狂肝两万字带你用pytorch搞深度学习!!!
Posted CC-Mac
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了狂肝两万字带你用pytorch搞深度学习!!!相关的知识,希望对你有一定的参考价值。
深度学习
基础知识和各种网络结构实战 ...狂肝两万字带你用pytorch搞深度学习!!!
- 深度学习
- 前言
- 一、基本数据:Tensor
- 二、Tensor的运算
- 三、神经网络工具箱torch.nn
- 四、torch实现一个完整的神经网络
- 五、搭建神经网络实现手写数据集
- 5.1 torchvision
- 5.1.1 torchvision.datasets
- 5.1.2 torchvision.models
- 5.1.3 torch.transforms
- 5.1.3.1 torchvision.transforms.Resize
- 5.1.3.2 torchvision.transforms.Scale
- 5.1.3.3 torchvision.transforms.CenterCrop
- 5.1.3.4 torchvision.transforms.RandomCrop
- 5.1.3.5 torchvision.transforms.RandomHorizontalFlip
- 5.1.3.6 torchvision.transforms.RandomVerticalFlip
- 5.1.3.7 torchvision.transforms.ToTensor
- 5.1.3.8 torchvision.transforms.ToPILImage:
- 5.1.4 torch.utils
- 5.2 模型搭建和参数优化
- 5.3 参数优化
- 5.4 模型验证
- 5.5 完整代码
- 六、结语
前言
学习深度学习一个好的框架十分的重要,现在主流的就是Pytorch和tf,今天让我们一起来学习pytorch
一、基本数据:Tensor
Tensor,即张量,是PyTorch中的基本操作对象,可以看做是包含单一数据类型元素的多维矩阵。从使用角度来看,Tensor与NumPy的ndarrays非常类似,相互之间也可以自由转换,只不过Tensor还支持GPU的加速。
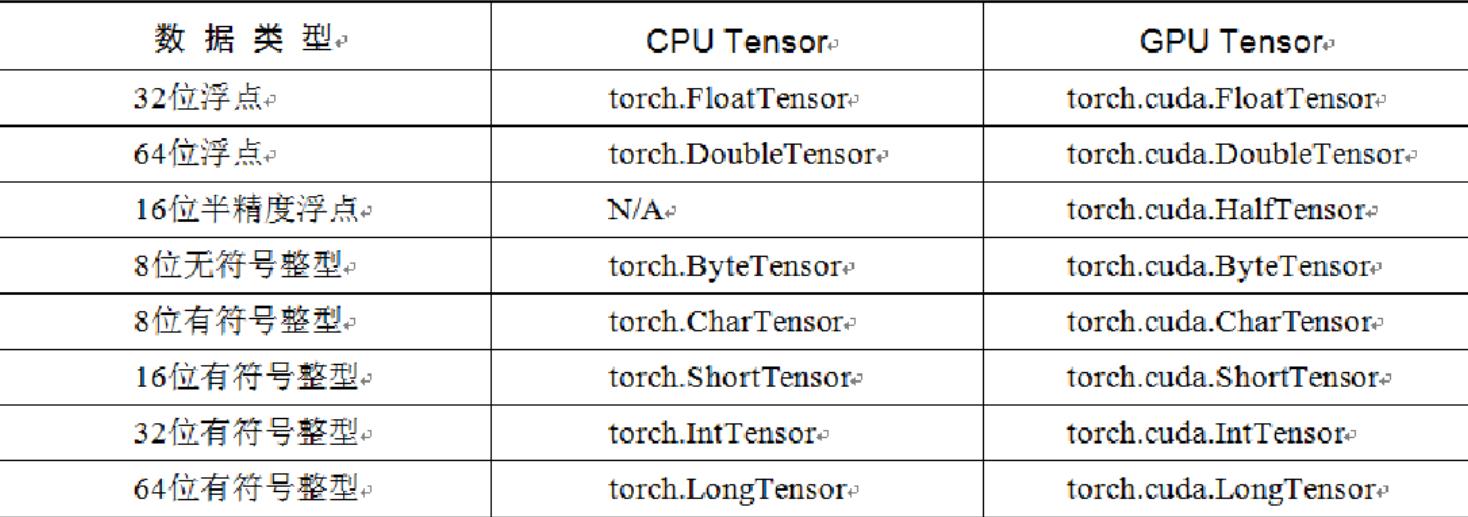
1.1 Tensor的创建

1.2 torch.FloatTensor
torch.FloatTensor用于生成数据类型为浮点型的Tensor,传递给torch.FloatTensor的参数可以是列表,也可以是一个维度值。
import torch
a = torch.FloatTensor(2,3)
b = torch.FloatTensor([2,3,4,5])
a,b
得到的结果是:
(tensor([[1.0561e-38, 1.0102e-38, 9.6429e-39],
[8.4490e-39, 9.6429e-39, 9.1837e-39]]),
tensor([2., 3., 4., 5.]))
1.3 torch.IntTensor
torch.IntTensor用于生成数据类型为整型的Tensor,传递给传递给torch.IntTensor的参数可以是列表,也可以是一个维度值。
import torch
a = torch.FloatTensor(2,3)
b = torch.FloatTensor([2,3,4,5])
a,b
import torch
a = torch.rand(2,3)
a
得到:
tensor([[0.5625, 0.5815, 0.8221],
[0.3589, 0.4180, 0.2158]])
1.4 torch.randn
用于生成数据类型为浮点数且维度指定的随机Tensor,和在numpy中使用的numpy.randn生成的随机数的方法类似,随机生成的浮点数的取值满足均值为0,方差为1的正态分布。
import torch
a = torch.randn(2,3)
a
得到:
tensor([[-0.0067, -0.0707, -0.6682],
[ 0.8141, 1.1436, 0.5963]])
1.5 torch.range
torch.range用于生成数据类型为浮点型且起始范围和结束范围的Tensor,所以传递给torch.range的参数有三个,分别为起始值,结束值,步长,其中步长用于指定从起始值到结束值得每步的数据间隔。
import torch
a = torch.range(1,20,2)
a
得到:
tensor([ 1., 3., 5., 7., 9., 11., 13., 15., 17., 19.])
1.6 torch.zeros/ones/empty
torch.zeros用于生成数据类型为浮点型且维度指定的Tensor,不过这个浮点型的Tensor中的元素值全部为0。
torch.ones生成全1的数组。
torch.empty创建一个未被初始化数值的tensor,tensor的大小是由size确定,size: 定义tensor的shape ,这里可以是一个list 也可以是一个tuple
import torch
a = torch.zeros(2,3)
a
得到:
tensor([[0., 0., 0.],
[0., 0., 0.]])
二、Tensor的运算
2.1 torch.abs
将参数传递到torch.abs后返回输入参数的绝对值作为输出,输入参数必须是一个Tensor数据类型的变量,如:
import torch
a = torch.randn(2,3)
a
得到的a是:
tensor([[ 0.0948, 0.0530, -0.0986],
[ 1.8926, -2.0569, 1.6617]])
对a进行abs处理:
b = torch.abs(a)
b
得到:
tensor([[0.0948, 0.0530, 0.0986],
[1.8926, 2.0569, 1.6617]])
2.2 torch.add
将参数传递到torch.add后返回输入参数的求和结果作为输出,输入参数既可以全部是Tensor数据类型的变量,也可以一个是Tensor数据类型的变量,另一个是标量。
import torch
a = torch.randn(2,3)
a
#tensor([[-0.1146, -0.3282, -0.2517],
# [-0.2474, 0.8323, -0.9292]])
b = torch.randn(2,3)
b
#tensor([[ 0.9526, 1.5841, -3.2665],
# [-0.4831, 0.9259, -0.5054]])
c = torch.add(a,b)
c
输出的c:
tensor([[ 0.8379, 1.2559, -3.5182],
[-0.7305, 1.7582, -1.4346]])
再看一个:
d = torch.randn(2,3)
d
#这里我们得到的d:
#tensor([[ 0.1473, 0.7631, -0.1953],
# [-0.2796, -0.7265, 0.7142]])
我们对d与一个标量10相加:
e = torch.add(d,10)
e
得到:
tensor([[10.1473, 10.7631, 9.8047],
[ 9.7204, 9.2735, 10.7142]])
2.3 torch.clamp
torch.clamp是对输入参数按照自定义的范围进行裁剪,最后将参数裁剪的结果作为输出,所以输入参数一共有三个,分别是需要进行裁剪的Tensor数据类型的变量、裁剪的上上边界和裁剪的下边界,具体的裁剪过程是:使用变量中的每个元素分别和裁剪的上边界及裁剪的下边界的值进行比较,如果元素的值小于裁剪的下边界的值,该元素被重写成裁剪的下边界的值;同理,如果元素的值大于裁剪的上边界的值,该元素就被重写成裁剪的上边界的值。我们直接看例子:
a = torch.randn(2,3)
a
#我们得到a为:
#tensor([[-1.4049, 1.0336, 1.2820],
# [ 0.7610, -1.7475, 0.2414]])
我们对b进行clamp操作:
b = torch.clamp(a,-0.1,0.1)
b
#我们得到b为:
#tensor([[-0.1000, 0.1000, 0.1000],
# [ 0.1000, -0.1000, 0.1000]])
2.4 torch.div
torch.div是将参数传递到torch.div后返回输入参数的求商结果作为输出,同样,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。具体我们看例子
a = torch.randn(2,3)
a
#我们得到a为:
#tensor([[ 0.6276, 0.6397, -0.0762],
# [-0.4193, -0.5528, 1.5192]])
b = torch.randn(2,3)
b
#我们得到b为:
#tensor([[ 0.9219, 0.2120, 0.1155],
# [ 1.1086, -1.1442, 0.2999]])
对a,b进行div操作
c = torch.div(a,b)
c
#得到c:
#tensor([[ 0.6808, 3.0173, -0.6602],
# [-0.3782, 0.4831, 5.0657]])
2.5 torch.pow
torch.pow:将参数传递到torch.pow后返回输入参数的求幂结果作为输出,参与运算的参数可以全部是Tensor数据类型的变量,也可以是Tensor数据类型的变量和标量的组合。
a = torch.randn(2,3)
a
#我们得到a为:
#tensor([[ 0.3896, -0.1475, 0.1104],
# [-0.6908, -0.0472, -1.5310]])
对a进行平方操作
b = torch.pow(a,2)
b
#我们得到b为:
#tensor([[1.5181e-01, 2.1767e-02, 1.2196e-02],
# [4.7722e-01, 2.2276e-03, 2.3441e+00]])
2.6 torch.mm
torch.mm:将参数传递到torch.mm后返回输入参数的求积结果作为输出,不过这个求积的方式和之前的torch.mul运算方式不太一样,torch.mm运用矩阵之间的乘法规则进行计算,所以被传入的参数会被当作矩阵进行处理,参数的维度自然也要满足矩阵乘法的前提条件,即前一个矩阵的行数必须和后一个矩阵列数相等
下面我们看实例:
a = torch.randn(2,3)
a
#我们得到a为:
#tensor([[ 0.1057, 0.0104, -0.1547],
# [ 0.5010, -0.0735, 0.4067]])
b = torch.randn(2,3)
b
#我们得到b为:
#tensor([[ 1.1971, -1.4010, 1.1277],
# [-0.3076, 0.9171, 1.9135]])
然后我们用产生的a,b进行矩阵乘法操作:
c = torch.mm(a,b.T)
c
#tensor([[-0.0625, -0.3190],
# [ 1.1613, 0.5567]])
2.7 torch.mv
将参数传递到torch.mv后返回输入参数的求积结果作为输出,torch.mv运用矩阵与向量之间的乘法规则进行计算,被传入的第1个参数代表矩阵,第2个参数代表向量,循序不能颠倒。
下面我们看实例:
a = torch.randn(2,3)
a
#我们得到a为:
#tensor([[ 1.0909, -1.1679, 0.3161],
# [-0.8952, -2.1351, -0.9667]])
b = torch.randn(3)
b
#我们得到b为:
#tensor([-1.4689, 1.6197, 0.7209])
然后我们用产生的a,b进行矩阵乘法操作:
c = torch.mv(a,b)
c
#tensor([-3.2663, -2.8402])
三、神经网络工具箱torch.nn
torch.autograd库虽然实现了自动求导与梯度反向传播,但如果我们要完成一个模型的训练,仍需要手写参数的自动更新、训练过程的控制等,还是不够便利。为此,PyTorch进一步提供了集成度更高的模块化接口torch.nn,该接口构建于Autograd之上,提供了网络模组、优化器和初始化策略等一系列功能。
3.1 nn.Module类
nn.Module是PyTorch提供的神经网络类,并在类中实现了网络各层的定义及前向计算与反向传播机制。在实际使用时,如果想要实现某个神经网络,只需继承nn.Module,在初始化中定义模型结构与参数,在函数forward()中编写网络前向过程即可。
1.nn.Parameter函数
2.forward()函数与反向传播
3.多个Module的嵌套
4.nn.Module与nn.functional库
5.nn.Sequential()模块
#这里用torch.nn实现一个MLP
from torch import nn
class MLP(nn.Module):
def __init__(self, in_dim, hid_dim1, hid_dim2, out_dim):
super(MLP, self).__init__()
self.layer = nn.Sequential(
nn.Linear(in_dim, hid_dim1),
nn.ReLU(),
nn.Linear(hid_dim1, hid_dim2),
nn.ReLU(),
nn.Linear(hid_dim2, out_dim),
nn.ReLU()
)
def forward(self, x):
x = self.layer(x)
return x
3.2 搭建简易神经网络
下面我们用torch搭一个简易神经网络:
1、我们设置输入节点为1000,隐藏层的节点为100,输出层的节点为10
2、输入100个具有1000个特征的数据,经过隐藏层后变成100个具有10个分类结果的特征,然后将得到的结果后向传播
import torch
batch_n = 100#一个批次输入数据的数量
hidden_layer = 100
input_data = 1000#每个数据的特征为1000
output_data = 10
x = torch.randn(batch_n,input_data)
y = torch.randn(batch_n,output_data)
w1 = torch.randn(input_data,hidden_layer)
w2 = torch.randn(hidden_layer,output_data)
epoch_n = 20
lr = 1e-6
for epoch in range(epoch_n):
h1=x.mm(w1)#(100,1000)*(1000,100)-->100*100
print(h1.shape)
h1=h1.clamp(min=0)
y_pred = h1.mm(w2)
loss = (y_pred-y).pow(2).sum()
print("epoch:{},loss:{:.4f}".format(epoch,loss))
grad_y_pred = 2*(y_pred-y)
grad_w2 = h1.t().mm(grad_y_pred)
grad_h = grad_y_pred.clone()
grad_h = grad_h.mm(w2.t())
grad_h.clamp_(min=0)#将小于0的值全部赋值为0,相当于sigmoid
grad_w1 = x.t().mm(grad_h)
w1 = w1 -lr*grad_w1
w2 = w2 -lr*grad_w2
torch.Size([100, 100])
epoch:0,loss:112145.7578
torch.Size([100, 100])
epoch:1,loss:110014.8203
torch.Size([100, 100])
epoch:2,loss:107948.0156
torch.Size([100, 100])
epoch:3,loss:105938.6719
torch.Size([100, 100])
epoch:4,loss:103985.1406
torch.Size([100, 100])
epoch:5,loss:102084.9609
torch.Size([100, 100])
epoch:6,loss:100236.9844
torch.Size([100, 100])
epoch:7,loss:98443.3359
torch.Size([100, 100])
epoch:8,loss:96699.5938
torch.Size([100, 100])
epoch:9,loss:95002.5234
torch.Size([100, 100])
epoch:10,loss:93349.7969
torch.Size([100, 100])
epoch:11,loss:91739.8438
torch.Size([100, 100])
epoch:12,loss:90171.6875
torch.Size([100, 100])
epoch:13,loss:88643.1094
torch.Size([100, 100])
epoch:14,loss:87152.6406
torch.Size([100, 100])
epoch:15,loss:85699.4297
torch.Size([100, 100])
epoch:16,loss:84282.2500
torch.Size([100, 100])
epoch:17,loss:82899.9062
torch.Size([100, 100])
epoch:18,loss:81550.3984
torch.Size([100, 100])
epoch:19,loss:80231.1484
四、torch实现一个完整的神经网络
4.1 torch.autograd和Variable
torch.autograd包的主要功能就是完成神经网络后向传播中的链式求导,手动去写这些求导程序会导致重复造轮子的现象。
自动梯度的功能过程大致为:先通过输入的Tensor数据类型的变量在神经网络的前向传播过程中生成一张计算图,然后根据这个计算图和输出结果精确计算出每一个参数需要更新的梯度,并通过完成后向传播完成对参数的梯度更新。
完成自动梯度需要用到的torch.autograd包中的Variable类对我们定义的Tensor数据类型变量进行封装,在封装后,计算图中的各个节点就是一个Variable对象,这样才能应用自动梯度的功能。
下面我们使用autograd实现一个二层结构的神经网络模型
import torch
from torch.autograd import Variable
batch_n = 100#一个批次输入数据的数量
hidden_layer = 100
input_data = 1000#每个数据的特征为1000
output_data = 10
x = Variable(torch.randn(batch_n,input_data),requires_grad=False)
y = Variable(torch.randn(batch_n,output_data),requires_grad=False)
#用Variable对Tensor数据类型变量进行封装的操作。requires_grad如果是False,表示该变量在进行自动梯度计算的过程中不会保留梯度值。
w1 = Variable(torch.randn(input_data,hidden_layer),requires_grad=True)
w2 = Variable(torch.randn(hidden_layer,output_data),requires_grad=True)
#学习率和迭代次数
epoch_n=50
lr=1e-6
for epoch in range(epoch_n):
h1=x.mm(w1)#(100,1000)*(1000,100)-->100*100
print(h1.shape)
h1=h1.clamp(min=0)
y_pred = h1.mm(w2)
#y_pred = x.mm(w1).clamp(min=0).mm(w2)
loss = (y_pred-y).pow(2).sum()
print("epoch:{},loss:{:.4f}".format(epoch,loss.data))
# grad_y_pred = 2*(y_pred-y)
# grad_w2 = h1.t().mm(grad_y_pred)
loss.backward()#后向传播
# grad_h = grad_y_pred.clone()
# grad_h = grad_h.mm(w2.t())
# grad_h.clamp_(min=0)#将小于0的值全部赋值为0,相当于sigmoid
# grad_w1 = x.t().mm(grad_h)
w1.data -= lr*w1.grad.data
w2.data -= lr*w2.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
# w1 = w1 -lr*grad_w1
# w2 = w2 -lr*grad_w2
得到结果:
torch.Size([100, 100])
epoch:0,loss:54572212.0000
torch.Size([100, 100])
epoch:1,loss:133787328.0000
torch.Size([100, 100])
epoch:2,loss:491439904.0000
torch.Size([100, 100])
epoch:3,loss:683004416.0000
torch.Size([100, 100])
epoch:4,loss:13681055.0000
torch.Size([100, 100])
epoch:5,loss:8058388.0000
torch.Size([以上是关于狂肝两万字带你用pytorch搞深度学习!!!的主要内容,如果未能解决你的问题,请参考以下文章