Jupyter Notebook从入门到精通
Posted 架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Jupyter Notebook从入门到精通相关的知识,希望对你有一定的参考价值。
下载
- 本课程练习完整代码 Jupyter Notebook: https://gist.github.com/zgpeace/8d3eb8c803a54d1ca797fa26cb68bd4c
- 财富500强 csv下载
https://github.com/zgpeace/fortune500.git
1. 什么是 Jupyter 笔记本?
Jupyter Notebook 是一个非常强大的工具,用于交互式开发和展示数据科学项目。本文将带您了解如何将 Jupyter Notebooks 用于数据科学项目,以及如何在您的本地机器上进行设置。
首先,什么是“笔记本”?
笔记本将代码及其输出集成到单个文档中,该文档结合了可视化、叙述性文本、数学方程式和其他富媒体。换句话说:它是一个单一的文档,您可以在其中运行代码、显示输出,还可以添加解释、公式、图表,并使您的工作更加透明、可理解、可重复和可共享。
使用 Notebooks 现在是全球公司数据科学工作流程的主要部分。如果您的目标是处理数据,使用 Notebook 将加快您的工作流程,并使交流和共享结果更容易。
最重要的是,作为开源 项目 Jupyter 的一部分,Jupyter Notebooks 是完全免费的。您可以下载该软件 自身,或作为的一部分Python数据科学工具包。
尽管可以在 Jupyter Notebooks 中使用多种不同的编程语言,但本文将重点介绍 Python,因为它是最常见的用例。(在 R 用户中,R Studio 往往是更受欢迎的选择)。
2. 如何遵循本教程
要从本教程中获得最大收益,您应该熟悉编程——特别是 Python 和Pandas。也就是说,如果您有使用其他语言的经验,本文中的 Python 应该不会太神秘,它仍然会帮助您在本地设置 Jupyter Notebooks。
Jupyter Notebooks 还可以作为一个灵活的平台来处理 Pandas 甚至 Python,这将在本教程中变得明显。
我们会:
- 涵盖安装 Jupyter 和创建您的第一个笔记本的基础知识
- 深入研究并学习所有重要术语
- 探索如何轻松地在线共享和发布笔记本。
(实际上,这篇文章是作为 Jupyter Notebook 编写的!它以只读形式在此处发布,但这是 Notebook 的多功能性的一个很好的例子。事实上,我们的大部分编程教程甚至我们的Python 课程都是创建的使用 Jupyter 笔记本)。
3. Jupyter Notebook 中的数据分析示例
首先,我们将通过设置和示例分析来回答现实生活中的问题。这将展示笔记本的流程如何使我们在工作时以及其他人在分享我们的工作时更直观地完成数据科学任务。
因此,假设您是一名数据分析师,您的任务是找出美国最大公司的利润在历史上是如何变化的。您可以找到自该榜单于 1955 年首次发布以来跨越 50 多年的财富 500 强公司数据集,这些数据集来自 财富的公共档案。我们已经创建了您可以在此处使用的数据的 CSV 文件 。
正如我们将要展示的,Jupyter Notebooks 非常适合这项调查。首先,让我们继续安装 Jupyter。
4. 安装
初学者开始使用 Jupyter Notebooks 的最简单方法是安装 Anaconda。
Anaconda 是数据科学领域使用最广泛的 Python 发行版,并预装了所有最流行的库和工具。
Anaconda 中包含的一些最大的 Python 库包括NumPy、 pandas和 Matplotlib,尽管 完整的 1000+ 列表是详尽无遗的。
因此,Anaconda 让我们可以通过一个储备充足的数据科学研讨会开始运行,而无需管理无数安装或担心依赖项和特定于操作系统(阅读:特定于 Windows)的安装问题。
要获得 Anaconda,只需:
下载适用于 Python 3.8 的最新版本的 Anaconda。
按照下载页面和/或可执行文件中的说明安装 Anaconda。
如果您是已经安装了 Python 的更高级用户并且更喜欢手动管理您的包,您可以使用 pip:
pip3 install jupyter
5. 创建您的第一个笔记本
在本节中,我们将学习运行和保存 notebook,熟悉它们的结构,并了解其界面。我们将熟悉一些核心术语,这些术语将引导您实际了解如何自己使用 Jupyter Notebooks,并为下一节做好准备,该部分将介绍数据分析示例,并将我们在这里学到的一切变为现实。
5.1 运行 Jupyter
在 Windows 上,您可以通过 Anaconda 添加到开始菜单的快捷方式运行 Jupyter,这将在您的默认 Web 浏览器中打开一个新选项卡,该选项卡应类似于以下屏幕截图。
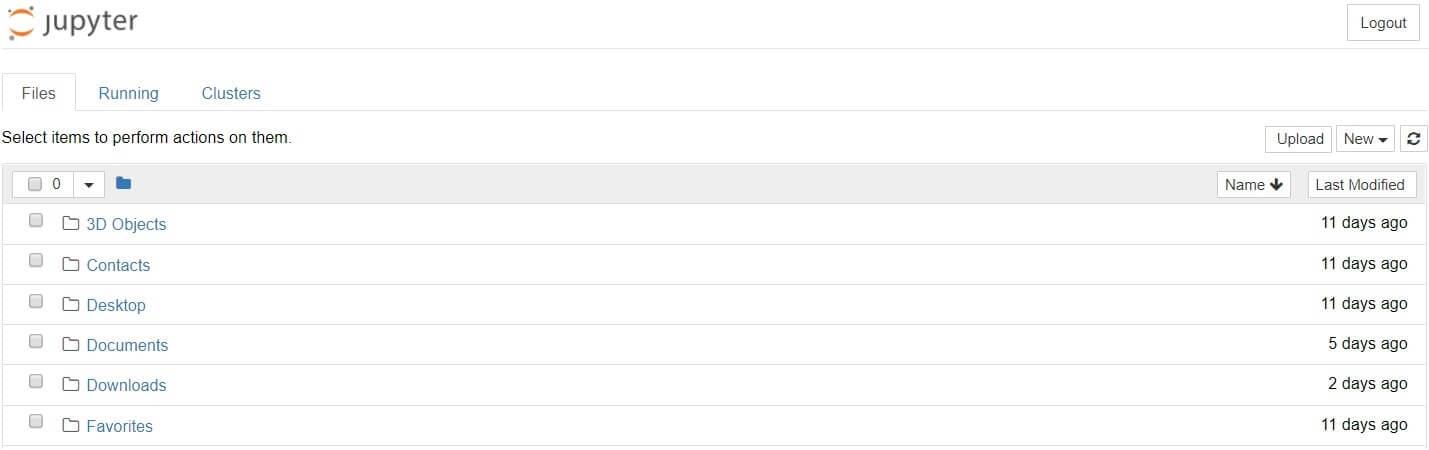
这还不是笔记本,但不要惊慌!没什么可做的。这是笔记本仪表板,专为管理您的 Jupyter 笔记本而设计。将其视为探索、编辑和创建笔记本的启动板。
请注意,仪表板只会让您访问 Jupyter 启动目录(即安装 Jupyter 或 Anaconda 的位置)中包含的文件和子文件夹。但是,可以更改启动目录。
也可以通过输入命令,通过命令提示符(或 Unix 系统上的终端)在任何系统上启动仪表板jupyter notebook;在这种情况下,当前工作目录将是启动目录。
在浏览器中打开 Jupyter Notebook 后,您可能已经注意到仪表板的 URL 类似于https://localhost:8888/tree. Localhost 不是网站,但表示内容是从您的 本地 机器:您自己的计算机提供的。
Jupyter 的 Notebooks 和仪表板是 Web 应用程序,Jupyter 启动本地 Python 服务器以将这些应用程序提供给您的 Web 浏览器,使其基本上独立于平台,并为更轻松地在 Web 上共享打开了大门。
(如果你还不明白这一点,别担心——重要的一点是,虽然 Jupyter Notebooks 在你的浏览器中打开,但它被托管并在你的本地机器上运行。你的笔记本实际上并不在网络上,直到你决定分享它们。)
仪表板的界面大部分都是不言自明的——尽管我们稍后会简单地回到它。那我们还在等什么呢?浏览到您要在其中创建第一个 notebook 的文件夹,单击右上角的“新建”下拉按钮并选择“Python 3”:
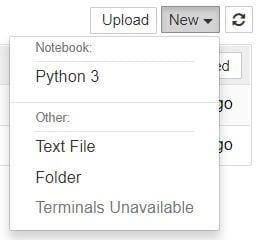
嘿,快,我们来了!您的第一个 Jupyter Notebook 将在新选项卡中打开 - 每个 notebook 使用自己的选项卡,因为您可以同时打开多个 notebook。
如果您切换回仪表板,您将看到新文件,Untitled.ipynb 并且您应该看到一些绿色文本,告诉您笔记本正在运行。
5.2 什么是 ipynb 文件?
简短的回答:每个 .ipynb文件都是一个笔记本,因此每次创建一个新笔记本时,.ipynb都会创建一个新 文件。
更长的答案:每个.ipynb 文件都是一个文本文件,以称为JSON的格式描述笔记本的内容 。每个单元格及其内容(包括已转换为文本字符串的图像附件)与一些元数据一起列在其中 。
你可以自己编辑这个——如果你知道自己在做什么!— 通过从笔记本的菜单栏中选择“编辑 > 编辑笔记本元数据”。您还可以通过从仪表板上的控件中选择“编辑”来查看笔记本文件的内容
但是,这里的关键词是can。在大多数情况下,您没有理由需要手动编辑笔记本元数据。
6. 笔记本界面
现在您面前有一个打开的笔记本,它的界面希望看起来不会完全陌生。毕竟,Jupyter 本质上只是一个高级文字处理器。
为什么不环顾四周?查看菜单以了解它,特别是花一些时间向下滚动命令面板中的命令列表,这是带有键盘图标(或Ctrl + Shift + P)的小按钮。

您应该注意到 两个相当重要的术语,它们可能对您来说是陌生的: 单元 和 内核是理解 Jupyter 以及使其不仅仅是文字处理器的关键。幸运的是,这些概念并不难理解。
- Kernel一个核心是“计算引擎”执行包含笔记本文件中的代码。
- Cell一个细胞是要显示在笔记本或代码文本通过笔记本电脑的内核中执行的容器。
6.1 Cell细胞
稍后我们将回到内核,但首先让我们来处理单元格。细胞构成了笔记本的主体。在上一节中新笔记本的屏幕截图中,带有绿色轮廓的框是一个空单元格。我们将介绍两种主要的细胞类型:
- Code Cell包含在内核中执行的代码。运行代码时,笔记本会在生成它的代码单元格下方显示输出。
- Markdown Cell包含使用格式文本标记符,并显示它的就地输出被运行降价细胞时。
新笔记本中的第一个单元格始终是代码单元格。
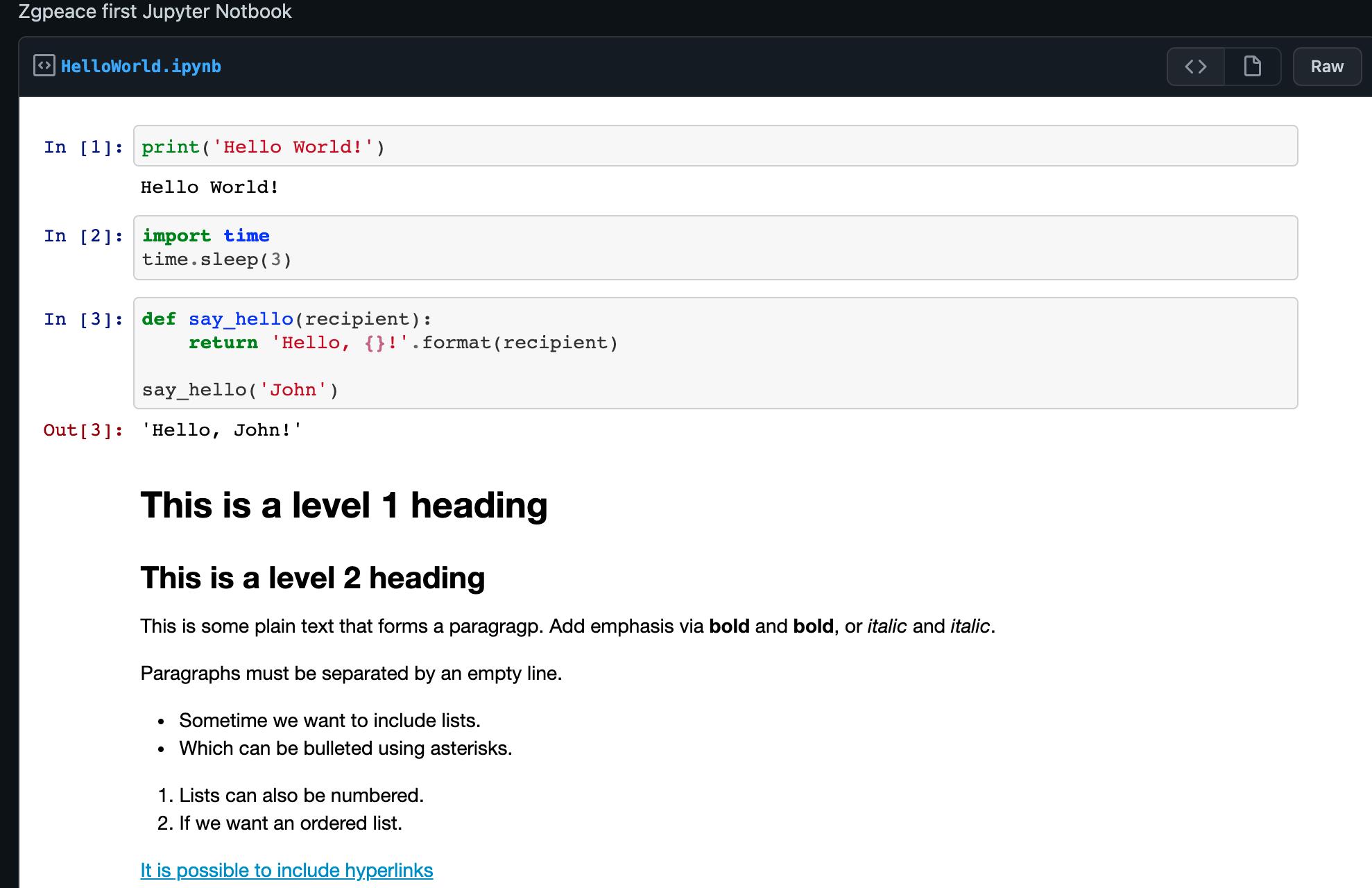
让我们用一个经典的 hello world 示例来测试一下:print('Hello World!') 在单元格中键入并单击笔记本运行按钮
上方工具栏中的运行按钮 或按 Ctrl + Enter。
结果应如下所示:
print('Hello World!')
Hello World!
当我们运行单元格时,它的输出显示在下方,其左侧的标签将从In [ ] 变为 In [1]。
代码单元的输出也构成文档的一部分,这就是您可以在本文中看到它的原因。您始终可以区分代码和 Markdown 单元格之间的区别,因为代码单元格左侧有该标签,而 Markdown 单元格没有。
标签的“以”部分只是短期的“输入”,而在标签的数字表示当将电池上的内核执行-在这种情况下,电池首先执行。
再次运行该单元格,标签将更改为 ,In [2] 因为现在该单元格是在内核上运行的第二个。稍后当我们仔细研究内核时,将更清楚为什么这如此有用。
从菜单栏中,单击“ 插入” 并选择“ 在下方插入单元格” 以在您的第一个下方创建一个新的代码单元格并尝试以下代码以查看会发生什么。你注意到有什么不同吗?
import time
time.sleep(3)
该单元不产生任何输出,但执行需要三秒钟。请注意 Jupyter 如何通过将其标签更改为 来表示单元格当前何时运行In [*]。
通常,单元格的输出来自单元格执行期间专门打印的任何文本数据,以及单元格中最后一行的值,无论是单独的变量、函数调用还是其他内容。例如:
def say_hello(recipient):
return 'Hello, {}!'.format(recipient)
say_hello('Tim')
'Hello, Tim!'
您会发现自己在自己的项目中几乎不断地使用它,我们稍后会看到更多。
7. 键盘快捷键
运行单元格时您可能会观察到的最后一件事是,它们的边框变成蓝色,而在您编辑时它是绿色的。在 Jupyter Notebook 中,总会有一个“活动”单元格突出显示,边框的颜色表示其当前模式:
- 绿色轮廓 — 单元格处于“编辑模式”
- 蓝色轮廓— 单元格处于“命令模式”
那么当单元处于命令模式时我们可以对它做什么呢?到目前为止,我们已经看到了如何使用 运行单元格 Ctrl + Enter,但是我们可以使用许多其他命令。使用它们的最佳方式是使用键盘快捷键
键盘快捷键是 Jupyter 环境中非常流行的一个方面,因为它们促进了基于单元格的快速工作流程。其中许多是您可以在活动单元格处于命令模式时对其执行的操作。
下面是一些 Jupyter 键盘快捷键的列表。您不需要立即记住所有内容,但此列表应该可以让您对可能的内容有一个很好的了解。
- 分别用
Esc和 切换编辑和命令模式Enter。 - 一旦进入命令模式:
☞ 使用Up 和 Down 键上下滚动单元格 。
☞ 按 A 或 B 在活动单元格的上方或下方插入一个新单元格。
☞ M 将活动单元格转换为 Markdown 单元格。
☞ Y 将活动单元格设置为代码单元格。
☞ D + D (D 两次)将删除活动单元格。
☞ Z 将撤销单元格删除。
☞ 按住 Shift ,然后按 Up 或 Down一次选择多个单元格。选择多个单元格后,Shift + M 将合并您的选择。 - Ctrl + Shift + -, 在编辑模式下,将在光标处拆分活动单元格。
- 您还可以单击 Shift + Click 单元格左侧边距中的 和 以选择它们。
继续并在您自己的笔记本中尝试这些。准备好后,创建一个新的 Markdown 单元格,我们将学习如何设置笔记本中文本的格式。
8. Markdown
Markdown是一种轻量级、易于学习的标记语言,用于格式化纯文本。它的语法与 html 标签一一对应,因此这里的一些先验知识会有所帮助,但绝对不是先决条件。
请记住,本文是在 Jupyter notebook 中编写的,因此您目前看到的所有叙述性文本和图像都是用 Markdown 编写的。让我们用一个简单的例子来介绍基础知识:
# This is a level 1 heading
## This is a level 2 heading
This is some plain text that forms a paragraph. Add emphasis via **bold** and __bold__, or *italic* and _italic_.
Paragraphs must be separated by an empty line.
* Sometimes we want to include lists.
* Which can be bulleted using asterisks.
1. Lists can also be numbered.
2. If we want an ordered list.
[It is possible to include hyperlinks](https://www.example.com)
Inline code uses single backticks: `foo()`, and code blocks use triple backticks:
#```
bar()
#```
Or can be indented by 4 spaces:
foo()
And finally, adding images is easy: [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0eTykzf6-1630831530920)(https://www.example.com/image.jpg)]
这是运行单元格渲染后 Markdown 的外观:

附加图像时,您有三个选项:
- 使用指向 Web 图像的 URL。
- 使用本地 URL 指向您将与笔记本一起保存的图像,例如在同一个 git 存储库中。
- 通过“编辑>插入图片”添加附件;这会将图像转换为字符串并将其存储在您的笔记本
.ipynb文件中。请注意,这将使您的.ipynb文件更大!
Markdown 还有很多内容,尤其是在超链接方面,而且还可以简单地包含纯 HTML。一旦您发现自己突破了上述基础知识的极限,您可以 在 Markdown 的创建者 John Gruber 的网站上参考官方指南。
9. Kernel内核
每个笔记本背后都有一个内核。当您运行代码单元时,该代码将在内核中执行。任何输出都返回到要显示的单元格。内核的状态随着时间和单元格之间持续存在——它与整个文档有关,而不是单个单元格。
例如,如果您在一个单元格中导入库或声明变量,它们将在另一个单元格中可用。让我们尝试一下,感受一下。首先,我们将导入一个 Python 包并定义一个函数:
import numpy as np
def square(x):
return x * x
一旦我们执行了上面的单元格,我们就可以在任何其他单元格中引用np 和 square。
x = np.random.randint(1, 10)
y = square(x)
print('%d squared is %d' % (x, y))
1 squared is 1
无论笔记本中单元格的顺序如何,这都将起作用。只要一个单元已经运行,您声明的任何变量或您导入的库都将在其他单元中可用。
你可以自己试试,让我们再次打印出我们的变量。
print('Is %d squared %d?' % (x, y))
Is 1 squared 1?
这里没有惊喜!但是如果我们改变值会发生什么 y?
y = 10
print('Is %d squared is %d?' % (x, y))
如果我们运行上面的单元格,你认为会发生什么?
我们将得到一个输出,如: Is 4 squared 10?。这是因为一旦我们运行了 y = 10代码单元,y就不再等于内核中 x 的平方。
大多数情况下,当您创建笔记本时,流程是自上而下的。但是返回进行更改是很常见的。当我们确实需要对较早的单元格进行更改时,我们可以在每个单元格的左侧看到的执行顺序,例如In [6],可以通过查看单元格运行的顺序来帮助我们诊断问题。
如果我们想重置一些东西,内核菜单中有几个非常有用的选项:
- 重新启动:重新启动内核,从而清除所有定义的变量等。
- 重新启动和清除输出:与上述相同,但也会清除代码单元格下方显示的输出。
- 重新启动并运行所有:与上面相同,但也会从头到尾运行所有单元格。
如果您的内核曾经卡在计算上并且您希望停止它,您可以选择中断选项。
9.1 选择内核 Kernel
您可能已经注意到 Jupyter 为您提供了更改内核的选项,实际上有许多不同的选项可供选择。当您通过选择 Python 版本从仪表板创建新笔记本时,您实际上是在选择要使用的内核。
有适用于不同版本 Python 的内核,也适用于 100 多种语言, 包括 Java、C 甚至 Fortran。数据科学家可能对R 和 Julia的内核以及 用于 Matlab 的imatlab 和 Calysto MATLAB 内核特别感兴趣 。
SoS内核 提供了一个单一的笔记本电脑中的多语言支持。
每个内核都有自己的安装说明,但可能需要您在计算机上运行一些命令。
10. 示例分析
现在我们已经 了解 了 Jupyter Notebook 是什么,是时候看看 它们在实践中是如何使用的,这应该能让我们更清楚地了解 它们为何如此受欢迎。
现在终于可以开始使用前面提到的财富 500 强数据集了。请记住,我们的目标是了解美国最大公司的利润在历史上是如何变化的。
值得注意的是,每个人都会发展自己的喜好和风格,但一般原则仍然适用。如果愿意,您可以在自己的笔记本中遵循此部分,或者将其用作创建自己方法的指南。
10.1 命名你的笔记本
在开始编写项目之前,您可能想给它一个有意义的名称。文件名Untitled在左上角的屏幕,进入一个新的文件名,并点击保存图标(看起来像一个软盘)以下,以节省。
请注意,在浏览器中关闭笔记本选项卡不会像在传统应用程序中关闭文档那样“关闭”笔记本。Notebook 的内核将继续在后台运行,需要在它真正“关闭”之前关闭——尽管如果您不小心关闭了选项卡或浏览器,这非常方便!
如果内核关闭,您可以关闭选项卡而不必担心它是否仍在运行。
最简单的方法是从笔记本菜单中选择“文件 > 关闭并暂停”。但是,您也可以通过从 notebook 应用程序中转到“Kernel > Shutdown”或通过在仪表板中选择 notebook 并单击“Shutdown”(见下图)来关闭内核。

10.2 设置
通常从专门用于导入和设置的代码单元开始,这样如果您选择添加或更改任何内容,您可以简单地编辑和重新运行该单元,而不会产生任何副作用。
%matplotlib inline
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns sns.set(style="darkgrid")
我们将导入pandas 来处理我们的数据, 导入 Matplotlib 来绘制图表,并 导入Seaborn 使我们的图表更漂亮。导入NumPy也很常见, 但在这种情况下,pandas 会为我们导入它。
第一行不是 Python 命令,而是使用一种称为 line magic 的东西来指示 Jupyter 捕获 Matplotlib 图并在单元格输出中呈现它们。稍后我们将更多地讨论线条魔术,我们的高级 Jupyter Notebooks 教程 中也介绍了它们。
现在,让我们继续加载我们的数据。
df = pd.read_csv('fortune500.csv')
在单个单元格中也这样做是明智的,以防我们需要在任何时候重新加载它。
10.3 保存和检查点
现在我们已经开始了,最好的做法是定期保存。按下 Ctrl + S将通过调用“保存和检查点”命令来保存我们的笔记本,但是这个检查点是什么?
每次我们创建一个新的 notebook 时,都会与 notebook 文件一起创建一个检查点文件。它位于您的保存位置的隐藏子目录中.ipynb_checkpoints ,它也是一个 .ipynb 文件。
默认情况下,Jupyter 会每 120 秒自动将您的笔记本保存到此检查点文件中,而不会更改您的主要笔记本文件。当您“保存并检查点”时,笔记本和检查点文件都会更新。因此,检查点使您能够在出现意外问题时恢复未保存的工作。
您可以通过“文件 > 恢复到检查点”从菜单恢复到检查点。
11. 调查我们的数据集
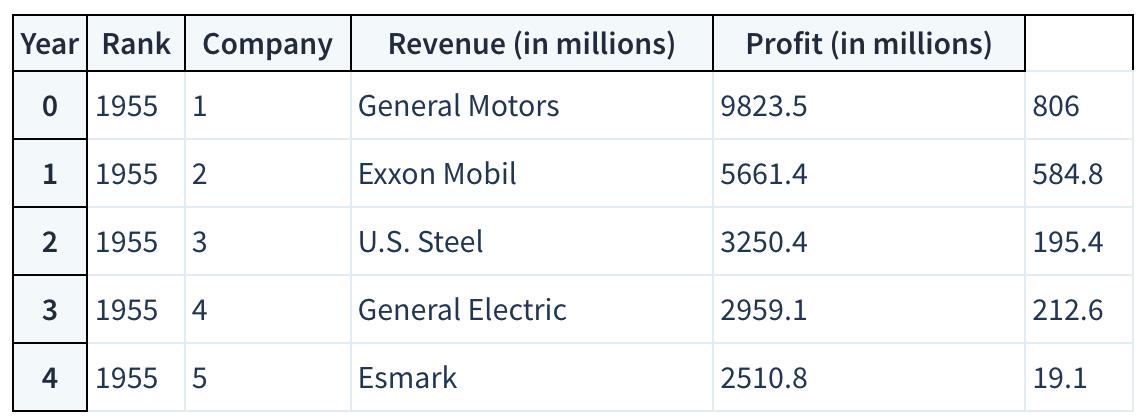
现在我们真的在沸腾!我们的 notebook 已安全保存,我们已将数据集加载 df 到最常用的 Pandas 数据结构中,该结构称为 a DataFrame ,基本上看起来像一张表。我们的是什么样子的?
df.head()
df.tail()
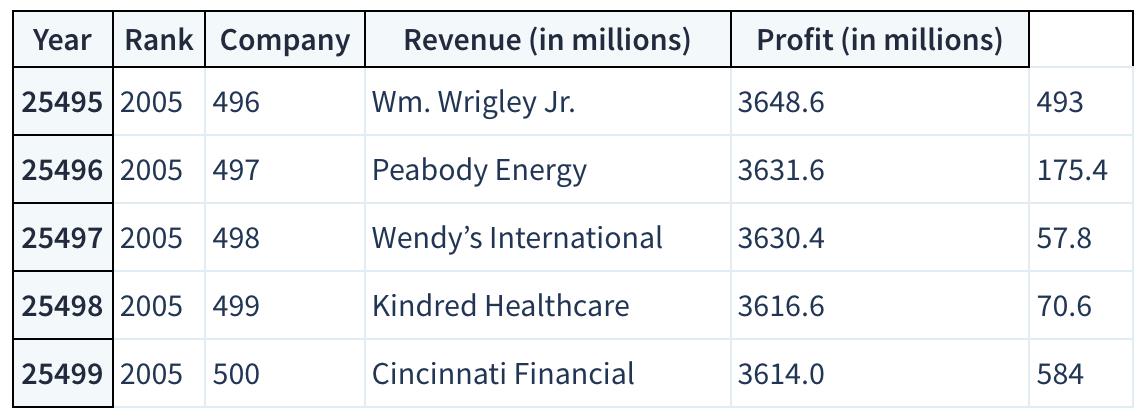
看起来不错。我们有我们需要的列,每一行对应于一年中的一家公司。
让我们重命名这些列,以便我们以后可以参考它们。
df.columns = ['year', 'rank', 'company', 'revenue', 'profit']
接下来,我们需要探索我们的数据集。是否完整?熊猫是否按预期阅读?是否缺少任何值?
len(df)
25500
好的,这看起来不错——从 1955 年到 2005 年,每年有 500 行,包括在内。
让我们检查我们的数据集是否已按预期导入。一个简单的检查是查看数据类型(或 dtypes)是否已被正确解释。
df.dtypes
year int64
rank int64
company object
revenue float64
profit object
dtype: object
哦哦。看起来利润栏有问题——我们希望它 float64 像收入栏一样。这表明它可能包含一些非整数值,所以让我们看一下。
non_numberic_profits = df.profit.str.contains('[^0-9.-]')
df.loc[non_numberic_profits].head()
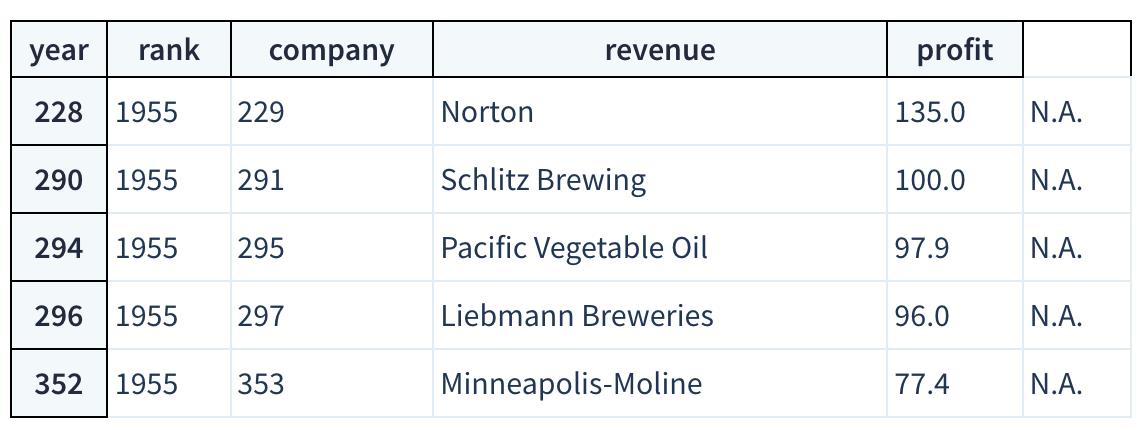
正如我们所怀疑的!一些值是字符串,用于指示缺失数据。是否有任何其他价值观已经悄然渗入?
set(df.profit[non_numberic_profits])
{'N.A.'}
这很容易解释,但我们应该怎么做?嗯,这取决于缺少多少值。
len(df.profit[non_numberic_profits])
369
这只是我们数据集的一小部分,但并非完全无关紧要,因为它仍然在 1.5% 左右。
如果包含N.A. 的行在这些年中大致均匀分布,那么最简单的解决方案就是删除它们。所以让我们快速看一下分布。
bin_sizes, _, _ = plt.hist(df.year[non_numberic_profits], bins=range(1955, 2006))
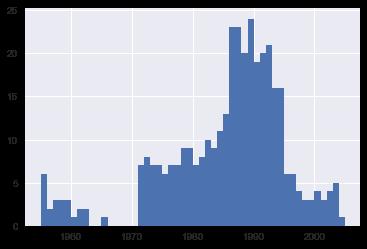
一目了然,我们可以看到,一年中最无效的值少于25个,并且由于每年有500个数据点,删除这些值将占最差年份数据的不到4%。事实上,除了 90 年代左右的激增之外,大多数年份的缺失值都不到峰值的一半。
出于我们的目的,假设这是可以接受的,然后继续删除这些行。
df = df.loc[~non_numberic_profits]
df.profit = df.profit.apply(pd.to_numeric)
我们应该检查是否有效。
len(df)
25131
df.dtypes
year int64
rank int64
company object
revenue float64
profit float64
dtype: object
太好了!我们已经完成了我们的数据集设置。
如果我们要将您的笔记本作为报告呈现,我们可以去掉我们创建的调查单元,这些单元包含在此处作为使用笔记本工作流程的演示,并合并相关单元(请参阅下面的高级功能部分以了解更多关于这个)来创建一个单一的数据集设置单元。
这意味着如果我们在其他地方弄乱了我们的数据集,我们可以重新运行设置单元来恢复它。
12. 使用 matplotlib 绘图
接下来,我们可以通过绘制每年的平均利润来解决手头的问题。我们不妨也绘制收入,所以首先我们可以定义一些变量和一种方法来减少我们的代码。
group_by_year = df.loc[:, ['year', 'revenue', 'profit']].groupby('year')
avgs = group_by_year.mean()
x = avgs.index
y1 = avgs.profit
def plot(x, y, ax, title, y_label):
ax.set_title(title)
ax.set_ylabel(y_label)
ax.plot(x, y)
ax.margins(x=0, y=0)
现在让我们来策划吧!
fig, ax = plt.subplots()
plot(x, y1, ax, 'Increase in mean Fortune 500 company profits from 1955 to 2005', 'Profit (millions)')
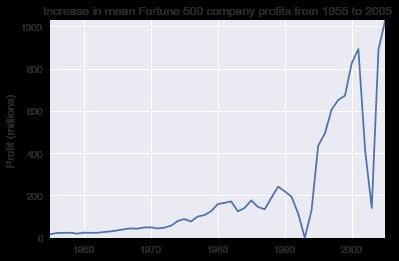
哇,这看起来像一个指数,但它有一些巨大的下降。它们必须对应 1990 年代初期的经济衰退 和 互联网泡沫。在数据中看到这一点非常有趣。但是,为什么每次经济衰退后利润都恢复到更高的水平呢?
也许收入可以告诉我们更多。
y2 = avgs.revenue
fig, ax = plt.subplots()
plot(x, y2, ax, 'Increase in mean Fortune 500 company revenues from 1955 to 2005', 'Revenue (millions)')
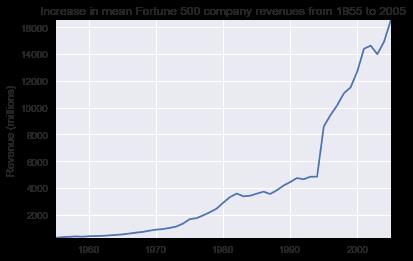
这增加了故事的另一面。收入没有受到那么严重的打击——这是财务部门的一些出色的会计工作。
在Stack Overflow 的帮助下 ,我们可以将这些图与 +/- 的标准偏差叠加在一起。
def plot_with_std(x, y, stds, ax, title, y_label):
ax.fill_between(x, y - stds, y + stds, alpha=0.2)
plot(x, y, ax, title, y_label)
fig, (ax1, ax2) = plt.subplots(ncols=2)
title = 'Increase in mean and std Fortune 500 company %s from 1955 to 2005'
stds1 = group_by_year.std().profit.values
stds2 = group_by_year.std().revenue.values
plot_with_std(x, y1.values, stds1, ax1, title % 'profits', 'Profit (millions)')
plot_with_std(x, y2.values, stds2, ax2, title % 'revenues', 'Revenue (millions)')
fig.set_size_inches(14, 4)
fig.tight_layout()
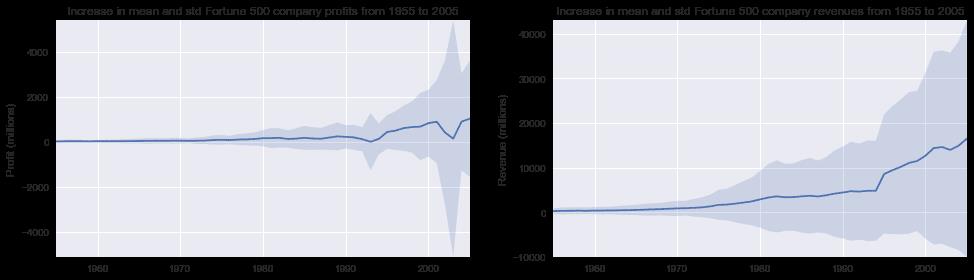
这是惊人的,标准偏差是巨大的!一些财富500强公司赚了数十亿,而另一些则亏损了数十亿,而且这些年来风险随着利润的增加而增加。
也许有些公司的表现比其他公司好;顶部 10% 的利润比底部 10% 的波动更大还是更小?
接下来我们可以研究很多问题,很容易看出在笔记本中工作的流程如何与自己的思维过程相匹配。出于本教程的目的,我们将在此停止分析,但您可以继续自己挖掘数据!
这个流程帮助我们在一个地方轻松调查我们的数据集,而无需在应用程序之间切换上下文,我们的工作可以立即共享和重现。如果我们希望为特定受众创建更简洁的报告,我们可以通过合并单元格和删除中间代码来快速重构我们的工作。
13. 共享您的笔记本
当人们谈论共享他们的笔记本时,他们通常会考虑两种范式。
大多数情况下,个人分享他们工作的最终结果,就像这篇文章本身一样,这意味着分享他们笔记本的非交互式、预渲染版本。但是,也可以借助Git等版本控制系统或Google Colab等在线平台在 notebook 上进行协作。
13.1 分享之前
共享笔记本将完全以其导出或保存时的状态显示,包括任何代码单元的输出。因此,为了确保您的笔记本已准备好共享,可以这么说,在共享之前您应该采取以下几个步骤:
- 单击“单元格>所有输出>清除”
- 单击“内核>重新启动并运行所有”
- 等待您的代码单元完成执行并检查按预期运行
这将确保您的笔记本不包含中间输出,具有陈旧状态,并在共享时按顺序执行。
13.2 GitHub
到 2018 年初,GitHub 上的公共笔记本数量超过 180 万,无疑是最流行的与世界共享 Jupyter 项目的独立平台。GitHub.ipynb 在其网站上的存储库和 gist 中直接集成了对渲染文件的支持 。如果您还不知道, GitHub 是一个代码托管平台,用于对使用Git创建的存储库进行版本控制和协作 。您需要一个帐户才能使用他们的服务,但标准帐户是免费的。
拥有 GitHub 帐户后,在 GitHub 上共享笔记本的最简单方法实际上根本不需要 Git。自 2008 年以来,GitHub 提供了用于托管和共享代码片段的 Gist 服务,每个代码片段都有自己的存储库。要使用 Gists 共享笔记本:
- 登录并导航到gist.github.com。
.ipynb在文本编辑器中打开您的 文件,全选并复制其中的 JSON。- 将笔记本 JSON 粘贴到要点中。
- 给你的 Gist 一个文件名,记得添加, .iypnb 否则这将不起作用。
- 单击“创建秘密要点”或“创建公共要点”。
这应该类似于以下内容:
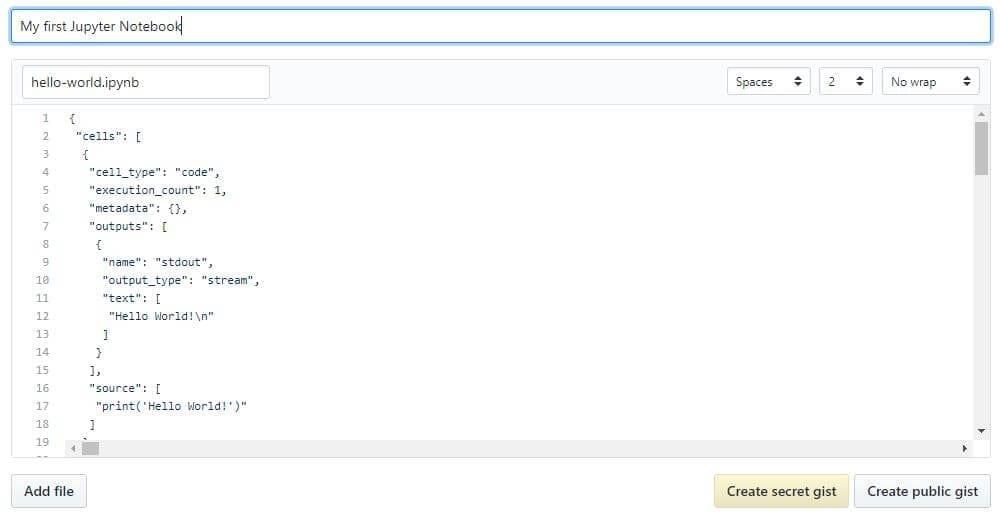
如果您创建了一个公共 Gist,您现在可以与任何人共享其 URL,其他人将能够 分叉和克隆 您的工作。
创建您自己的 Git 存储库并在 GitHub 上共享它超出了本教程的范围,但 GitHub 提供了大量指南 供您自行开始。
一个额外的小费使用Git的是 一个例外添加 到你 .gitignore 的那些隐藏 .ipynb_checkpoints 关卡文件的目录Jupyter创建,以免不必要的承诺你的回购协议。
14. NBViewer
到 2015 年,NBViewer已经发展到每周渲染 数十万个笔记本,是网络上最受欢迎的笔记本渲染器。如果您已经在某个地方在线托管您的 Jupyter Notebook,无论是 GitHub 还是其他地方,NBViewer 都会呈现您的笔记本并提供一个可共享的 URL。它作为 Project Jupyter 的一部分作为免费服务提供,可在 nbviewer.jupyter.org 上获得。
NBViewer 最初是在 GitHub 的 Jupyter Notebook 集成之前开发的,它允许任何人输入 URL、Gist ID 或 GitHub 用户名/repo/文件,并将笔记本呈现为网页。Gist 的 ID 是其 URL 末尾的唯一编号;例如,中最后一个反斜杠后的字符串 https://gist.github.com/zgpeace/8d3eb8c803a54d1ca797fa26cb68bd4c。如果您输入 GitHub 用户名或用户名/存储库,您将看到一个最小的文件浏览器,可让您浏览用户的存储库及其内容。
显示笔记本时显示的 URL NBViewer 是基于它正在呈现的笔记本的 URL 的常量,因此您可以与任何人共享它,只要原始文件保持在线,它就会工作 - NBViewer 不会缓存文件长。
15. 附加功能:Jupyter Notebook 扩展
我们已经涵盖了在 Jupyter Notebooks 中运行所需的一切。
15.1 什么是扩展?
扩展正是它们听起来的样子——扩展 Jupyter Notebooks 功能的附加功能。虽然基本的 Jupyter Notebook 可以做很多事情,但扩展提供了一些额外的功能,可能有助于特定的工作流程,或者只是改善用户体验。
例如,一个名为"Table of Contents"“目录”的扩展为您的笔记本生成一个目录,以使大型笔记本更易于可视化和导航。
另一个称为 Variable Inspector变量检查器,将向您显示笔记本中每个变量的值、类型、大小和形状,以便于快速参考和调试。
另一个名为 ExecuteTime 的函数可让您知道每个单元格运行的时间和时间——如果您想加快代码片段的速度,这会特别方便。
这些只是冰山一角;有许多扩展可用。
15.2 在哪里可以获得扩展?
要获得扩展,您需要安装 Nbextensions。您可以使用 pip 和命令行执行此操作。如果您有 Anaconda,最好通过 Anaconda Prompt 而不是常规命令行来执行此操作。
关闭 Jupyter Notebooks,打开 Anaconda Prompt,然后运行以下命令:
pip3 install jupyter_contrib_nbextensions && jupyter contrib nbextension install
完成后,启动笔记本,您应该会看到一个 Nbextensions 选项卡。单击此选项卡将显示可用扩展的列表。只需勾选您想要启用的扩展的方框,您就可以开始比赛了!
15.3 安装扩展
一旦安装了 Nbextensions 本身,就不需要额外安装每个扩展。但是,如果您已经安装了 Nbextensons 但没有看到该选项卡,那么您并不孤单。Github 上的这个帖子详细介绍了一些常见问题和解决方案。
16. 附加:Jupyter 中的 Line Magics
之前我们%matplotlib inline在 Notebook 中制作 Matplotlib 图表时提到了魔法命令。我们也可以使用许多其他魔法。
16.1 如何在 Jupyter 中使用魔法
一个好的第一步是打开一个 Jupyter Notebook,%lsmagic在一个单元格中输入,然后运行该单元格。这将输出可用的行魔法和单元格魔法的列表,它还会告诉你是否打开了“自动魔法”。
- 行魔术在代码单元的单行上运行
- 单元魔术对调用它们的整个代码单元进行操作
如果 automagic 处于打开状态,您只需在代码单元格中自己的一行中键入它,然后运行该单元格即可运行魔法。如果它关闭,您将需要 %在行魔法%% 之前和 单元魔法之前使用它们。
许多魔法需要额外的输入(很像一个函数需要一个参数)来告诉它们如何操作。我们将在下一节中查看一个示例,但是您可以通过使用问号运行它来查看任何魔法的文档,如下所示:
%matplotlib?
当您在笔记本中运行上述单元格时,屏幕上会弹出一个冗长的文档字符串,其中包含有关如何使用魔法的详细信息。
16.2 一些有用的魔法命令
我们在高级 Jupyter 教程中介绍了更多内容,但这里有一些可以帮助您入门:
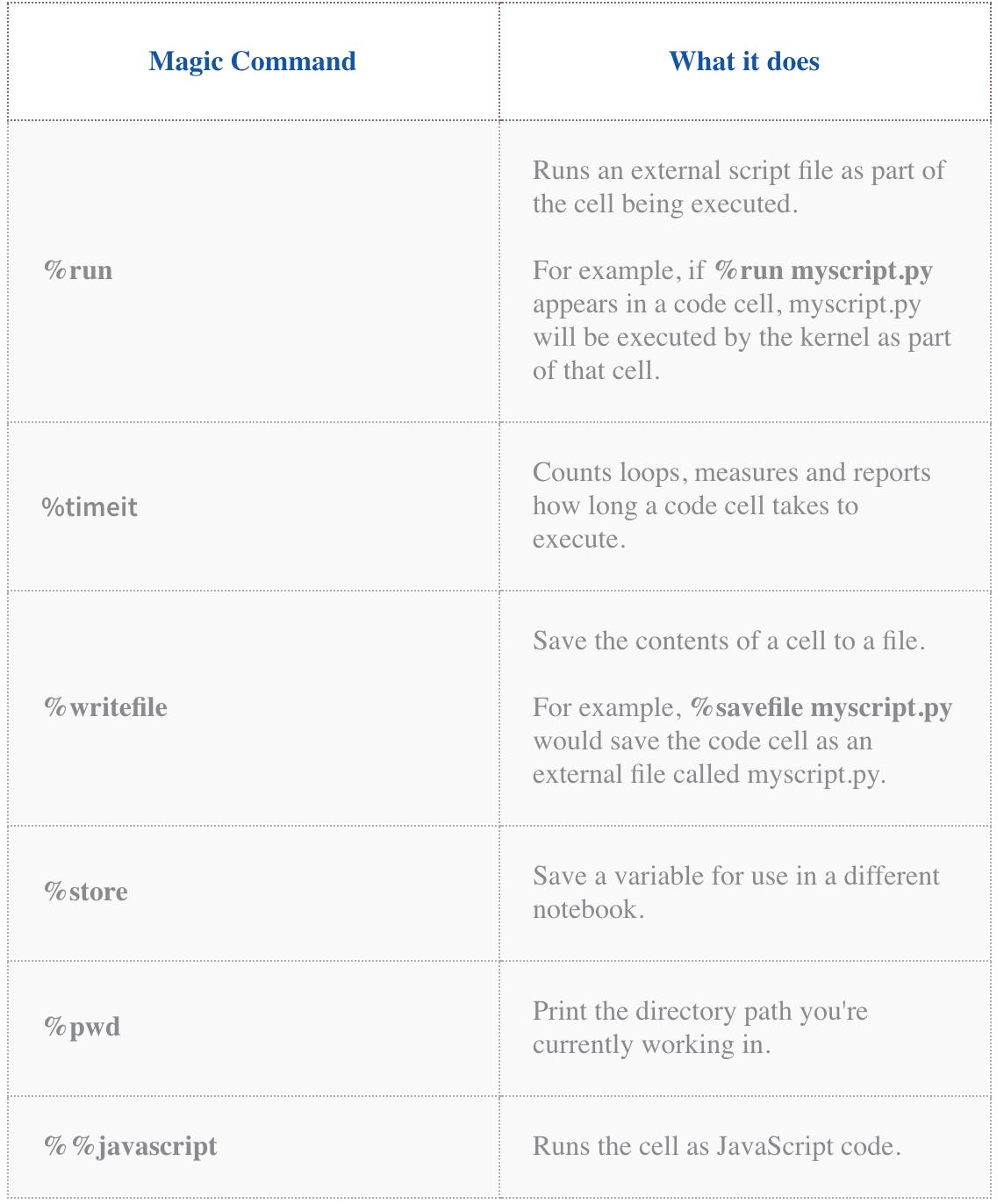
还有很多来自哪里。跳入 Jupyter Notebooks 并开始使用%lsmagic
17. 最后的想法
从头开始,我们已经掌握了 Jupyter Notebooks 的自然工作流程,深入研究了 IPython 更高级的功能,最终学会了如何与朋友、同事和世界分享我们的工作。我们通过笔记本本身完成了这一切!
应该清楚笔记本如何通过减少上下文切换和模拟项目期间思想的自然发展来促进富有成效的工作体验。使用 Jupyter Notebooks 的强大功能也应该是显而易见的,我们涵盖了大量线索,以帮助您开始在自己的项目中探索更高级的功能。
如果您想为自己的笔记本获得更多灵感,Jupyter 已经整理了 一个有趣的 Jupyter 笔记本图库 ,您可能会发现它们对您有所帮助,并且 Nbviewer 主页 链接到一些非常精美的优质笔记本示例。
18. 更多优秀的 Jupyter Notebooks 资源
- 高级 Jupyter Notebooks 教程 – 现在您已经掌握了基础知识,通过这个高级教程成为 Jupyter Notebooks 专家!
- 28 个 Jupyter Notebook 提示、技巧和快捷方式 – 通过这些提示和技巧让自己成为超级用户并提高效率!
- 指导项目 – 安装和学习 Jupyter Notebooks – 通过完成这个交互式指导项目,为自己使用 Jupyter Notebooks 打下良好的基础,该项目将帮助您进行设置并教您掌握技巧。
参考
https://www.dataquest.io/blog/jupyter-notebook-tutorial/
以上是关于Jupyter Notebook从入门到精通的主要内容,如果未能解决你的问题,请参考以下文章