elasticsearch系列windows安装IK分词器插件
Posted 溪~源
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elasticsearch系列windows安装IK分词器插件相关的知识,希望对你有一定的参考价值。
环境
github下载:https://github.com/medcl/elasticsearch-analysis-ik/releases
注意,IK分词器插件要与ES版本保持一致;
有的小伙伴在GitHub上下载插件时,没有发现与ES相对应的版本,可以切换到Tags中选择分支版本;
例如Branchs列表中仅可能存在主版本号;
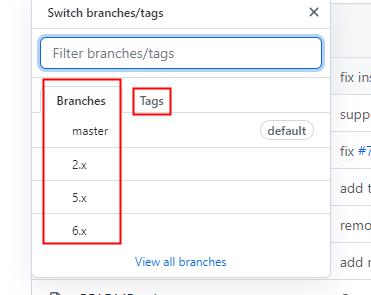
切换到右侧Tags中查找对应的版本即可;小编这里选择的7.8.0的版本;

安装IK
-
解压缩后拷贝到
ElasticSearch安装目录的plugins文件夹下,默认情况该文件夹中为空,不存在任何插件,将IK插件存入plugins目录并重命名ik,如图:
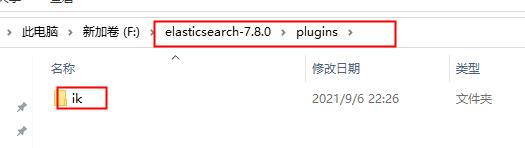
解压缩目录如下:
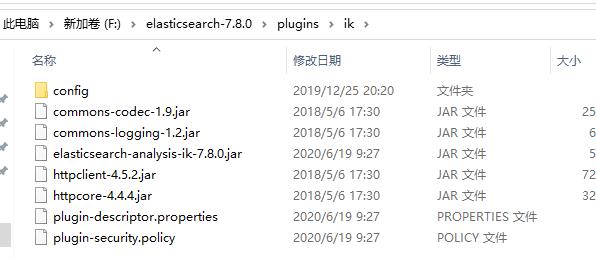
-
重启elasticsearch,观看是否加载插件

-
通过ES自带的工具查看, 命令行执行
elasticSearch-plugin list

注意,切换到bin目录下执行上面命令;
kibana实操
介绍两种分词用法和区别,主要以努力实现中国梦为例;
ik_smart
ik_smart为最少切分;
如何最少切分呢???
GET _analyze
{
"analyzer": "ik_smart",
"text": "努力实现中国梦"
}
分词结果:
{
"tokens" : [
{
"token" : "努力实现",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中国",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "梦",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 2
}
]
}
ik_max_word
ik_max_word为最细粒度划分;
GET _analyze
{
"analyzer": "ik_max_word",
"text": "努力实现中国梦"
}
分词结果:
{
"tokens" : [
{
"token" : "努力实现",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "努力",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "实现",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "梦",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 4
}
]
}
自定义分词格式
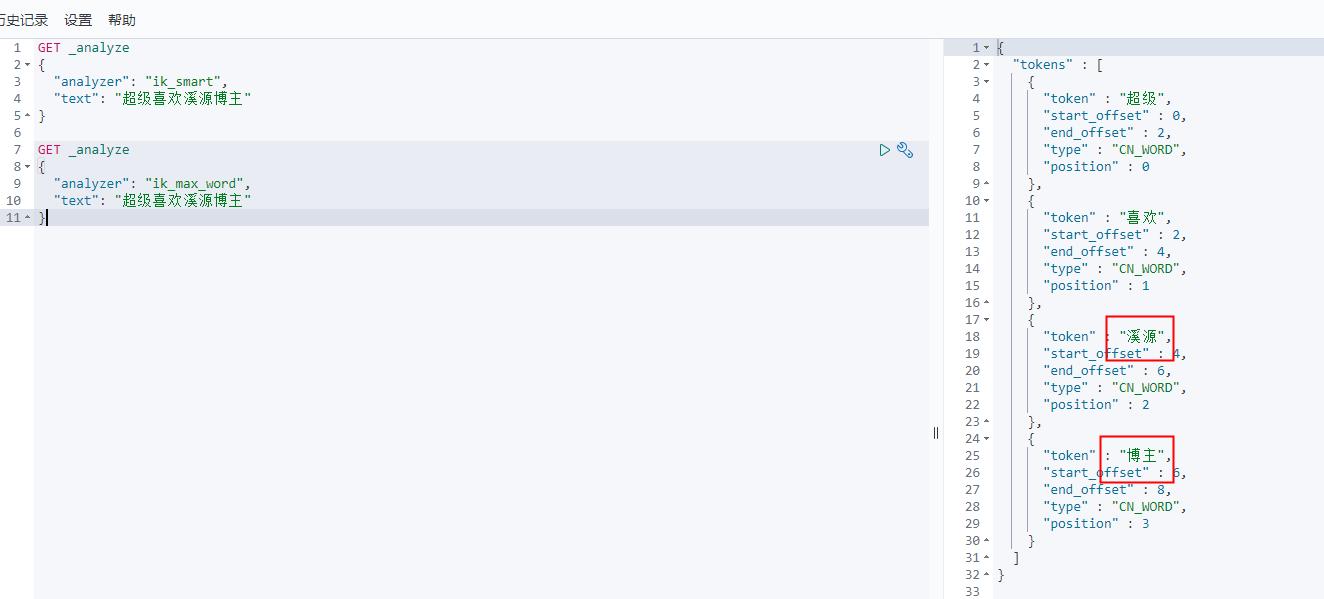
比如:超级喜欢溪源博主,用上面两种分词,会把溪源,博主分别作为单个词分开,结果如下:

需求想把溪源,博主作为两个词,因此需要我们自定义字典;
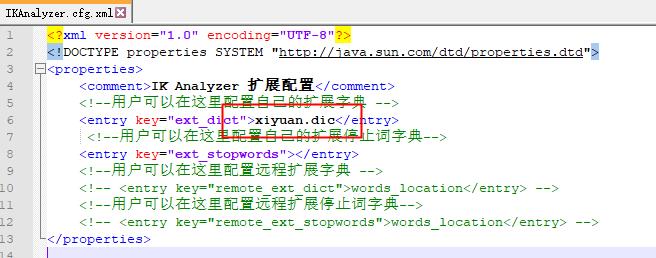
- 修改插件配置文件
ik/config/IKAnalyzer.cfg.xml,加入自定义字典;
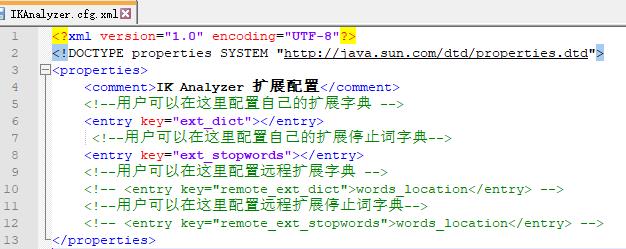
打开配置文件夹目录,可以看到已经存在的默认词库,如下:
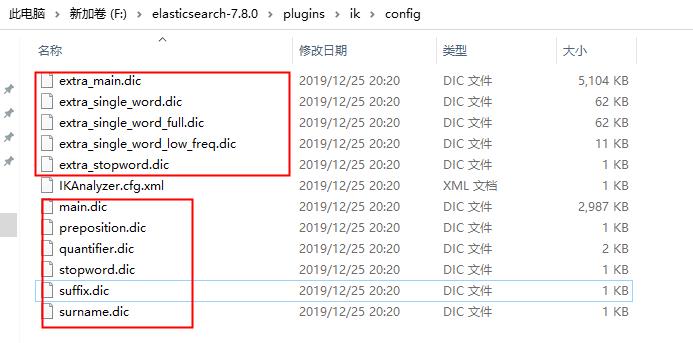
- 自定义
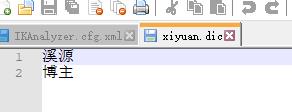
xiyuan.dic文件
将溪源、博主作为词存入文件中;
加入扩展自定义文件,如下:
- 重启ES服务和kibana
GET _analyze
{
"analyzer": "ik_smart",
"text": "超级喜欢溪源博主"
}
分词结果:
{
"tokens" : [
{
"token" : "超级",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "喜欢",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "溪源",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "博主",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 3
}
]
}
以上是关于elasticsearch系列windows安装IK分词器插件的主要内容,如果未能解决你的问题,请参考以下文章