Python爬虫之reuqests实现简单网页采集--网页采集教程
Posted 梦子mengy7762
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之reuqests实现简单网页采集--网页采集教程相关的知识,希望对你有一定的参考价值。
我们介绍了一种新的爬取网页的方法–reuqests,并介绍了它的使用方法,我们还介绍了urllib与reuqests的区别。这节课我们通过一个实例–reuqests实现简单网页采集来加深大家对reuqests的学习。
1.最终采集的效果
**
**
我们打开搜狗浏览器,在搜索框,输入一个词,比如”扫黑风暴“,然后将搜索结果保存下来。
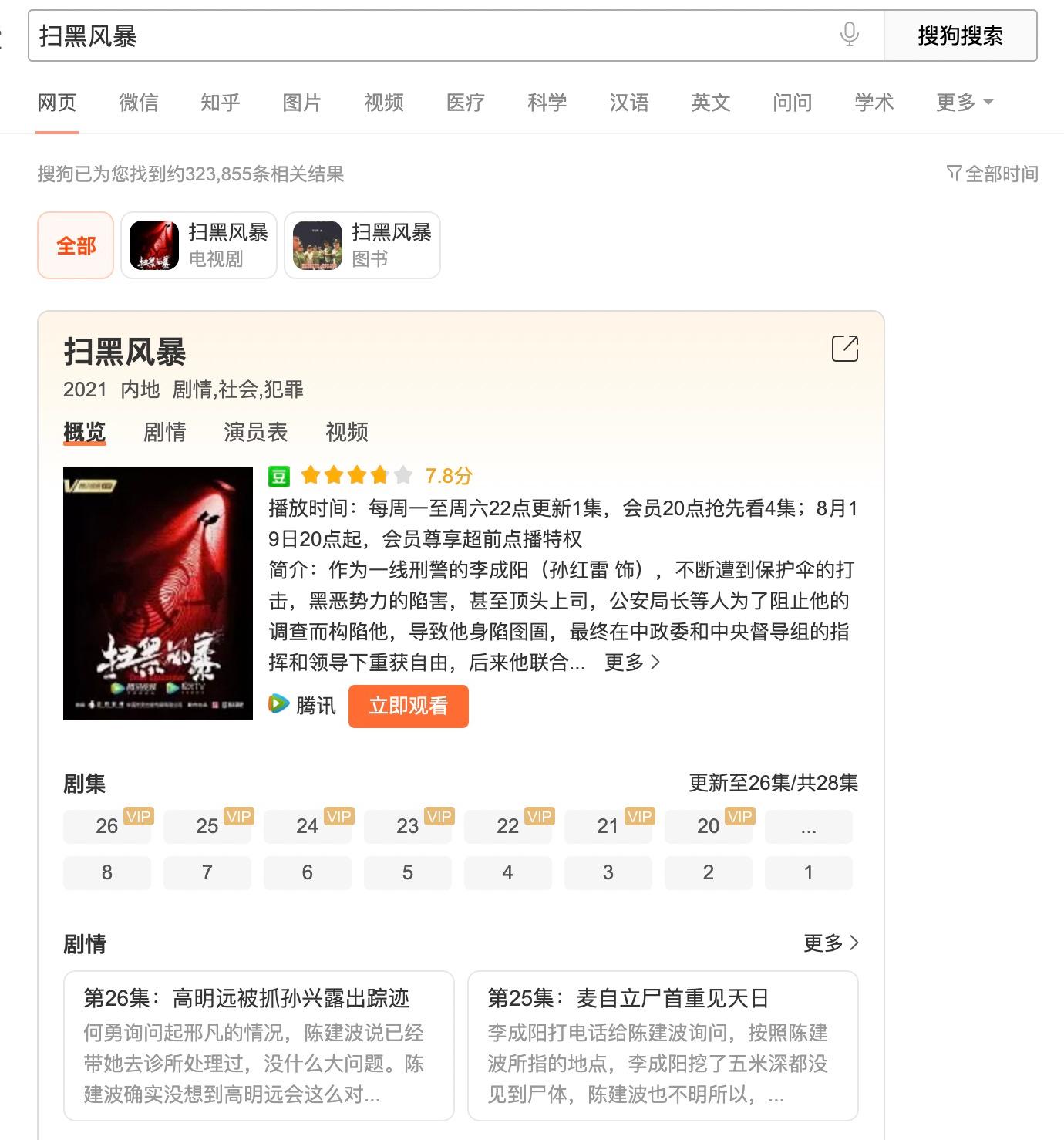
** **
2.开始进行网页采集
第一步。导入reuqests模块

第二步。分析网页类型
**
**
首先我们获取网页的地址,我们会发现网址很长,并且网址中包含我们输入的关键 词,这时我们的网址应该怎么写呢?最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~

我们只需要保留下图划痕线的部分,”query=扫黑风暴“这部分我们以关键词的形式加入到网址中:

然后我们接着分析通过检查–network–headers–Request Method可知是get类型,Content-Type:为text类型,因此我们就可以通过我们获取到的信息书写代码了!

** **
3.开始采集
以下为源代码,轻轻松松获取网页的数据(我当时写的关键词是手机,大家把相应关键词改过来即可)
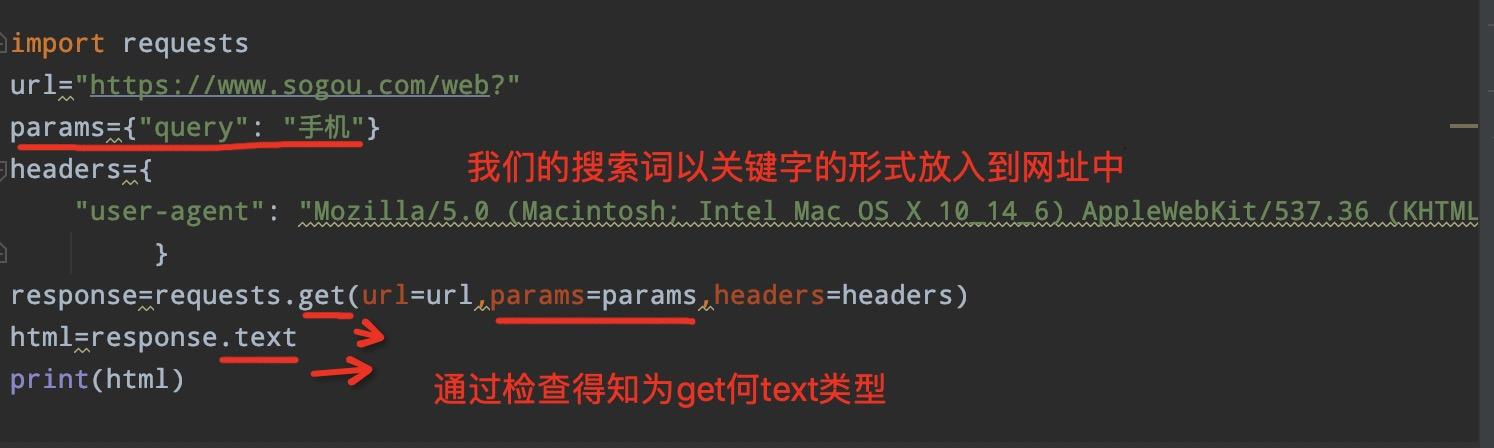
** **
4.采集的结果
**
**
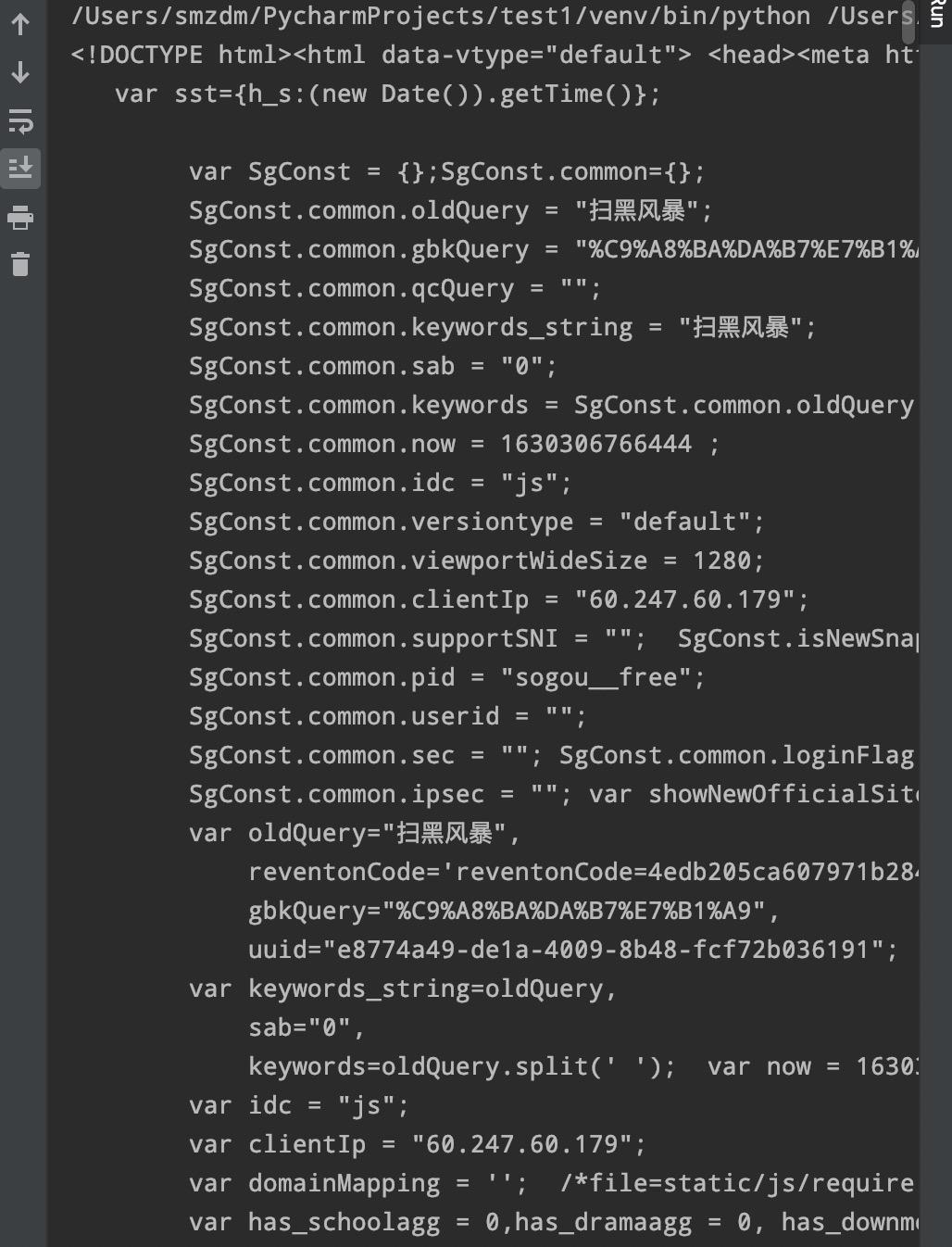
** **
5.扩展知识
我们获取的只是单个关键词的结果,假如我想要很多关键词的结果怎么办呢?我们是不是只需要把query参数对应的词变成一个变量即可呢?因此我们可以利用input模块完成自动化:最后,如果你的时间不是很紧张,并且又想快速的提高,最重要的是不怕吃苦,建议你可以联系维:762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
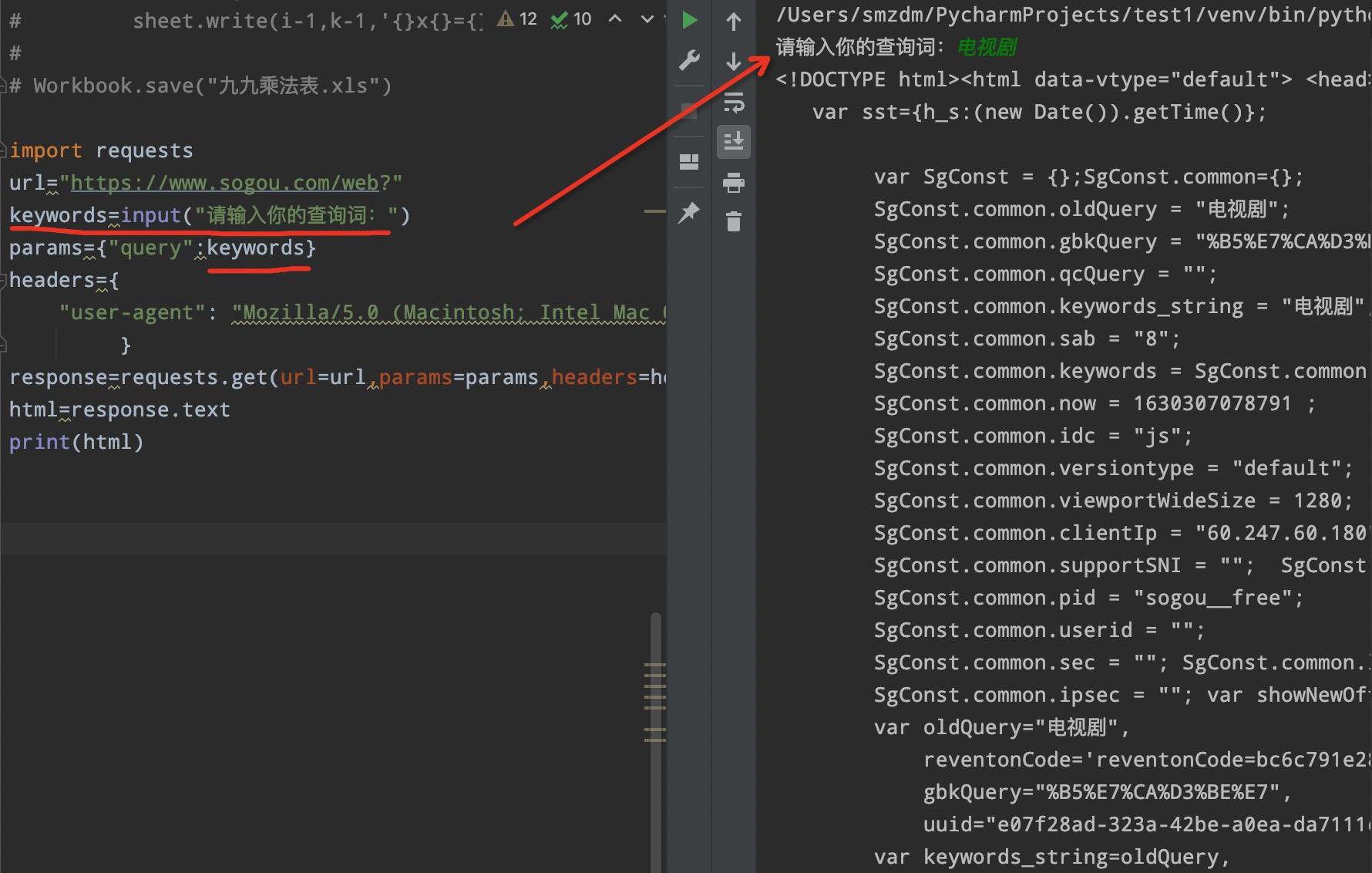
好了,这节课内容我们就先到这吧!接下来还会通过几个案例来巩固我们的requests模块
以上是关于Python爬虫之reuqests实现简单网页采集--网页采集教程的主要内容,如果未能解决你的问题,请参考以下文章