -1;
@Override
public boolean hasNext() {
if Java源代码-迭代器模式