目标检测——标注图像(超详细步骤)
Posted 辉e
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了目标检测——标注图像(超详细步骤)相关的知识,希望对你有一定的参考价值。
1、目标
标注图像是为了生成用于训练的数据集,我们需要对采集的图像进行一系列操作,然后生成与图像同名的txt文件,txt文件中记录了目标信息包括有:类别标签、左上角横坐标、左上角纵坐标、右下角横坐标、右下角纵坐标。
举个例子,对DSC_0011_12.jpg图像进行标注,我们要生成一个DSC_0011_12.txt文件,txt文件内部为

2、标注目标框生成XML文件
标注的过程大概分为如下几步,首先是框选目标并形成XML文件,而后将XML文件转化为TXT文件。在本节将说明框选目标并形成XML文件的过程。
在本步骤中我们借助了labeIImg完成(下载地址:https://tzutalin.github.io/labelImg/),通过这个工具我们可以在图像中框出选择的目标,然后labelImg会生成如下的XML文件来记录标注的信息。

(1)建立工作区(必须)
明确本步的目标后,我们正式开始我们的框选目标过程。首先要为我们的labeIImg建立工作区,首先新建文件夹myData,然后在myData内部建立两个文件夹,分别命名为Annotations和JPEGImages,然后将我们的待标记图片放入JPEGImages,labeIImg生成的html文件会在Annotations文件夹内。

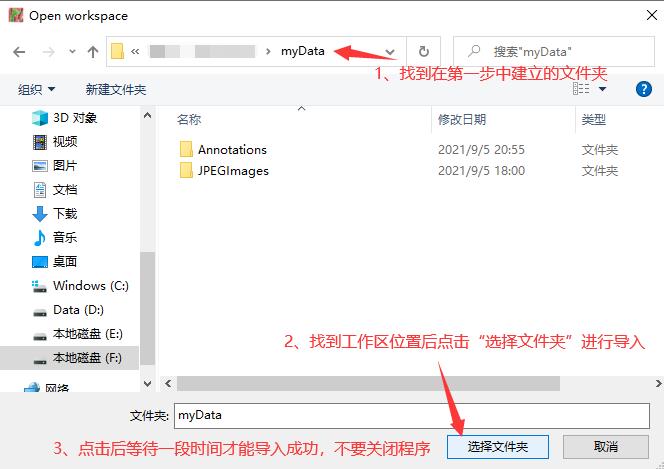
(2) 导入工作区
这一步我们直接用图片说明,打开工具labeIImg(下载地址:https://tzutalin.github.io/labelImg/)后:
step1:点击按钮

step2:找到文件夹并导入
step3:导入完成
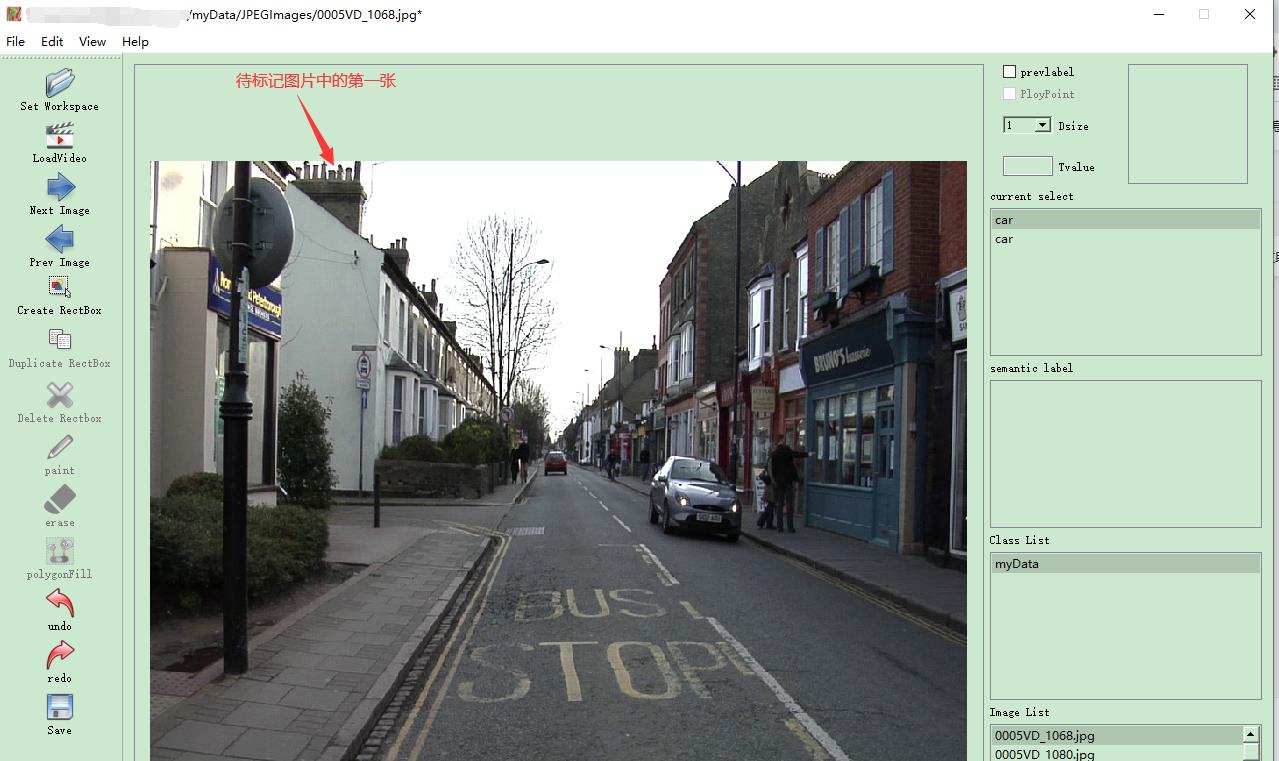
(3)在图片中进行标注
本次标注的目标是标记车辆,命名为car。
step1:点击创建目标框按钮
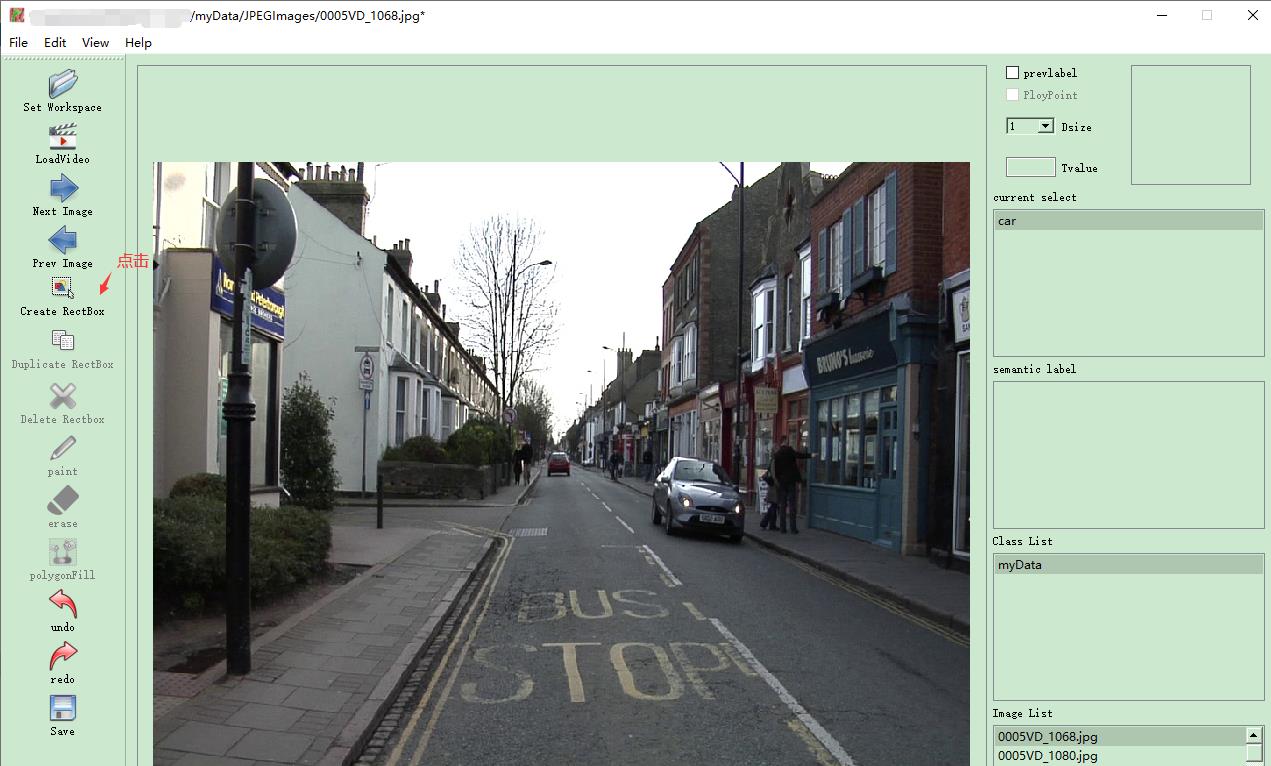
step2:画目标框
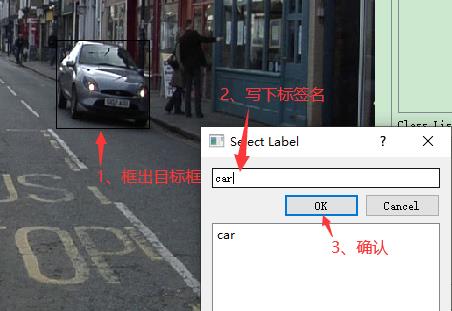
step3:保存
点击右边的按钮或者快捷键都可
step4:下一张
(4)完成
完成后在JPEGImages中的每张图片都会有一个相应的xml文件在Annotations中。
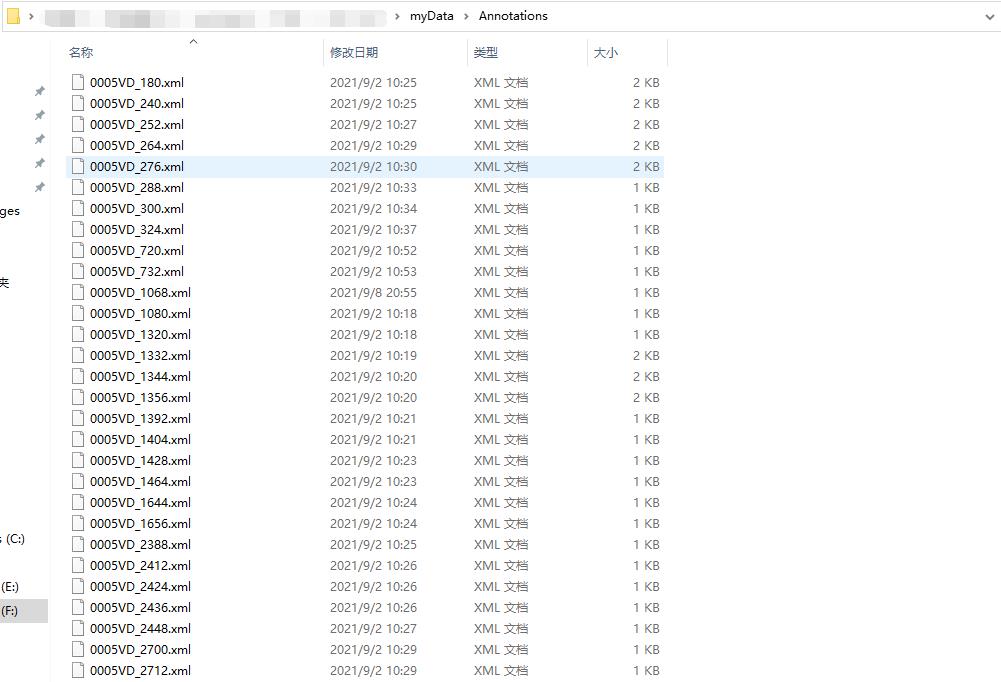
3、将XML文件转化为TXT文件
因为我们的最终需要的是生成与图像同名的txt文件,而目前是xml文件,所有在本步中要完成聪XML文件到TXT文件的转化。首先我们先统计图像的名称放在一个文件中,然后再与Annotations中保留目标框位置的信息对照生成与图像同名的txt文件,这两步各使用一个代码完成。
3.1将图像遍历输入到txt文件中
(1)建立存放目标文件的目录
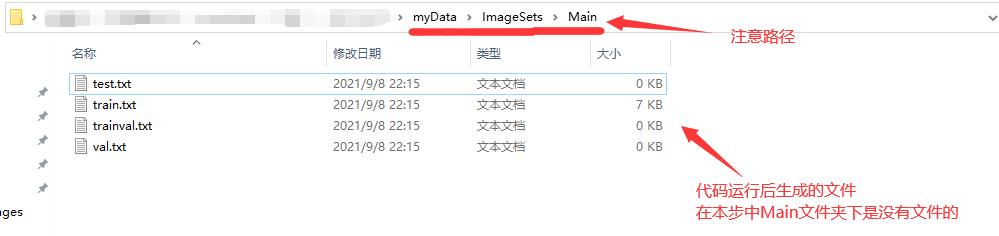
建立目标文件夹目录:在myData文件夹下建立ImageSets文件夹,在ImageSets文件夹内建立Main文件夹,本步骤生成的文件都会存放在myData\\ImageSets\\Main中,如下图:
(2)运行代码生成文件
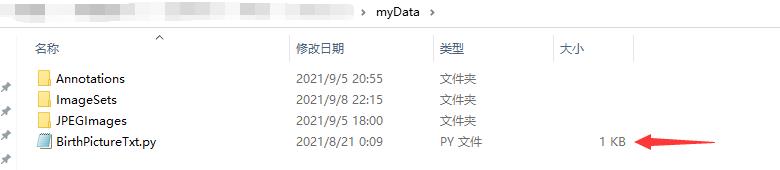
本步需要利用代码实现,我这边是命名为了BirthPictureTxt.py,存放在myData目录下:
代码为:
#代码来源:https://www.cnblogs.com/answerThe/p/11481564.html#
import os
import random
trainval_percent = 0#划分数据集
train_percent = 1#划分数据集,这边不希望划分所以一个为1,一个为0
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\\Main'#先建立目标文件夹是为了这边
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()(3)完成结果
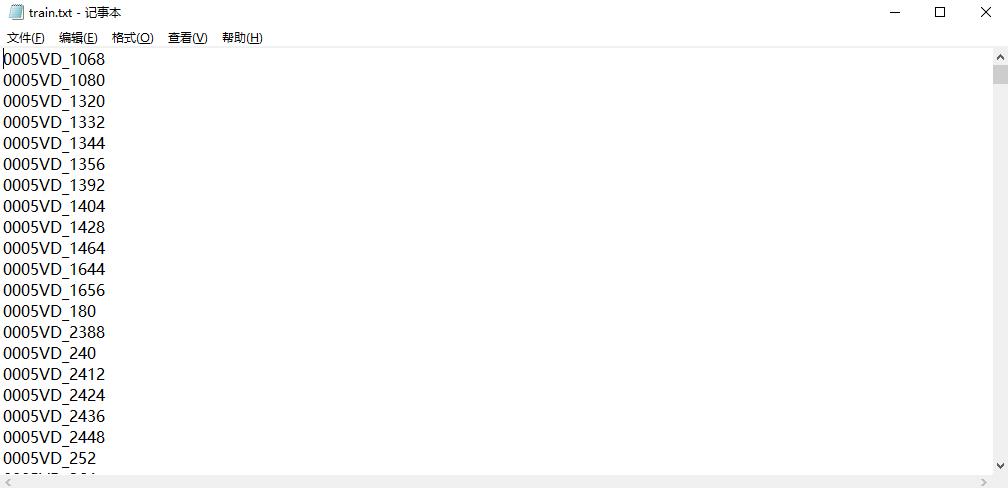
完成后,我们得到包含图像名称的txt文件train.txt(该文件存放在myData\\ImageSets\\Main中)
3.2生成与图像名对应的txt文件
这是最后一步,需要生成与图像名对应的txt文件。
(1) 运行代码
将代码放在与myData同级的目录下:

代码为:
#代码来源:https://www.cnblogs.com/answerThe/p/11481564.html#
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# 源代码sets=[('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test')]
sets = [('2021', 'train')] # 改成自己建立的myData名称,如果直接拷贝上面步骤的代码,这步不需要改变
classes = ["car"] # 改成自己的类别名称(按前后写,照应第44行)
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(year, image_id):
in_file = open('myData/Annotations/%s.xml' % (image_id)) # 源代码VOCdevkit/VOC%s/Annotations/%s.xml
out_file = open('myData/labels/%s.txt' % (image_id), 'w') # 源代码VOCdevkit/VOC%s/labels/%s.txt
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
if obj.find('difficult'):
difficult = int(obj.find('difficult').text)
else:
difficult = 0
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)#这里是指目标序号,默认是从0开始,按第10行classes里的顺序递增
#例如classes = ["car","apple"],则car序号是0,apple是1
#若想改变比如从2开始计数,这里可以+2
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('myData/labels/'): # 改成自己建立的myData
os.makedirs('myData/labels/')
image_ids = open('myData/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('myData/%s_%s.txt' % (year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/myData/JPEGImages/%s.jpg\\n' % (wd, image_id))
convert_annotation(year, image_id)
list_file.close()(2)完成结果
我们的目标文件就存在于myData/labels(自动建立)里面啦
以上是关于目标检测——标注图像(超详细步骤)的主要内容,如果未能解决你的问题,请参考以下文章