❤️❤️新生代农民工爆肝8万字,整理Python编程从入门到实践(建议收藏)已码:8万字❤️❤️
Posted 码上开始
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❤️❤️新生代农民工爆肝8万字,整理Python编程从入门到实践(建议收藏)已码:8万字❤️❤️相关的知识,希望对你有一定的参考价值。
人生苦短,我用Python
- 开发环境搭建
- 编码规范
- 基本语法规则
- 运算符
- 字符串
- 列表
- 字典
- 元组
- 集合
- 集合的基本操作
- 集合内置方法完整列表
- 条件语句
- 循环
- 函数
- 面向对像
- 异常处理
- 日志模块
- datatime模块
- OS文件目录操作
- os.path模块
- random随机数
- 有趣好玩的伪装者模块:Faker
- 发送邮箱件模块
- POM设计模型
- POM优势有哪些
- 为什么使用POM设计模式
- 如何设计POM
- 总结
- Python操作Excel
- file文件操作
- 安装第3方库
- Web自动化浏览器和驱动的解决办法
- Web自动化三种等待
- Python读取Text,Excel,Yaml文件
- Yaml数据完整篇
- Python结合Web电商+Mysql实战
- Python接口测试自动化(附源码)
- 分享Python自学历程

开发环境搭建
- Pycharm
- Python3
- window10/win7
安装 Python
-
打开Python官网地址
-
下载 executable installer,x86 表示是 32 位机子的,x86-64 表示 64 位机子的。
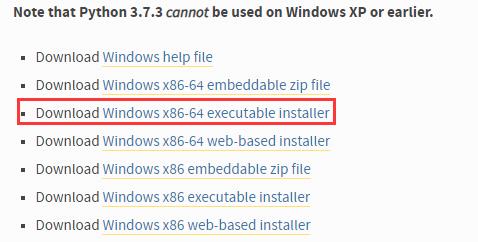
-
开始安装
- 双击下载的安装包,弹出如下界面
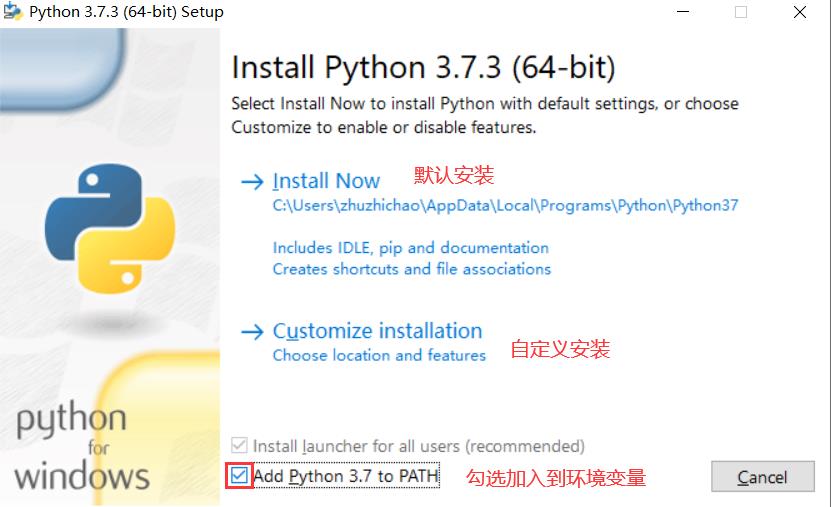
这里要注意的是:
- 将python加入到windows的环境变量中,如果忘记打勾,则需要手工加到环境变量中
- 在这里我选择的是自定义安装,点击“自定义安装”进行下一步操作
- 自定义安装
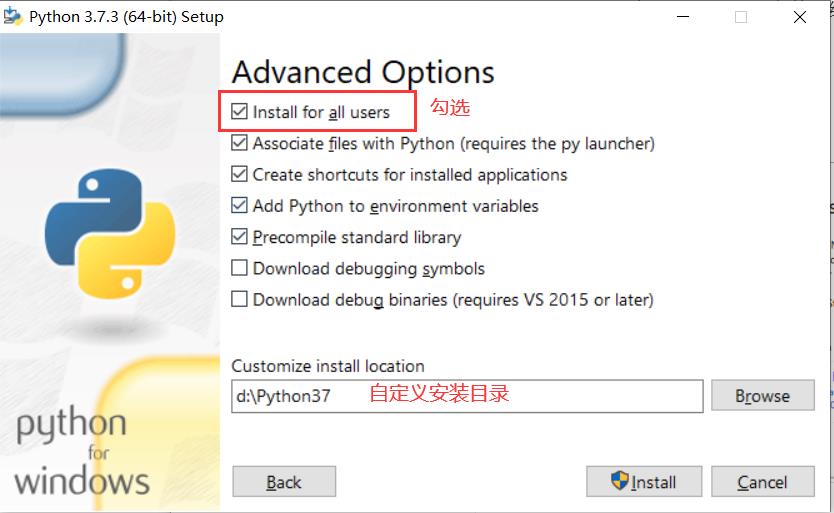
- 等待安装成功

- 双击下载的安装包,弹出如下界面
验证是否安装成功
- 按 Win+R 键,输入 cmd 调出命令提示符,输入 python:

安装Pycharm
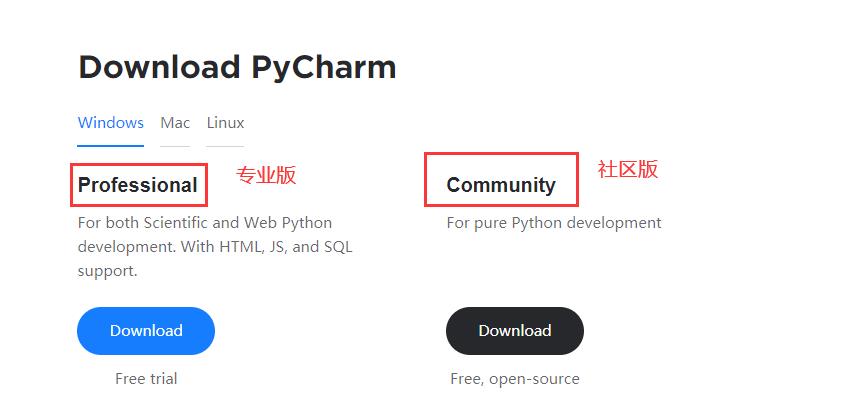
- 打开Pycharm官网下载链接
- 选择下载的版本(当前下载的是Windows下的社区版)
- 专业版收费的,当前下载的社区版免费
配置pycharm
- 外观配置(推荐使用Darcula)
- 配色方案(推荐使用Monokai)
- 代码编辑区域字体及大设置(推荐使用Consolas)
- 控制台字体选择及大小设置
- 文件模版配置
编码规范
- 类名采用驼峰命名法,即类名的每个首字母都大写,如:class HelloWord,类名不使用下划线
- 函数名只使用小写字母和下划线
- 定义类后面包含一个文档字符串且与代码空一行,字符串说明也可以用双三引号
- 顶级定义之间空两行
- 两个类之间使用两个空行来分隔
- 变量等号两边各有一个空格 a = 10
- 函数括号里的参数 = 两边不需要空格
- 函数下方需要带函数说明字符串且与代码空一行
- 默认参数要写在最后,且逗号后边空一格
- 函数与函数之间空一行
- if语句后的运算符两边需要空格
- 变量名,函数名,类名等不要使用拼音
- 注释要离开代码两个空格

基本语法规则
保留字
- 保留字即关键字,我们不能把它们用作任何标识符名称。
- Python 的标准库提供了一个 keyword 模块,可以输出当前版本的所有关键字
import keyword
keyword.kwlist
# 关键字列表
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
单行注释
Python中单行注释以 # 开头,实例如下:
# 第一个注释
print ("Hello, Python!") # 第二个注释
多行注释
多行注释可以用多个 # 号,还有’’'和 “”“xxxx”"":
# 第一个注释
# 第二个注释
'''
第三注释
第四注释
'''
"""
第五注释
第六注释
行与缩进
- python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {} 。
- 缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。实例如下:
# 正确行与缩进
if True:
print ("True")
else:
print ("False")
# 错误的行与缩进
if True:
print ("Answer")
print ("True")
else:
print ("Answer")
print ("False") # 缩进不一致,会导致运行错误
多行语句
- Python 通常是一行写完一条语句,但如果语句很长,我们可以使用反斜杠()来实现多行语句,例如:
total = item_one + \\
item_two + \\
item_three
在 [], {}, 或 () 中的多行语句,不需要使用反斜杠(),例如:
total = ['item_one', 'item_two', 'item_three',
'item_four', 'item_five']
数据类型
-
Python中数字有四种类型:整数、布尔型、浮点数和复数。
int (整数), 如 1, 只有一种整数类型 int,表示为长整型,没有 python2 中的 Long。
bool (布尔), 如 True和False
float (浮点数), 如 1.23
complex (复数), 如 1 + 2j、 1.1 + 2.2j -
查看类型,用type()方法
-
字符串
python中单引号和双引号使用完全相同
使用三引号(’’'或""")可以指定一个多行字符串
空行
def hello():
pass
# 此处为空行
def word():
pass
等待用户输入
input("请输入你的名字")
print输出
x = "a"
y = "b"
# 换行输出
print( x )
print( y )
print('---------')
# 不换行输出
print( x, end=" " )
print( y, end=" " )
print()
运算符
本章节主要说明Python的运算符。举个简单的例子 1 +2 = 3 。 例子中,1 和 1、2 被称为操作数,"+" 称为运算符。
Python语言支持以下类型的运算符:
- 算术运算符
- 比较(关系)运算符
- 赋值运算符
- 逻辑运算符
- 成员运算符
- 身份运算符
- 运算符优先级
算术运算符
以下假设变量:a=10,b=20
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加: 两个对象相加 | a + b 输出结果 30 |
| - | 减 - 得到负数或是一个数减去另一个数 | a - b 输出结果 -10 |
| * | 乘: 两个数相乘 | a * b 输出结果 200 |
| 返回一个被重复若干次的字符串,如:HI*3 | HI,HI,HI | |
| / | 除: x除以y(即两个数的商) | b / a 输出结果 2 |
| % | 取模:返商的余数 | b % a 输出结果 0 |
| ** | 幂:返回x的y次幂 | a**b 为10的20次方,输出结果100000000000000000000 |
| // | 取整除: 返回商的整数部分 | 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
注:加号也可用作连接符,但两边必须是同类型的才可以,否则会报错,如:23+ “Python” ,数字23和字符串类型不一致
比较运算符
以下假设变量a为10,变量b为20
| 运算符 | 描述 | 实例 |
|---|---|---|
| == | 等于:比较对象是否相等 | (a == b) 返回 False |
| != | 不等于:比较两个对象是否不相等 | (a != b) 返回 True |
| > | 大于:返回x是否大于y | (a > b) 返回 False |
| < | 小于:返回x是否小于y | (a < b) 返回 True。 |
| >= | 大于等于:返回x是否大于等于y | (a >= b) 返回 False |
| <= | 小于等于:返回x是否小于等于y | (a <= b) 返回 True |
注:所有比较运算符返回1表示真,返回0表示假。这分别与特殊的变量True和False等价。注意True和False第一个字母是大写
赋值运算符
以下假设变量a为10,变量b为20
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符 | c = a + b 将 a + b 的运算结果赋值为 c |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
逻辑运算符
Python语言支持逻辑运算符,以下假设变量 a 为 10, b为 20:
| 运算符 | 逻辑表达式 | 描述 | 实例 |
|---|---|---|---|
| and | x and y | 布尔"与":如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值 | (a and b) 返回 20 |
| or | x or y | 布尔"或" :如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值 | (a or b) 返回 10 |
| not | not x | 布尔"非":如果 x 为 True,返回 False 。如果 x 为 False它返回 True | not(a and b) 返回 False |
成员运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| in | 如果在指定的序列中找到值返回 True,否则返回 False | x 在 y 序列中 , 如果 x 在 y 序列中返回 True |
| not in | 如果在指定的序列中没有找到值返回 True,否则返回 False | x 不在 y 序列中 , 如果 x 不在 y 序列中返回 True |
身份运算符
身份运算符用于比较两个对象的存储单元
| 运算符 | 描述 | 实例 |
|---|---|---|
| is | is 是判断两个标识符是不是引用自一个对象 | x is y, 类似 id(x) == id(y) , 如果引用的是同一个对象则返回 True,否则返回 False |
| is not | is not 是判断两个标识符是不是引用自不同对象 | x is not y , 类似 id(a) != id(b)。如果引用的不是同一个对象则返回结果 True,否则返回 False。 |
运算符优先级
以下表格列出了从最高到最低优先级的所有运算符:
| 运算符 | 描述 |
|---|---|
| ** | 指数 (最高优先级) |
| ~ + - | 按位翻转, 一元加号和减号 (最后两个的方法名为 +@ 和 -@) |
| * / % // | 乘,商,取余和取整除 |
| + - | 加法减法 |
| >> << | 右移,左移运算符 |
| & | 位 ‘AND’ |
| ^ | | 位运算符 |
| <= < > >= | 比较运算符 |
| <> == != | 等于运算符 |
| = %= /= //= -= += *= **= | 赋值运算符 |
| is is not | 身份运算符 |
| in not in | 成员运算符 |
| not or and | 逻辑运算符 |

字符串
- 字符串是由数字,字母、下划线组成的一串字符
- 创建字符串,可以使用单引号(’’)和双引号("")
# -*- coding: utf-8 -*-
# @Author : 码上开始
var1 = 'Hello World!'
var2 = "Hello World!"
访问字符串中的值
- Python 访问子字符串,可以使用方括号 [] 来截取字符串
# -*- coding: utf-8 -*-
# @Author : 码上开始
var = “Hello World”
print(var[0])
#运行结果H
字符串更新
# -*- coding: utf-8 -*-
# @Author : 码上开始
print(var1[0:6] + “Python”)
#运行结果:Hello Python
另一种写法:
print(var1[:6] + “Python”)
#运行结果:Hello Python
合并连接字符串
- 使用+号连接字符
- +两边类型必须一致
#-*- coding: utf-8 -*-
#@Author : 码上开始
first_word = “码上”
last_word = “开始”
print(first_word + last_word)
#运行结果为:码上开始
删除空白
- ” Python”和”Python ”表面上看两个字符串是一样的,但实际代码中是认为不相同的
- 因为后面的字串符有空白,那么如何去掉空白?
# -*- coding: utf-8 -*-
# @Author : 码上开始
language = "Python "
language.rstrip() # 删除右边空格
language = " Python"
language.lstrip() # 删除左边空格
language = " Python " #
language.strip() # 删除左右空白
startswith()方法
# str传入的是字符串
str.startswith(str, beg=0,end=len(string))
-
方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False。
-
如果参数 beg 和 end 指定值,则在指定范围内检查。
# -*- coding: utf-8 -*-
# @Author : 码上开始
str = "this is string example....wow!!!"
# 默认从坐标0开始匹配this这个字符
print str.startswith( 'this' )
# 指定下标从2到4匹配is
print str.startswith( 'is', 2, 4 )
# 同上
print str.startswith( 'this', 2, 4 )
# 运行结果
True
True
False
传入的值为元组时
- 元组中只要任一元素匹配则返回True,反之为False
# -*- coding: utf-8 -*-
# @Author : 码上开始
string = "Postman"
# 元组中只要任一元素匹配则返回True,反之为False
print(string.startswith(("P", "man"),0))
# 虽然元组元素Po/man都存在字符中,但不匹配开始的下标,所以仍返回值Flase
print(string.startswith(("Po", "man"),1))
endswith()方法
# 语法
str.endswith(string,[, start[, end]])
-
Python endswith() 方法用于判断字符串是否以指定后缀结尾,如果以指定后缀结尾返回True,否则返回False。
-
可选参数"start"与"end"为检索字符串的开始与结束位置。
# -*- coding: utf-8 -*-
# @Author : 码上开始
string = "this is string example....wow!!!";
str = "wow!!!"
print(string.endswith(str))
print(string.endswith(str,20))
str1 = "is"
print(string.endswith(str1, 2, 4))
print(string.endswith(str1, 2, 6))
# 运行结果
True
True
True
False
字符串格式化
- **%格式化:**占位符%,搭配%符号一起使用
- 传整数时:%d
- 传字符串时:%s
- 传浮点数时:%f
# -*- coding: utf-8 -*-#
@Author : 码上开始
age = 29
print("my age is %d" %age)
#my age is 29
name = "makes"print("my name is %s" %name)
#my name is makes
print("%f" %2.3)#2.300000
-
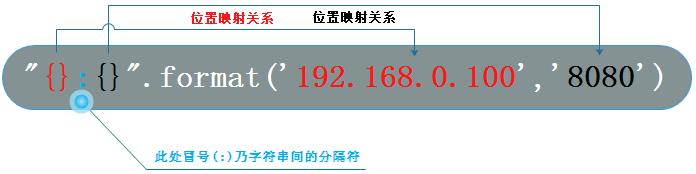
**format()格式化:**占位符{},搭配format()函数一起使用
-
位置映射
-
print("{}:{}".format('192.168.0.100',8888))#192.168.0.100:8888
-
关键字映射
-
print("{server}{1}:{0}".format(8888,'192.168.1.100',server='Web Server Info :')) #Web Server Info :192.168.1.100:8888

-
字符串运算符
下表实例变量 a 值为字符串 “Hello”,b 变量值为 “Python”:
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | a + b ‘HelloPython’ |
| * | 重复输出字符串 | a * 2 ‘HelloHello’ |
| [] | 通过索引获取字符串中字符 | a[1] ‘e’ |
| [ : ] | 截取字符串中的一部分 | a[1:4] ‘ell’ |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | “H” in a True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | “M” not in a True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | >>>print r’\\n’ \\n >>> print R’\\n’ \\n |

列表
- 列表:用于存储任意数目、任意类型的数据集合。
1.基本语法[]创建
a = [1, 'jack', True, 100]
b = []
2. list()创建
使用list()可以将任何可迭代的数据转化成列表
a = list() # 创建一个空列表
b = list(range(5)) # [0, 1, 2, 3, 4]
c = list('nice') # ['n', 'i', 'c', 'e']
3. 通过range()创建整数列表
range()
可以帮助我们非常方便的创建整数列表,这在开发中及其有用。语法格式为:`range([start,]end[,step])
start参数:可选,表示起始数字。默认是0。
end参数:必选,表示结尾数字。
step参数:可选,表示步长,默认为1。
python3中range()返回的是一个range对象,而不是列表。我们需要通过list()方法将其转换成列表对象。
a = list(range(-3, 2, 1)) # [-3, -2, -1, 0, 1]
b = list(range(2, -3, -1)) # [2, 1, 0, -1, -2]
4. 列表推导式
a = [i * 2 for i in range(5) if i % 2 == 0] # [0, 4, 8]
points = [(x, y) for x in range(0, 2) for y in range(1, 3)]
print(points) # [(0, 1), (0, 2), (1, 1), (1, 2)]
列表元素的增加
当列表增加和删除元素时,列表会自动进行内存管理,大大减少了程序员的负担。但这个特点涉及列表元素的大量移动,效率较低。除非必要,我们一般只在列表的尾部添加元素或删除元素,这会大大提高列表的操作效率。
append()
>>>a = [20,40]
>>>a.append(80)
>>>a
[20,40,80]
+运算符
并不是真正的尾部添加元素,而是创建新的列表对象;将原列表的元素和新列表的元素依次复制到新的列表对象中。这样,会涉及大量的复制操作,对于操作大量元素不建议使用。
>>> a = [3, 1, 4]
>>> b = [4, 2]
>>> a + b
[3, 1, 4, 4, 2]
extend()
将目标列表的所有元素添加到本列表的尾部,属于原地操作,不创建新的列表对象。
>>> a = [3, 2]
>>> a.extend([4, 6])
>>> a
[3, 2, 4, 6]
insert()
使用insert()方法可以将指定的元素插入到列表对象的任意指定位置。这样会让插入位置后面所有的元素进行移动,会影响处理速度。涉及大量元素时,尽量避免使用。类似发生这种移动的函数还有:remove()、pop()、del(),它们在删除非尾部元素时也会发生操作位置后面元素的移动。
>>> a = [2, 5, 8]
>>> a.insert(1, 'jack')
>>> a
[2, 'jack', 5, 8]
- 乘法
使用乘法扩展列表,生成一个新列表,新列表元素时原列表元素的多次重复。
>>> a = [4, 5]
>>> a * 3
[4, 5, 4, 5, 4, 5]
适用于乘法操作的,还有:字符串、元组。
列表元素的删除
del()
删除列表指定位置的元素。
>>> a = [2, 3, 5, 7, 8]
>>> del a[1]
>>> a
[2, 5, 7, 8]
pop()
删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个元素。
>>> a = [3, 6, 7, 8, 2]
>>> b = a.pop()
>>> b
2
>>> c = a.pop(1)
>>> c
6
remove()
删除首次出现的指定元素,若不存在该元素抛出异常。
>>> a=[10,20,30,40,50,20,30,20,30]
>>> a.remove(20)
>>> a
[10, 30, 40, 50, 20, 30, 20, 30]
clear()
清空一个列表。
a = [3, 6, 7, 8, 2]
a.clear()
print(a) # []
列表元素的访问
- 通过索引直接访问元素
>>> a = [2, 4, 6]
>>> a[1]
4
index()获得指定元素在列表中首次出现的索引
index()可以获取指定元素首次出现的索引位置。语法是:index(value,[start,[end]])。其中,start和end指定了搜索的范围。
>>> a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
>>> a.index(20)
1
>>> a.index(20, 3)
5
>>> a.index(20, 6, 8)
7
列表元素出现的次数
返回指定元素在列表中出现的次数。
>>> a = [10, 20, 30, 40, 50, 20, 30, 20, 30]
>>> a.count(20)
3
切片(slice)
[起始偏移量start:终止偏移量end[:步长step]]
-
三个量为正数的情况下
| 操作和说明 | 示例 | 结果 |
| ---------------------------------------------------- | ------------------------------------- | -------------- |
|[:]提取整个列表 |[10, 20, 30][:]|[10, 20, 30]|
|[start:]从start索引开始到结尾 |[10, 20, 30][1:]|[20, 30]|
|[:end]从头开始到 end-1 |[10, 20, 30][:2]|[10, 20]|
|[start:end]从 start 到 end-1 |[10, 20, 30, 40][1:3]|[20, 30]|
|[start:end:step]从 start 提取到 end-1,步长是step |[10, 20, 30, 40, 50, 60, 70][1:6:2]|[20, 40, 60]| -
三个量为负数的情况
| 示例 | 说明 | 结果 |
| ------------------------------------- | ---------------------- | ------------------------ |
|[10, 20, 30, 40, 50, 60, 70][-3:]| 倒数三个 |[50, 60, 70]|
|[10, 20, 30, 40, 50, 60, 70][-5:-3]| 倒数第五个至倒数第四个 |[30, 40]|
|[10,20,30,40,50,60,70][::-1]| 逆序 |[70,60,50,40,30,20,10]|
t1 = [11, 22, 33, 44, 55, 66, 77, 88, 99]
print(t1[100:]) # []
print(t1[0:-1]) # [11, 22, 33, 44, 55, 66, 77, 88]
print(t1[1:5:-1]) # []
print(t1[-1:-5:-1]) # [99, 88, 77, 66]
print(t1[-5:-1:-1]) # []
print(t1[5:-1:-1]) # []
print(t1[::-1]) # [99, 88, 77, 66, 55, 44, 33, 22, 11]
# 注意以下两个
print(t1[3::-1]) # [44, 33, 22, 11]
print(t1[3::1]) # [44, 55, 66, 77, 88, 99]
123456789101112131415161718
列表的排序
- 修改原列表,不创建新列表的排序
a = [3, 2, 8, 4, 6]
print(id(a)) # 2180873605704
a.sort() # 默认升序
print(a) # [2, 3, 4, 6, 8]
print(id(a)) # 2180873605704
a.sort(reverse=True)
print(a) # [8, 6, 4, 3, 2]
12345678
# 将序列的所有元素随机排序
import random
b = [3, 2, 8, 4, 6]
random.shuffle(b)
print(b) # [4, 3, 6, 2, 8]
12345
- 创建新列表的排序
通过内置函数sorted()进行排序,这个方法返回新列表,不对原列表做修改。
a = [3, 2, 8, 4, 6]
b = sorted(a) # 默认升序
c = sorted(a, reverse=True) # 降序
print(b) # [2, 3, 4, 6, 8]
print(c) # [8, 6, 4, 3, 2]
12345
- 冒泡排序
list1 = [34,54,6,5,65,100,4,19,50,3]
#冒泡排序,以升序为例
#外层循环:控制比较的轮数
for i in range(len(list1) - 1):
#内层循环:控制每一轮比较的次数,兼顾参与比较的下标
for j in range(len(list1) - 1 - i):
#比较:只要符合条件则交换位置,
# 如果下标小的元素 > 下标大的元素,则交换位置
if list1[j] < list1[j + 1]:
list1[j],list1[j + 1] = list1[j + 1],list1[j]
print(list1)
- 选择排序
li = [17, 4, 77, 2, 32, 56, 23]
# 外层循环:控制比较的轮数
for i in range(len(li) - 1):
# 内层循环:控制每一轮比较的次数
for j in range(i + 1, len(li)):
# 如果下标小的元素>下标大的元素,则交换位置
if li[i] > li[j]:
li[i], li[j] = li[j], li[i]
print(li)
列表元素的查找
- 顺序查找
# 顺序查找
# 1.需求:查找指定元素在列表中的位置
list1 = [5, 6, 5, 6, 24, 17, 56, 4]
key = 6
for i in range(len(list1)):
if key == list1[i]:
print("%d在列表中的位置为:%d" % (key,i))
# 2.需求:模拟系统的index功能,只需要查找元素在列表中第一次出现的下标,如果查找不到,打印not found
# 列表.index(元素),返回指定元素在列表中第一次出现的下标
list1 = [5, 6, 5, 6, 24, 17, 56, 4]
key = 10
for i in range(len(list1)):
if key == list1[i]:
print("%d在列表中的位置为:%d" % (key,i))
break
else:
print("not found")
# 3.需求:查找一个数字列表中的最大值以及对应的下标
num_list = [34, 6, 546, 5, 100, 16, 77]
max_value = num_list[0]
max_index = 0
for i in range(1, len(num_list)):
if num_list[i] > max_value:
max_value = num_list[i]
max_index = i
print("最大值%d在列表中的位置为:%d" % (max_value,max_index))
# 4.需求:查找一个数字列表中的第二大值以及对应的下标
num_list = [34, 6, 546, 5, 100, 546, 546, 16, 77]
# 备份
new_list = num_list.copy()
# 升序排序
for i in range(len(new_list) - 1):
for j in range(len(new_list) - 1 - i):
if new_list[j] > new_list[j + 1]:
new_list[j],new_list[j + 1] = new_list[j + 1],new_list[j]
print(new_list)
# 获取最大值
max_value = new_list[-1]
# 统计最大值的以上是关于❤️❤️新生代农民工爆肝8万字,整理Python编程从入门到实践(建议收藏)已码:8万字❤️❤️的主要内容,如果未能解决你的问题,请参考以下文章