OpenCV4机器学习:K-means原理及实现
Posted AI 菌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OpenCV4机器学习:K-means原理及实现相关的知识,希望对你有一定的参考价值。
前言:
本专栏主要结合OpenCV4,来实现一些基本的图像处理操作、经典的机器学习算法(比如K-Means、KNN、SVM、决策树、贝叶斯分类器等),以及常用的深度学习算法。
系列文章,持续更新:
- OpenCV4机器学习(一):OpenCV4+VS2017环境搭建与配置
- OpenCV4机器学习(二):图像的读取、显示与存储
- OpenCV4机器学习(三):颜色空间(RGB、HSI、HSV、Lab、Gray)之间的转换
- OpenCV4机器学习(四):图像的几何变换、仿射变换
- OpenCV4机器学习(五):标注文字和矩形框
一、基本介绍
K-means,即K均值, 是一种迭代求解的聚类算法。聚类是一个将数据集中在某些方面相似的数据成员进行分类组织的过程,聚类就是一种发现这种内在结构的技术,聚类技术经常被称为无监督学习。
K 均值聚类是最著名的划分聚类算法,由于简洁和效率使得他成为所有聚类算法中最广泛使用的。给定一个数据点集合和需要的聚类数目 K,K 由用户指定,K 均值算法根据某个距离函数反复把数据分入 K 个聚类中。
二、算法原理
对于给定的数据集,通过K-means方法进行聚类的流程如下:
- 初始化K个聚类中心。
- 样本分配。将每个样本放入与其最近的类别中心所在的集合。通过设定的距离函数来判断样本距离哪个中心最近,并放入对应的样本中。距离函数一般采用:欧式距离、曼哈顿距离、闵可夫斯基距离、汉明距离。
- 更新类别中心。对分配在每个集合中样本,求样本均值,并作为当前的类别中心。
- 判断终止条件。 判断类别标签是否达到收敛精度或达到训练轮数。
三、函数解释
在 OpenCV4 中,cv::kmeans 函数实现了 K-means,该算法找到 K 个类别的中心,并对类别周围的输入样本进行分组。
cv::kmeans 函数定义如下:
double cv::kmeans(InputArray data, //样本
int K, //类别数
InputOutputArray bestLabels, //输出整数数组,用于存储每个样本的聚类类别索引
TermCriteria criteria, //算法终止条件:即最大迭代次数或所需精度
int attempts, //用于指定使用不同初始标记执行算法的次数
int flags, //初始化均值点的方法
OutputArray centers = noArray() //聚类中心的输出矩阵,每个聚类中心占一行
)
四、实战演示
下面将演示一个示例,采用 OpenCV 中的 kmeans() 方法对二维坐标点集进行聚类。
#include<iostream>
#include<opencv.hpp>
using namespace std;
using namespace cv;
int main() {
const int MAX_CLUSTERS = 5; //最大类别数
Scalar colorTab[] = { //绘图颜色
Scalar(0, 0, 255),
Scalar(0, 255, 0),
Scalar(255, 100, 100),
Scalar(255, 0, 255),
Scalar(0, 255, 255)
};
Mat img(500, 500, CV_8UC3); //新建画布
img = Scalar::all(255); //将画布设置为白色
RNG rng(35345); //随机数产生器
//初始化类别数
int clusterCount = rng.uniform(2, MAX_CLUSTERS + 1);
//在指定区间,随机生成一个整数,样本数
int sampleCount = rng.uniform(1, 1001);
//输入样本矩阵:sampleCount行x1列, 浮点型,2通道
Mat points(sampleCount, 1, CV_32FC2);
Mat labels;
//聚类类别数 < 样本数
clusterCount = MIN(clusterCount, sampleCount);
//聚类结果索引矩阵
vector<Point2f> centers;
//随机生成多高斯分布的样本
//for (int k = 0; k < clusterCount; k++) {
Point center;
center.x = rng.uniform(0, img.cols);
center.y = rng.uniform(0, img.rows);
//对样本points指定进行赋值
Mat pointChunk = points.rowRange(0, sampleCount / clusterCount);
//以center为中心,产生高斯分布的随机点,把坐标点保存在 pointChunk 中
rng.fill(pointChunk, RNG::NORMAL, Scalar(center.x, center.y), Scalar(img.cols*0.05, img.rows*0.05));
//打乱points中的值
randShuffle(points, 1, &rng);
//执行k-means
double compactness = kmeans(points, //样本
clusterCount, //类别数
labels, //输出整数数组,用于存储每个样本的聚类类别索引
TermCriteria(TermCriteria::EPS + TermCriteria::COUNT, 10, 1.0), //算法终止条件:即最大迭代次数或所需精度
3, //用于指定使用不同初始标记执行算法的次数
KMEANS_PP_CENTERS, //初始化均值点的方法
centers); //聚类中心的输出矩阵,每个聚类中心占一行
//绘制或输出聚类结果
for (int i = 0; i < sampleCount; i++) {
int clusterIdx = labels.at<int>(i);
Point ipt = points.at<Point2f>(i);
circle(img, ipt, 2, colorTab[clusterIdx], FILLED, LINE_AA);
}
//以聚类中心为圆心绘制圆形
for (int i = 0; i < (int)centers.size(); ++i) {
Point2f c = centers[i];
circle(img, c, 40, colorTab[i], 1, LINE_AA);
}
cout << "Compactness: " << compactness << endl;
imshow("clusters", img);
waitKey(0);
return 0;
}
聚类结果如下图所示:
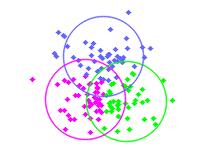
本专栏所有完整的代码将在我的GitHub仓库上更新,欢迎大家前往学习:
进入GitHub仓库,点击 star (红色箭头所示),第一时间获取干货:
最好的关系是互相成就,各位的「三连」就是【AI 菌】创作的最大动力,我们下期见!
以上是关于OpenCV4机器学习:K-means原理及实现的主要内容,如果未能解决你的问题,请参考以下文章