用一张草图创建GAN模型,新手也能玩转,朱俊彦团队新研究入选ICCV 2021
Posted Charmve
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用一张草图创建GAN模型,新手也能玩转,朱俊彦团队新研究入选ICCV 2021相关的知识,希望对你有一定的参考价值。
大家好,我是Charmve!快两周每更新文章了,大家会想我吗 :-)
最近在准备GitHub开源项目《计算机视觉实验演练:算法与应用》,源码、文本还有网站的搭建,我花了大量时间,就没腾出时间来给大家分享新内容。上周末将项目整体上线了,基本实现 “跨平台学习,一个浏览器就可以开始!”
有兴趣的社友们,可以到 GitHub 查看,https://github.com/Charmve/computer-vision-in-action
以用促学,先会后懂。理解深度学习的最佳方法是学以致用。
那现在就开始我们今天的文章分享,
CMU 助理教授朱俊彦团队的最新研究将 GAN 玩出了花,仅仅使用一个或数个手绘草图,即可以自定义一个现成的 GAN 模型,进而输出与草图匹配的图像。相关论文已被 ICCV 2021 会议接收。
深度生成模型(例如 GAN)强大之处在于,它们能够以最少的用户努力合成无数具有真实性、多样性和新颖的内容。近年来,随着大规模生成模型的质量和分辨率的不断提高,这些模型的潜在应用也不断的在增长。
然而,训练高质量生成模型需要高性能的计算平台,这使得大多数用户都无法完成这种训练。此外,训练高质量的模型还需要收集大规模数据以及复杂的预处理过程。常用的数据集(例如 ImageNet 、LSUN)需要人工标注和过滤;而专用的数据集 FFHQ Face 需要进行人脸对齐以及超分辨率预处理。此外,开发一个高级生成模型需要一组专家的领域知识,他们通常会在特定数据集的单个模型上投入数月或数年的时间,耗时较长。
这就引出了一个问题:普通用户如何创建自己的生成模型?比如,用猫来创造艺术作品的用户可能不愿意使用普通的猫模型,而希望是一种特殊猫的定制模特,摆着特定的姿势:在附近、斜倚着,或者都向左看。一般来说,要获得这样的定制模型,用户必须管理成千上万的向左倾斜的猫图像,然后需要领域专家花几个月的时间进行模型训练和参数调整,才能生成一个较为理想的模型。
在这项工作中,朱俊彦等来自 CMU 和 MIT 的研究者提出 GAN Sketching,该方法通过一个或多个草图重写 GAN,让新手用户更容易地训练 GAN。具体地,该方法还能通过用户草图改变原始 GAN 模型的权重,并且通过跨域(cross-domain )对抗损失鼓励模型输出来匹配用户草图。
此外,该研究还探索了不同的正则化方法,以保持原始模型的多样性和图像质量。

-
论文地址:https://arxiv.org/pdf/2108.02774.pdf
-
项目地址:https://peterwang512.github.io/GANSketching
实验表明,GAN Sketching 可以塑造 GAN 来匹配草图指定的形状和姿态,同时保持真实感和多样性。研究者最后演示了生成的 GAN 的一些应用,包括潜在空间插值和图像编辑等应用。
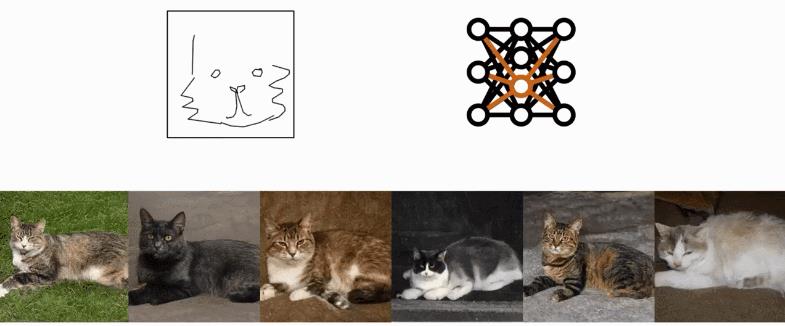
它的效果是这样的:绘制一张猫咪草图,模型会匹配与草图神似的猫咪图片:

看起来在远处、趴着的猫咪:
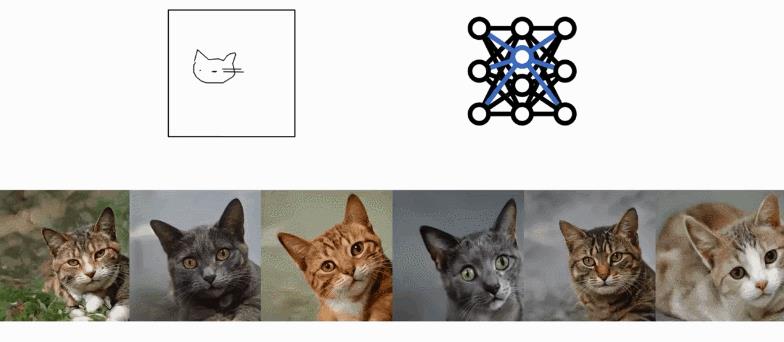
匹配和你对视的猫咪:
方法
研究者的目标是创建一个真实图像的模型,其中这些照片的形状和姿态由草图来指导,但输出的是真实图像,而不再是草图。
基于此,研究者提出了一个使用域转换网络的跨域对抗损失。不过,单单使用跨域对抗损失明显改变了模型的行为,并生成了不真实的结果。因此,他们通过图像空间正则化进一步训练模型,并且为了减轻模型的过拟合,他们限制了特定层的更新,并使用到了数据增强策略。
完整的训练流程如下图 2 所示:
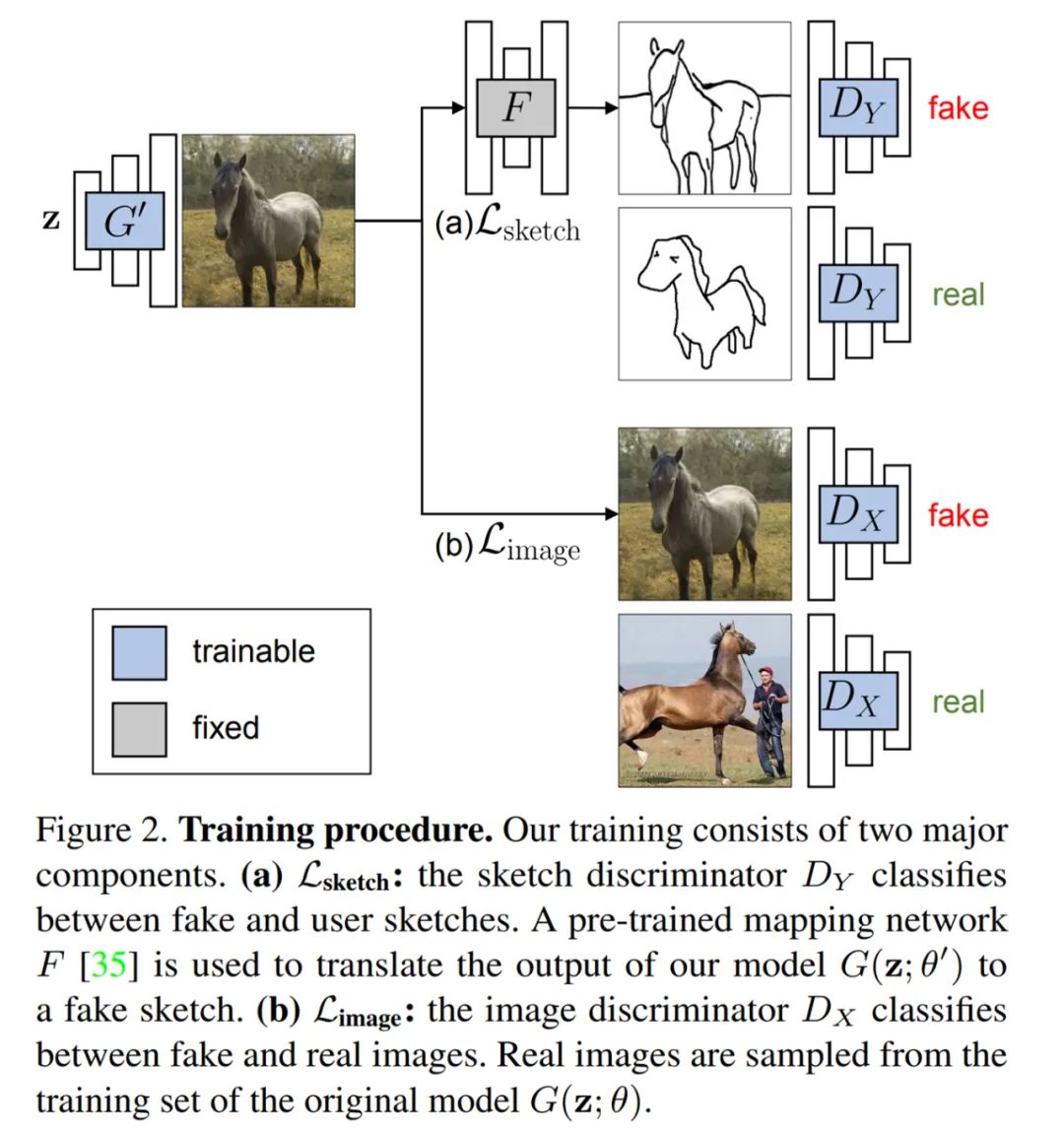
跨域对抗学习
假设 X, Y 分别是由图像和草图组成的域。研究者收集了一个大规模训练图像集 x ∼ p_data(x)和一些手绘草图 y ∼ p_data(y)。他们将 G(z; θ)作为一个从低维代码 z 中生成图像 x 的预训练 GAN,并希望创建一个新的 GAN 模型 G(z; θ´),它的输出图像呈现与 X 相同的数据分布,同时输出图像的草图也与 Y 的数据分布相似。
为了缩小草图训练数据与图像生成模型之间的差距,研究者提出以跨域对抗损失来激励生成的图像匹配草图 Y。在传递至判别器之前,生成器的输出通过预训练的图像 - 草图网络 F 转换成了草图。如公式(1)所示:
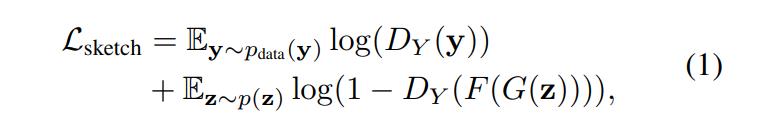
其中,研究者将 Photosketch 作为图像 - 草图网络 F。
图像空间正则化
研究者观察到,仅使用草图上的损失将大大降低图像质量和生成结果的多样性,这是因为该损失迫使生成图像的形状匹配草图。为了解决这一问题,他们添加了第二个对抗损失,以将输出与原始模型的训练设置进行比较。如公式(2)所示:
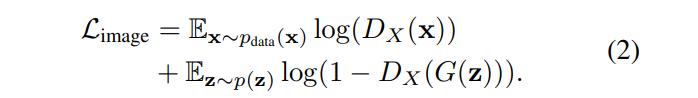
其中,判别器 D_X 用来保持图像质量和模型输出的多样性,并匹配用户的草图。
研究者还实验了权重正则化,其中使用公式(3)中的损失来显式地惩罚大的变化:
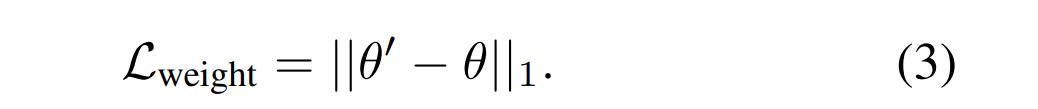
最后,研究者实验了图像和权重正则化方法联合训练的模型,结果发现,该模型并不优于仅通过图像正则化训练的模型。
优化
研究者的目标是:
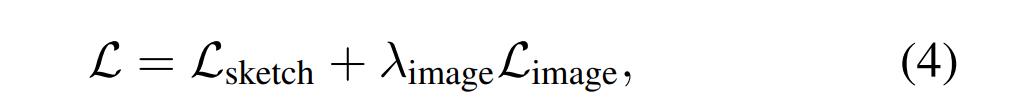
为了防止模型过拟合并加速微调速度,他们仅修改了 StyleGAN2 的映射网络的权重,其本质上是将 z ∼ N (0, I)重映射为不同的中间潜在空间(W 空间)。
此外,研究者使用了一个预训练的 Photosketch 网络 F,并通过训练固定了 F 的权重。他们实验了应用于训练草图的可微增强策略,结果发现,轻微的增强在场景测试中表现更好。在本研究中,他们使用了转换增强。
实验
为了实现大规模的定量评估,研究者构建了一个模型草图场景数据集。该研究使用 PhotoSketch 将数据集 LSUN 中的马、猫和教堂的图像转换为草图,并手工选择 30 幅形状和姿势相似的草图集合,指定为用户输入,如下图 3 所示。

该研究根据生成图像和评估集之间 FID(Frechet Inception Distance)来评估模型,为了公平比较,该研究通过选择具有最佳 FID 的迭代来评估每个模型。
该研究与以下基线进行了比较:(1)基线 (SBIR),使用 Bui 等人提出的基于草图的图像检索方法选择最佳匹配样本(2) 基线 (Chamfer),使用 PhotoSketch 计算的输入草图 y 和图像 x 的草图之间的对称倒角距离 d(x, y) + d(y, x) 匹配样本。
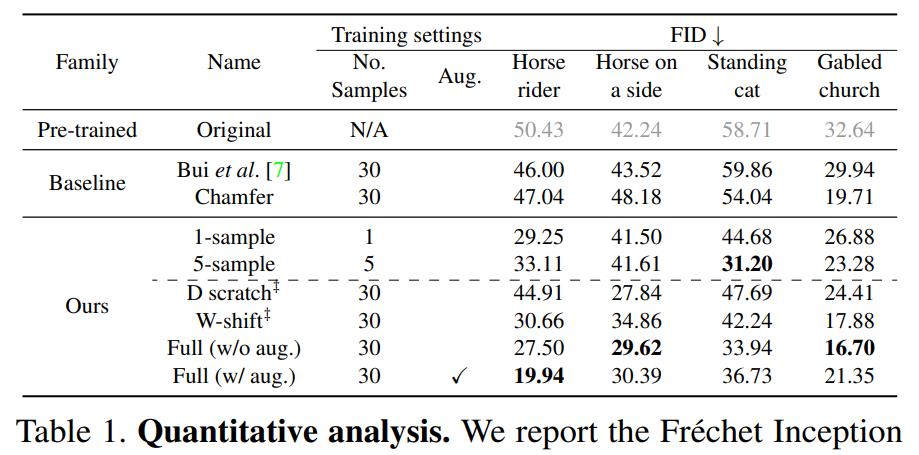
表 1 为定量比较,由结果可得该研究所用方法获得的 FID 明显优于基线 (SBIR) 和基线(Chamfer)。此外,该研究还调查了其他训练因素的影响,如表 1 所示。
更少的草图样本:该研究还测试了 GAN Sketching 方法是否能够处理较少数量的草图。每项任务只使用 1 或 5 个草图训练模型,这些草图选自前 30 个草图。结果如下表 1 所示。
消融实验:首先,该研究对正则化方法和数据增强效果进行了实验,结果如下表 2 所示:
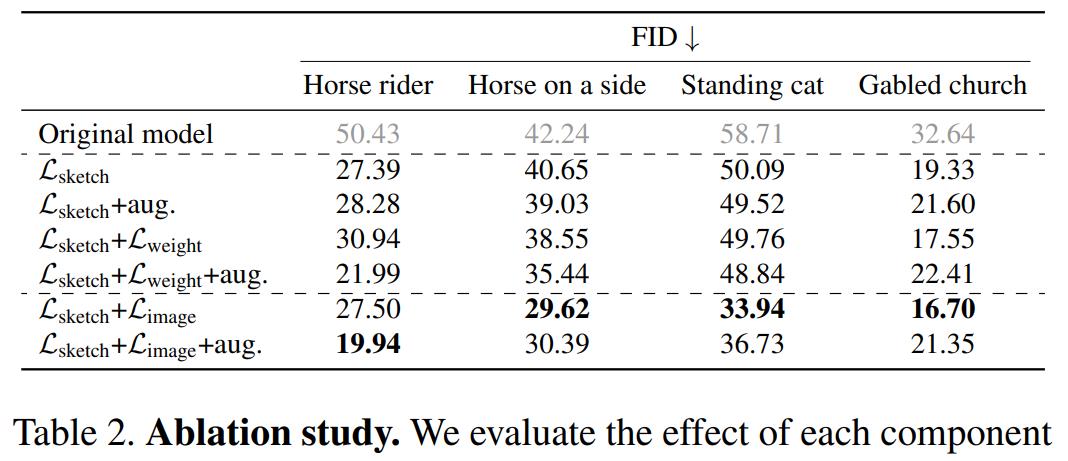
正则化方法对比:与使用 L_sketch 训练相比,正则化方法 L_image 或者 L_weight 提高了 FID,而使用 L_image 优于 L_weight 正则化方法。这与下图 4 中的观察结果一致,展示了经过正则化和不经过正则化训练的模型的 snapshot。

为了让普通用户可以定制 GAN,该研究还在新手手绘草图上进行了测试。研究者从 Quickdraw 数据集收集猫和马的草图作为训练图像。首先他们在一个草图上训练模型,并在下图 5 中显示成功和失败的案例。

该研究还观察到,在困难的情况下,可以通过增加输入用户草图的数量来提高性能,如下图 6 所示:

研究者还发现,增强策略是该方法在用户草图中获得成功必不可少的因素。如下图 7 所示,给定相同的输入草图,仅有通过增强策略训练的模型生成了忠实匹配输入草图的图像。

研究者将他们的方法应用于人脸生成模型,并使用增强策略加持的方法自定义了在 4 张人类手绘草图上训练的 StyleGAN2 FFHQ 模型。具体结果如下图 11 所示,可以看到,输出的图像与输入的草图匹配。

应用
研究者了探讨了将他们的方法应用于图像编辑和合成任务的几种方法,并表示:用户利用自定义模型可以更好地执行潜在空间编辑以及更好地操控自然图像。
对于潜在空间编辑来说,研究者在原始模型中应用了潜在发现方法 GANSpace。如下图 8 所示,通过沿着得出的潜在方向移动,他们发现自定义模型可以执行与 Harkonen 等人工作中完全相同的操作。

由于研究者仅调整了生成器的映射网络,他们的方法并没有改变模型处理 W 空间潜变量的方式,因此保留了潜在编辑的属性。他们还观察到,潜在插值(latent interpolation)在模型中保留了平滑性。下图 9 为利用自定义模型的差值结果:

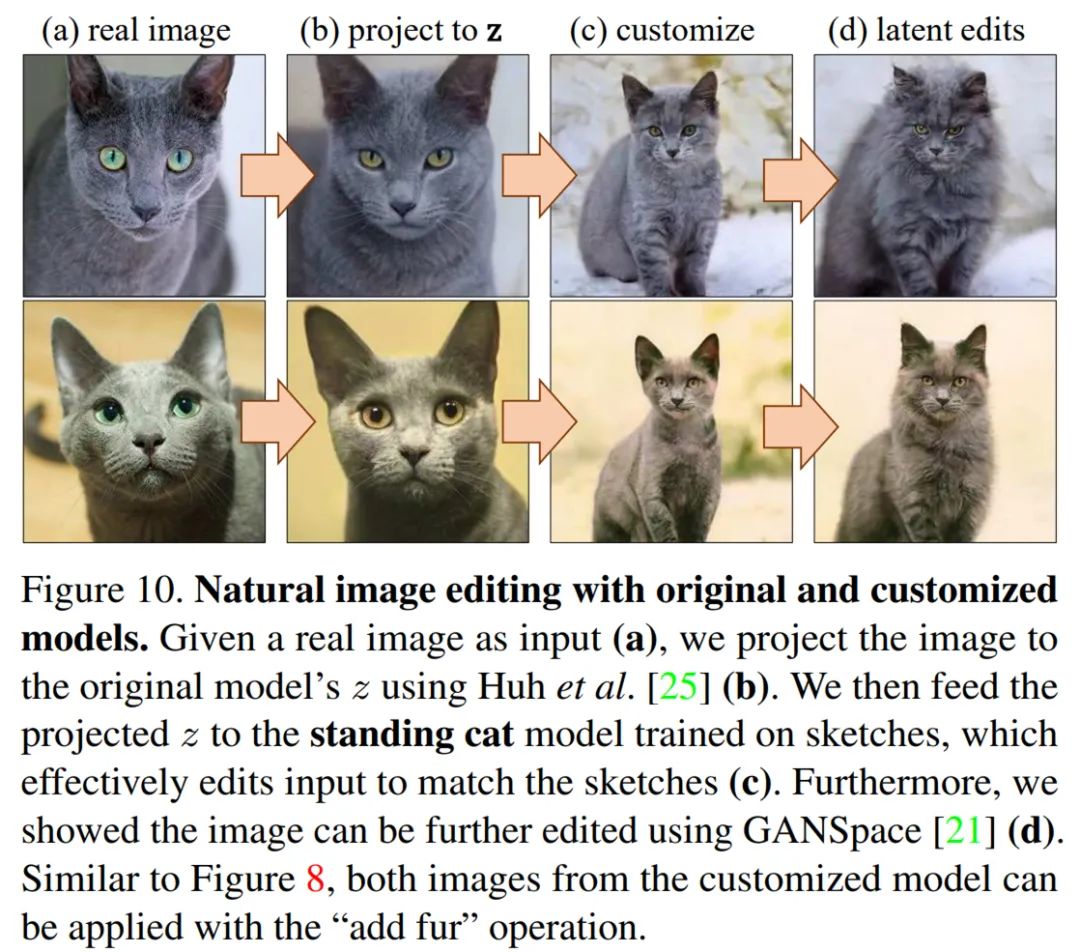
对于 自然图像编辑来说,研究者表示,自然图像编辑可以通过图像投影(image projection)来实现。下图 10 为利用原始和自定义模型进行的自然图像编辑:
不过,研究者也遇到了一些失败的示例,具体如下图 12 所示,生成的图像无法忠实地匹配草图的姿态:

推荐阅读
(点击标题可跳转阅读)
更多细节可参考论文原文,更多精彩内容请关注迈微AI研习社,每天晚上七点不见不散!

以上是关于用一张草图创建GAN模型,新手也能玩转,朱俊彦团队新研究入选ICCV 2021的主要内容,如果未能解决你的问题,请参考以下文章
朱俊彦团队最新论文:用GAN监督学习给左晃右晃的猫狗加表情,很丝滑很贴合...