爬虫学习笔记(二十四)—— pyspider框架
Posted 别呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫学习笔记(二十四)—— pyspider框架相关的知识,希望对你有一定的参考价值。
文章目录
一、框架介绍
1.1、简介
pyspider 是个强大的由python实现的爬虫系统。
- 纯python的
- 强大的webui,支持脚本编辑,任务监控,项目管理和结果查看
- 数据后台支持,mysql,MongoDB,Reids,SQLite,Elasticsearch,PostgreSQL和SQLAlchemy
- 消息队列支持,RabbitMQ,Beanstalk,Redis以及Kombu
- 支持任务优先级,定时,失败重试等调度方案
- 分布式架构,抓取js页面
- 支持Python2和3
1.2、安装(windows)
下载 pyspider
方式一:pip install pyspider
方式二(建议):pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspider
下载出错
1、运行 pyspider 运行报错误:
ValueError: Invalid configuration:
- Deprecated option 'domaincontroller': use 'http_authenticator.domain_controller' instead.
解决方案:删除wsgidav 然后重新安装2.4.1版本
(1)where wsgidav找到wsgidav的位置,删除wsgidav.exe
(2)pip install wsgidav==2.4.1 安装2.4.1版本
2、再次运行 pyspider 报错
ImportError: cannot import name 'DispatcherMiddleware'
解决方案:
- 卸载
pip uninstall werkzeug
- 安装指定版本
pip install werkzeug==0.16.0
3、再次运行 `pyspider` 运行成功

如果出现:
ImportError: cannot import name 'ContextVar'
你可以看下你在 成功执行下面语句时 有没有出现下面情况
pip install werkzeug==0.16.0
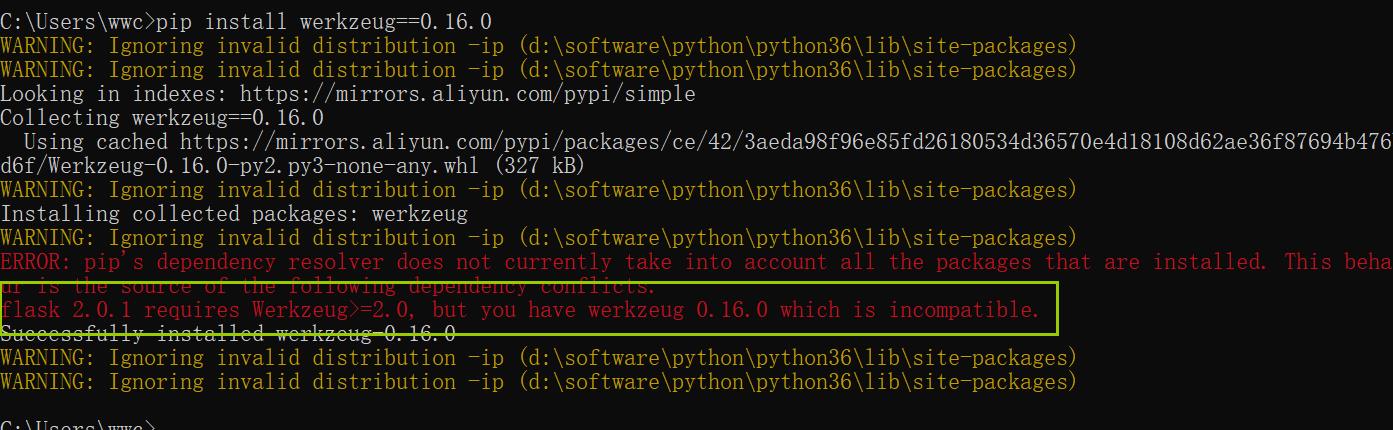
这个是你flask版本的问题,你只要降低下flask版本就行了
pip uninstall flask #卸载
pip install flask==1.0 #我这里改成1.0就行了,改成其他低版本应该也没问题,有兴趣自己试下
1.3、Phantomjs 无界面浏览器
(windows环境)
(用途:就是可以执行js代码。。。)
1、下载
http://phantomjs.org/download.html
2、解压(phantomjs-2.1.1-windows.zip)
3、配置环境变量
将解压的bin目录的路径配置到环境变量中去
二、框架入门
2.1、启动pyspider
安装好pyspider后,创建一个项目文件夹用来存放相关文件,进入文件夹后运行pyspider命令,默认情况下会运行一个web服务端监听5000端口,通过127.0.0.1:5000即可访问pyspider的web管理界面,它看起来是这样的:
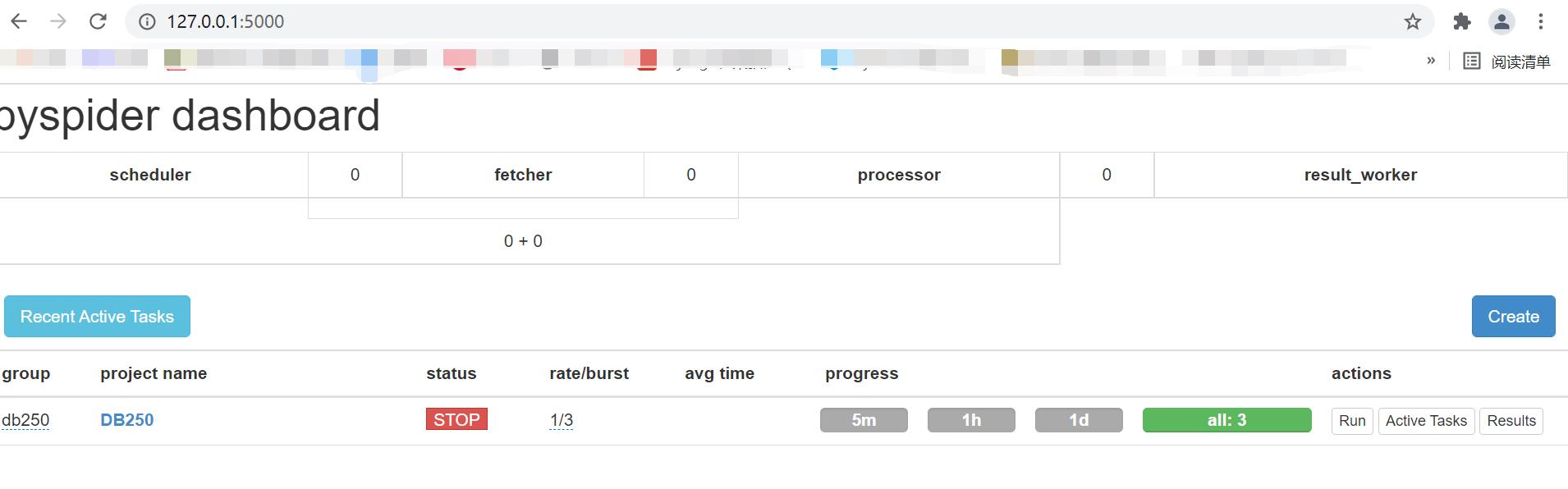
2.2、创建一个项目
点击右边的Create按钮,在弹出框里,填写项目名称,和起始url 。
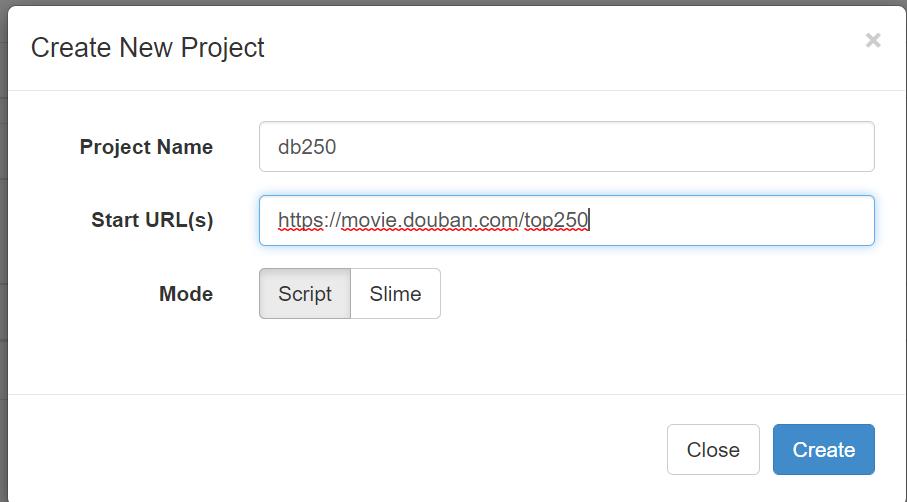
创建完成后,窗口右边部分为代码编辑器,在这里你可以编写你的爬虫脚本。
2.3、脚本
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://scrapy.org/', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
def on_start(selef)是脚本的入口。当你点击run按钮时,它会被调用。self.crawl(url, callback=self.index_page)是最重要的接口。它会添加一个新的待爬取任务。大部分的设置可以通过self.crawl的参数去指定。def index_page(self, response)接收一个response对象。response.doc是一个pyquery对象,它有一个类似jQuery选择器一样的接口,去解析页面元素。def detail_page(self, response)返回一个字典结果。这个结果默认会被写入resultdb(结果数据库)。你可以通过复写on_result(self, result)方法来按照你自己的需求处理结果。@every(minutes=24 * 60)这个装饰器会告诉调度器,on_start方法将会每天被调用。@config(age=10 * 24 * 60 * 60)指定当self.crawl爬取的页面类型为index_page(当callback=self.index_page)时的age参数的默认值。参数age可以通过self.crawl(url, age=10*24*60*60)和crawl_config来指定,直接在方法参数中指定具有最高的优先级。age=10*24*60*60告诉调度器抛弃10天内爬取过的请求。默认情况下,相同URL不会被爬取两次,甚至你修改了代码。对于初学者来说,第一次运行项目然后修改它,在第二次运行项目的情况非常常见,但是它不会再次爬行(阅读itag了解解决方案)@config(priority=2)标志着,detail page将会被优先爬取。
你可以通过点击绿色的run按钮,一步一步的调试你的脚本。切换到follows面板,点击play按钮前进。
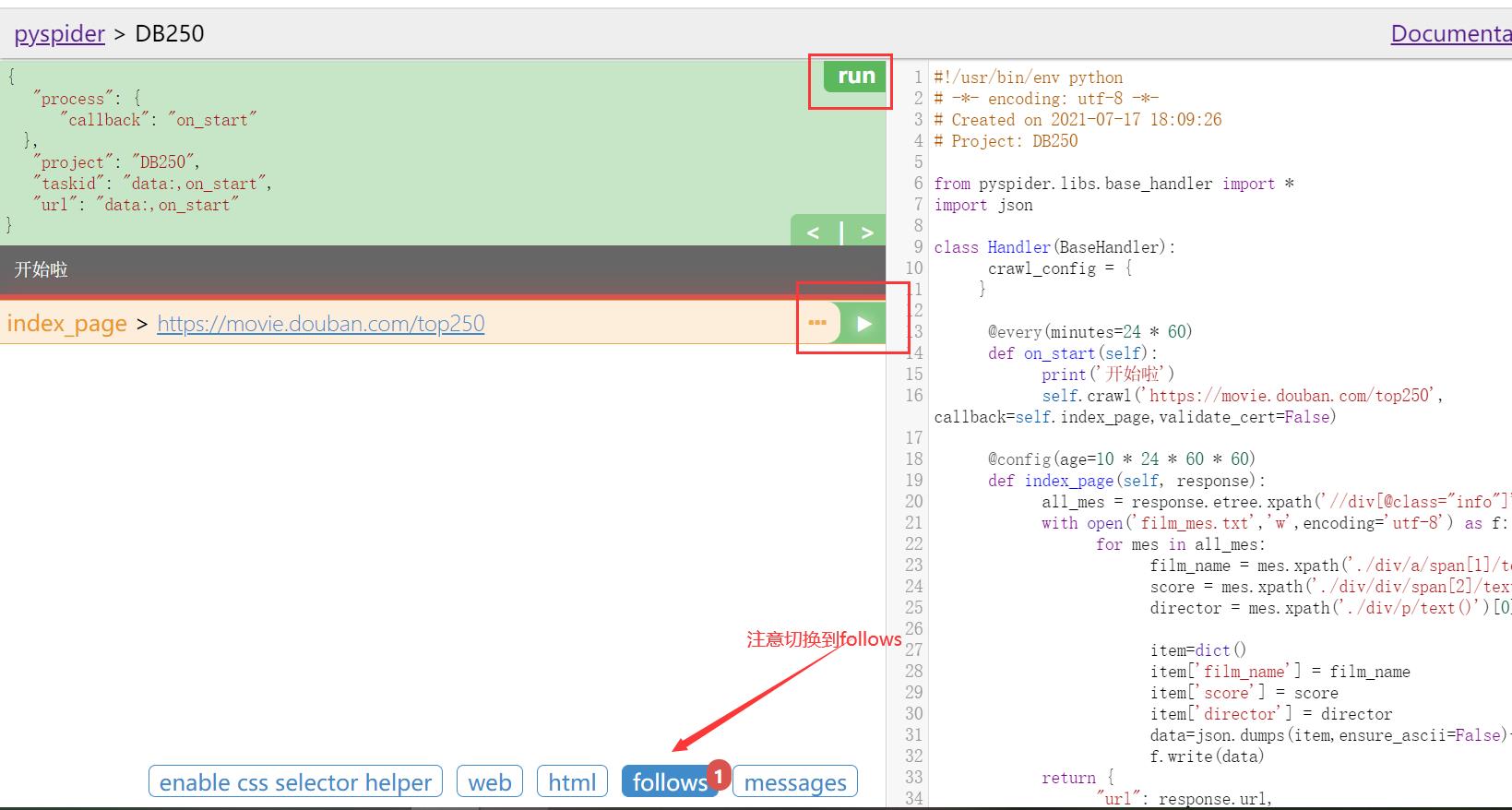
2.4、运行项目
-
保存脚本
-
返回后台首页,找到你的项目
-
改变
status为DEBUG或RUNNING -
点击按钮
run
补充:
删除项目:将status改为stop,将group改为delete,然后24小时后才会被删除(注意pyspider没法直接删除项目,只能这样等24小时就会自动删除)

三、小案例:豆瓣250信息
from pyspider.libs.base_handler import *
import json
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
print('开始啦')
self.crawl('https://movie.douban.com/top250', callback=self.index_page,validate_cert=False)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
all_mes = response.etree.xpath('//div[@class="info"]')
with open('film_mes.txt','w',encoding='utf-8') as f:
for mes in all_mes:
film_name = mes.xpath('./div/a/span[1]/text()')[0]
score = mes.xpath('./div/div/span[2]/text()')[0]
director = mes.xpath('./div/p/text()')[0].strip()
item=dict()
item['film_name'] = film_name
item['score'] = score
item['director'] = director
data=json.dumps(item,ensure_ascii=False)+'\\n'
f.write(data)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
四、架构
4.1、概述
下图显示了pyspider体系结构及其组件的概述,以及系统内部发生的数据流的概要。
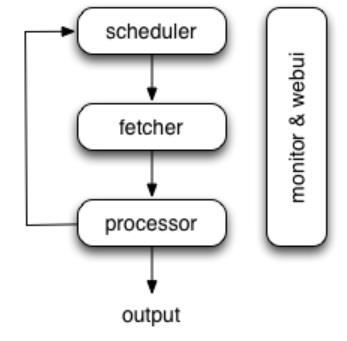
组件之间通过消息队列进行连接。每一个组件都包含消息队列,都在它们自己的进程/线程中运行,并且是可以替换的。这意味者,当处理速度缓慢时,可以通过启动多个processor实例来充分利用多核cpu,或者进行分布式部署。
4.2、组件
1、Scheduler
调度器从processor返回的新任务队列中接收任务。判断是新任务还是需要重新爬取。通过优先级对任务进行分类,并且利用令牌桶算法将任务发送给fetcher. 处理周期任务,丢失的任务和失败的任务,并且稍后重试。
以上都可以通过self.crawl进行设置。
注意,在当前的调度器实现中,只允许一个调度器。
2、Fetcher
Fetcher的职责是获取web页面然后把结果发送给processor。请求method, headers, cookies, proxy, etag 等,都可以设置。
3、Processor
处理器的职责是运行用户编写的脚本,去解析和提取信息。您的脚本在无限制的环境中运行。尽管我们有各种各样的工具(如风PyQuery)供您提取信息和连接,您可以使用任何您想使用的方法来处理响应。
处理器会捕捉异常和记录日志,发送状态(任务跟踪)和新的任务给调度器,发送结果给Result Worker
4、Result Worker
Result Worker从Porcess接收结果。Pyspider有一个内置的结果处理器将数据保存到resultdb.根据您的需要重写它以处理结果。
5、WebUI
WebUI是一个面向所有内容的web前端。它包含:
- 脚本编辑器,调试器
- 项目管理器
- 任务监控程序
- 结果查看器和导出
也许webui是pyspider最吸引人的地方。使用这个强大的UI,您可以像pyspider一样一步一步地调试脚本。启动停止项目。找到哪个项目出错了,什么请求失败了,然后使用调试器再试一次。
6、Data flow
pyspider中的数据流如上图所示:
- 当您按下WebUI上的Run按钮时,每个脚本都有一个名为on_start的回调。作为项目的入口,
on_start产生的新任务将会提交给调度器。 - 调度程序使用一个数据URI将这个on_start任务分派为要获取的普通任务。
- Fetcher对它发出一个请求和一个响应(对于数据URI,它是一个假的请求和响应,但与其他正常任务没有区别),然后送给处理器。
- 处理器调用on_start方法并生成一些要抓取的新URL。处理器向调度程序发送一条消息,说明此任务已完成,并通过消息队列将新任务发送给调度程序(在大多数情况下,这里没有on_start的结果。如果有结果,处理器将它们发送到result_queue)。
- 调度程序接收新任务,在数据库中查找,确定任务是新的还是需要重新抓取,如果是,将它们放入任务队列。按顺序分派任务。
- 这个过程重复(从步骤3开始),直到WWW死后才停止;-)。调度程序将检查定期任务,以抓取最新数据。
4.3、关于任务
任务是调度的基本单元。
基本原理
- 任务由它的
taskid(默认:md5(url), 可以通过重写get_taskid(self, task)方法来修改)来区分。 - 不同项目之间的任务是隔离的
- 一个任务有4个状态:
- active
- failed
- success
- bad-not used
- 只有处于
active状态的任务会被调度 - 任务按优先次序执行。
调度
- 新任务
当一个新的任务(从未见过)出现:
- 如果设置了exetime但没有到达,它将被放入一个基于时间的队列中等待。
- 否则将被接受。
当任务已经在队列中:
- 除非(
force_update)强制更新,否则忽略
当一个完成过的任务出现时:
- 如果
age设置,且last_crawl_time + age < now它将会被接受,否则抛弃。 - 如果
itag设置,且它不等于上一次的值,它会被接受,否则抛弃。
- 重试
当请求错误或脚本错误发生时,任务将在默认情况下重试3次。
第一次重试将在30秒、1小时、6小时、12小时后每次执行,任何更多的重试将推迟24小时。retry_delay是一个指定重试间隔的字典。这个字典中的元素是{retried:seconds}, 如果未指定,则使用特殊键:''空字符串指定的默认推迟时间。
例如默认的retry_delay声明如下:
class MyHandler(BaseHandler):
retry_delay = {
0: 30,
1: 1*60*60,
2: 6*60*60,
3: 12*60*60,
'': 24*60*60
}
4.4、关于项目
在大多数情况下,项目是为一个网站编写的一个脚本。
- 项目是独立的,但是可以用
from Projects import other_project将另一个项目作为模块导入 - 一个项目有5个状态:
TODO,STOP,CHECKING,DEBUG和RUNNINGTODO- 刚创建,正在编写脚本- 如果您希望项目停止(= =),可以将其标记为STOP。
CHECKING- 当正在运行的项目被修改时,为了防止未完成的修改,项目状态将被设置为自动检查。DEBUG/RUNNING- 这两种状态对爬虫没有区别。但最好在第一次运行时将其标记为DEBUG,然后在检查后将其更改为RUNNING。
- 爬行速率由
rate和burst并采用令牌桶算法进行控制。rate- 一秒钟内有多少请求burst- 考虑这种情况,RATE/BURST=0.1/3,这意味着蜘蛛每10秒抓取1个页面。所有任务都已完成,Project将每分钟检查最后更新的项目。假设找到3个新项目,pyspider将“爆发”并爬行3个任务,而不等待3*10秒。但是,第四个任务需要等待10秒。
- 若要删除项目,请将“组”设置为“删除”,将“状态”设置为“停止”,然后等待24小时。
回调on_finished
您可以在项目中重写on_finished方法,当task_queue变为0时将触发该方法。
第一种情况:当您启动一个项目来抓取一个包含100个页面的网站时,当100个页面被成功抓取或重试失败时,on_finished回调将被触发。
第二种情况:带有auto_recrawl任务的项目永远不会触发on_finished回调,因为当其中有auto_recrawl任务时,时间队列永远不会变为0。
第三种情况:带有@every修饰方法的项目将在每次新提交的任务完成时触发on_finished回调。
4.5、脚本环境
变量
self.project_nameself.project当前项目的详细信息self.responseself.task
官方文档:http://docs.pyspider.org/en/latest/
关于脚本
handler的名称并不重要,但您需要至少一个继承basehandler的类- 可以设置第三个参数来获取任务对象:
def callback(self、response、task) - 默认情况下,非200响应不会提交回调。可以使用
@catch_status_code_error来处理非200响应
关于环境
logging,print以及异常会被捕获。- 你可以通过
from projects import some_project将其他项目当做模块导入。
Web view
- 以浏览器呈现的方式查看页面(大约)
HTML view
- 查看当前回调的html(索引页、细节页等)
Follows view
- 查看可从当前回调进行的回调
- 索引页面跟随视图将显示可执行的详细页面回调。
Messages view
- 显示
self.send_message发送的消息
Enable CSS Selector Helper
- 启用Web视图的CSS选择器帮助程序。它获取您单击的元素的CSS选择器,然后将其添加到脚本中。
4.6、处理结果
从WebUI下载和查看数据很方便,但可能不适用于计算机。
使用resultdb
虽然resultdb仅用于结果预览,但不适用于大规模存储。
但是,如果您想从resultdb中获取数据,那么有一些使用数据库API的简单案例可以帮助您连接和选择数据。
from pyspider.database import connect_database
resultdb = connect_database("<your resutldb connection url>")
for project in resultdb.projects:
for result in resultdb.select(project):
assert result['taskid']
assert result['url']
assert result['result']
result['result']是由你编写的脚本中的RETURN语句提交的对象。
使用ResultWorker
在生产环境中,你可能希望将pyspider连接到你的系统的处理管道,而不是将结果存储到resultdb中。强烈建议重写ResultWorker。
from pyspider.result import ResultWorker
class MyResultWorker(ResultWorker):
def on_result(self, task, result):
assert task['taskid']
assert task['project']
assert task['url']
assert result
# your processing code goes here
result是你脚本中return语句提交的对象。
您可以将这个脚本(例如,my_result_worker.py)放在启动pyspider的文件夹中。
为result_worker子命令添加参数:
pyspider result_worker --result-cls=my_result_worker.MyResultWorker
或者,如果你使用配置文件
{
...
"result_worker": {
"result_cls": "my_result_worker.MyResultWorker"
}
...
}
为了兼容性,将存储在数据库中的结果编码为JSON。强烈建议您设计自己的数据库,并覆盖上面描述的ResultWorker。
-----关于结果的小技巧
想要在回调中返回多个结果?
resultdb会通过taskid(url)对结果进行去重,后面的结果会覆盖前面的。
一个解决方案是使用send_message API为每个结果生成一个伪taskid。
def detail_page(self, response):
for li in response.doc('li').items():
self.send_message(self.project_name, {
...
}, url=response.url+"#"+li('a.product-sku').text())
def on_message(self, project, msg):
return msg
以上是关于爬虫学习笔记(二十四)—— pyspider框架的主要内容,如果未能解决你的问题,请参考以下文章