以❤️简单易懂❤️的语言带你搞懂有监督学习算法附Python代码详解机器学习系列之KNN篇
Posted 报告,今天也有好好学习
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了以❤️简单易懂❤️的语言带你搞懂有监督学习算法附Python代码详解机器学习系列之KNN篇相关的知识,希望对你有一定的参考价值。
必须要看的前言
本文风格:以❤️简单易懂❤️的语言带你彻底搞懂KNN,了解什么是有监督学习算法。
认真看完这篇文章,彻底了解KNN、了解监督学习算法绝对是一样很简单的事情。
注:本篇文章非常详细,同时我也附加了Python代码,欢迎收藏后慢慢阅读。
目录
监督学习算法
本文主要介绍的有监督学习算法是KNN,后续会接着介绍决策树、线性回归等算法。
KNN/K近邻算法
1 算法原理
首先,第一个也是最主要的问题——KNN是如何对样本进行分类的呢?
它的本质是通过距离判断两个样本是否相似,如果距离够近就认为他们足够相似属于同一类别。
当然只对比一个样本是不够的,误差会很大,我们需要找到离其最近的 k 个样本,并将这些样本称之为「近邻」(nearest neighbor)。对这 k 个近邻,查看它们的都属于何种类别(这些类别我们称作「标签」 (labels))。
然后根据“少数服从多数,一点算一票”原则进行判断,数量最多的的标签类别就是新样本的标签类别。其中涉及到的原理是“越相近越相似”,这也是KNN的基本假设。
1.1 实现过程
假设 X_test 待标记的数据样本,X_train 为已标记的数据集。
- 遍历已标记数据集中所有的样本,计算每个样本与待标记点的距离,并把距离保存在 Distance 数组中。
- 对 Distance 数组进行排序,取距离最近的 k 个点,记为 X_knn。
- 在 X_knn 中统计每个类别的个数,即 class0 在 X_knn 中有几个样本,class1 在 X_knn 中有几个样本等。
- 待标记样本的类别,就是在 X_knn 中样本个数最多的那个类别。
1.2 距离的确定
该算法的「距离」在二维坐标轴就表示两点之间的距离,计算距离的公式有很多。
我们常用欧拉公式,即“欧氏距离”。回忆一下,一个平面直角坐标系上,如何计算两点之间的距离?
应该不难会想起来吧,公式应该大致如下: d i s t a n c e ( A , B ) = ( x A − x B ) 2 + ( y A − y B ) 2 distance(A, B)=\\sqrt[]{(x_A-x_B)^2+(y_A-y_B)^2} distance(A,B)=(xA−xB)2+(yA−yB)2那如果不是在一个平面直角坐标系,而是在立体直角坐标系上,怎么计算呢? d i s t a n c e ( A , B ) = ( x A − x B ) 2 + ( y A − y B ) 2 + ( z A − z B ) 2 distance(A, B)=\\sqrt[]{(x_A-x_B)^2+(y_A-y_B)^2+(z_A-z_B)^2} distance(A,B)=(xA−xB)2+(yA−yB)2+(zA−zB)2那如果是n维空间呢? d i s t a n c e ( A , B ) = ( x 1 A − x 1 B ) 2 + ( x 2 A − x 2 B ) 2 + ( x 3 A − x 3 B ) 2 + . . . . . . + ( x n A − x n B ) 2 = ∑ i = 1 n ( x i A − x i B ) 2 distance(A, B)=\\sqrt[]{(x_{1A}-x_{1B})^2+(x_{2A}-x_{2B})^2+(x_{3A}-x_{3B})^2+......+(x_{nA}-x_{nB})^2}=\\sqrt[]{\\sum_{i=1}^{n} {(x_{iA}-x_{iB})^2}} distance(A,B)=(x1A−x1B)2+(x2A−x2B)2+(x3A−x3B)2+......+(xnA−xnB)2=i=1∑n(xiA−xiB)2而在我们的机器学习中,坐标轴上的值 x 1 x_1 x1, x 2 x_2 x2 , x 3 x_3 x3 ,…… x n x_n xn正是我们样本数据上的 n 个特征。
2 算法的优缺点
算法参数是 k,k 可以理解为标记数据周围几个数作为参考对象,参数选择需要根据数据来决定。
- k 值越大,模型的偏差越大,对噪声数据越不敏感。
- k 值很大时,可能造成模型欠拟合。
- k 值越小,模型的方差就会越大。
- 但是 k 值太小,容易过拟合。
3 算法的变种
3.1 变种一
默认情况下,在计算距离时,权重都是相同的,但实际上我们可以针对不同的邻居指定不同的距。离权重,比如距离越近权重越高。
- 这个可以通过指定算法的 weights 参数来实现。
3.2 变种二
使用一定半径内的点取代距离最近的 k 个点。
- 在 scikit-learn 中,RadiusNeighborsClassifier 实现了这种算法的变种。
- 当数据采样不均匀时,该算法变种可以取得更好的性能。
4 Python代码实现
这里我还是先以上篇文章讲到的红酒分类为例子,待会还会有其他实例。
4.1 导入模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 解决坐标轴刻度负号乱码
plt.rcParams['axes.unicode_minus'] = False
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['Simhei']
plt.style.use('ggplot')
# plt.figure(figsize=(2,3),dpi=720)
4.2 构建已经分类好的原始数据集
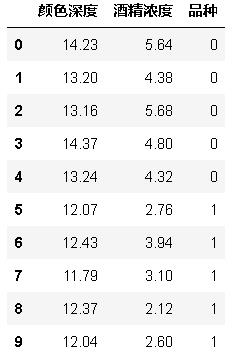
首先随机设置十个样本点表示十杯酒,这里取了部分样本点。
为了方便验证,这里使用 Python 的字典 dict 构建数据集,然后再将其转化成 DataFrame 格式。
rowdata = {'颜色深度': [14.23,13.2,13.16,14.37,13.24,12.07,12.43,11.79,12.37,12.04],
'酒精浓度': [5.64,4.38,5.68,4.80,4.32,2.76,3.94,3.1,2.12,2.6],
'品种': [0,0,0,0,0,1,1,1,1,1]}
# 0 代表 “黑皮诺”,1 代表 “赤霞珠”
wine_data = pd.DataFrame(rowdata)
wine_data
X = np.array(wine_data.iloc[:,0:2]) #我们把特征(酒的属性)放在X
y = np.array(wine_data.iloc[:,-1]) #把标签(酒的类别)放在Y
我们先来画一下图。
#探索数据,假如我们给出新数据[12.03,4.1] ,你能猜出这杯红酒是什么类别么?
new_data = np.array([12.03,4.1])
plt.scatter(X[y==1,0], X[y==1,1], color='red', label='赤霞珠') #画出标签y为1 的、关于“赤霞珠”的散点
plt.scatter(X[y==0,0], X[y==0,1], color='purple', label='黑皮诺') #画出标签y为0 的、关于“黑皮诺”的散点
plt.scatter(new_data[0],new_data[1], color='yellow') # 新数据点 new_data
plt.xlabel('酒精浓度')
plt.ylabel('颜色深度') plt.legend(loc='lower right') plt.savefig('葡萄酒样本.png')
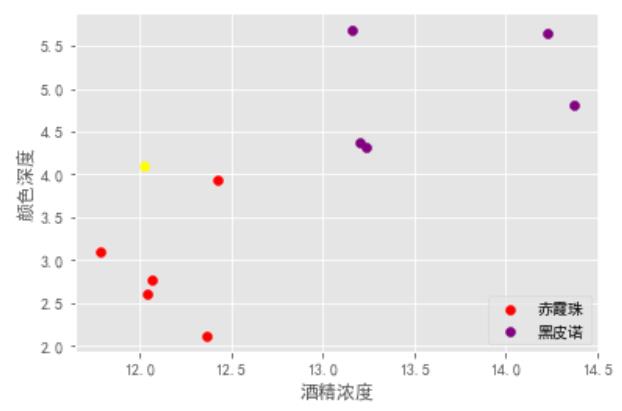
讲道理,你应该一下就能看出来了。不过,如果是计算机,会这么分辨呢?
4.3 计算已知类别数据集中的点与当前点之间的距离。
我们使用欧式距离公式,计算新数据点 new_data 与现存的 X 数据集每一个点的距离:
from math import sqrt
distance = [sqrt(np.sum((x-new_data)**2)) for x in X ]
distance

那现在,我们就已经得到黄点距离其它每个点的距离啦。
4.4 将距离升序排列,然后选取距离最小的k个点。
sort_dist = np.argsort(distance) # 这里是用到了argsort方法,可以返回数据对应的下标,如果直接用sort方法的话是返回打乱的数据,我们也不好区分对应是什么类别。
sort_dist
array([6, 7, 1, 4, 5, 9, 2, 8, 3, 0], dtype=int64)
6、7、4为最近的3个“数据点”的索引值,那么这些索引值对应的原数据的标签是什么?
k = 3
topK = [y[i] for i in sort_dist[:k]]
topK
[1,1,0]
这个时候我们就得到了离黄点最近的三个点对应的类别啦。
4.5 确定前k个点所在类别的计数。
# 在numpy中有mean、median方法可以求平均数和中位数,不过没有方法直接求众数。
pd.Series(topK).value_counts().index[0]
1
所以当我们的k取3时,分类结果为1,也就是赤霞珠。大家看一下是不是跟我们人脑分辨的结果是一样的呢?
4.6 封装成函数
那为了后续更好的操作,我们可以将上述过程封装成一个函数。
def KNN(new_data,dataSet,k):
'''
函数功能:KNN分类器
参数说明:
new_data: 需要预测分类的数据集
dataSet: 已知分类标签的数据集
k: k-近邻算法参数,选择距离最小的k个点
return:
result: 分类结果
'''
from math import sqrt
from collections import Counter
import numpy as np
import pandas as pd
result = []
distance = [sqrt(np.sum((x-new_data)**2)) for x in np.array(dataSet.iloc[:,0:2])]
sort_dist = np❤️C语言文件的操作与处理❤️----1.6W字详解,带你搞懂文件操作!!!