C++编程经验(12):C++11新特性
Posted 看,未来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++编程经验(12):C++11新特性相关的知识,希望对你有一定的参考价值。

没有系统学过,所以这篇写的基本都是我接触过的,接触过多少就整理多少吧。
有些特性也不知道是不是新的,反正都是我新接触的,用的还挺顺手。
语法层面
区间迭代range for
用过一次我就很喜欢这个特性了,写起来是方便了不少。
for(int i:vec){
cout<<i<<endl;
}
nullptr
这是一个空指针类的对象。
我们以前把指针置空都是:
ptr = NULL;
NULL是一个宏定义,数值为0。当然不是说用NULL有什么问题,不过新的规范都出来了,就用新规也没什么不好嘛。
强制类型转换(这个其实不是)
static_cast:正常的类型转换,static_cast 不能从表达式中去除 const 属性
const_cast:用于且仅用于类型转换掉表达式的 const 或 volatileness 属性。
dynamic_cast:用于安全地沿着类的继承关系向下进行类型转换。
reinterpret_cast:在函数指针类型之间进行转换,这个转换符不是很受待见
其的转换结果几乎都是执行期定义。 因此,使用reinterpret_casts 的代码很难移植。
示例:
int a;
double result = static_cast<double>(a);
class father { ... };
class son: public father { ... };
void update(son* psw);
son sw; // sw 是一个非 const 对象。
const son& csw = sw; // csw 是 sw 的一个引用,它是一个 const 对象
update(&csw); // 错误!不能传递一个 const son* 变量给一个处理 son*类型变量的函数
update(const_cast<son*>(&csw)); // 正确,csw 的 const 被显示地转换掉
update((son*)&csw); // 同上,但用了一个更难识别的 C 风格的类型转换
father *pw = new son;
update(pw); // 错误!pw 的类型是 father*,但是 update 函数处理的是 son*类型
update(const_cast<son*>(pw));// 错误!const_cast 仅能被用在影响 constness or volatileness 的地方上。,
// 不能用在向继承子类进行类型转换。
father* pw;
...
update(dynamic_cast<son*>(pw)); // 正确,传递给 update 函数一个指针是指向变量类型为 son的 pw 的指针
void updateViaRef(son& rsw);
updateViaRef(dynamic_cast<son&>(*pw)); //正确。 传递给 updateViaRef 函数 SpecialWidget pw 指针
智能指针
智能指针是存储指向动态分配(堆)对象指针的类。除了能够在适当的时间自动删除指向的对象外,他们的工作机制很像C++的内置指针。
在使用对象的时候,使用强智能指针;在引用对象的时候,使用弱智能指针。
详情转:C++编程经验(9):智能指针 – 裸指针管得了的我要管,裸指针管不了的我更要管!
function函数对象、bind绑定器、placeholders占位符
这三个还是要合在一起讲的了。
C++编程经验(11):std::function 和 bind绑定器,虽然在这一篇里面专门讲过了,但是感觉有点抽象,重新捋一下,不然我也不长记性呐。
using MsgHandler = std::function<void(const TcpConnectionPtr &conn,json &js,Timestamp time)>;
理解为:
typename void(const TcpConnectionPtr &conn,json &js,Timestamp time) MsgHandler ;
MsgHandler 是一个自定义数据类型,函数指针。
既然是一个数据类型,就可以被塞到容器里面:
unordered_map<int,MsgHandler> _msgHanderMap;
函数指针有什么用,它就有什么用,可以用来推迟函数的声明。
绑定器是干嘛的呢?将参数绑定到函数指针上的。
以前的绑定器只能绑定一个参数,所以我们看到的很多古老的需要函数指针做传参的函数都只有一个参数传递,但是有了新的绑定器就不一样了。
_msgHanderMap.insert({LOGIN_TYPE,std::bind(&ChatService::login,this,_1,_2,_3)});
//将三个参数绑定到login函数上,由于是在类内,所以带上一个this。
std::bind(&ChatService::login,this,_1,_2,_3)
//这三个参数使用占位符事先申明
绑定好了,现在要调用这个函数就需要在调用的时候传参,那被绑定的函数要如何取参数,这就取决于占位符的声明了。
std::placeholders决定函数占用位置取用输入参数的第几个参数。
那么现在一条脉络就很清楚了。
要使用函数指针,使用function进行函数指针模板的声明与调用;
实例化function模板所用的函数可能有不下于1个的参数,旧的绑定器已经不行了,用新的绑定器来吧;
而函数指针需要从调用函数指针的函数那里去获得传入参数,这个参数的位置排序的确定就需要靠占位符来指定了,或许可以称之为导航符吧。
lambda表达式
简单来说,Lambda函数也就是一个函数,它的语法定义如下:
[capture](parameters) mutable ->return-type{statement}
1.[capture]:捕捉列表。捕捉列表总是出现在Lambda函数的开始处。实际上,[]是Lambda引出符。编译器根据该引出符判断接下来的代码是否是Lambda函数。捕捉列表能够捕捉上下文中的变量以供Lambda函数使用;
2.(parameters):参数列表。与普通函数的参数列表一致。如果不需要参数传递,则可以连同括号“()”一起省略;
3.mutable:mutable修饰符。默认情况下,Lambda函数总是一个const函数,mutable可以取消其常量性。在使用该修饰符时,参数列表不可省略(即使参数为空);
4.->return-type:返回类型。用追踪返回类型形式声明函数的返回类型。我们可以在不需要返回值的时候也可以连同符号”->”一起省略。此外,在返回类型明确的情况下,也可以省略该部分,让编译器对返回类型进行推导;
5.{statement}:函数体。内容与普通函数一样,不过除了可以使用参数之外,还可以使用所有捕获的变量。
与普通函数最大的区别是,除了可以使用参数以外,Lambda函数还可以通过捕获列表访问一些上下文中的数据。具体地,捕捉列表描述了上下文中哪些数据可以被Lambda使用,以及使用方式(以值传递的方式或引用传递的方式)。语法上,在“[]”包括起来的是捕捉列表,捕捉列表由多个捕捉项组成,并以逗号分隔。捕捉列表有以下几种形式:
1.[var]表示值传递方式捕捉变量var;
2.[=]表示值传递方式捕捉所有父作用域的变量(包括this);
3.[&var]表示引用传递捕捉变量var;
4.[&]表示引用传递方式捕捉所有父作用域的变量(包括this);
5.[this]表示值传递方式捕捉当前的this指针。
6.[]没有任何函数对象参数。
7.&a。将 a 按引用进行传递。
8.a,&b。将 a 按值传递,b 按引用进行传递。
9.=,&a,&b。除 a 和 b 按引用进行传递外,其他参数都按值进行传递。
10.&,a,b。除 a 和 b 按值进行传递外,其他参数都按引用进行传递。
move
对于move了解不多。
C++11为了解决这个问题,提供了std::move()方法来将左值转换为右值,从而方便应用移动语义。move是将对象的状态或者所有权从一个对象转移到另一个对象,只是转义,没有内存拷贝。
类相关
explicit类型转换运算符
防止类构造发生默认类型转换
对这个关键字我现在持怀疑态度了,是我的VS坏了,还是我的眼睛瞎了呢?
下面三个测试案例结果都是一样的。
#include<vector>
#include<iostream>
using namespace std;
//发生了转换
//class A {
//public:
// explicit A(int i,int j) {
// cout << i << endl;
// }
//
//};
//
//
//int main() {
// A a('a', 20);
//}
//依旧发生了转换,有什么区别吗?
//class A {
//public:
// explicit A(int i) {
// cout << i << endl;
// }
//
//};
//
//
//int main() {
// A a('a');
//}
class A {
public:
A(int i) {
cout << i << endl;
}
};
int main() {
A a('a');
}
=default和=delete
如果实现了默认的构造函数,编译器则不会自动生成默认版本;可以通过使用关键字 default 来控制默认构造函数的生成,显示的指示编译器生成该函数的默认版本;
如果不想有某些默认生成的函数,就设置一个 =delete。
如果给类手动写了带参构造,那也是无法显式使用无参构造函数了。
如果没有了默认构造,子类就不能不传参给父类进行构造了。
override、final
final关键字的作用是使派生类不可覆盖它所修饰的虚函数。
override关键字的作用是使派生类被制定的函数必须是覆盖它所修饰的虚函数。
using
现在不仅仅可以用它来引用名空间了,不过现在我也不怎么用这个来引用名空间了,都是用域作用符::。
现在用它都是用来替代以前的typedef了,而且一般是和下面的function函数对象结合在一起使用,最近在整muduo,这些接触到的会比较多。
volatile
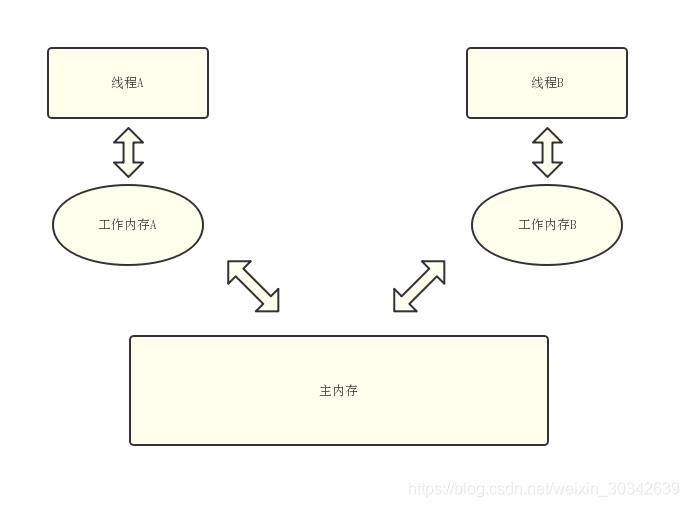
如上图所示,所有线程的共享变量都存储在主内存中,每一个线程都有一个独有的工作内存,每个线程不直接操作在主内存中的变量,而是将主内存上变量的副本放进自己的工作内存中,只操作工作内存中的数据。当修改完毕后,再把修改后的结果放回到主内存中。每个线程都只操作自己工作内存中的变量,无法直接访问对方工作内存中的变量,线程间变量值的传递需要通过主内存来完成。
如果对变量 i 加上 volatile 关键字修饰的话,它可以保证当 A 线程对变量 i 值做了变动之后,会立即刷回到主内存中,而其它线程读取到该变量的值也作废,强迫重新从主内存中读取该变量的值,这样在任何时刻,AB线程总是会看到变量 i 的同一个值。
它不是原子操作的。
线程
Thread
std::thread无疑是一个重磅福利。
std::thread 在 <thread> 头文件中声明,因此使用 std::thread 时需要包含 <thread> 头文件。
线程构造
默认构造函数 thread() noexcept;
初始化构造函数 template <class Fn, class... Args>
explicit thread(Fn&& fn, Args&&... args);
拷贝构造函数 [deleted] thread(const thread&) = delete;
Move 构造函数 thread(thread&& x) noexcept;
Move 赋值操作 thread& operator=(thread&& rhs) noexcept;
拷贝赋值操作 [deleted] thread& operator=(const thread&) = delete;
默认构造函数,创建一个空的 std::thread 执行对象。
初始化构造函数,创建一个 std::thread 对象,该 std::thread 对象可被 joinable,新产生的线程会调用 fn 函数,该函数的参数由 args 给出。
拷贝构造函数(被禁用),意味着 std::thread 对象不可拷贝构造。
Move 构造函数,,调用成功之后 x 不代表任何 std::thread 执行对象。
注意:可被 joinable 的 std::thread 对象必须在他们销毁之前被主线程 join 或者将其设置为 detached.
Move 赋值操作(1),如果当前对象不可 joinable,需要传递一个右值引用(rhs)给 move 赋值操作;如果当前对象可被 joinable,则会调用 terminate() 报错。
拷贝赋值操作(2),被禁用,因此 std::thread 对象不可拷贝赋值。
其他方法
get_id: 获取线程 ID,返回一个类型为 std::thread::id 的对象。
joinable: 检查线程是否可被 join。检查当前的线程对象是否表示了一个活动的执行线程,由默认构造函数创建的线程是不能被 join 的。另外,如果某个线程 已经执行完任务,但是没有被 join 的话,该线程依然会被认为是一个活动的执行线程,因此也是可以被 join 的。
detach: Detach 线程。 将当前线程对象所代表的执行实例与该线程对象分离,使得线程的执行可以单独进行。一旦线程执行完毕,它所分配的资源将会被释放。
swap: Swap 线程,交换两个线程对象所代表的底层句柄
thread 1 id: 1892
thread 2 id: 2584
after std::swap(t1, t2):
thread 1 id: 2584
thread 2 id: 1892
after t1.swap(t2):
thread 1 id: 1892
thread 2 id: 2584
yield: 当前线程放弃当前时间片,操作系统调度另一线程继续执行。
sleep_until: 线程休眠至某个指定的时刻(time point),该线程才被重新唤醒。
sleep_for: 线程休眠某个指定的时间片(time span),该线程才被重新唤醒,不过由于线程调度等原因,实际休眠时间可能比 sleep_duration 所表示的时间片更长。
threadpool示例
缩略muduo库(5):Thread、EventThread、EventThreadPool
对这份线程池我还是有自信的。
锁种
lock_guard
创建lock_guard对象时,它将尝试获取提供给它的互斥锁的所有权。当控制流离开lock_guard对象的作用域时,lock_guard析构并释放互斥量。
它的特点如下:
创建即加锁,作用域结束自动析构并解锁,无需手工解锁
不能中途解锁,必须等作用域结束才解锁
不能复制
unique_lock
简单地讲,unique_lock 是 lock_guard 的升级加强版,它具有 lock_guard 的所有功能,同时又具有其他很多方法,使用起来更强灵活方便,能够应对更复杂的锁定需要。
特点如下:
创建时可以不锁定(通过指定第二个参数为std::defer_lock),而在需要时再锁定
可以随时加锁解锁
作用域规则同 lock_grard,析构时自动释放锁
不可复制,可移动
条件变量需要该类型的锁作为参数(此时必须使用unique_lock)
示例:
#include <mutex>
#include <thread>
#include <chrono>
struct Box {
explicit Box(int num) : num_things{num} {}
int num_things;
std::mutex m;
};
void transfer(Box &from, Box &to, int num)
{
// don't actually take the locks yet
std::unique_lock<std::mutex> lock1(from.m, std::defer_lock);
std::unique_lock<std::mutex> lock2(to.m, std::defer_lock);
// lock both unique_locks without deadlock
std::lock(lock1, lock2);
from.num_things -= num;
to.num_things += num;
// 'from.m' and 'to.m' mutexes unlocked in 'unique_lock' dtors
}
int main()
{
Box acc1(100);
Box acc2(50);
std::thread t1(transfer, std::ref(acc1), std::ref(acc2), 10);
std::thread t2(transfer, std::ref(acc2), std::ref(acc1), 5);
t1.join();
t2.join();
}
condition_variable
条件变量。
通知方:
获取 std::mutex, 通常是 std::lock_guard
修改共享变量(即使共享变量是原子变量,也需要在互斥对象内进行修改,以保证正确地将修改发布到等待线程)
在 condition_variable 上执行 notify_one/notify_all 通知条件变量(该操作不需要锁)
等待方:
获取相同的 std::mutex, 使用 std::unique_lock
执行 wait,wait_for或wait_until(该操作会自动释放锁并阻塞)
接收到条件变量通知、超时或者发生虚假唤醒时,线程被唤醒,并自动获取锁。唤醒的线程负责检查共享变量,如果是虚假唤醒,则应继续等待
std :: condition_variable仅适用于 std::unique_lock
对于只需要通知一次的情况,如初始化完成、登录成功等,建议不要使用 condition_variable,使用std::future更好。不过这个我还没有去了解。
CAS 和 atomic
在有些场景里面,是需要对一些资源进行锁定的。但是有些资源实在是太小了,锁定的粒度也太小了,不免显得上锁解锁倒成了繁琐。
比方说:
_mlock.lock();
count++;
_mlock.unlock();
CAS,是基于硬件层面的无锁操作,由CPU来保证。
#include<iostream>
#include<memory>
#include<thread>
#include<atomic> //其中包含很多原子操作
#include<vector>
using namespace std;
volatile atomic_bool isReady = false; //volatile:防止共享变量被缓存,导致线程跑来跑去
volatile atomic_int mycount = 0;
void task() {
while (!isReady) {
this_thread::yield(); //出让时间片,等待下一次调用
}
for (int i = 0; i < 100; i++) {
mycount++;
}
}
int main() {
vector<thread> tvec;
for (int i = 0; i < 10;i++) {
tvec.push_back(thread(task));
}
this_thread::sleep_for(chrono::seconds(3));
isReady = true;
for (thread& t : tvec) {
t.join();
}
cout << mycount << endl;
return 0;
}
容器相关
unordered_XXX
哈希表。
容器的emplace成员
emplace操作是C++11新特性,新引入的的三个成员emplace_front、emplace 和 emplace_back。这些操作构造而不是拷贝元素到容器中,这些操作分别对应push_front、insert 和push_back,允许我们将元素放在容器头部、一个指定的位置和容器尾部。
以上是关于C++编程经验(12):C++11新特性的主要内容,如果未能解决你的问题,请参考以下文章
C++11新特性:1—— C++ 11是什么,C++ 11标准的由来