后端学习后端技术要点总结
Posted 毛_三月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了后端学习后端技术要点总结相关的知识,希望对你有一定的参考价值。
目录
一、SSM框架中Dao层,Mapper层,controller层,service层,model层,entity层都有什么作用
SSM是sping+springMVC+mybatis集成的框架。
MVC即model view controller。
**model层=entity层。**存放我们的实体类,与数据库中的属性值基本保持一致。
**service层。**存放业务逻辑处理,也是一些关于数据库处理的操作,但不是直接和数据库打交道,他有接口还有接口的实现方法,在接口的实现方法中需要导入mapper层,mapper层是直接跟数据库打交道的,他也是个接口,只有方法名字,具体实现在mapper.xml文件里,service是供我们使用的方法。
mapper层=dao层,现在用mybatis逆向工程生成的mapper层,其实就是dao层。对数据库进行数据持久化操作,他的方法语句是直接针对数据库操作的,而service层是针对我们controller,也就是针对我们使用者。service的impl是把mapper和service进行整合的文件。
(多说一句,数据持久化操作就是指,把数据放到持久化的介质中,同时提供增删改查操作,比如数据通过hibernate插入到数据库中。)
controller层。控制器,导入service层,因为service中的方法是我们使用到的,controller通过接收前端传过来的参数进行业务操作,在返回一个指定的路径或者数据表。
二、RESTfull 接口规范理解
RESTfull = Representational State Transfer 即表现层状态转移 加 ful (即形容词后缀) 则表示是形容词性的
而要理解RESTful架构,最好的方法就是去理解Representational State Transfer这个词组,直译过来就是「表现层状态转化」,其实它省略了主语。「表现层」其实指的是「资源」的「表现层」,所以通俗来讲就是:资源在网络中以某种表现形式进行状态转移。分解开来:
Resource:资源,即数据。比如usenames/users/friends/menu/order等;
Representational:某种表现形式,比如用JSON,XML,JPEG等;
State Transfer:状态变化。通过HTTP动词实现。
二、名称
Fielding将他对互联网软件的架构原则,定名为REST,即Representational State Transfer的缩写。我对这个词组的翻译是"表现层状态转化"。
如果一个架构符合REST原则,就称它为RESTful架构。
**要理解RESTful架构,最好的方法就是去理解Representational State Transfer这个词组到底是什么意思,它的每一个词代表了什么涵义。**如果你把这个名称搞懂了,也就不难体会REST是一种什么样的设计。
三、资源(Resources)
REST的名称"表现层状态转化"中,省略了主语。“表现层"其实指的是"资源”(Resources)的"表现层"。
**所谓"资源",就是网络上的一个实体,或者说是网络上的一个具体信息。**它可以是一段文本、一张图片、一首歌曲、一种服务,总之就是一个具体的实在。你可以用一个URI(统一资源定位符)指向它,每种资源对应一个特定的URI。要获取这个资源,访问它的URI就可以,因此URI就成了每一个资源的地址或独一无二的识别符。
所谓"上网",就是与互联网上一系列的"资源"互动,调用它的URI。
四、表现层(Representation)
"资源"是一种信息实体,它可以有多种外在表现形式。我们把"资源"具体呈现出来的形式,叫做它的"表现层"(Representation)。
比如,文本可以用txt格式表现,也可以用html格式、XML格式、JSON格式表现,甚至可以采用二进制格式;图片可以用JPG格式表现,也可以用PNG格式表现。
URI只代表资源的实体,不代表它的形式。严格地说,有些网址最后的".html"后缀名是不必要的,因为这个后缀名表示格式,属于"表现层"范畴,而URI应该只代表"资源"的位置。它的具体表现形式,应该在HTTP请求的头信息中用Accept和Content-Type字段指定,这两个字段才是对"表现层"的描述。
五、状态转化(State Transfer)
访问一个网站,就代表了客户端和服务器的一个互动过程。在这个过程中,势必涉及到数据和状态的变化。
互联网通信协议HTTP协议,是一个无状态协议。这意味着,所有的状态都保存在服务器端。因此,如果客户端想要操作服务器,必须通过某种手段,让服务器端发生"状态转化"(State Transfer)。而这种转化是建立在表现层之上的,所以就是"表现层状态转化"。
客户端用到的手段,只能是HTTP协议。具体来说,就是HTTP协议里面,四个表示操作方式的动词:GET、POST、PUT、DELETE。它们分别对应四种基本操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源。
六、综述
综合上面的解释,我们总结一下什么是RESTful架构:
(1)每一个URI代表一种资源;
(2)客户端和服务器之间,传递这种资源的某种表现层;
(3)客户端通过四个HTTP动词,对服务器端资源进行操作,实现"表现层状态转化"。
七、误区
RESTful架构有一些典型的设计误区。
**最常见的一种设计错误,就是URI包含动词。**因为"资源"表示一种实体,所以应该是名词,URI不应该有动词,动词应该放在HTTP协议中。
举例来说,某个URI是/posts/show/1,其中show是动词,这个URI就设计错了,正确的写法应该是/posts/1,然后用GET方法表示show。
如果某些动作是HTTP动词表示不了的,你就应该把动作做成一种资源。比如网上汇款,从账户1向账户2汇款500元,错误的URI是:
POST /accounts/1/transfer/500/to/2
正确的写法是把动词transfer改成名词transaction,资源不能是动词,但是可以是一种服务:
POST /transaction HTTP/1.1
Host: 127.0.0.1
from=1&to=2&amount=500.00
另一个设计误区,就是在URI中加入版本号:
http://www.example.com/app/1.0/foo
http://www.example.com/app/1.1/foo
http://www.example.com/app/2.0/foo
因为不同的版本,可以理解成同一种资源的不同表现形式,所以应该采用同一个URI。版本号可以在HTTP请求头信息的Accept字段中进行区分(参见Versioning REST Services):
Accept: vnd.example-com.foo+json; version=1.0
Accept: vnd.example-com.foo+json; version=1.1
Accept: vnd.example-com.foo+json; version=2.0
三、SpringBoot事务
1、事务是什么
事务是应用程序中一系列严密的操作,所有操作必须成功完成,否则在每个操作中所作的所有更改都会被撤消。也就是事务具有原子性,一个事务中的一系列的操作要么全部成功,要么一个都不做。
2、事务的四大特性
数据库事务 transanction 正确执行的四个基本要素。ACID,原子性(Atomicity)、一致性(Correspondence)、隔离
性(Isolation)、持久性(Durability)。
(1)原子性:整个事务中的所有操作,要么全部完成,要么全部不完成,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
(2)一致性:在事务开始之前和事务结束以后,数据库的完整性约束没有被破坏。
(3)隔离性:隔离状态执行事务,使它们好像是系统在给定时间内执行的唯一操作。如果有两个事务,运行在相同的时间内,执行 相同的功能,事务的隔离性将确保每一事务在系统中认为只有该事务在使用系统。这种属性有时称为串行化,为了防止事务操作间的混淆, 必须串行化或序列化请 求,使得在同一时间仅有一个请求用于同一数据。
(4)持久性:在事务完成以后,该事务所对数据库所作的更改便持久的保存在数据库之中,并不会被回滚。
Spring Boot实现事务特别特别简单,没有多余操作,一个注解@Transactional搞定
注解属性
rollbackFor:触发回滚的异常,默认是RuntimeException和Errorisolation: 事务的隔离级别,默认是Isolation.DEFAULT也就是数据库自身的默认隔离级别,比如mysql是ISOLATION_REPEATABLE_READ可重复读
四、Mybatis
动态SQL
什么是动态SQL:动态SQL指的是根据不同的查询条件 , 生成不同的Sql语句.
官网描述:
MyBatis 的强大特性之一便是它的动态 SQL。如果你有使用 JDBC 或其它类似框架的经验,你就能体会到根据不同条件拼接 SQL 语句的痛苦。例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL 这一特性可以彻底摆脱这种痛苦。
虽然在以前使用动态 SQL 并非一件易事,但正是 MyBatis 提供了可以被用在任意 SQL 映射语句中的强大的动态 SQL 语言得以改进这种情形。
动态 SQL 元素和 JSTL 或基于类似 XML 的文本处理器相似。在 MyBatis 之前的版本中,有很多元素需要花时间了解。MyBatis 3 大大精简了元素种类,现在只需学习原来一半的元素便可。MyBatis 采用功能强大的基于 OGNL 的表达式来淘汰其它大部分元素。
-------------------------------
- if
- choose (when, otherwise)
- trim (where, set)
- foreach
-------------------------------
我们之前写的 SQL 语句都比较简单,如果有比较复杂的业务,我们需要写复杂的 SQL 语句,往往需要拼接,而拼接 SQL ,稍微不注意,由于引号,空格等缺失可能都会导致错误。
那么怎么去解决这个问题呢?这就要使用 mybatis 动态SQL,通过 if, choose, when, otherwise, trim, where, set, foreach等标签,可组合成非常灵活的SQL语句,从而在提高 SQL 语句的准确性的同时,也大大提高了开发人员的效率。
分页
limit实现分页
思考:为什么需要分页?
在学习mybatis等持久层框架的时候,会经常对数据进行增删改查操作,使用最多的是对数据库进行查询操作,如果查询大量数据的时候,我们往往使用分页进行查询,也就是每次处理小部分数据,这样对数据库压力就在可控范围内。
使用Limit实现分页
#语法
SELECT * FROM table LIMIT stratIndex,pageSize
SELECT * FROM table LIMIT 5,10; // 检索记录行 6-15
#为了检索从某一个偏移量到记录集的结束所有的记录行,可以指定第二个参数为 -1:
SELECT * FROM table LIMIT 95,-1; // 检索记录行 96-last.
#如果只给定一个参数,它表示返回最大的记录行数目:
SELECT * FROM table LIMIT 5; //检索前 5 个记录行
#换句话说,LIMIT n 等价于 LIMIT 0,n。
步骤:
1、修改Mapper文件
<select id="selectUser" parameterType="map" resultType="user">
select * from user limit #{startIndex},#{pageSize}
</select>
2、Mapper接口,参数为map
//选择全部用户实现分页
List<User> selectUser(Map<String,Integer> map);
3、在测试类中传入参数测试
- 推断:起始位置 = (当前页面 - 1 ) * 页面大小
//分页查询 , 两个参数startIndex , pageSize
@Test
public void testSelectUser() {
SqlSession session = MybatisUtils.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);
int currentPage = 1; //第几页
int pageSize = 2; //每页显示几个
Map<String,Integer> map = new HashMap<String,Integer>();
map.put("startIndex",(currentPage-1)*pageSize);
map.put("pageSize",pageSize);
List<User> users = mapper.selectUser(map);
for (User user: users){
System.out.println(user);
}
session.close();
}
五、主键生成策略
默认 ID_WORKER 全局唯一id
分布式系统唯一id生成:https://www.cnblogs.com/haoxinyue/p/5208136.html
雪花算法:
snowflflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为
毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味
着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。可以保证几乎全球唯
一!
主键自增
我们需要配置主键自增:
1、实体类字段上 @TableId(type = IdType.AUTO)
2、数据库字段一定要是自增!
3、再次测试插入即可!
其与的源码解释
public enum IdType {
AUTO(0), // 数据库id自增
NONE(1), // 未设置主键
INPUT(2), // 手动输入
ID_WORKER(3), // 默认的全局唯一id
UUID(4), // 全局唯一id uuid
ID_WORKER_STR(5); //ID_WORKER 字符串表示法
}
六、context上下文概念
Context,在程序翻译为上下文。上下文就是提供一些程序的运行环境基础信息。比如,要运行一个APP,这个APP运行时需要加载配置文件,然后写到一个类中,然后你需要的时候,通过这个类来获取这些参数。–这个类就是所谓的上下文。
七、cookie和session
cookie和session的区别如下:
1、session保存在服务器,客户端不知道其中的信息;cookie保存在客户端,服务器能够知道其中的信息。
2、session中保存的是对象,cookie中保存的是字符串。
3、session不能区分路径,同一个用户在访问一个网站期间,所有的session在任何一个地方都可以访问到。而cookie中如果设置了路径参数,那么同一个网站中不同路径下的cookie互相是访问不到的。
4、session需要借助cookie才能正常工作。如果客户端完全禁止cookie,session将失效。
应用场景如下:
1.session就是一种保存上下文信息的机制,它是针对每一个用户的,变量的值保存在服务器端,通过SessionID来区分不同的客户,session是以cookie或URL重写为基础的,默认使用cookie来实现,系统会创造一个名为JSESSIONID的输出cookie,
2.persistent cookies和session cookie的区别了,网上那些关于两者安全性的讨论也就一目了然了,session cookie针对某一次会话而言,会话结束session cookie也就随着消失了,而persistent cookie只是存在于客户端硬盘上的一段文本(通常是加密的),而且可能会遭到cookie欺骗以及针对cookie的跨站脚本攻击,自然不如 session cookie安全了。
3.通常session cookie是不能跨窗口使用的,当新开了一个浏览器窗口进入相同页面时,系统会赋予一个新的sessionid,这样信息共享的目的就达不到了,可以先把sessionid保存在persistent cookie中,然后在新窗口中读出来,就可以得到上一个窗口SessionID了,这样通过session cookie和persistent cookie的结合就实现了跨窗口的session tracking(会话跟踪)。
八、授权认证登录之 Cookie、Session、Token、JWT 详解
授权认证登录之 Cookie、Session、Token、JWT 详解
一、先了解几个基础概念
什么是认证(Authentication)
通俗地讲就是验证当前用户的身份。
互联网中的认证:
- 用户名密码登录
- 邮箱发送登录链接
- 手机号接收验证码
- 只要你能收到邮箱/验证码,就默认你是账号的主人
什么是授权(Authorization)
用户授予第三方应用访问该用户某些资源的权限。
实现授权的方式有:cookie、session、token、OAuth。
什么是凭证(Credentials)
实现认证和授权的前提是需要一种媒介(证书)来标记访问者的身份。
在互联网应用中,一般网站(如掘金)会有两种模式,游客模式和登录模式。游客模式下,可以正常浏览网站上面的文章,一旦想要点赞/收藏/分享文章,就需要登录或者注册账号。当用户登录成功后,服务器会给该用户使用的浏览器颁发一个令牌(token),这个令牌用来表明你的身份,每次浏览器发送请求时会带上这个令牌,就可以使用游客模式下无法使用的功能。
二、Cookie
浏览器Cookie详解
三、什么是 Session
- session 是另一种记录服务器和客户端会话状态的机制
- session 是基于 cookie 实现的,session 存储在服务器端,sessionId 会被存储到客户端的cookie 中
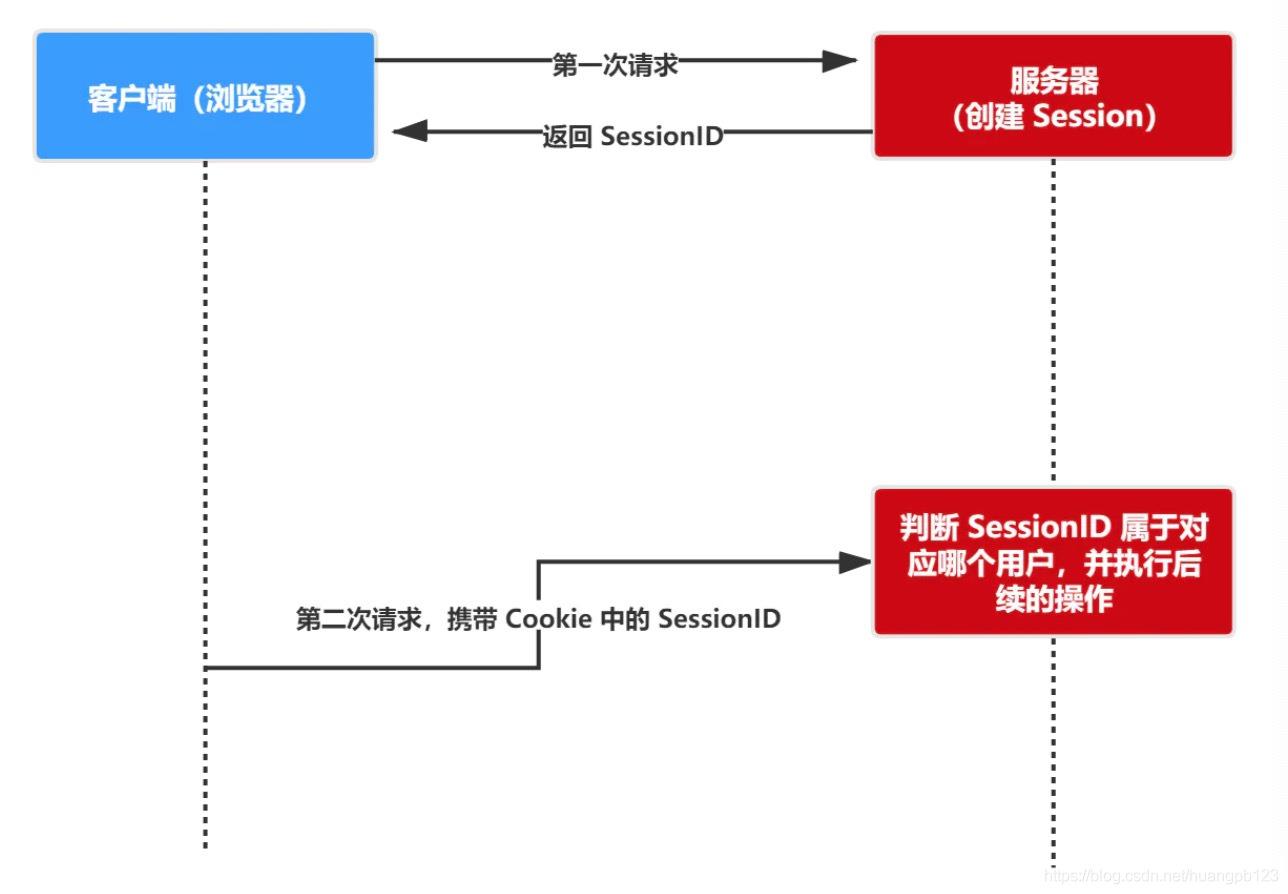
session 认证流程:
- 用户第一次请求服务器的时候,服务器根据用户提交的相关信息,创建对应的 Session
- 请求返回时将此 Session 的唯一标识 SessionID 返回给浏览器
- 浏览器接收到服务器返回的 SessionID 后,会将此信息存入到 Cookie 中,同时 Cookie 记录此 SessionID
属于哪个域名 - 当用户第二次访问服务器的时候,请求会自动把此域名下的 Cookie 信息也发送给服务端,服务端会从 Cookie 中获取
SessionID,再根据 SessionID 查找对应的 Session 信息,如果没有找到说明用户没有登录或者登录失效,如果找到
Session 证明用户已经登录可执行后面操作。
根据以上流程可知,SessionID 是连接 Cookie 和 Session 的一道桥梁,大部分系统也是根据此原理来验证用户登录状态。
四、Cookie 和 Session 的区别
安全性: Session 比 Cookie 安全,Session 是存储在服务器端的,Cookie 是存储在客户端的。
存取值的类型不同:Cookie 只支持存字符串数据,Session 可以存任意数据类型。
有效期不同: Cookie 可设置为长时间保持,比如我们经常使用的默认登录功能,Session 一般失效时间较短,客户端关闭(默认情况下)或者 Session 超时都会失效。
存储大小不同: 单个 Cookie 保存的数据不能超过 4K,Session 可存储数据远高于 Cookie,但是当访问量过多,会占用过多的服务器资源。
五、什么是 Token(令牌)
Acesss Token
访问资源接口(API)时所需要的资源凭证
简单 token 的组成: uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,token 的前几位以哈希算法压缩成的一定长度的十六进制字符串)
服务器对 Token 的存储方式:
- 存到数据库中,每次客户端请求的时候取出来验证(服务端有状态)
- 存到 redis 中,设置过期时间,每次客户端请求的时候取出来验证(服务端有状态)
- 不存,每次客户端请求的时候根据之前的生成方法再生成一次来验证(JWT,服务端无状态)
特点:
- 服务端无状态化、可扩展性好
- 支持移动端设备
- 安全
- 支持跨程序调用
Token 的身份验证流程:
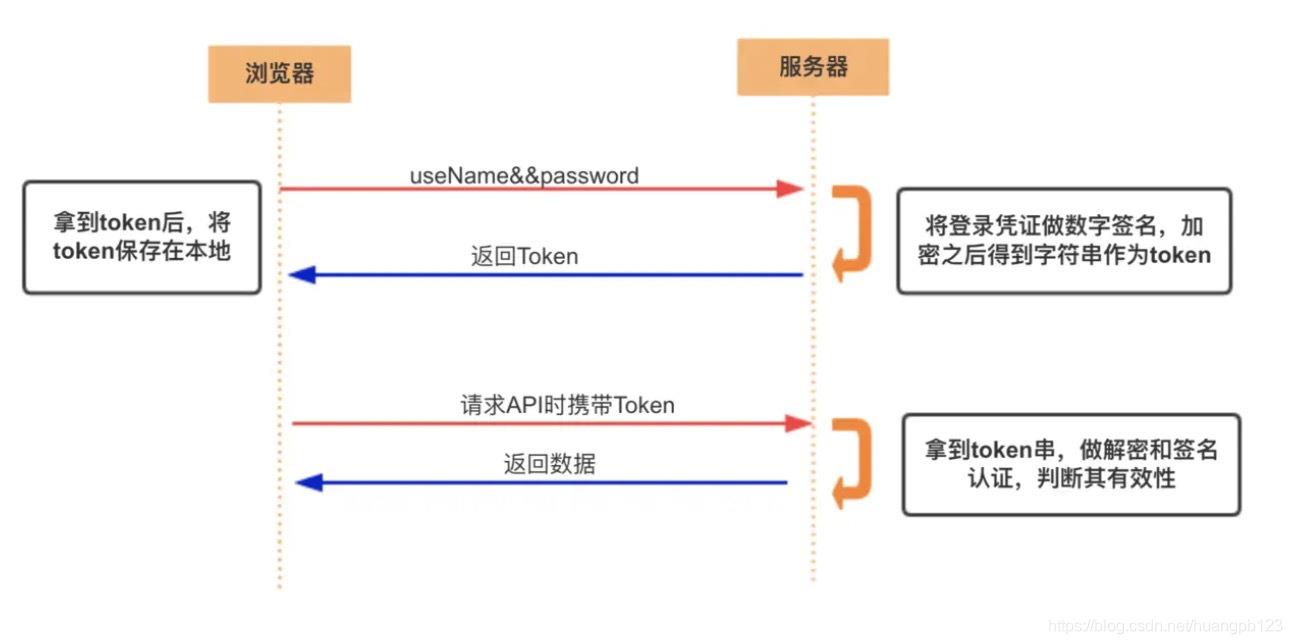
- 客户端使用用户名跟密码请求登录
- 服务端收到请求,去验证用户名与密码
- 验证成功后,服务端会签发一个 token 并把这个 token 发送给客户端
- 客户端收到 token 以后,会把它存储起来,比如放在 cookie 里或者 localStorage 里
- 客户端每次向服务端请求资源的时候需要带着服务端签发的 token
- 服务端收到请求,然后去验证客户端请求里面带着的 token ,如果验证成功,就向客户端返回请求的数据
- 每一次请求都需要携带 token,需要把 token 放到 HTTP 的 Header 里
- token 完全由应用管理,所以它可以避开同源策略
注意:
登录时 token 不宜保存在 localStorage,被 XSS 攻击时容易泄露。所以比较好的方式是把 token 写在 cookie
里。为了保证 xss 攻击时 cookie 不被获取,还要设置 cookie 的 http-only。这样,我们就能确保 js 读取不到
cookie 的信息了。再加上 https,能让我们的请求更安全一些。
Refresh Token
- 另外一种 token——refresh token
- refresh token 是专用于刷新 access token 的 token。如果没有 refresh token,也可以刷新
access token,但每次刷新都要用户输入登录用户名与密码,会很麻烦。有了 refresh
token,可以减少这个麻烦,客户端直接用 refresh token 去更新 access token,无需用户进行额外的操作。
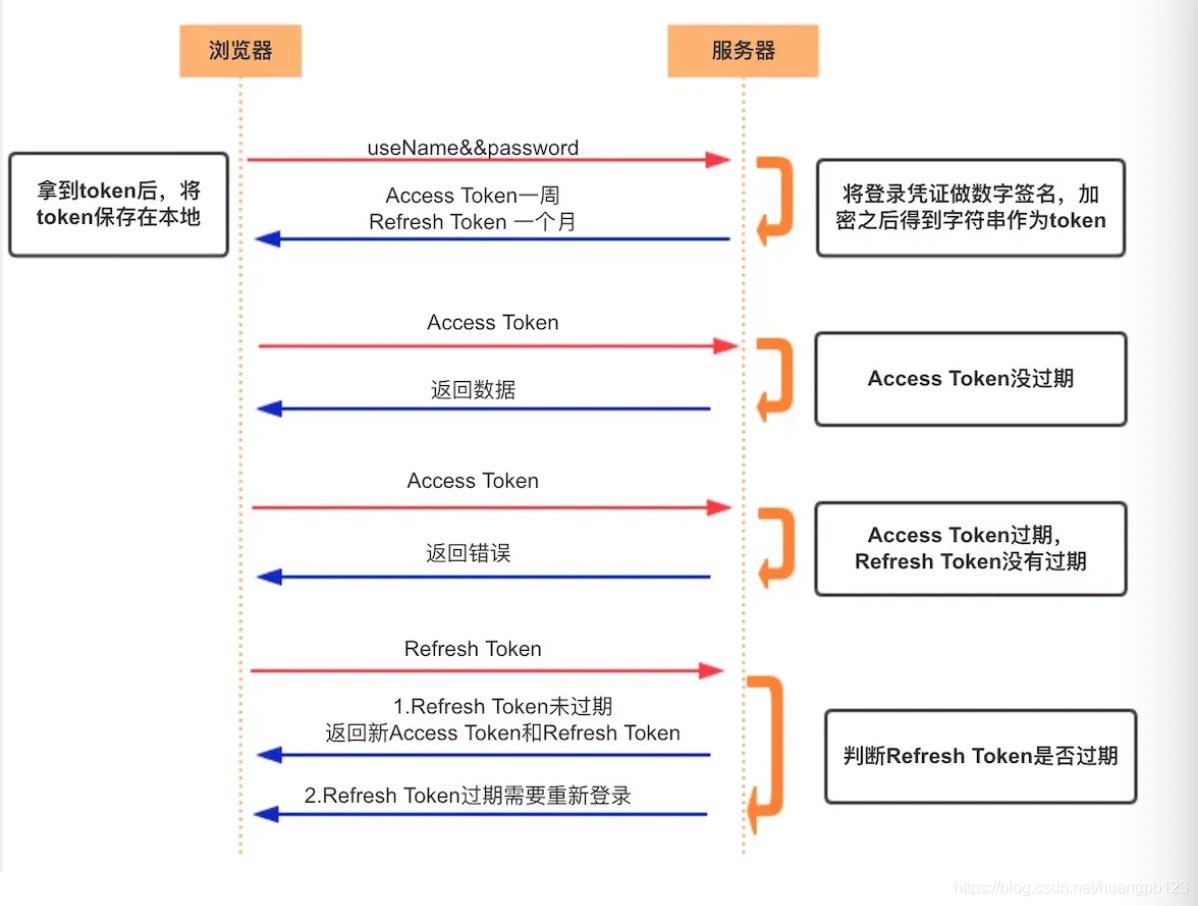
- Access Token 的有效期比较短,当 Acesss Token 由于过期而失效时,使用 Refresh Token
就可以获取到新的 Token,如果 Refresh Token 也失效了,用户就只能重新登录了。 - Refresh Token 及过期时间是存储在服务器的数据库中,只有在申请新的 Acesss Token
时才会验证,不会对业务接口响应时间造成影响,也不需要向 Session 一样一直保持在内存中以应对大量的请求。
六、Token 和 Session 的区别
- Session 是一种记录服务器和客户端会话状态的机制,使服务端有状态化,可以记录会话信息。而 Token
是令牌,访问资源接口(API)时所需要的资源凭证。Token 使服务端无状态化,不会存储会话信息。 - Session 和 Token 并不矛盾,作为身份认证 Token 安全性比 Session
好,因为每一个请求都有签名还能防止监听以及重复攻击,而 Session
就必须依赖链路层来保障通讯安全了。如果你需要实现有状态的会话,仍然可以增加 Session 来在服务器端保存一些状态。 - 如果你的用户数据可能需要和第三方共享,或者允许第三方调用 API 接口,用 Token 。如果永远只是自己的网站,自己的
App,用什么就无所谓了。
七、什么是 JWT
- JSON Web Token(简称 JWT)是目前最流行的跨域认证解决方案。 是一种认证授权机制。
- JWT 是为了在网络应用环境间传递声明而执行的一种基于 JSON 的开放标准。JWT
的声明一般被用来在身份提供者和服务提供者间传递被认证的用户身份信息,以便于从资源服务器获取资源。比如用在用户登录上。 - 可以使用 HMAC 算法或者是 RSA 的公/私秘钥对 JWT 进行签名。因为数字签名的存在,这些传递的信息是可信的。
JWT 的原理
JWT 的原理是,服务器认证以后,生成一个 JSON 对象,返回给用户,就像下面这样。
{
"姓名": "张三",
"角色": "管理员",
"到期时间": "2018年7月1日0点0分"
}
以后,用户与服务端通信的时候,都要发回这个 JSON 对象。服务器完全只靠这个对象认定用户身份。为了防止用户篡改数据,服务器在生成这个对象的时候,会加上签名。
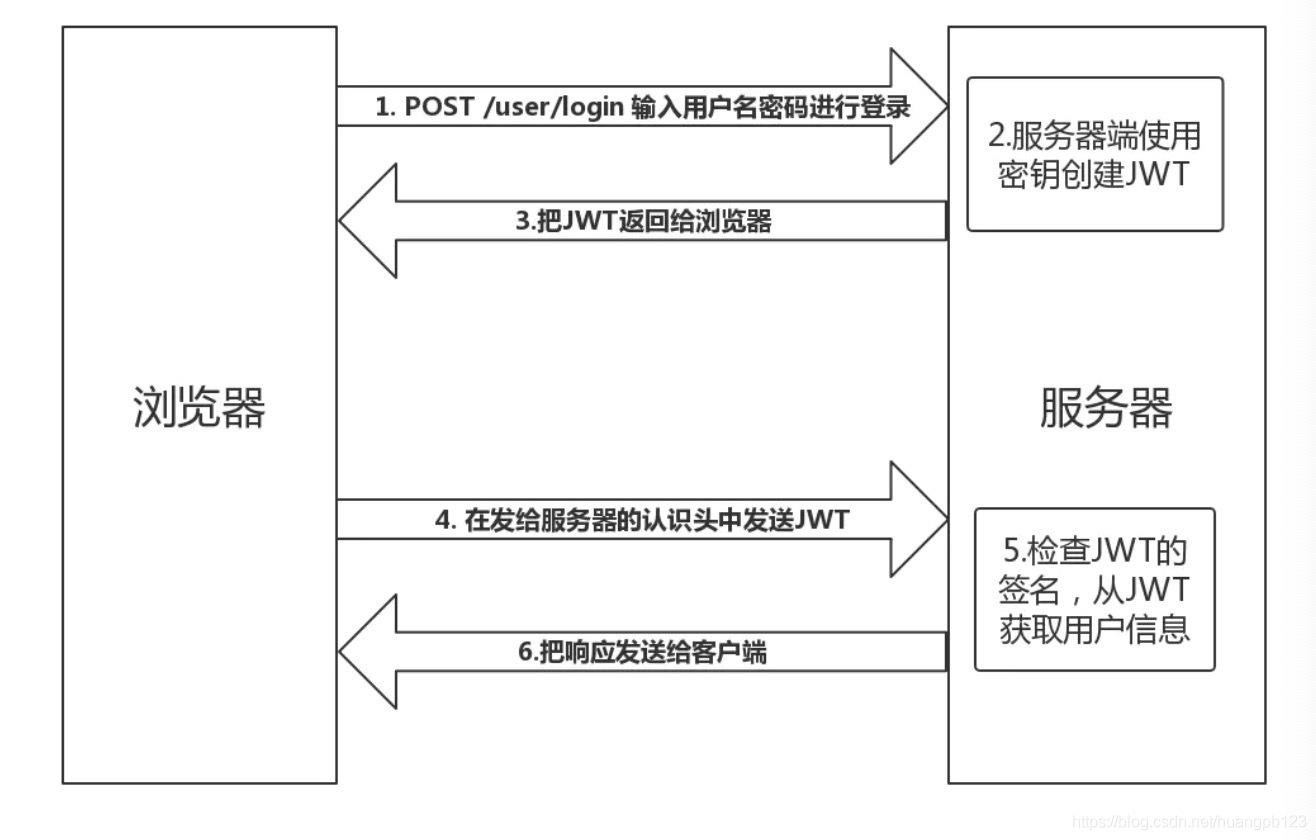
JWT 认证流程:
- 用户输入用户名/密码登录,服务端认证成功后,会返回给客户端一个 JWT
- 客户端将 token 保存到本地(通常使用 localstorage,也可以使用 cookie)
- 当用户希望访问一个受保护的路由或者资源的时候,需要请求头的 Authorization 字段中使用Bearer 模式添加
JWT,其内容看起来是下面这样
Authorization: Bearer <token>
- 服务端的保护路由将会检查请求头 Authorization 中的 JWT 信息,如果合法,则允许用户的行为
- 因为 JWT 是自包含的(内部包含了一些会话信息),因此减少了需要查询数据库的需要
- 因为 JWT 并不使用 Cookie 的,所以你可以使用任何域名提供你的 API 服务而不需要担心跨域问题
- 因为用户的状态不再存储在服务端的内存中,所以这是一种无状态的认证机制
JWT 的数据结构
实际的 JWT 大概就像下面这样:
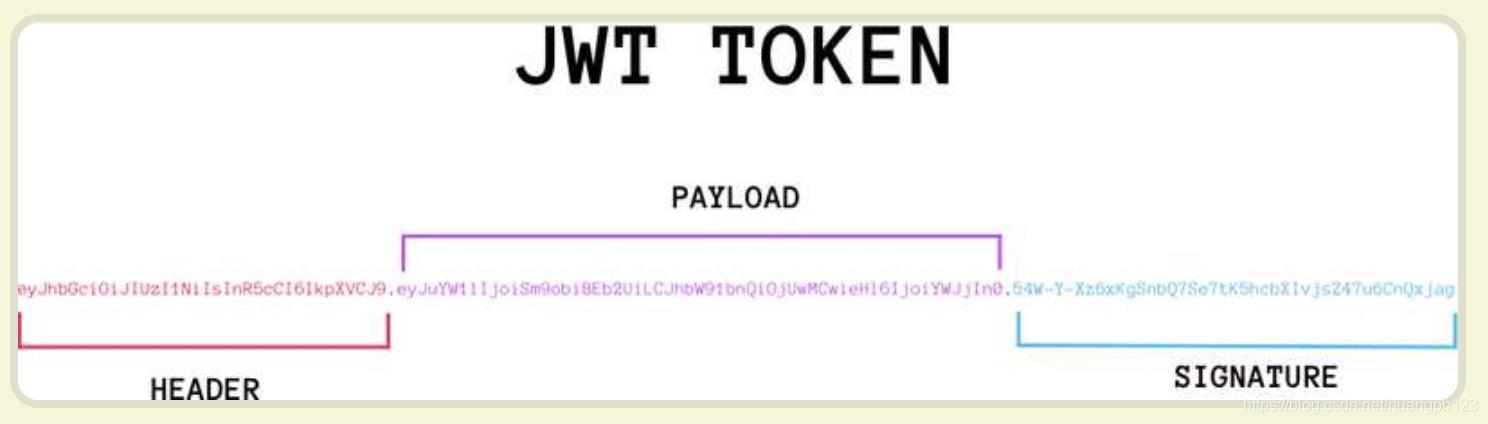
它是一个很长的字符串,中间用点(.)分隔成三个部分。
JWT 的三个部分依次如下:
Header(头部)
Payload(负载)
Signature(签名)
JWT详细数据结构
生成 JWT
八、Token 和 JWT 的区别
相同:
- 都是访问资源的令牌
- 都可以记录用户的信息
- 都是使服务端无状态化
- 都是只有验证成功后,客户端才能访问服务端上受保护的资源
区别:
- Token:服务端验证客户端发送过来的 Token 时,还需要查询数据库获取用户信息,然后验证 Token 是否有效。
- JWT: 将 Token 和 Payload 加密后存储于客户端,服务端只需要使用密钥解密进行校验(校验也是 JWT
自己实现的)即可,不需要查询或者减少查询数据库,因为 JWT 自包含了用户信息和加密的数据。
九、要注意的问题
使用 session 时需要考虑的问题
- 将 session 存储在服务器里面,当用户同时在线量比较多时,这些 session 会占据较多的内存,需要在服务端定期的去清理过期的
session - 当网站采用集群部署的时候,会遇到多台 web 服务器之间如何做 session 共享的问题。因为 session
是由单个服务器创建的,但是处理用户请求的服务器不一定是那个创建 session 的服务器,那么该服务器就无法拿到之前已经放入到
session 中的登录凭证之类的信息了。 - 当多个应用要共享 session 时,除了以上问题,还会遇到跨域问题,因为不同的应用可能部署的主机不一样,需要在各个应用做好 cookie
跨域的处理。 - sessionId 是存储在 cookie 中的,假如浏览器禁止 cookie 或不支持 cookie 怎么办? 一般会把
sessionId 跟在 url 参数后面即重写 url,所以 session 不一定非得需要靠 cookie 实现 - 移动端对 cookie 的支持不是很好,而 session 需要基于 cookie 实现,所以移动端常用的是 token
使用 JWT 时需要考虑的问题
- 因为 JWT 并不依赖 Cookie 的,所以你可以使用任何域名提供你的 API 服务而不需要担心跨域问题
- JWT 默认是不加密,但也是可以加密的。生成原始 Token 以后,可以用密钥再加密一次。
- JWT 不加密的情况下,不能将秘密数据写入 JWT。
- JWT 不仅可以用于认证,也可以用于交换信息。有效使用 JWT,可以降低服务器查询数据库的次数。
- JWT 最大的优势是服务器不再需要存储 Session,使得服务器认证鉴权业务可以方便扩展。但这也是 JWT
最大的缺点:由于服务器不需要存储 Session 状态,因此使用过程中无法废弃某个 Token 或者更改 Token 的权限。也就是说一旦
JWT 签发了,到期之前就会始终有效,除非服务器部署额外的逻辑。 - JWT
本身包含了认证信息,一旦泄露,任何人都可以获得该令牌的所有权限。为了减少盗用,JWT的有效期应该设置得比较短。对于一些比较重要的权限,使用时应该再次对用户进行认证。 - JWT 适合一次性的命令认证,颁发一个有效期极短的 JWT,即使暴露了危险也很小,由于每次操作都会生成新的 JWT,因此也没必要保存
JWT,真正实现无状态。 - 为了减少盗用,JWT 不应该使用 HTTP 协议明码传输,要使用 HTTPS 协议传输。
使用加密算法时需要考虑的问题
- 绝不要以明文存储密码
- 永远使用 哈希算法 来处理密码,绝不要使用 Base64
或其他编码方式来存储密码,这和以明文存储密码是一样的,使用哈希,而不要使用编码。编码以及加密,都是双向的过程,而密码是保密的,应该只被它的所有者知道,
这个过程必须是单向的。哈希正是用于做这个的,从来没有解哈希这种说法,但是编码就存在解码,加密就存在解密。 - 绝不要使用弱哈希或已被破解的哈希算法,像 MD5 或 SHA1 ,只使用强密码哈希算法。
- 绝不要以明文形式显示或发送密码,即使是对密码的所有者也应该这样。如果你需要 “忘记密码” 的功能,可以随机生成一个新的
一次性的(这点很重要)密码,然后把这个密码发送给用户。
只要关闭浏览器 ,session 真的就消失了?
不对。浏览器关闭时,是不会主动去通知服务器的。之所以会有这种错觉,是大部分 session 机制都使用会话 cookie 来保存 sessionId,而关闭浏览器后这个 cookie 就消失了,再次连接服务器时也就无法找到原来的 session。如果服务器设置的 cookie 被保存在硬盘上,或者使用某种手段改写浏览器发出的 HTTP 请求头,把原来的 sessionId 发送给服务器,则再次打开浏览器仍然能够打开原来的 session。
恰恰是由于关闭浏览器不会导致 session 被删除,迫使服务器为 session 设置了一个失效时间,当距离客户端上一次使用 session 的时间超过这个失效时间时,服务器就认为客户端已经停止了活动,才会把 session 删除以节省存储空间。
九、IOC
IOC是spring的两大核心概念之一,IOC给我们提供了一个IOCbean容器,这个容器会帮我们自动去创建对象,不需要我们手动创建,IOC实现创建的通过DI(Dependency Injection 依赖注入),我们可以通过写Java注解代码或者是XML配置方式,把我们想要注入对象所依赖的一些其他的bean,自动的注入进去,他是通过byName或byType类型的方式来帮助我们注入。正是因为有了依赖注入,使得IOC有这非常强大的好处,解耦。
可以举个例子,JdbcTemplate 或者 SqlSessionFactory 这种bean,如果我们要把他注入到容器里面,他是需要依赖一个数据源的,如果我们把JdbcTemplate 或者 Druid 的数据源强耦合在一起,会导致一个问题,当我们想要使用jdbctemplate必须要使用Druid数据源,那么依赖注入能够帮助我们在Jdbc注入的时候,只需要让他依赖一个DataSource接口,不需要去依赖具体的实现,这样的好处就是,将来我们给容器里面注入一个Druid数据源,他就会自动注入到JdbcTemplate如果我们注入一个其他的也是一样的。比如说c3p0也是一样的,这样的话,JdbcTemplate和数据源完全的解耦了,不强依赖与任何一个数据源,在spring启动的时候,就会把所有的bean全部创建好,这样的话,程序在运行的时候就不需要创建bean了,运行速度会更快,还有IOC管理bean的时候默认是单例的,可以节省时间,提高性能,
十、AOP
【SpringBoot-3】切面AOP实现权限校验:实例演示与注解全解
【SpringBoot-3】切面AOP实现权限校验:实例演示与注解全解
十一、Shiro和Spring Security对比
Shiro简介
Apache Shiro是Java的一个安全框架。目前,使用Apache Shiro的人越来越多,因为它相当简单,对比Spring Security,可能没有Spring Security做的功能强大,但是在实际工作时可能并不需要那么复杂的东西,所以使用小而简单的Shiro就足够了。对于它俩到底哪个好,这个不必纠结,能更简单的解决项目问题就好了。
Shiro架构与功能介绍
1.认证与授权相关基本概念
两个基本的概念
安全实体:系统需要保护的具体对象数据
权限:系统相关的功能操作,例如基本的CRUD
Authentication:身份认证/登录,验证用户是不是拥有相应的身份;
Authorization:授权,即权限验证,验证某个已认证的用户是否拥有某个权限;即判断用户是否能做事情,常见的如:验证某个用户是否拥有某个角色。或者细粒度的验证某个用户对某个资源是否具有某个权限;
Session Manager:会话管理,即用户登录后就是一次会话,在没有退出之前,它的所有信息都在会话中;会话可以是普通JavaSE环境的,也可以是如Web环境的;
Cryptography:加密,保护数据的安全性,如密码加密存储到数据库,而不是明文存储;
Web Support:Web支持,可以非常容易的集成到Web环境;
Caching:缓存,比如用户登录后,其用户信息、拥有的角色/权限不必每次去查,这样可以提高效率;
Concurrency:shiro支持多线程应用的并发验证,即如在一个线程中开启另一个线程,能把权限自动传播过去;
Testing:提供测试支持;
Run As:允许一个用户假装为另一个用户(如果他们允许)的身份进行访问;
Remember Me:记住我,这个是非常常见的功能,即一次登录后,下次再来的话不用登录了。
2.Shiro四大核心功能:Authentication,Authorization,Cryptography,Session Management
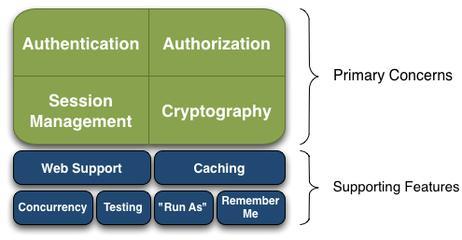
Shiro架构
3.Shiro三个核心组件:Subject, SecurityManager 和 Realms.
Subject:主体,代表了当前“用户”,这个用户不一定是一个具体的人,与当前应用交互的任何东西都是Subject,如网络爬虫,机器人等;即一个抽象概念;所有Subject都绑定到SecurityManager,与Subject的所有交互都会委托给SecurityManager;可以把Subject认为是一个门面;SecurityManager才是实际的执行者;
SecurityManager:安全管理器;即所有与安全有关的操作都会与SecurityManager交互;且它管理着所有Subject;可以看出它是Shiro的核心,它负责与后边介绍的其他组件进行交互,如果学习过SpringMVC,你可以把它看成DispatcherServlet前端控制器;
Realm:域,Shiro从从Realm获取安全数据(如用户、角色、权限),就是说SecurityManager要验证用户身份,那么它需要从Realm获取相应的用户进行比较以确定用户身份是否合法;也需要从Realm得到用户相应的角色/权限进行验证用户是否能进行操作;可以把Realm看成DataSource,即安全数据源。
Spring Security简介
Spring Security是一个能够为基于Spring的企业应用系统提供声明式的安全访问控制解决方案的安全框架。它提供了一组可以在Spring应用上下文中配置的Bean,充分利用了Spring IoC,DI(控制反转Inversion of Control ,DI:Dependency Injection 依赖注入)和AOP(面向切面编程)功能,为应用系统提供声明式的安全访问控制功能,减少了为企业系统安全控制编写大量重复代码的工作。它是一个轻量级的安全框架,它确保基于Spring的应用程序提供身份验证和授权支持。它与Spring MVC有很好地集成,并配备了流行的安全算法实现捆绑在一起。安全主要包括两个操作“认证”与“验证”(有时候也会叫做权限控制)。“认证”是为用户建立一个其声明的角色的过程,这个角色可以一个用户、一个设备或者一个系统。“验证”指的是一个用户在你的应用中能够执行某个操作。在到达授权判断之前,角色已经在身份认证过程中建立了。
它的设计是基于框架内大范围的依赖的,可以被划分为以下几块。
- Web/Http 安全:这是最复杂的部分。通过建立 filter 和相关的 service bean 来实现框架的认证机制。当访问受保护的
URL 时会将用户引入登录界面或者是错误提示界面。 - 业务对象或者方法的安全:控制方法访问权限的。
- AuthenticationManager:处理来自于框架其他部分的认证请求。
- AccessDecisionManager:为 Web 或方法的安全提供访问决策。会注册一个默认的,但是我们也可以通过普通 bean
注册的方式使用自定义的 AccessDecisionManager。 - AuthenticationProvider:AuthenticationManager 是通过它来认证用户的。
- UserDetailsService:跟 AuthenticationProvider 关系密切,用来获取用户信息的。
Shiro和Spring Security比较
- Shiro比Spring更容易使用,实现和最重要的理解
- Spring Security更加知名的唯一原因是因为品牌名称 “Spring”以简单而闻名,但讽刺的是很多人发现安装Spring
Security很难 - 然而,Spring Security却有更好的社区支持
- Apache Shiro在Spring Security处理密码学方面有一个额外的模块
- Spring-security 对spring 结合较好,如果项目用的springmvc
,使用起来很方便。但是如果项目中没有用到spring,那就不要考虑它了。 - Shiro 功能强大、且 简单、灵活。是Apache 下的项目比较可靠,且不跟任何的框架或者容器绑定,可以独立运行
十二、单例模式
十三、简单工厂模式
更多java全栈相关技术文章点下面哦
记录我的自学成长日志
【Java全栈】Java全栈学习路线及项目全资料总结【JavaSE+Web基础+大前端进阶+SSM+微服务+Linux+JavaEE】
【Java全栈】Java全栈学习路线及项目全资料总结【JavaSE+Web基础+大前端进阶+SSM+微服务+Linux+JavaEE】
以上是关于后端学习后端技术要点总结的主要内容,如果未能解决你的问题,请参考以下文章