ClickHouse到底有什么本事呢?互联网公司如此追捧
Posted 科技D人生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ClickHouse到底有什么本事呢?互联网公司如此追捧相关的知识,希望对你有一定的参考价值。
一 ClickHouse的介绍
1.1 什么是ClickHouse
ClickHouse is a fast open-source OLAP database management system.ClickHouse works 100-1000x faster than traditional approaches.
上面是官网文档给出的解释,翻译过来就是:ClickHouse 是一个开源的用于OLAP分析的数据库系统,其处理数据的速度比传统方法快100-1000 倍。
ClickHouse的性能确实超过了目前市面上很多DBMS系统,尤其是ClickHouse具有强悍的单机处理能力。它可以每秒钟处理数亿或数十亿条数据。
1.2 ClickHouse的能力
ClickHouse的定位是对OLAP场景的支持,定制开发出了一套全新的面向列式存储的数据库引擎,并且实现了数据的有序存储、主键索引、稀疏索引、数据Sharding、数据Partitioning、TTL、主备复制等功能。
二 ClickHouse的架构
2.1 集群架构特点
HDFS、Spark、HBase和Elasticsearch都采用了Master-Slave主从模式的分布式架构。而ClickHouse则采用的是Multi-Master多主架构,集群中的每个节点角色对等,客户端访问任意一个节点都能得到相同的效果。这种多主的架构有许多优势,例如对等的角色使系统架构变得更加简单,不用再区分主控节点、数据节点和计算节点,集群中的所有节点功能相同。所以它天然规避了单点故障的问题,非常适合用于多数据中心、异地多活的场景。具体的架构如图所示:
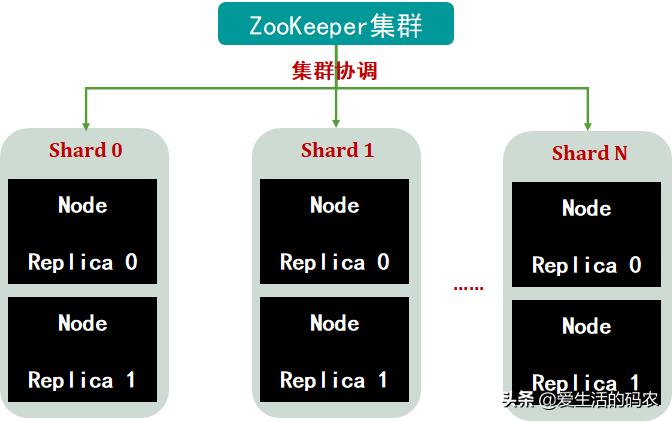
ClickHouse集群架构
2.1.1 Shard
集群内部划分成多个分组/分片(Shard 0 ... Shard N),可以通过Shard的线性扩张,来扩大ClickHouse的存储能力。
2.1.2 Node
每个Shard都有多个节点(Node),同一个Shard内的节点互为副本,而且不同的Shard内的副本数可以不同。
2.1.3 ZooKeeper
因为ClickHouse采用的是Multi-Master多主架构,集群中的每个节点角色对等,因此,节点间通过 ZooKeeper 服务进行分布式协调。
2.2 ClickHouse的架构设计
目前ClickHouse公开的资料非常少,甚至连官方的架构设计图都没有。即便如此,我们还是从一些零散的资料中,找到一些蛛丝马迹。接下来我们一起来学习一下ClickHouse底层概念,已帮助我们进一步了解ClickHouse。

ClickHouse内部架构
2.2.1 Column和field
Column和Field是ClickHouse的逻辑数据基本单元,因为ClickHouse完全是按列存储的,所以内存中的一列数据由一个Column表示。要表示内存中的列(实际上是列块),需使用 Column 接口。该接口提供了用于实现各种关系操作符的辅助方法。
在大多数情况下,ClickHouse都会以整列的方式操作数据,但是凡事都有例外,如果需要操作单个具体的数值(也就是单列中的一行数据),则需要使用field对象,Field对象代表一个单值。Field 是 UInt64、Int64、Float64、String 和 Array 组成的联合。Column 拥有 operator[] 方法来获取第 n 个值成为一个 Field,同时也拥有 insert 方法将一个 Field 追加到一个列的末尾。这些方法并不高效,因为它们需要处理表示单一值的临时 Field 对象,但是有更高效的方法比如 insertFrom 和 insertRangeFrom 等。
2.2.2 DataType
DataType 负责序列化和反序列化,DataType 直接与表的数据类型相对应。比如,有 DataTypeUInt32、DataTypeDateTime、DataTypeString 等数据类型。
DataType 具有针对各种数据格式的辅助函数。比如如下一些辅助函数:序列化一个值并加上可能的引号;序列化一个值用于 JSON 格式;序列化一个值作为 XML 格式的一部分。辅助函数与数据格式并没有直接的对应。比如,两种不同的数据格式 Pretty和TabSeparated均可以使用DataType接口提供的 serializeTextEscaped 这一辅助函数。
2.2.3 Block
Block 是表示内存中表的子集(chunk)的容器,是由三元组(Column, DataType, 列名) 构成的集合。在查询执行期间,数据是按 Block 进行处理的。Column提供了数据的读取能力,而DataType知道如何正反序列化,所以Block在这些对象的基础之上实现了进一步的抽象和封装,从而简化了整个使用的过程,仅通过Block对象就能完成一系列的数据操作。
2.2.4 块流(Block Streams)
块流用于处理数据。我们可以使用块流从某个地方读取数据,执行数据转换,或将数据写到某个地方。IBlockInputStream 具有 read 方法,其能够在数据可用时获取下一个块。IBlockOutputStream 具有 write 方法,其能够将块写到某处。
2.2.5 表(Tables)
在数据表的底层设计中并没有所谓的Table对象,表由 IStorage 接口表示。该接口的不同实现对应不同的表引擎。比如 StorageMergeTree、StorageMemory 等。这些类的实例就是表。
IStorage 中最重要的方法是 read 和 write,除此之外还有 alter、rename 和 drop 等方法。
在数据查询时,IStorage负责根据AST查询语句的指示要求,返回指定列的原始数据。后续对数据的进一步加工、计算和过滤,则会统一交由Interpreter解释器对象处理。对Table发起的一次操作通常都会经历这样的过程,接收AST查询语句,根据AST返回指定列的数据,之后再将数据交由Interpreter做进一步处理。
2.2.6 Parser
Parser负责创建 AST对象,不同的SQL语句,会经由不同的Parser实现类解析。例如,有负责解析DDL查询语句的ParserRenameQuery、ParserDropQuery和ParserAlterQuery解析器,也有负责解析INSERT语句的ParserInsertQuery解析器,还有负责SELECT语句的ParserSelectQuery等。
2.2.7Interpreter
Interpreter负责串联整个查询过程,根据Parser的类型,聚合它所需要的资源。首先解析AST对象;然后执行"业务逻辑" ( 例如分支判断、设置参数、调用接口等 );最终返回IBlock对象,以线程的形式建立起一个查询执行管道。
2.2.8 Functions 与Aggregate Functions
函数既有普通函数,也有聚合函数。普通函数不会改变行数 - 它们的执行看起来就像是独立地处理每一行数据。
聚合函数使用 IAggregateFunction 接口进行管理。状态可以非常简单(AggregateFunctionCount 的状态只是一个单一的UInt64 值),也可以非常复杂(
AggregateFunctionUniqCombined 的状态是由一个线性数组、一个散列表和一个 HyperLogLog 概率数据结构组合而成的)。
2.2.9 Cluster与Replication
集群内部划分成多个分组/分片(Shard 0 ... Shard N),可以通过Shard的线性扩张,来扩大ClickHouse的存储能力。每个Shard都有多个节点(Node),同一个Shard内的节点互为副本,而且不同的Shard内的副本数可以不同。
三 ClickHouse为何如此之快
3.1 ClickHouse存储层
3.1.1 列式存储
相比于行式存储,列式存储有如下优点:
- 我们在做统计某些指标的聚合值时,往往需要查询海量的行,但是仅仅需要少量的列。在列式存储的模式下,只需要读取与计算有关的列即可,极大的减少的数据的IO操作,加快了查询速度。
- 同一列的数据类型相同,压缩比高,能够减少大量的存储空间;更高的压缩比,意味着从磁盘中读取数据更加省时。
- 自由的压缩比算法,不同的列可以选用不同的压缩算法。这样可以根据不同列的类型,选择最合适的压缩算法。
3.1.2 数据的有序存储
在创建ClickHouse表时,可以指定数据按某些列进行排序。排序后,这些sort key相同的数据会分布在磁盘的连续空间上。这样在查询数据的时候,命中率就非常高。
3.1.3 主键索引
ClickHouse支持主键索引,它将每列数据按照index granularity(默认8192行)进行划分,每个index granularity的开头第一行被称为一个mark行。主键索引存储该mark行对应的primary key的值。
对于where条件中含有primary key的查询,通过对主键索引进行二分查找,能够直接定位到对应的index granularity,避免了全表扫描从而加速查询。
3.1.4 高吞吐写入能力
ClickHouse采用类LSM树的结构,数据写入后定期在后台Compaction。ClickHouse采用顺序写的模式将数据追加到文件中。顺序写的特性,充分利用了磁盘的吞吐能力,我们知道顺序写和向内存中写入数据的效果差不多。
3.2 ClickHouse的计算层
3.2.1 多核并行计算
ClickHouse将数据划分为多个partition,每个partition再进一步划分为多个index granularity,然后通过多个CPU核心分别处理其中的一部分来实现并行数据处理。这样,单条Query就能利用整机所有CPU。极致的并行处理能力,极大的降低了查询延时。
3.2.2 向量化执行
在支持列存储格式的基础上,ClickHouse 实现了一套面向向量化处理的计算引擎,大量的处理操作都是向量化执行的。
向量化执行引擎采用批量处理模式,可以大幅减少函数调用开销,降低数据的 Cache Miss,提升 CPU 利用效率。
四 结束语
我们主要介绍了ClickHouse的整体架构和众多核心功能,分析了ClickHouse如何实现高性能。近年来,ClickHouse发展的很猛,社区和很多互联网大厂都在跟进使用。
相比于开源社区的其他OLAP技术,例如Presto、Impala、Kylin、Druid等,ClickHouse具有完整的一套解决方案,它自己包含存储和计算能力(无需依赖其他存储软件),完全自主的实现了高可用,而且对SQL支持的相对比较好。
ClickHouse仍然年轻,肯定有很多不足,希望大家一起努力为社区贡献力量,让ClickHouse做的更好。
以上是关于ClickHouse到底有什么本事呢?互联网公司如此追捧的主要内容,如果未能解决你的问题,请参考以下文章