python爬虫实例教程之豆瓣电影排行榜--python爬虫requests库
Posted 梦子mengy7762
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫实例教程之豆瓣电影排行榜--python爬虫requests库相关的知识,希望对你有一定的参考价值。
我们通过requests库进行了简单的网页采集和百度翻译的操作,这一节课我们继续进行案例的讲解–python爬虫实例教程之豆瓣电影排行榜,这次的案例与上节课案例相似,同样会涉及到JSON模块,异步加载以及局部加载方式等内容,接下来我们一一讲解操作方法。
1.主要获取的内容
我们主要通过豆瓣电影排行榜()
这个网站获取到影片的相关信息,如链接、片名、评分等内容(如下)

2.分析解题思路
首先我们打开我们要爬取的网址,我们会发现通过拖动鼠标滑块,电影是不断被加载出来的,并且网址不发生变化,因此我们是不是能立刻联想到上节课做的案例百度搜索有异曲同工之处–ajax异步,因此我们获取网址信息、headers、关键词等信息,不能再通过all查看,而是选择xpath查看(如下图)最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~

3.书写代码
第一步,导入requests模块

第二步,获取url、参数、headers等信息
上面我们已经分析了,该网页采用ajax异步,因此我们通过xpath获取url、参数、headers信息(如下)
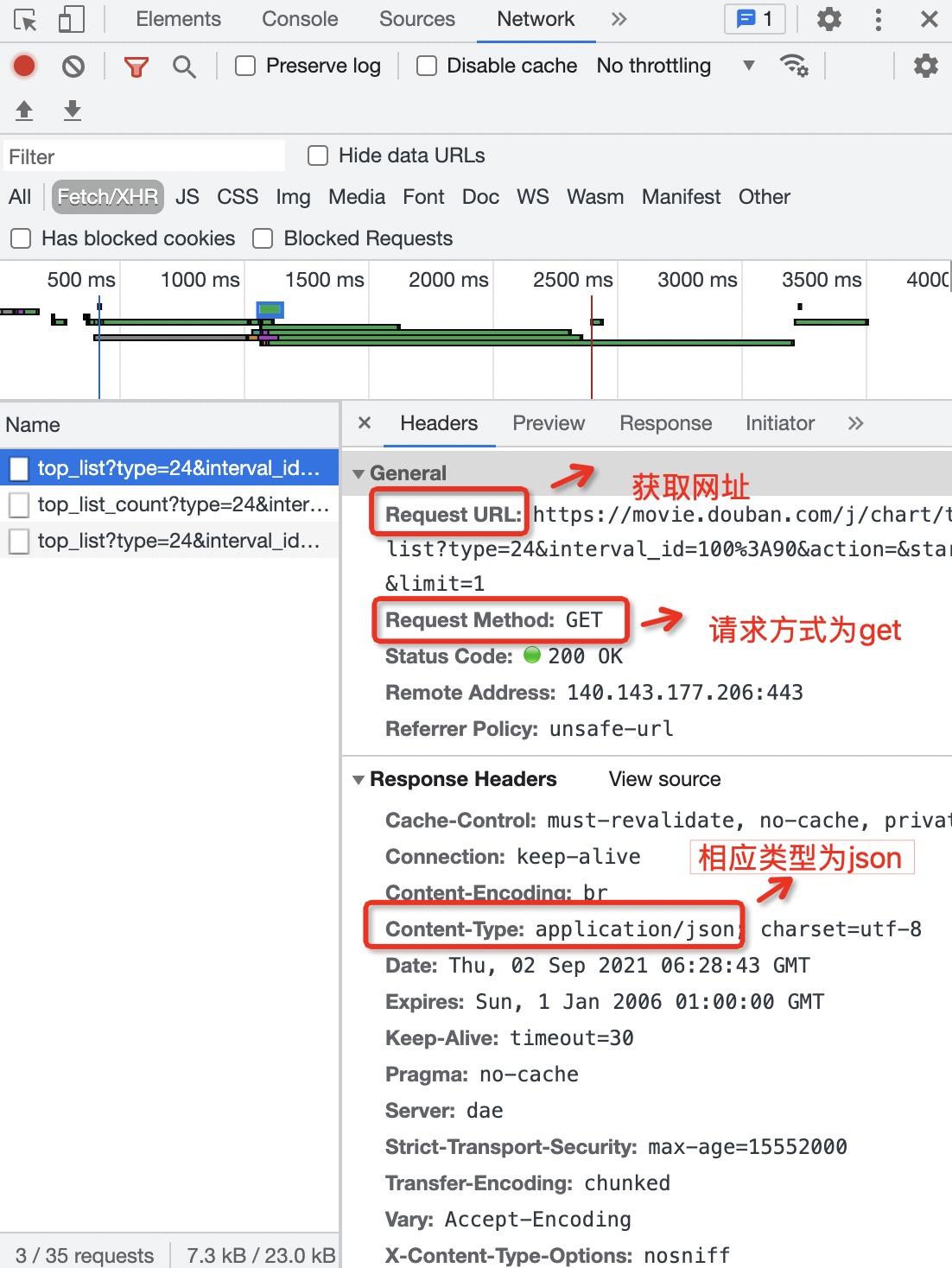

我们从上图中也了解到该网页的请求类型为get,响应类型方式为JSON,因此代码如下:最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~

需要注意的是:
(1)网址中去掉了“limit=1”因为在参数中已经包含了“limit”
(2)参数中“limit”对应的值改为了100,原因是“limit”代表着电影的篇数,我们不只想获取1部电影的信息,我们想获取100部,当然数字可根据需要更改
以上是关于python爬虫实例教程之豆瓣电影排行榜--python爬虫requests库的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫编程思想(87):项目实战--抓取豆瓣电影排行榜