NLP⚠️学不会打我! 半小时学会基本操作 3⚠️ 词袋模型
Posted 我是小白呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了NLP⚠️学不会打我! 半小时学会基本操作 3⚠️ 词袋模型相关的知识,希望对你有一定的参考价值。
概述
从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁.

词袋模型
词袋模型 (Bag of Words Model) 能帮助我们把一个句子转换为向量表示. 词袋模型把文本看作是无序的词汇集合, 把每一单词都进行统计.

向量化
词袋模型首先会进行分词, 在分词之后. 通过通过统计在每个词在文本中出现的次数. 我们就可以得到该文本基于词语的特征, 如果将各个文本样本的这些词与对应的词频放在一起, 就是我们常说的向量化.
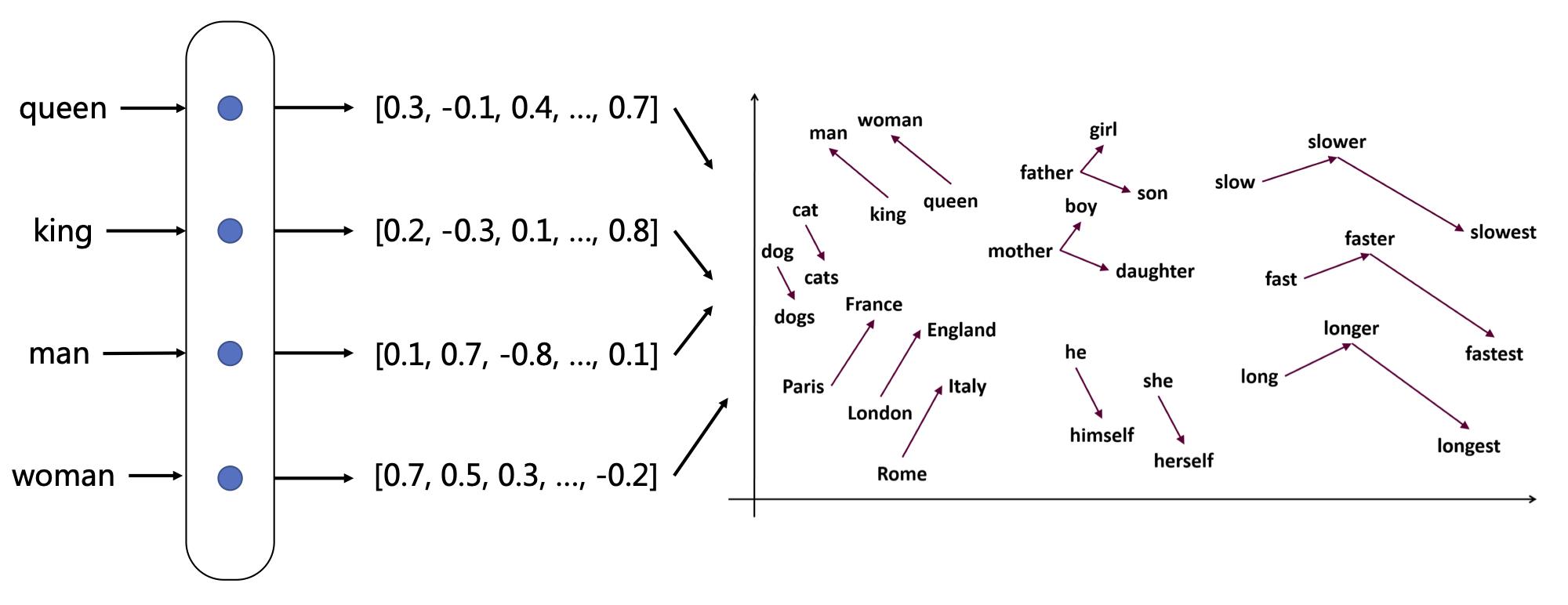
例子:
import jieba
from gensim import corpora
# 定义标点符号
punctuation = [",", "。", ":", ";", "?", "!"]
# 定义语料
content = [
"今天天气真不错!",
"明天要下雨?",
"后天要打雷。"
]
# 分词
seg = [jieba.lcut(con) for con in content]
print("语料:", seg)
# 去除标点符号
tokenized = seg.copy()
for s in tokenized:
for p in punctuation:
if p in s:
s.remove(p)
print("去除标点:", tokenized)
# tokenized是去标点之后的
dictionary = corpora.Dictionary(seg)
print("词袋模型:", dictionary)
# 保存词典
dictionary.save('deerwester.dict')
# 查看字典和下标id的映射
print("编号:", dictionary.token2id)
输出结果:
Building prefix dict from the default dictionary ...
Loading model from cache C:\\Users\\Windows\\AppData\\Local\\Temp\\jieba.cache
Loading model cost 1.140 seconds.
Prefix dict has been built successfully.
语料: [['今天天气', '真不错', '!'], ['明天', '要', '下雨', '?'], ['后天', '要', '打雷', '。']]
去除标点: [['今天天气', '真不错'], ['明天', '要', '下雨'], ['后天', '要', '打雷']]
词袋模型: Dictionary(7 unique tokens: ['今天天气', '真不错', '下雨', '明天', '要']...)
编号: {'今天天气': 0, '真不错': 1, '下雨': 2, '明天': 3, '要': 4, '后天': 5, '打雷': 6}

以上是关于NLP⚠️学不会打我! 半小时学会基本操作 3⚠️ 词袋模型的主要内容,如果未能解决你的问题,请参考以下文章
NLP⚠️学不会打我! 半小时学会基本操作 8⚠️ 新闻分类
NLP⚠️学不会打我! 半小时学会基本操作 8⚠️ 新闻分类