FedBN
Posted LeoJarvis
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了FedBN相关的知识,希望对你有一定的参考价值。
《FEDBN: FEDERATED LEARNING ON NON-IID FEATURES VIA LOCAL BATCH NORMALIZATION》ICLR 2021。文章通过在局部模型中加入批量归一化层(BN)解决联邦学习数据异构性中feature shift这种情况(之前很多文章都是研究label shift或client shift),文章将这种方法名为FedBN。
什么是feature shift
y为标签,x为特征,文章将feature shift定义为以下情况:
1)covariate shift:即使所有客户的
P
i
P_i
Pi(y|x)是相同的,不同客户之间的边缘分布
P
i
P_i
Pi(x)是不同的;
2)concept shift:不同客户的条件分布
P
i
P_i
Pi(x|y)不同,但P(y)相同。
例如:医学成像中不同的扫描仪/传感器,自动驾驶中不同的环境分布(公路和城市),使得本地客户端的样本分布不同于其他客户端。
FedBN ALGORITHM
与FedAvg类似,FedBN也进行局部更新和模型聚合,不同的是,FedBN假设局部模型有批量归一化层(BN),且BN的参数不参与聚合。

收敛性分析
一片华丽的数学推导也太秀了,暂时没能看懂…
反正结论是在feature shift场景下,FedBN的收敛比FedAvg更快更光滑
实验
文章分benchmark和real-world datasets两种数据进行实验
1、benchmark experiment
1.1 实验设置
数据集:五个来自不同域且带有feature shift性质的数据集(不同域的数据具有异构的性质,但具有相同的标签和标签分布)。具体包括SVHN, USPS, MNIST-M, MNIST, SynthDigits。文章还对这五个数据集进行了些预处理,主要是控制无关因素,例如客户之间样本数量不平衡问题,使BN的作用在实验中更加易于观察。
模型:在卷积层和全连接层后面加入BN层。
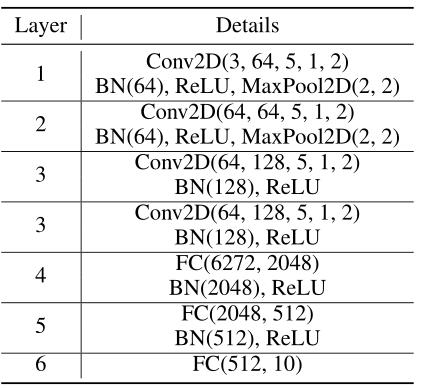
客户端:默认设置下,有五个客户端,每个客户端的数据来自对不同的数据集的采样,且只有对应数据集的数据量的10%。
其他参数略详见论文。
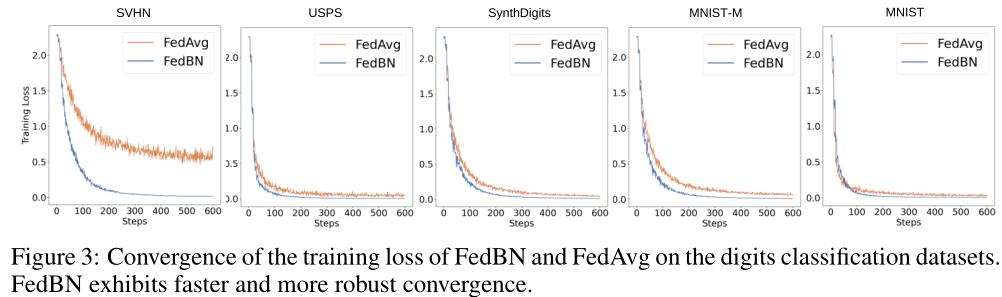
1.2 收敛速度分析
具体设置:

与收敛性分析的结论相同,聚合模型在每个数据集(也就是每个客户端)上的收敛曲线显示,FedBN的收敛比FedAvg更快更光滑。
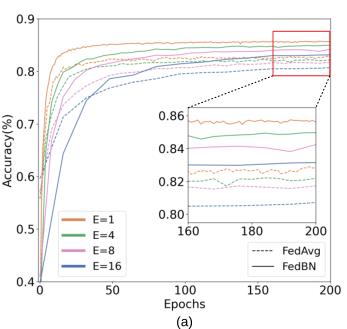
1.3 局部模型训练迭代次数分析
具体设置:

不同迭代次数(E)下,FedBN和FedAvg测试集上的准确率曲线显示,在各种E上,FedBN的准确率稳定地超过FedAvg。
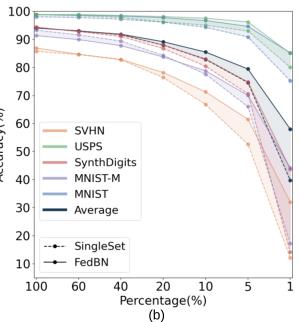
1.4 本地数据集的大小分析
具体设置:

结果表明,每个客户端持有的Non-IID数据越少,FedBN的优越性越明显。
1.5 统计异质性的影响
具体设置:

更多的客户端对应更小的异构性。在所有异质性水平上,FedBN都比FedAvg实现了更高的测试精度。
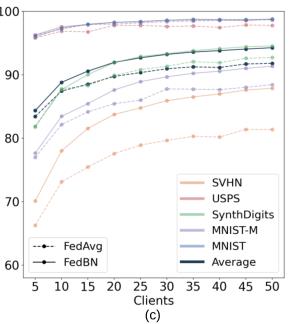
1.6 Comparison with State-of-the-art
具体设置:

(1) FedBN实现了最高的精度;
(2) FedBN对SVHN数据集的性能最为显著,SVHN的图像外观与其他图像有很大的不同。
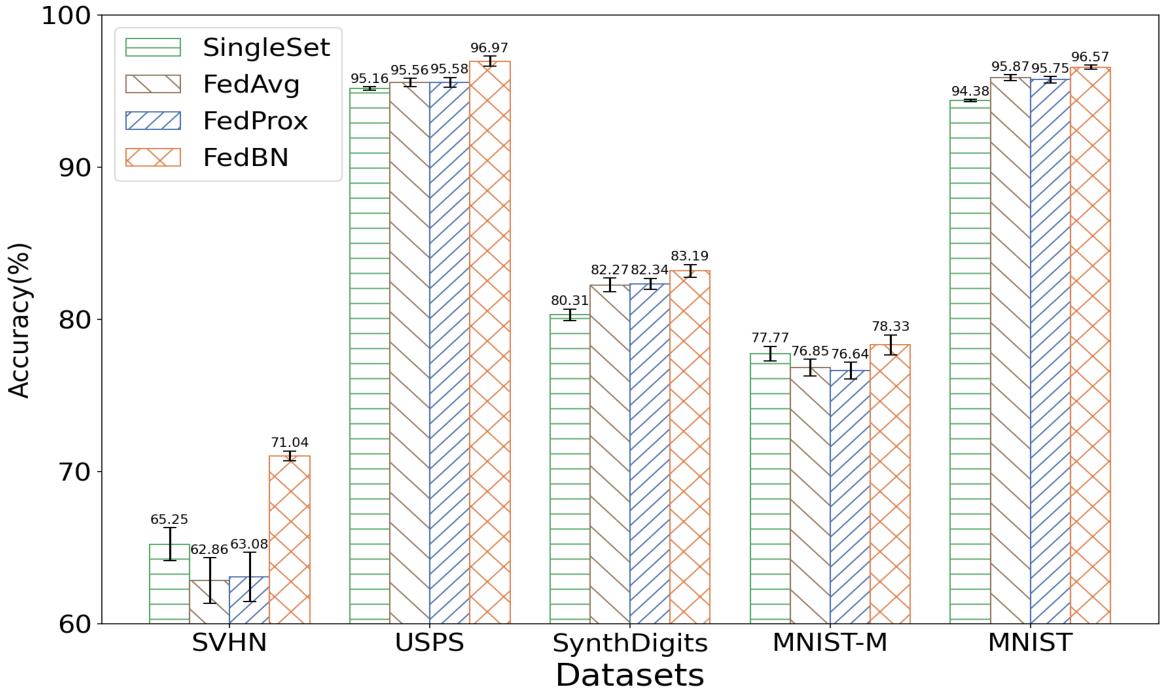
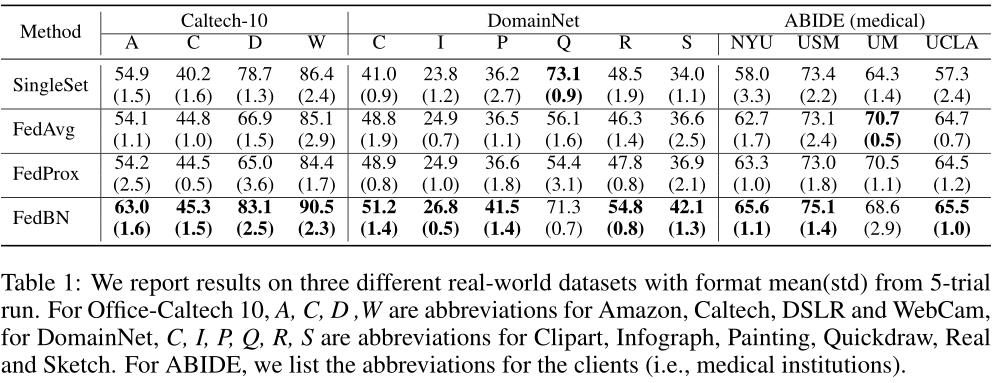
2、EXPERIMENTS ON REAL-WORLD DATASETS
总结与展望
其实这篇文章的中心很简单,就是在本地模型中加入BN层,然后应用于feature shift这种异构性场景并获得了不错的性能。有望与其他方法和框架,例如客户端选择策略,聚合策略等等相结合。并且BN本身也有优化版本可以尝试应用于此。
以上是关于FedBN的主要内容,如果未能解决你的问题,请参考以下文章