「深度学习一遍过」必修19:基于LeNet-5的MNIST手写数字识别
Posted 小泽yyds
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了「深度学习一遍过」必修19:基于LeNet-5的MNIST手写数字识别相关的知识,希望对你有一定的参考价值。
本专栏用于记录关于深度学习的笔记,不光方便自己复习与查阅,同时也希望能给您解决一些关于深度学习的相关问题,并提供一些微不足道的人工神经网络模型设计思路。
专栏地址:「深度学习一遍过」必修篇
目录
项目 GitHub 地址Classic_model_examples/1998_LeNet-5_MNIST at main · zhao302014/Classic_model_examples · GitHubContribute to zhao302014/Classic_model_examples development by creating an account on GitHub. https://github.com/zhao302014/Classic_model_examples/tree/main/1998_LeNet-5_MNIST
https://github.com/zhao302014/Classic_model_examples/tree/main/1998_LeNet-5_MNIST
项目心得
- 1998 年——LeNet-5:这是 Yann LeCun 在 1998 年设计的用于手写数字识别的卷积神经网络。该项目自己搭建了 Lenet-5 网络并在 MNIST 手写数字识别项目中得到了应用。(注:该项目最令我印象深刻的是我自己验证了几年前学者验证的最大池化的效果是要优于平均池化的;这一点在本项目代码中并没有体现,原因是项目旨在遵循基准 LeNet-5 模型的各项指标,应用了基准模型设计的平均池化,若改为最大池化,训练代码中的优化器定义可删去动量项,亦可随之删去学习率变化代码,也可达到同样效果)
项目代码
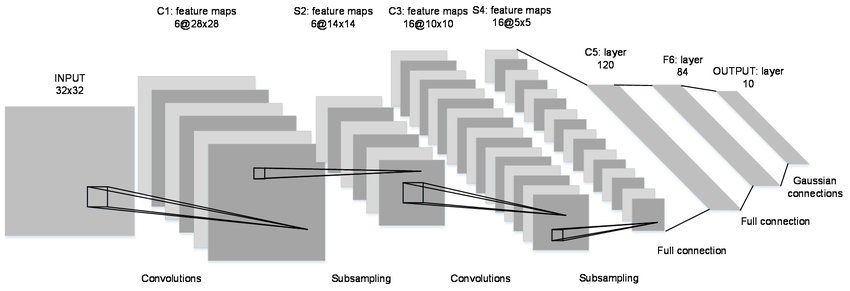
net.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
# ------------------------------------------------- #
# 作者:赵泽荣
# 时间:2021年9月9日(农历八月初三)
# 个人站点:1.https://zhao302014.github.io/
# 2.https://blog.csdn.net/IT_charge/
# 个人GitHub地址:https://github.com/zhao302014
# ------------------------------------------------- #
import torch
from torch import nn
# ------------------------------------------------------------------------------- #
# 自己搭建一个 LeNet-5 模型结构
# · LeNet-5 是 Yann LeCun 在 1998 年设计的用于手写数字识别的卷积神经网络
# · 所有卷积核均为 5×5,步长为 1
# · 所有池化方法为平均池化
# · 所有激活函数采用 Sigmoid
# · 该模型共 7 层(3 个卷积层,2 个池化层,2 个全连接层)
# · LeNet5 网络结构被称为第 1 个典型的 CNN
# ------------------------------------------------------------------------------- #
class MyLeNet5(nn.Module):
def __init__(self):
super(MyLeNet5, self).__init__()
self.c1 = nn.Conv2d(in_channels=1, out_channels=6, kernel_size=5, padding=2)
self.Sigmoid = nn.Sigmoid()
self.s2 = nn.AvgPool2d(2)
self.c3 = nn.Conv2d(in_channels=6, out_channels=16, kernel_size=5)
self.s4 = nn.AvgPool2d(2)
self.flatten = nn.Flatten()
self.c5 = nn.Conv2d(in_channels=16, out_channels=120, kernel_size=5)
self.f6 = nn.Linear(120, 84)
self.output = nn.Linear(84, 10)
def forward(self, x): # 输入shape: torch.Size([1, 1, 28, 28])
x = self.Sigmoid(self.c1(x)) # shape: torch.Size([1, 6, 28, 28])
x = self.s2(x) # shape: torch.Size([1, 6, 14, 14])
x = self.Sigmoid(self.c3(x)) # shape: torch.Size([1, 16, 10, 10])
x = self.s4(x) # shape: torch.Size([1, 16, 5, 5]
x = self.c5(x) # shape: torch.Size([1, 120, 1, 1])
x = self.flatten(x) # shape: torch.Size([1, 120])
x = self.f6(x) # shape: torch.Size([1, 84])
x = self.output(x) # shape: torch.Size([1, 10])
return x
if __name__ == '__main__':
x = torch.rand([1, 1, 28, 28])
model = MyLeNet5()
y = model(x)train.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
# ------------------------------------------------- #
# 作者:赵泽荣
# 时间:2021年9月9日(农历八月初三)
# 个人站点:1.https://zhao302014.github.io/
# 2.https://blog.csdn.net/IT_charge/
# 个人GitHub地址:https://github.com/zhao302014
# ------------------------------------------------- #
import torch
from torch import nn
from net import MyLeNet5
from torch.optim import lr_scheduler
from torchvision import datasets, transforms
data_transform = transforms.Compose([
transforms.ToTensor() # 仅对数据做转换为 tensor 格式操作
])
# 加载训练数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_transform, download=True)
# 给训练集创建一个数据集加载器
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
# 加载测试数据集
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_transform, download=True)
# 给测试集创建一个数据集加载器
test_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else 'cpu'
# 调用 net 里定义的模型,如果 GPU 可用则将模型转到 GPU
model = MyLeNet5().to(device)
# 定义损失函数(交叉熵损失)
loss_fn = nn.CrossEntropyLoss()
# 定义优化器(SGD:随机梯度下降)
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3, momentum=0.9)
# 学习率每隔 10 个 epoch 变为原来的 0.1
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
loss, current, n = 0.0, 0.0, 0
for batch, (X, y) in enumerate(dataloader):
# 前向传播
X, y = X.to(device), y.to(device)
output = model(X)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred) / output.shape[0]
# 反向传播
optimizer.zero_grad()
cur_loss.backward()
optimizer.step()
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
print('train_loss:' + str(loss / n))
print('train_acc:' + str(current / n))
# 定义测试函数
def test(dataloader, model, loss_fn):
# 将模型转换为验证模式
model.eval()
loss, current, n = 0.0, 0.0, 0
# 非训练,推理期用到(测试时模型参数不用更新,所以 no_grad)
with torch.no_grad():
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device)
output = model(X)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred) / output.shape[0]
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
print('test_loss:' + str(loss / n))
print('test_acc:' + str(current / n))
# 开始训练
epoch = 100
for t in range(epoch):
lr_scheduler.step()
print(f"Epoch {t + 1}\\n----------------------")
train(train_dataloader, model, loss_fn, optimizer)
test(test_dataloader, model, loss_fn)
torch.save(model.state_dict(), "save_model/{}model.pth".format(t)) # 模型保存
print("Done!")test.py
#!/usr/bin/python
# -*- coding:utf-8 -*-
# ------------------------------------------------- #
# 作者:赵泽荣
# 时间:2021年9月9日(农历八月初三)
# 个人站点:1.https://zhao302014.github.io/
# 2.https://blog.csdn.net/IT_charge/
# 个人GitHub地址:https://github.com/zhao302014
# ------------------------------------------------- #
import torch
from net import MyLeNet5
from torch.autograd import Variable
from torchvision import datasets, transforms
from torchvision.transforms import ToPILImage
data_transform = transforms.Compose([
transforms.ToTensor() # 仅对数据做转换为 tensor 格式操作
])
# 加载训练数据集
train_dataset = datasets.MNIST(root='./data', train=True, transform=data_transform, download=True)
# 给训练集创建一个数据集加载器
train_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
# 加载测试数据集
test_dataset = datasets.MNIST(root='./data', train=False, transform=data_transform, download=True)
# 给测试集创建一个数据集加载器
test_dataloader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=16, shuffle=True)
# 如果显卡可用,则用显卡进行训练
device = "cuda" if torch.cuda.is_available() else 'cpu'
# 调用 net 里定义的模型,如果 GPU 可用则将模型转到 GPU
model = MyLeNet5().to(device)
# 加载 train.py 里训练好的模型
model.load_state_dict(torch.load("./save_model/99model.pth"))
# 获取预测结果
classes = [
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9",
]
# 把 tensor 转成 Image,方便可视化
show = ToPILImage()
# 进入验证阶段
model.eval()
# 对 test_dataset 里 10000 张手写数字图片进行推理
for i in range(len(test_dataset)):
x, y = test_dataset[i][0], test_dataset[i][1]
# tensor格式数据可视化
show(x).show()
# 扩展张量维度为 4 维
x = Variable(torch.unsqueeze(x, dim=0).float(), requires_grad=False).to(device)
with torch.no_grad():
pred = model(x)
# 得到预测类别中最高的那一类,再把最高的这一类对应classes中的哪一个标签
predicted, actual = classes[torch.argmax(pred[0])], classes[y]
# 最终输出预测值与真实值
print(f'Predicted: "{predicted}", Actual: "{actual}"')欢迎大家交流评论,一起学习
希望本文能帮助您解决您在这方面遇到的问题
感谢阅读
END
以上是关于「深度学习一遍过」必修19:基于LeNet-5的MNIST手写数字识别的主要内容,如果未能解决你的问题,请参考以下文章