fake_useragent 模块的使用和网络超时报错的解决方案
Posted Jason_WangYing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了fake_useragent 模块的使用和网络超时报错的解决方案相关的知识,希望对你有一定的参考价值。
在使用 Python 做爬虫的时候,我们需要伪装头部信息骗过网站的防爬策略,Python 中的第三方模块 fake_useragent 就很好的解决了这个问题,它将给我们返回一个随机封装了好的头部信息,我们直接使用即可
fake_useragent的安装
pip install fake_useragent
fake_useragent的使用
from fake_useragent import UserAgent
# 随机生成ua,推荐使用
UA = UserAgent().random
request.headers['User-Agent']=UAfake_useragent使用过程的发生的错误
socket.timeout: timed out
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "d:\\programdata\\anaconda3\\lib\\site-packages\\fake_useragent\\utils.py", lin
e 166, in load
verify_ssl=verify_ssl,
File "d:\\programdata\\anaconda3\\lib\\site-packages\\fake_useragent\\utils.py", lin
e 122, in get_browser_versions
verify_ssl=verify_ssl,
File "d:\\programdata\\anaconda3\\lib\\site-packages\\fake_useragent\\utils.py", lin
e 84, in get
raise FakeUserAgentError('Maximum amount of retries reached')
fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached依据报错信息提示,推断是网络超时造成,从网查阅资料得知,这个库会引用在线资源,其源码 fake_useragent\\settings.py 相关配置如下所示:
# -*- coding: utf-8 -*-
from __future__ import absolute_import, unicode_literals
import os
import tempfile
__version__ = '0.1.11'
DB = os.path.join(
tempfile.gettempdir(),
'fake_useragent_{version}.json'.format(
version=__version__,
),
)
CACHE_SERVER = 'https://fake-useragent.herokuapp.com/browsers/{version}'.format(
version=__version__,
)
BROWSERS_STATS_PAGE = 'https://www.w3schools.com/browsers/default.asp'
BROWSER_BASE_PAGE = 'http://useragentstring.com/pages/useragentstring.php?name={browser}' # noqa
BROWSERS_COUNT_LIMIT = 50
REPLACEMENTS = {
' ': '',
'_': '',
}
SHORTCUTS = {
'internet explorer': 'internetexplorer',
'ie': 'internetexplorer',
'msie': 'internetexplorer',
'edge': 'internetexplorer',
'google': 'chrome',
'googlechrome': 'chrome',
'ff': 'firefox',
}
OVERRIDES = {
'Edge/IE': 'Internet Explorer',
'IE/Edge': 'Internet Explorer',
}
HTTP_TIMEOUT = 5
HTTP_RETRIES = 2
HTTP_DELAY = 0.1经过试验发现是由于其中 BROWSERS_STATS_PAGE = 'https://www.w3schools.com/browsers/default.asp' 的网址打不开导致的超时报错。
解决办法:将该文件下载到本地,放置到相应的文件夹下。
浏览器访问 https://www.w3schools.com/browsers/default.asp 网址,然后 Ctrl+S 将文件另存为 fake_useragent_0.1.11.json,注意这个名字不能变,要和源文件配置的名字一样,不然会导致无法访问。至于把保存的文件放置到那个位置,可以通过查看配置源码:
DB = os.path.join(
tempfile.gettempdir(),
'fake_useragent_{version}.json'.format(
version=__version__,
),
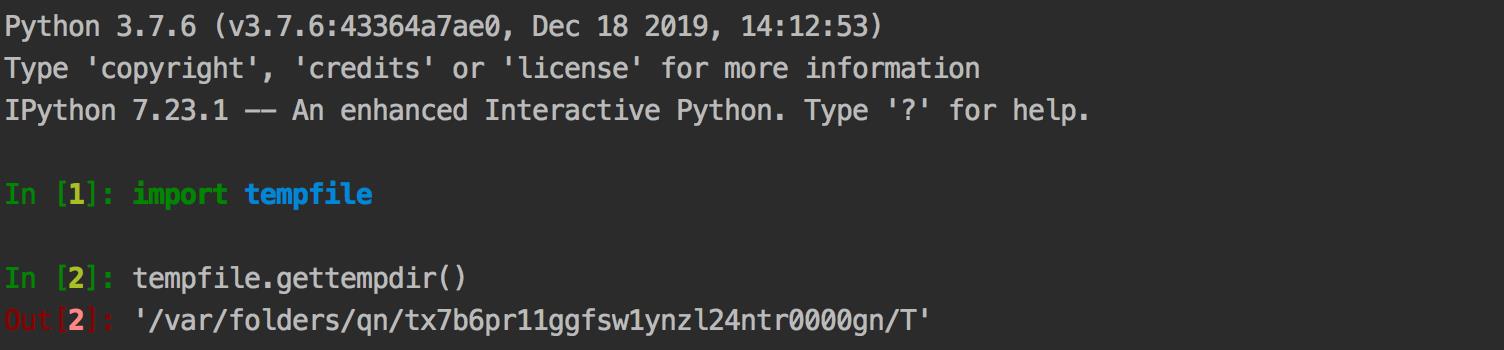
)发现,它是和 tempfile.gettempdir() 的路径拼接成DB完整路径的,因此tempfile.gettempdir() 的路径就是存放 fake_useragent_0.1.11.json 文件的路径。 如下图所示,只需要把保存的json文件放到该目录下,就可以正常访问了,在也不会出现超时的问题!
注意:如果 CACHE_SERVER 不是 https://fake-useragent.herokuapp.com/browsers/0.1.11 请更新一下库 :
pip install --upgrade fake_useragent
最终
以上是关于fake_useragent 模块的使用和网络超时报错的解决方案的主要内容,如果未能解决你的问题,请参考以下文章