跨云集群的就近本地访问
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了跨云集群的就近本地访问相关的知识,希望对你有一定的参考价值。
业务需求
作业帮为了确保某个业务 Elasticsearch 集群的高可用,在百度云和华为云上面采取了双云部署,即将单个 Elasticsearch 集群跨云进行部署,并且要求业务请求优先访问本地云。
Elasticsearch 单集群双云实现
Elasticsearch 集群采用 Master 与 Data 节点分离的架构。目前主力云放 2 个 Master,另外一个云放一个 Master。主要考虑就是基础设施故障中,专线故障问题是大多数,某个云厂商整体挂的情况基本没有。所以设置了主力云,当专线故障时,主力云的 Elasticsearch 是可以读写的,业务把流量切到主力云就行了。
具体配置方式如下。
首先,在 Master 节点上设置:
cluster.routing.allocation.awareness.attributes: zone_id
cluster.routing.allocation.awareness.force.zone_id.values: zone_baidu,zone_huawei
然后分别在百度云上数据节点上设置:
node.attr.zone_id: zone_baidu
和华为云上数据节点上设置:
node.attr.zone_id: zone_huawei
创建索引采用 1 副本,可以保证百度云与华为云上都有一份相同的数据。
业务访问方式如下图:
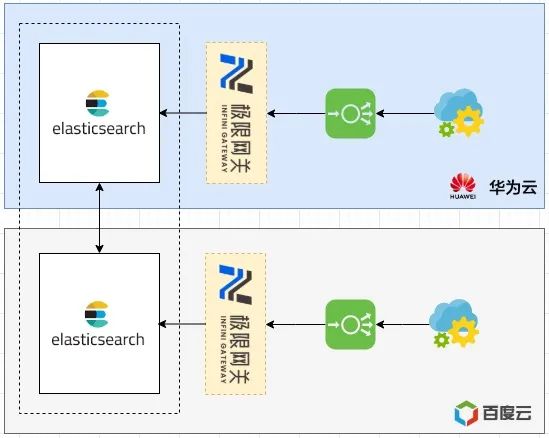
百度云业务 -> 百度 lb -> INFINI Gateway (百度) -> Elasticsearch (百度云 data 节点)
华为云业务 -> 华为 lb -> INFINI Gateway (华为) -> Elasticsearch (华为云 data 节点)
极限网关配置
Elasticsearch 支持一个 Preference 参数来设置请求的优先访问,通过在两个云内部的极限网关分别设置各自请求默认的 Preference 参数,让各个云内部的请求优先发往本云内的数据节点,即可实现请求的就近访问。
具体的百度云的 INFINI Gateway 配置如下(华为云大体相同,就不重复贴了):
path.data: data
path.logs: log
entry:
- name: es-test
enabled: true
router: default
network:
binding: 0.0.0.0:9200
reuse_port: true
router:
- name: default
default_flow: es-test
flow:
- name: es-test
filter:
- name: set_request_query_args
parameters:
args:
- preference -> _prefer_nodes:data-baidu01,data-baidu02 #通过配置preference的_prefer_nodes为所有的百度data节点,来实现百度云的业务优先访问百度云的节点,最大程度避免跨云访问,对业务更友好。
- name: elasticsearch
parameters:
elasticsearch: default
refresh:
enabled: true
interval: 10s
roles:
include:
- data #配置为data,请求只发送到data节点
tags:
include:
- zone_id: zone_baidu #只转发给百度云里面的节点
elasticsearch:
- name: default
enabled: true
endpoint: http://10.10.10.10:9200
discovery:
enabled: true
refresh:
enabled: true
interval: 10s
basic_auth:
username: elastic
password: elastic
总结与收益
引入极限网关前故障回顾
百度云业务访问 Elasticsearch 集群,拉取每天的增量数据同步到 Hive 集群,其中有几个任务失败后,又重新同步。结果是部分数据从华为云的 Elasticsearch 节点拉取到百度云的 Hive 集群中,数据量巨大导致跨云专线流量监控告警。由于线上业务、mysql、Redis、Elasticsearch 等使用同一根专线, 此次故障影响面较大。临时解决方案是业务修改语句加入 Preference 参数来实现业务只拉取本地云数据,减少对专线的占用。但是一方面业务改造及维护成本较高;另一方面作为 DBA 会担心业务改造有疏漏、新增业务遗忘 Preference 参数、以及后期调整成本较高,这始终是一个风险点。
引入极限网关的收益
在原有架构上加入极限网关,可以在业务不修改代码的情况下做到优先访问本地云,提升访问速度的同时,最大限度减少对专线的压力。
正文完
作者:赵青
前网易 DBA,工作主要涉及 Oracle、MySQL、Redis、Elasticsearch、Tidb、OB 等组件的运维以及运维自动化、平台化、智能化等工作。现就职于作业帮。
本文编辑:喝咖啡的猫
关于极限网关
极限网关 (INFINI Gateway) 是一个面向 Elasticsearch 的高性能应用网关,它包含丰富的特性,使用起来也非常简单。极限网关工作的方式和普通的反向代理一样,我们一般是将网关部署在 Elasticsearch 集群前面, 将以往直接发送给 Elasticsearch 的请求都发送给网关,再由网关转发给请求到后端的 Elasticsearch 集群。因为网关位于在用户端和后端 Elasticsearch 之间,所以网关在中间可以做非常多的事情, 比如可以实现索引级别的限速限流、常见查询的缓存加速、查询请求的审计、查询结果的动态修改等等。
极限网关特性:
极限网关是专为 Elasticsearch 而量身打造的应用层网关,地表最强,没有之一!
高可用,不停机索引,自动处理后端 Elasticsearch 的故障,不影响数据的正常摄取
写入加速,可自动合并独立的索引请求为批量请求,降低后端压力,提高索引效率
查询加速,可配置查询缓存,Kibana 分析仪表板的无缝智能加速,全面提升搜索体验
透明重试,自动处理后端 Elasticsearch 节点故障和对查询请求进行迁移重试
流量克隆,支持复制流量到多个不同的后端 Elasticsearch 集群,支持流量灰度迁移
一键重建,优化过的高速重建和增量数据的自动处理,支持新旧索引的透明无缝切换
安全传输,自动支持 TLS/HTTPS,可动态生成自签证书,也可指定自签可信证书
精准路由,多种算法的负载均衡模式,索引和查询可分别配置负载路由策略,动态灵活
限速限流,支持多种限速和限流测规则,可以实现索引级别的限速,保障后端集群的稳定性
并发控制,支持集群和节点级别的 TCP 并发连接数控制,保障后端集群和节点稳定性
无单点故障,内置基于虚拟 IP 的高可用解决方案,双机热备,故障自动迁移,避免单点故障
请求透视,内置日志和指标监控,可以对 Elasticsearch 请求做全面的数据分析
更多推荐
1、Elasticsearch 极限网关测试版本发布
https://elasticsearch.cn/article/14165
2、极限网关 INFINI Gateway 初体验
https://elasticsearch.cn/article/14173
3、INFINI Gateway 的使用方法和使用心得分享
https://elasticsearch.cn/article/14188
4、性能爆表!INFINI Gateway 性能与压力测试结果
https://elasticsearch.cn/article/14174
5、四倍索引速度提升, 有点东西
https://elasticsearch.cn/article/14228
6、索引速度提升 20000% - 某保险集团业务的索引速度提升之旅
http://xn--d6q905cs0q16u.com/docs/user-cases/stories/indexing_speedup_for_big_index_rebuild/
文章转载来源:Elastic中文社区
以上是关于跨云集群的就近本地访问的主要内容,如果未能解决你的问题,请参考以下文章