Apache Spark:SparkSQL的使用
Posted 你是小KS
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Apache Spark:SparkSQL的使用相关的知识,希望对你有一定的参考价值。
当前版本:spark2.4.6
1. 声明
当前内容主要用于本人学习和记录学习SparkSQL的内容,当前内容借鉴Spark官方文档
当前内容包括以下
- 创建SparkSession
- 从text文件、csv文件、集合中创建dataset
- 使用dataset实现sql操作
- 从mysql中拉取表进行内连接查询操作
pom依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.6</version>
<scope>provided</scope>
<!-- tried to access method com.google.common.base.Stopwatch.<init>()V
from class org.apache.hadoop.mapred.FileInputFormat 使用低版本的可以解决问题 -->
<exclusions>
<exclusion>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>15.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.6</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.13</version>
</dependency>
</dependencies>
准备一个类用于转换
public static class User{
private int id;
private String name;
// 省略get,set,toString 方法,无参有参等构造函数
}
2. 创建SparkSession
private static SparkSession createSparkSession() {
// 第一种使用sparkContext创建SparkSession
SparkConf config=new SparkConf().setMaster("local").setAppName("spark sql test");
SparkContext sparkContext=new SparkContext(config);
sparkContext.setLogLevel("ERROR");
SparkSession sparkSession=new SparkSession(sparkContext);
// 2. 使用sparkSession中的builder创建
//SparkSession sparkSession = SparkSession.builder().master("local").appName("spark sql test").getOrCreate();
return sparkSession;
}
主要有两种,一个是手动创建new SparkSession注入SparkContext,一种是使用SparkSession的builder进行创建,这里设置日志打印级别为ERROR
3. 从集合中创建Dataset并执行SQL操作
/**
*
* @author hy
* @createTime 2021-09-04 09:02:23
* @description 从集合中加载数据到当前的dataset中并执行数据打印的操作
* @param sparkSession
*
*/
private static void loadFromCollection(SparkSession sparkSession) {
List<User> users=Arrays.asList(new User(1,"admin"),new User(2,"guest"));
Dataset<Row> userDataFrame = sparkSession.createDataFrame(users, User.class);
userDataFrame.printSchema();
userDataFrame.show();
}
执行结果
root
|-- id: integer (nullable = false)
|-- name: string (nullable = true)
+---+-----+
| id| name|
+---+-----+
| 1|admin|
| 2|guest|
+---+-----+
4. 从text文件中创建Dataset并执行SQL操作
准备user.txt文件,内容如下

/**
*
* @author hy
* @createTime 2021-09-04 09:38:53
* @description 从文本文件中加载数据集并执行sql操作
* @param sparkSession
*
*/
private static void loadFromTxtFile(SparkSession sparkSession) {
JavaRDD<User> map = sparkSession.read().textFile("C:\\\\Users\\\\admin\\\\Desktop\\\\users.txt")
.toJavaRDD()
.map(new Function<String, User>() {
@Override
public User call(String v1) throws Exception {
// TODO Auto-generated method stub
String[] split = v1.split(",");
return new User(Integer.valueOf(split[0]), split[1]);
}
});
Dataset<Row> userDataFrame = sparkSession.createDataFrame(map, User.class).cache();// 缓存数据,这样别名处理才有作用
userDataFrame.printSchema();
String[] columns = userDataFrame.columns();
System.out.println("当前的列明为:"+Arrays.toString(columns));
userDataFrame.show();
long count = userDataFrame.count();
System.out.println("当前的数量为:"+count);
System.out.println("按照名称聚合的结果如下:");
//按照名称进行统计聚合,并显示
userDataFrame.groupBy("name").count().show();
System.out.println("按照id进行降序排列的结果如下:");
// 按照当前id进行降序排列
userDataFrame.orderBy(new Column("id").desc()).show();
System.out.println("条件查询结果如下:");
// 执行查询操作
userDataFrame.where("id>1 and name='guest'").show();
// 上面的条件查询等价于下面的,默认使用and,并且使用字符串查询的时候需要加单引号
// userDataFrame.where("id>1").where("name='guest'").show();
System.out.println("别名处理和查询结果如下:");
Dataset<Row> alias = userDataFrame.as("u1").cache();
// 使用sql方式查询数据(可以正常执行)
alias.select("u1.id","u1.name").where("u1.id>1").show();
// 查询字段的时候讲name做出别名处理现实loginName
alias.select(new Column("id"),new Column("name").as("loginName")).show();
// 使用sqlContext的sql方式好像有问题:不能直接使用,必须注册表
// alias.sqlContext().sql("select u1.id,u1.name from u1 where u1.id>1").show(); 错误必须注册dataset并设置注册的名称
SQLContext sqlContext = alias.sqlContext();
sqlContext.registerDataFrameAsTable(alias, "u1");
sqlContext.sql("select u1.id,u1.name from u1 where u1.id>1").show();
}
执行结果:
root
|-- id: integer (nullable = false)
|-- name: string (nullable = true)
当前的列明为:[id, name]
+---+-----+
| id| name|
+---+-----+
| 1|admin|
| 2|guest|
| 3| user|
+---+-----+
当前的数量为:3
按照名称聚合的结果如下:
+-----+-----+
| name|count|
+-----+-----+
| user| 1|
|admin| 1|
|guest| 1|
+-----+-----+
按照id进行降序排列的结果如下:
+---+-----+
| id| name|
+---+-----+
| 3| user|
| 2|guest|
| 1|admin|
+---+-----+
条件查询结果如下:
+---+-----+
| id| name|
+---+-----+
| 2|guest|
+---+-----+
别名处理和查询结果如下:
+---+-----+
| id| name|
+---+-----+
| 2|guest|
| 3| user|
+---+-----+
+---+---------+
| id|loginName|
+---+---------+
| 1| admin|
| 2| guest|
| 3| user|
+---+---------+
+---+-----+
| id| name|
+---+-----+
| 2|guest|
| 3| user|
+---+-----+
5. 从csv文件中创建Dataset
准备users.csv文件,内容如下
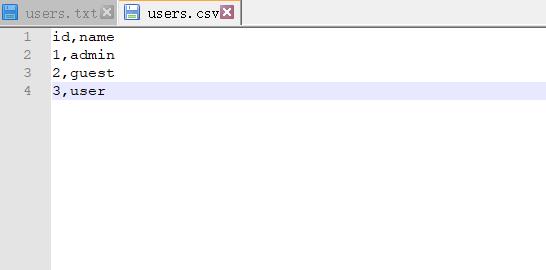
private static void loadFromCsvFile(SparkSession sparkSession) {
Dataset<Row> usersCsv = sparkSession.read().format("csv")
.option("sep", ",") //解析默认的分隔符
.option("inferSchema", "true") // 将头转换为schema
.option("header", "true") // 使用头
.load("C:\\\\Users\\\\admin\\\\Desktop\\\\users.csv");
usersCsv.show();
}
执行结果:
+---+-----+
| id| name|
+---+-----+
| 1|admin|
| 2|guest|
| 3| user|
+---+-----+
6. 从mysql中创建Dataset并实现连表查询
首先准备两张表(t_user,t_class)



/**
*
* @author hy
* @createTime 2021-09-04 09:36:01
* @description 使用内连接查询
* @param reader
*
*/
private static void unionOption(SparkSession sparkSession) {
DataFrameReader reader = sparkSession.read().format("jdbc")
.option("driver","com.mysql.cj.jdbc.Driver")
.option("url", "jdbc:mysql://localhost:3306/flink_test?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8")
.option("user", "root")
.option("password", "root");
// 加载t_user表中的全部数据
Dataset<Row> students = reader.option("query", "select * from t_user").load();
students.printSchema();
students.show();
// 加载t_class表中的全部数据
Dataset<Row> classes = reader.option("query", "select * from t_class").load();
classes.show();
Dataset<Row> c1 = classes.as("c1");
Dataset<Row> s1 = students.as("s1");
// 使用join(默认使用内连接方式执行查询),后面的where表示连接的条件
Dataset<Row> unionTable = s1.join(c1).where("s1.classId=c1.id");
unionTable.show();
//查询特定的数据(unionTable中还是保存了对应的别名表的信息内容)
unionTable.select("s1.*","c1.className","c1.schoolName","c1.description","c1.childNum").show();
}
执行结果如下:
root
|-- id: integer (nullable = true)
|-- name: string (nullable = true)
|-- age: integer (nullable = true)
|-- score: double (nullable = true)
|-- classId: integer (nullable = true)
+---+----+---+-----+-------+
| id|name|age|score|classId|
+---+----+---+-----+-------+
| 1|张三| 18| 55.5| 201|
| 2|李四| 22| 59.5| 202|
+---+----+---+-----+-------+
+---+---------+----------+-----------+--------+
| id|className|schoolName|description|childNum|
+---+---------+----------+-----------+--------+
|201| 学前1班| 学校|所属学前1班| 22|
|202| 学前2班| 学校|所属学前2班| 18|
+---+---------+----------+-----------+--------+
+---+----+---+-----+-------+---+---------+----------+-----------+--------+
| id|name|age|score|classId| id|className|schoolName|description|childNum|
+---+----+---+-----+-------+---+---------+----------+-----------+--------+
| 2|李四| 22| 59.5| 202|202| 学前2班| 学校|所属学前2班| 18|
| 1|张三| 18| 55.5| 201|201| 学前1班| 学校|所属学前1班| 22|
+---+----+---+-----+-------+---+---------+----------+-----------+--------+
+---+----+---+-----+-------+---------+----------+-----------+--------+
| id|name|age|score|classId|className|schoolName|description|childNum|
+---+----+---+-----+-------+---------+----------+-----------+--------+
| 2|李四| 22| 59.5| 202| 学前2班| 学校|所属学前2班| 18|
| 1|张三| 18| 55.5| 201| 学前1班| 学校|所属学前1班| 22|
+---+----+---+-----+-------+---------+----------+-----------+--------+
执行成功
以上是关于Apache Spark:SparkSQL的使用的主要内容,如果未能解决你的问题,请参考以下文章