YOLOF 解读You Only Look One-level Feature(CVPR 2021)
Posted AI 菌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了YOLOF 解读You Only Look One-level Feature(CVPR 2021)相关的知识,希望对你有一定的参考价值。

本文发布于CVPR2021,作者分别来自中科院、国科大、旷视。本文最大的贡献在于指出了 FPN 中 divide and conquer 策略的重要性,并因此而提出了更加简单有效的目标检测框架 YOLOF。
文章目录
一、YOLOF
作者认为 FPN(特征金字塔网络)的成功不仅来源于多尺度的特征融合,更在于“分而治之”的检测策略。基于这一观点,作者提出了简单高效的网络架构 YOLOF。
YOLOF 仅采用一级特征层进行检测,并且引入了两个关键组件:膨胀编码器和均匀匹配,带来了不错的性能提升。在COCO基准上的大量实验表明,YOLOF 比 YOLOv4 的检测速度还要快13%,且精度相当。
开源代码:https://github.com/megvii-model/YOLOF

二、FPN介绍
当前,FPN 几乎成为优秀目标检测网络的不可缺少的组成部分。FPN 的优越性主要在于两点:
- 多尺度特征融合:融合多个低分辨率和高分辨率特征输入以获得更好的表示
- 分而治之:根据尺度的不同,分别检测不同层次的目标
FPN 的一个普遍观念是,它的成功依赖于多级特征的融合,从而引发了一系列手动设计复杂融合方法的研究。然而,这种观念忽略了 FPN 中分而治之的作用。这导致关于这两个好处如何促进 FPN 成功的研究较少,进而可能阻碍新的进展。
因此,本文首先研究了 FPN 的两个好处在 one-stage 检测器中的影响。通过将多尺度特征融合和分治功能与 RetinaNet 解耦来设计实验。
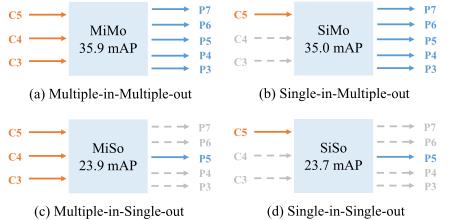
如下图所示,作者对 MiMo、SiMo、MiSo、SiSo 进行了比较,令人惊讶的是,只有一个输入特征 C5 且不进行特征融合的 SiMo 编码器可以实现与 MiMo 编码器(即 FPN)相当的性能,性能差距小于 1 mAP。相比之下,MiSo 和 SiSo 编码器的性能急剧下降(≥ 12 mAP)。
这些现象说明了两个事实:
- C5 特征带有足够的上下文来检测各种尺度的对象,这使得 SiMo 编码器能够达到可比的结果
- 多尺度特征融合的好处远不如分而治之的好处那么重要,因此多尺度特征融合可能不是FPN最显着的好处
三、相关工作
(1)多级特征检测器
使用多个特征进行目标检测是一种传统技术。构建多个特征的典型方法可以分为图像金字塔方法和特征金字塔方法。基于图像金字塔的检测器,例如 DPM,在前深度学习时代主导了检测,它的优点在于可以开箱即用,且实现更高的性能。
然而,图像金字塔方法并不是获得多个特征的唯一方法;在 CNN 模型中利用特征金字塔的力量更有效、更自然。 SSD 首先利用多尺度特征并在每个尺度上对不同尺度的对象进行对象检测。FPN 通过结合浅层特征和深层特征构建语义丰富的特征金字塔。之后,PANet 在 FPN 基础上进一步丰富了特征融合以获得更好的表示。
FPN 似乎已经成为必不可少的组件,并主导现代检测器。它也适用于流行的单级检测器,例如 RetinaNet 、FCOS 及其变体。获得特征金字塔的另一行方法是使用多分支和扩张卷积 。与上述工作不同,本文的方法是单级特征检测器。
(2)单级特征检测器
在早期,R-CNN 系列 和 R-FCN 仅在单个特征上提取 RoI 特征,而它们的性能落后于对应的多级特征检测器。此外,在 one stage 检测器中,YOLO 和 YOLOv2 仅使用主干的最后一个输出特征,它们检测速度快,但必须承受检测精度的下降。CornerNet 和 CenterNet 遵循这种方式并在使用下采样率为 4 的单个特征来检测所有对象的同时取得了有竞争力的结果。
使用高分辨率的特征图进行检测会带来巨大的内存成本,并且不利于部署。最近,DETR 引入了 Transformer 进行检测,并表明它仅使用单个 C5 特征(5倍下采样)就可以达到最先进的结果。由于anchor-free 机制和 transformer learning 阶段,DETR 需要长期的训练才得以收敛。
与这些论文不同,本文研究了多级检测器的工作机制。从优化的角度,本文为广泛使用的 FPN 提供了一种替代解决方案。此外,YOLOF 收敛速度更快并取得了可比的性能;因此,YOLOF 可以作为快速准确检测器的简单基线。
四、改进方法
作者尝试使用简单的 SiSo 编码器替换复杂的 MiMo 编码器。但是根据下图中的结果,可以发现,直接应用 SiSo 编码器时,网络的检测性能会大幅下降。

通过仔细分析,作者发现 SiSo 编码器带来的两个问题是导致性能下降的原因:
- 第一个问题是: C5 特征层的感受野匹配的尺度范围是有限的,这阻碍了对不同尺度的物体的检测性能。
- 第二个问题是:单层特征中稀疏 anchor 提出的 positive anchors 的不平衡问题。
接下来,将详细讨论这两个问题和本文提供的解决方案。
(1)膨胀编码器
如图 4(a) 所示,C5 特征的感受野只能覆盖有限的尺度范围,如果物体的尺度与感受野不匹配,则会导致性能不佳。为了实现使用 SiSo 编码器检测所有对象的目标,我们必须找到一种方法来生成具有各种感受野的输出特征,以弥补多级特征的缺失。
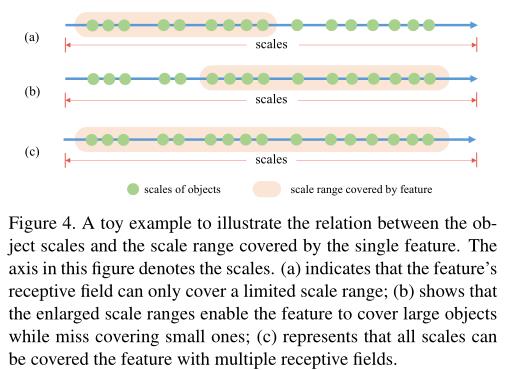
作者首先通过堆叠标准卷积和扩张卷积来扩大 C5 特征的感受野。虽然覆盖的尺度范围有所扩大,但仍然不能覆盖所有物体尺度,因为扩大过程对所有原始覆盖尺度乘以大于1的因子。我们说明了图 4(b) 中的情况,与图 4(a) 相比,整个尺度范围转移到更大的尺度。然后,我们通过添加相应的特征将原始尺度范围和扩大的尺度范围相结合,从而产生具有覆盖所有对象尺度的多个感受野的输出特征,如图 4©。通过在中间的 3×3 卷积层上构造带有膨胀的残差块,可以轻松实现上述操作。
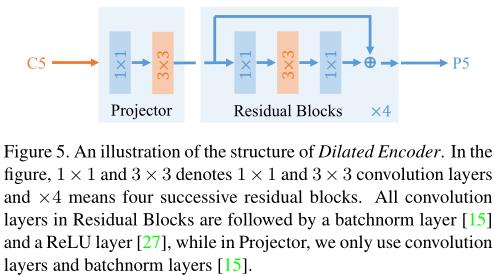
1)膨胀编码器
基于上述设计,作者提出了 SiSo 编码器,命名为 Dilated Encoder,如下图5所示。它包含两个主要组件:Projector 和 残差块。投影层首先应用一个 1×1 卷积层来降低通道维度,然后添加一个 3×3 卷积层来细化语义上下文,这与 FPN 中的相同。之后,作者在 3 × 3 卷积层中堆叠四个具有不同扩张率的连续扩张残差块,以生成具有多个感受野的输出特征,覆盖所有对象的尺度。
2)讨论
扩张卷积是一种在目标检测中扩大特征感受野的常用策略。比如,TridentNet 使用扩张卷积来生成多尺度特征。它通过多分支结构和权重共享机制来处理目标检测中的尺度变化问题,这与我们的单级特征设置不同。
并且,Dilated Encoder 将扩张的残差块一一堆叠,没有权重共享。尽管 DetNet 也相继应用了扩张的残差块,但其目的是保持特征的空间分辨率并在主干的输出中保留更多细节,而我们的目的是在主干之外生成具有多个感受野的特征。 Dilated Encoder 的设计使我们能够检测单级特征上的所有对象,而不是像 TridentNet 和 DetNet 等多级特征。
(2)均匀匹配
Positive Anchors 的定义对于目标检测中的优化问题至关重要。在基于锚的检测器中,定义 Positive Anchors 主要是通过测量锚和真实框之间的 IOU 来确定的。在 RetinaNet 中,如果锚和真实框的最大 IoU 大于阈值 0.5,则该锚将设置为正,我们称之为 Max-IoU 匹配。
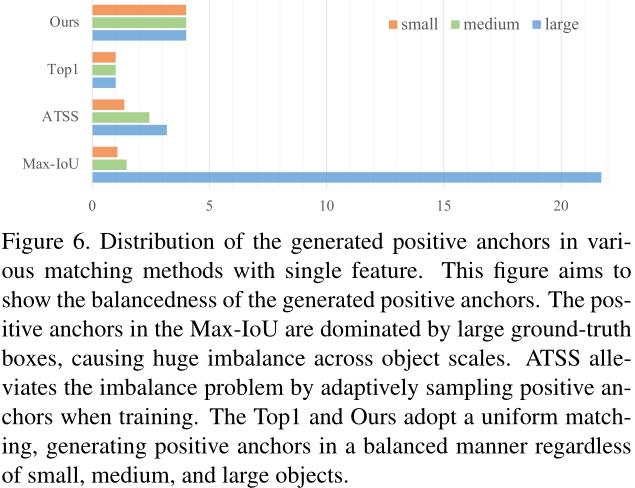
在 MiMo 编码器中,anchors 以密集铺砌的方式在多个级别上预定义,ground-truth 框在与其尺度对应的特征级别中生成 Positive Anchors。鉴于分而治之的机制,Max-IoU 匹配使每个尺度中的真实框能够生成足够数量的 Positive Anchors。然而,当我们采用 SiSo 编码器时,锚点的数量与 MiMo 编码器中的相比大幅减少,从 100k 到 5k,导致锚点稀疏。在应用 Max-IoU 匹配时,稀疏锚会引发检测器的匹配问题,如图 6 所示。自然中,大的真值框比小的真值框诱导更多的 Positive Anchors,这会导致 Positive Anchors 的不平衡问题。这种不平衡使得检测器在训练时关注大的真值框而忽略小的。
1)均匀匹配
为了解决正锚中的这种不平衡问题,我们提出了一种均匀匹配策略:采用 k 个最近的锚作为每个真值框的正锚,这确保所有真值框都可以与相同数量的正锚均匀匹配,而不管它们的大小(图 6)。正样本中的平衡确保所有真实值框都参与训练并做出同等贡献。此外,学习 Max-IoU 匹配,作者在 Uniform Matching 中设置 IoU 阈值以忽略大 IoU (>0.7) 的负锚和小 IoU (<0.15) 的正锚。
2)讨论:与其他匹配方法的关系
在匹配过程中应用 topk 并不新鲜。 ATSS 首先在 L 个特征级别上为每个地面实况框选择 topk 锚,然后通过动态 IoU 阈值在 k × L 候选中采样正锚。然而,TSS 侧重于自适应地定义正例和负例,而我们的均匀匹配侧重于在具有稀疏锚点的正样本上实现平衡。尽管之前的几种方法在正样本上实现了平衡,但它们的匹配过程并不是针对这种不平衡问题而设计的。例如,YOLO 和 YOLOv2 将地面实况框与最佳匹配单元格或锚点匹配; DETR 应用匈牙利算法进行匹配。这些匹配方法可以看作是top1匹配,这是我们统一匹配的一个特例。更重要的是,统一匹配和学习匹配方法的区别在于:学习匹配方法,如 FreeAnchor 和 PAA,根据学习状态,而统一匹配是固定的,不会随着训练而发展。统一匹配是为了解决 SiSo 设计下正锚点的特定不平衡问题而提出的
五、YOLOF 网络架构
基于以上改进方案,本文提出了一个具有单级特征的快速而直接的框架 YOLOF。本文将 YOLOF 网络架构分为三部分:主干、编码器和解码器。如下图所示:
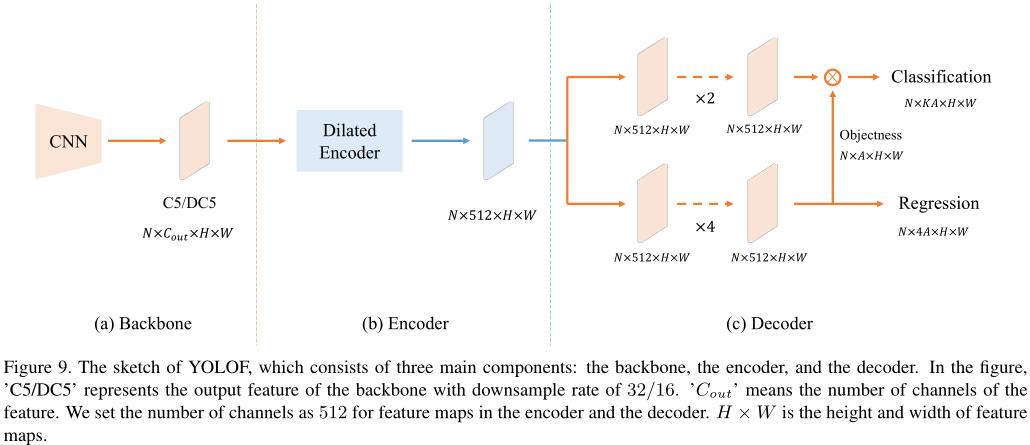
主干网络
在所有模型中,本文均采用 ResNet 和 ResNeXt 系列作为主干网络。所有模型都在 ImageNet 上进行了预训练。主干的输出是 C5 特征图,它有 2048 个通道,下采样率为 32。为了与其他检测器进行公平比较,主干中的所有BN层默认冻结。
编码器
对于编码器(图 5),首先通过在主干网络之后添加两个投影层(一个 1 × 1 和一个 3 × 3 卷积)来遵循 FPN,从而产生具有 512 个通道的特征图。然后,为了使编码器的输出特征能够覆盖各种尺度上的所有目标,我们建议添加残差块,它由三个连续的卷积组成:第一个 1 × 1 卷积应用减少率为 4 的通道减少,然后是一个 3 × 3 卷积与扩张用于扩大感受野,最后,1 × 1 卷积恢复通道数。
解码器
对于解码器,我们采用 RetinaNet 的主要设计,它由两个并行的特定任务头组成:分类头和回归头。我们只添加了两个小的修改。第一个是我们沿用了 DETR 中 FFN 的设计,让两个 head 的卷积层数不同。回归头上有四个卷积,后面是批归一化层和 ReLU 层,而分类头上只有两个。第二个是我们遵循 Autoassign 并为回归头上的每个锚点添加一个隐式对象性预测(没有直接监督)。所有预测的最终分类分数是通过将分类输出与相应的隐式对象相乘来生成的。
六、实验数据
作者在 MS COCO 基准上评估 YOLOF,并与 RetinaNet 和 DETR 进行比较,然后,提供了每个组件设计的详细消融研究以及定量结果和分析。最后,为了对单级检测的进一步研究提供见解,作者提供了错误分析并展示了 YOLOF 与 DETR 相比的弱点。
(1)实验细节
YOLOF 在 8 个 GPU 上同步使用 SGD 进行训练,每个 mini-batch 总共 64 张图像(每个 GPU 8 张图像)。所有模型都以 0.12 的初始学习率进行训练。此外,在 DETR 之后,作者为主干网络设置了一个较小的学习率,即基础学习率的 1/3。为了稳定一开始的训练,作者将预热迭代次数从 500 次扩展到 1500 次。对于训练计划,随着增加批量大小,YOLOF 中的“1×”计划设置总共为 22.5k 次迭代,并且具有基数在 15k 和 20k 迭代中,学习率降低了 10倍。其他时间表根据 Detectron2 中的原则进行调整。对于模型推理,使用阈值为 0.6 的 NMS 对结果进行后处理。对于其他超参数,遵循 RetinaNet 的设置。
(2)对比实验
与 RetinaNet 对比: 在多尺度测试的帮助下,我们获得了 47.1 mAP 的最终结果和小物体上 31.8 mAP 的竞争性能。

与 DETR 对比: YOLOF 在小物体上的表现优于 DETR,而在大物体上落后于 DETR。更重要的是,与 DETR 相比,YOLOF 收敛得更快(约7 倍),使其比 DETR 更适合作为单级检测器的简单基线。
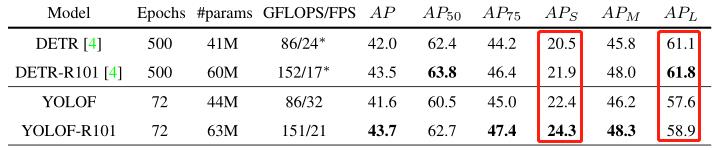
与 YOLOv4 对比: YOLOF-DC5 的运行速度比 YOLOv4 快 13%,整体性能提高了 0.8 mAP。 YOLOF-DC5 在小物体上的结果不如 YOLOv4(24.0 mAP 对 26.7 mAP),但在大物体上的表现要好得多(7.1 mAP)。

(3)消融实验
作者首先对两个提出的组件进行全面分析。然后,展示了每个组件详细设计的消融实验。
使用 ResNet-50 进行扩张编码器和均匀匹配的效果:这两个组件将原始单级检测器提高了 16.6 mAP
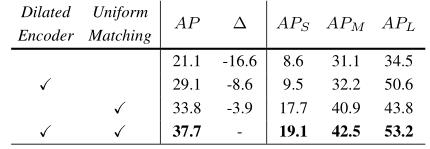
上表显示了膨胀编码器和均匀匹配都是 YOLOF 所必需的,并带来了相当大的改进。具体来说,Dilated Encoder 对大目标有显着影响(43.8 vs. 53.2),对中小对象的结果略有提升。
结果表明,有限的尺度范围是 C5 特征(第 4.1 节)中的一个严重问题。本文提出的 Dilated Encoder 为这个问题提供了一个简单但有效的解决方案。另一方面,在没有统一匹配的情况下,中小型目标的性能显着下降(%10AP),而大型对象的性能仅受到轻微影响。
更多消融实验可看下表:

七、总结
简而言之,本文主要贡献在于:
- 指出 FPN 最显着的好处是它对密集目标检测中的优化问题的分而治之的解决方案,而不是多尺度特征融合。
- 出了一个去 FPN 的简单有效的基线 YOLOF。在 YOLOF 中,提出了两个关键组件,Dilated Encoder 和 Uniform Matching,弥合了 SiSo 编码器和 MiMo 编码器之间的性能差距。
- 在 COCO 基准上进行了大量实验,表明了每个组件的重要性。此外,YOLOF 与 RetinaNet、DETR 和 YOLOv4 进行了比较,实验表明 YOLOF 可以在 GPU 上以更快的速度获得可比的结果。
以上是关于YOLOF 解读You Only Look One-level Feature(CVPR 2021)的主要内容,如果未能解决你的问题,请参考以下文章
《YOLOF:You Only Look One-level Feature》论文笔记
YOLOP 解读You Only Look Once for Panoptic Driving Perception