Carson带你学序列化:深入分析XML多种解析方式(DOMSAXPULL)
Posted Carson_Ho
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Carson带你学序列化:深入分析XML多种解析方式(DOMSAXPULL)相关的知识,希望对你有一定的参考价值。

目录

1. 定义
XML,即 extensible Markup Language ,是一种数据标记语言 & 传输格式
关于另外1种主流的数据传输格式
JSON,具体请看:Carson带你学序列化:深入分析JSON多种解析方式(Gson、AS自带org.json、Jackson)
2. 作用
对数据进行标记(结构化数据)、存储 & 传输
区别于
html:html用于显示信息;而XML用于存储&传输信息
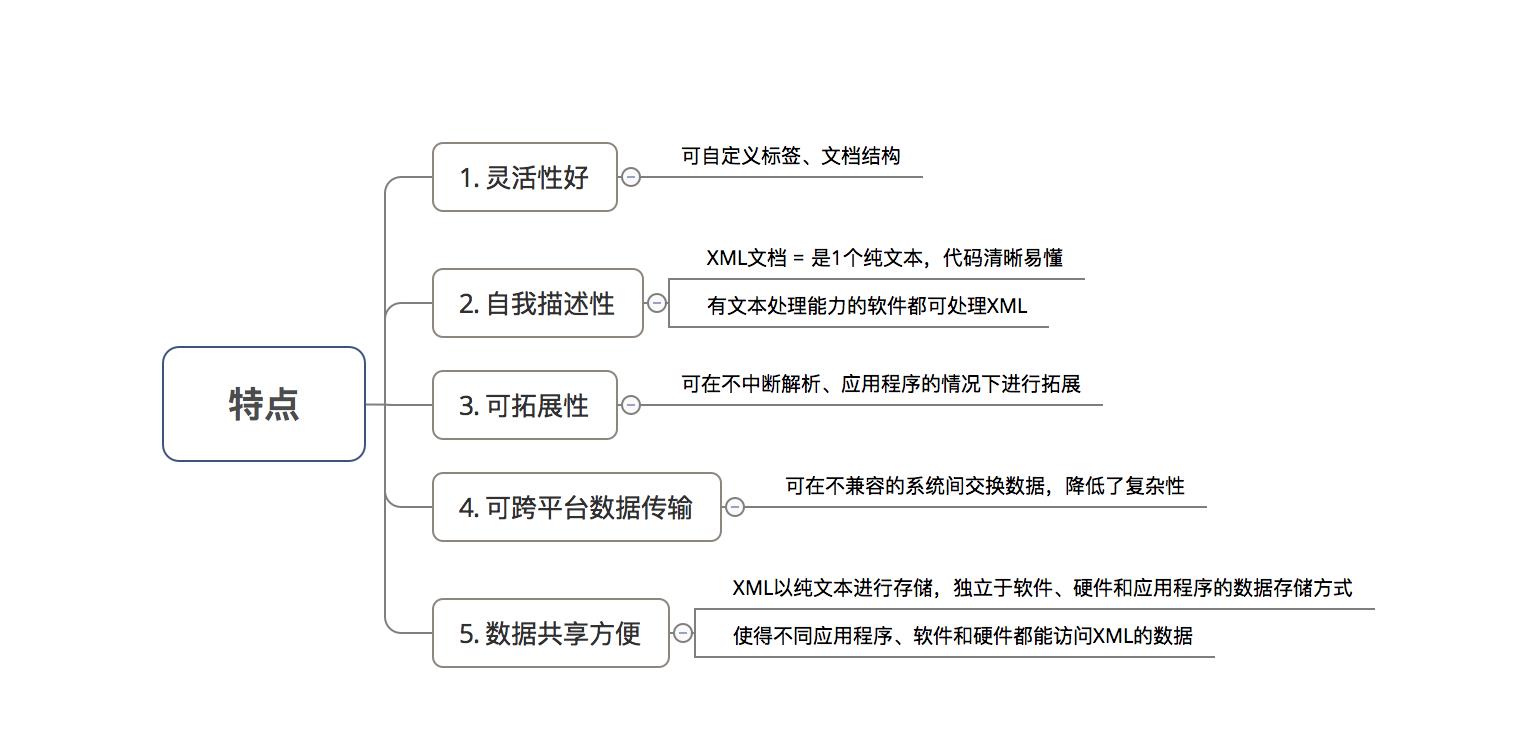
3. 特点
4. 语法
- 元素要关闭标签
< p >this is a bitch <p> - 对大小写敏感
< P >这是错误的<p>
< p >这是正确的 <p>
- 必须要有根元素(父元素)
<root>
<kid>
</kid>
</root>
- 属性值必须加引号
<note date="16/08/08">
</note>
- 实体引用
| 实体引用 | 符号 | 含义 |
|---|---|---|
| <; | < | 小于 |
| > ; | > | 大于 |
| &; | & | 和浩 |
| &apos; | ‘ | 单引号 |
| "; | " | 双引号 |
元素不能使用&(实体的开始)和<(新元素的开始)
-
注释
<!-- This is a comment --> -
XML的元素、属性和属性值
文档实例
<bookstore>
<book category="CHILDREN">
<title lang="en"> Harry Potter </title>
<author> JK.Rowling</author>
</book>
<book category="WEB">
<title lang="en"> woshiPM </title>
<author>Carson_Ho</author>
</book>
</bookstore>
其中,是根元素;是子元素,也是元素类型之一;而中含有属性,即category,属性值是CHILDREN;而元素则拥有文本内容( JK.Rowling)
- 元素与属性的差别
属性即提供元素额外的信息,但不属于数据组成部分的信息。
范例一
<bookstore>
<book category="CHILDREN">
<title lang="en"> Harry Potter </title>
<author> JK.Rowling</author>
</book>
范例二
<bookstore>
<book >
<category>CHILDREN<category>
<title lang="en"> Harry Potter </title>
<author> JK.Rowling</author>
</book>
范例一和二提供的信息是完全相同的。
一般情况下,请使用元素,因为
- 属性无法描述树结构(元素可以)
- 属性不容易拓展(元素可以)
使用属性的情况:用于分配ID索引,用于标识XML元素。
实例
<bookstore>
<book id = "501">
<category>CHILDREN<category>
<title lang="en"> Harry Potter </title>
<author> JK.Rowling</author>
</book>
<book id = "502">
<category>CHILDREN<category>
<title lang="en"> Harry Potter </title>
<author> JK.Rowling</author>
</book>
<bookstore>
上述属性(id)仅用于标识不同的便签,并不是数据的组成部分
- XML元素命名规则
- 不能以数字或标点符号开头
- 不能包含空格
- 不能以xml开头
-
CDATA
不被解析器解析的文本数据,所有xml文档都会被解析器解析(cdata区段除外)
<![CDATA["传输的文本 "]]> -
PCDATA
被解析的字符数据
5. XML树结构
XML文档中的元素会形成一种树结构,从根部开始,然后拓展到每个树叶(节点),下面将以实例说明XML的树结构。
- 假设一个XML文件如下
<?xml version ="1.0" encoding="UTF-8"?>
<简历>
<基本资料>
<求职意向>
<自我评价>
<其他信息>
<联系方式>
<我的作品>
</简历>
-
其树结构如下

-
XML节点解释
XML文件是由节点构成的。它的第一个节点为“根节点”。一个XML文件必须有且只能有一个根节点,其他节点都必须是它的子节点。

this 代表整个XML文件,它的根节点就是 this.firstChild 。 this.firstChild.childNodes 则返回由根节点的所有子节点组成的节点数组。

每个子节点又可以有自己的子节点。节点编号由0开始,根节点的第一个子节点为 this.firstChild.childNodes[0],它的子节点数组就是this.firstChild.childNodes[0].childNodes 。

根节点第一个子节点的第二个子节点 this.firstChild.childNodes[0].childNodes[1],它返回的是一个XML对象(Object) 。这里需要特别注意,节点标签之间的数据本身也视为一个节点 this.firstChild.childNodes[0].childNodes[1].firstChild ,而不是一个值。

我们解析XML的最终目的当然就是获得数据的值:this.firstChild.childNodes[0].childNodes[1].firstChild.nodeValue 。
请注意区分:节点名称(<性别></性别>)和之间的文本内容(男)可以当作是节点,也可以当作是一个值
节点:
名称:this.firstChild.childNodes[0].childNodes[1]
文本内容:this.firstChild.childNodes[0].childNodes[1].firstChild
值:
名称:this.firstChild.childNodes[0].childNodes[1].nodeValue
(节点名称有时也是我们需要的数据)
文本内容:this.firstChild.childNodes[0].childNodes[1].nodeName
在了解完XML之后,是时候来学下如何进行XML的解析了
6. 解析方式
- 解析
XML,即从XML中提取有用的信息 XML的解析方式主要分为2大类:

6.1 DOM方式
- 简介
Document Object Model,即 文件对象模型,是 一种 基于树形结构节点 & 文档驱动 的XML解析方法
定义了访问 & 操作xml文档元素的方法和接口
- 解析原理

- 具体解析实例
// 假设需要解析的XML文档如下(subject.xml)
<?xml version ="1.0" encoding="UTF-8"?>`
<code>
<language id="1">
<name>Java</name>
<usage>android</usage>
</language>
<language id="2">
<name>Swift#</name>
<usage>ios</usage>
</language>
<language id="3">
<name>Html5</name>
<usage>Web</usage>
</language>
</code>
// 解析的核心代码
public static List<subject> getSubjectList(InputStream stream)
{ tv = (TextView)findViewById(R.id.tv);
try {
//打开xml文件到输入流
InputStream stream = getAssets().open("subject.xml");
//得到 DocumentBuilderFactory 对象
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
//得到DocumentBuilder对象
DocumentBuilder builder = builderFactory.newDocumentBuilder();
//建立Document存放整个xml的Document对象数据
Document document = builder.parse(stream);
//得到 XML数据的"根节点"
Element element = document.getDocumentElement();
//获取根节点的所有language的节点
NodeList list = element.getElementsByTagName("language");
//遍历所有节点
for (int i= 0;i<=list.getLength();i++){
//获取lan的所有子元素
Element language = (Element) list.item(i);
//获取language的属性(这里即为id)并显示
tv.append(lan.getAttribute("id")+"\\n");
//获取language的子元素 name 并显示 tv.append(sub.getElementsByTagName("name").item(0).getTextContent()+"\\n");
//获取language的子元素usage 并显示 tv.append(sub.getElementsByTagName("usage").item(0).getTextContent()+"\\n");
}
- 特点 & 应用场景

6.2 SAX 方式
-
简介
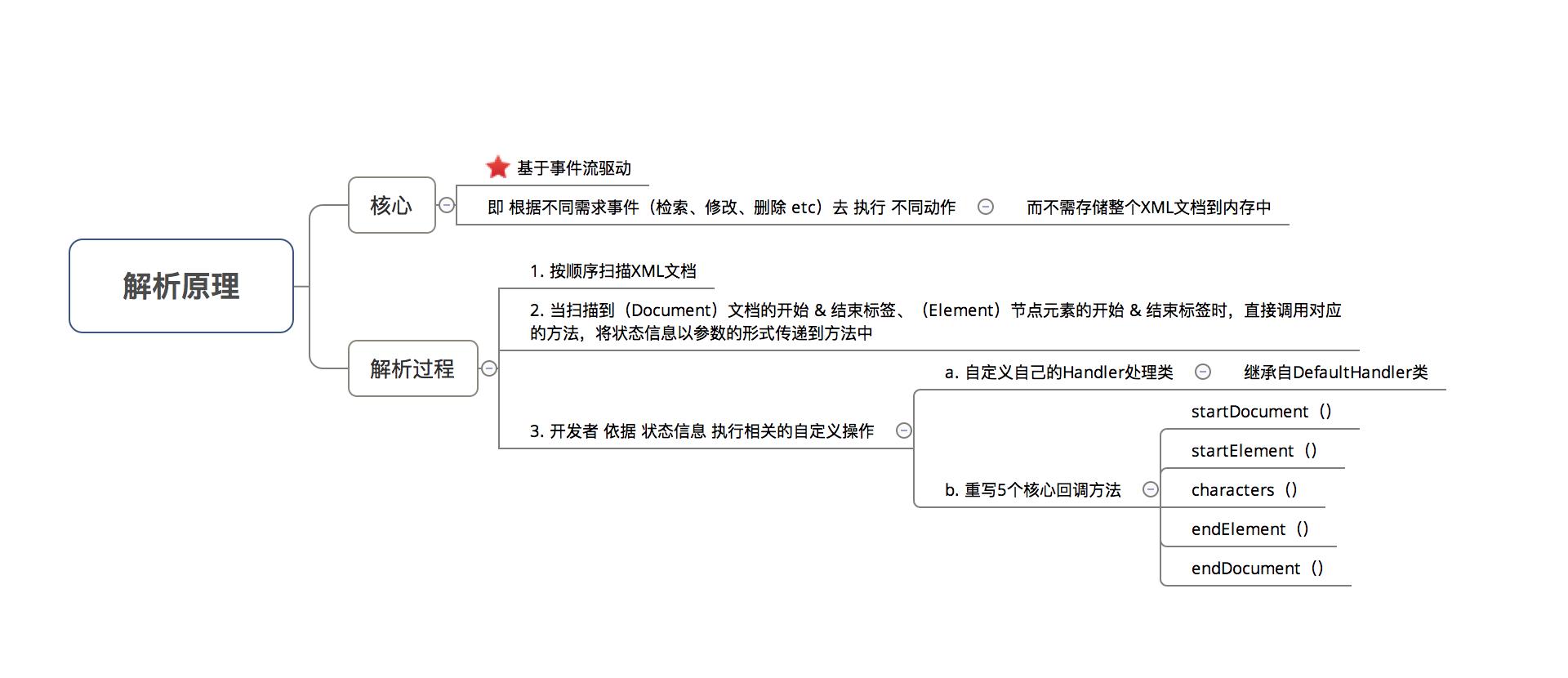
即Simple API for XML,一种 基于事件流驱动、通过接口方法解析 的XML解析方法 -
解析原理
-
解析实例
在使用SAX解析XML文档时,关键在于 自定义自己的Handler处理类 & 复写对应方法
public class MyHandler extends DefaultHandler{
@Override
public void startDocument() throws SAXException{
}
@Override
public void startElement(String uri,String localName,String qName,
Attributes attributes) throws SAXException{
}
@Override
public void characters(char[] ch,int start,int length) throws SAXException{
}
@Override
public void endElement(String uri,String localName,String qName)
throws SAXException{
}
@Override
public void endDocument() throws SAXException{
}
}
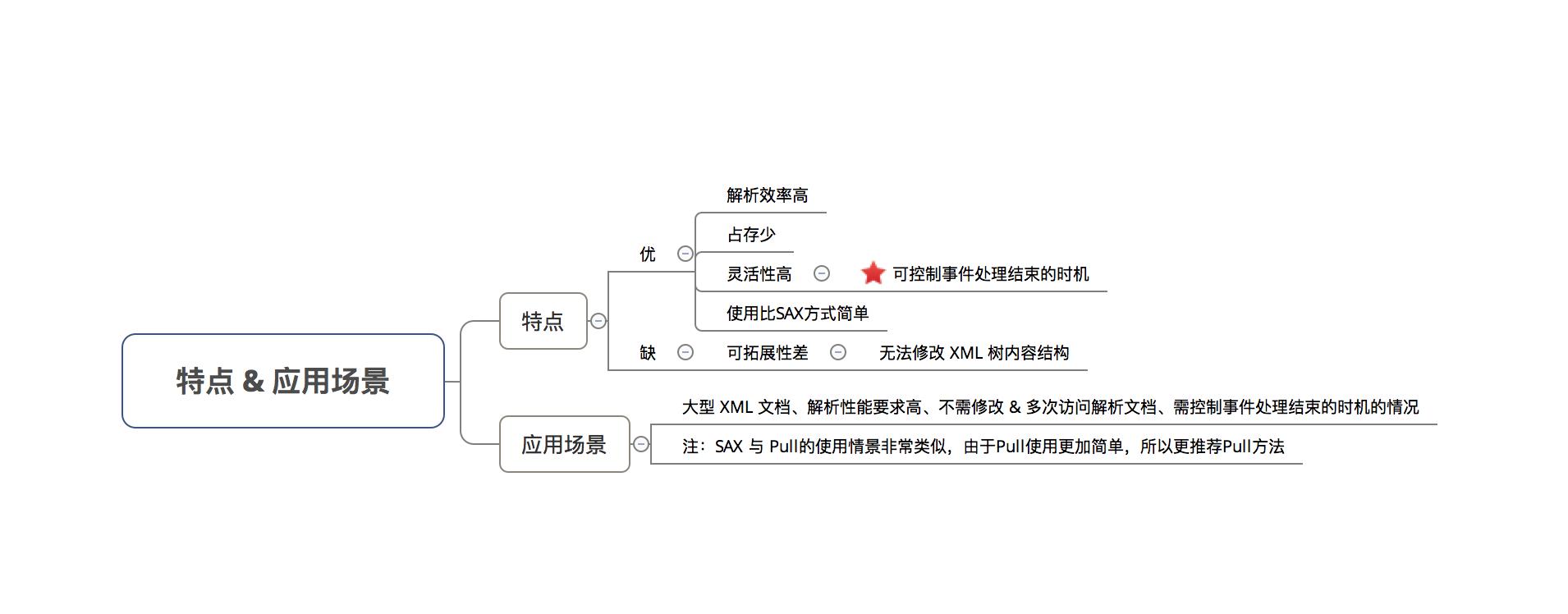
- 特点 & 应用场景

6.3 PULL解析
-
简介
一种 基于事件流驱动 的XML解析方法 -
解析原理

- 解析模板代码
注:
Android中自带了Pull解析的jar包,故不需额外导入第三方jar包
// Pull使用循环解析
XmlPullParserFactory factory = XmlPullParserFactory.newInstance();
XmlPullParser xmlPullParser = factory.newPullParser();
xml.setInput(new StringReader(xmlData));
int eventType = xmlPullParser.getEventType();
while(eventType!=XmlPullParser.END_DOCUMENT){
String nodeName = xmlPullParser.getName();
switch(eventType){
case XmlPullParser.START_DOCUMENT:{}
case XmlPullParser.START_TAG:{}
case XmlPullParser.END_TAG:{}
}
eventType = parser.next();
}
- 解析实例
public class MainActivity extends Activity {
private EditText et;
private Button myButton;
@Override
public void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
myButton = (Button) this.findViewById(R.id.btn01);
et = (EditText) this.findViewById(R.id.edittext01);
myButton.setOnClickListener(new OnClickListener() {
//可变字符序列,比StringBuffer块
StringBuilder sb = new StringBuilder("");
Resources res = getResources();
XmlResourceParser xrp = res.getXml(R.xml.subject);
@Override
public void onClick(View v) {
int counter = 0;
try {
// 判断是否到了文件的结尾
while (xrp.getEventType() != XmlPullParser.END_DOCUMENT) {
//文件的内容的起始标签开始,这里的起始标签是subject.xml文件里面<subjects>标签下面的第一个标签
int eventType=xrp.getEventType();
switch (eventType) {
case XmlPullParser.START_DOCUMENT:
break;
case XmlPullParser.START_TAG:
String tagname = xrp.getName();
if (tagname.endsWith("language")) {
counter++;
sb.append("这是第" + counter + "种语言"+"\\n");
//可以调用XmlPullParser的getAttributte()方法来获取属性的值
sb.append("语言id是:"+xrp.getAttributeValue(0)+"\\n");
}
else if(tagname.equals("name")){
//可以调用XmlPullParser的nextText()方法来获取节点的值
sb.append("语言名称是:"+xrp.nextText()+"\\n");
}
else if(tagname.equals("teacher")){
sb.append("用途是:"+xrp.nextText()+"\\n");
}
break;
case XmlPullParser.END_TAG:
break;
case XmlPullParser.TEXT:
break;
}
//解析下一个事件
xrp.next();
}
//StringBuilder要调用toString()方法并显示
et.setText(sb.toString());
} catch (XmlPullParserException e) {
} catch (IOException e) {
e.printStackTrace();
}
}
});
}
- 特点 & 应用场景
6.4 解析方式对比

7. 总结
- 本文全面介绍了现今主流的数据传输格式
XML,下面用一张图总结XML的主流解析方法

- 关于另外1种主流的数据传输格式
JSON,具体请看:Carson带你学序列化:深入分析JSON多种解析方式(Gson、AS自带org.json、Jackson)
欢迎关注Carson_Ho的CSDN博客
博客链接:https://carsonho.blog.csdn.net/
请帮顶 / 评论点赞!因为你的鼓励是我写作的最大动力!
以上是关于Carson带你学序列化:深入分析XML多种解析方式(DOMSAXPULL)的主要内容,如果未能解决你的问题,请参考以下文章