selenium 分分钟爬取51job(前程无忧),获取职位招聘详细信息,十万数据不是梦
Posted myriads_changes_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了selenium 分分钟爬取51job(前程无忧),获取职位招聘详细信息,十万数据不是梦相关的知识,希望对你有一定的参考价值。
大数据的时代,数据成为最重要的基础,不管是数据挖掘、数据分析、还是人工智能里的机器学习还是深度学习,数据就是基础,没有数据就没有后期的发展。
下面是为做数据分析来爬取的51job网的职位数据。
环境:
- python3.7.3
- windows10
- Google驱动
- selenium
- csv
1 模拟登录
第一步我们先配置谷歌,谷歌驱动,在这里我们需要加载 图片,因为在登录验证的时候我们需要手动去勾选同意条款
def main():
option = webdriver.ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
driver = webdriver.Chrome(executable_path=r'D:\\chromedriver.exe',options=option)
driver.set_page_load_timeout(15)
login(driver)
在这里就是在驱动打开后,我们去定位密码登录、账号输入框、密码输入框、登录框
在他自动填写密码完成后,我们需要手动勾选我同意条款合约,然后就需要等待他自己自动点击登录,在这里如果出现了滑动验证,也是一样,需要自己手动去拖动,在这里也不好去写滑动块的拉动,因为它在有的时候没有验证的那一步~~~~
driver.delete_all_cookies()
url = "https://login.51job.com/login.php?lang=c"
driver.get(url)
time.sleep(5)
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/div[1]/span[3]/a').click()
time.sleep(1)
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[1]/div/input[1]').send_keys('51job账号')
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[2]/div/input[1]').send_keys('51job密码')
time.sleep(10)
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[4]/button').click() # 点击登录
2 获取URL
在登陆成功后就分为两步
(1)获取具体公司的URL
在这里需要提前提供好你要爬取的关键字的职位的url,在改变里面的换页编号,
将第一页获取的URL保存,供后期的详细信息爬取。
url = ["https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,{0}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=".format(i) for i in range(1, 822)]
for k in url:
driver.get(k)
time.sleep(10)
url_3 = []
for id in range(1,50):
x = driver.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div[{}]/a'.format(id))
url_3.append(x.get_attribute("href"))
(2) 获取具体岗位的详情信息
在这里就是根据前面获取的url来爬取里面的详细信息,
注意注意注意注意注意注意注意注意注意
在这里我们,需要去判断
-
判断页面是否加载完成--------------么有加载完,就需要去重新加载
-
判断页面是否是405/443---------- 出现错误,就需要去判断是否是被封IP
-
判断打开页面是否符合要求--------错误页面。就需要去更换URL,重新打开
for j in url_3:
po = 1
driver.get(j) # 详细资料爬取
kl = 0
time.sleep(5)
while True:
try:
kl += 1
gangwei = driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]').text.split('\\n')
break
except:
if kl == 10:
print('--------*****************----------')
time.sleep(5)
print('-----------*************************************************-------')
po = 0
break
else:
time.sleep(5)
continue
if po == 0:
continue


注意
打开URL链接后我们应该设置等待时间,不然十分十分十分容易被封IP
完整代码
import time
import pandas as pd
from selenium import webdriver
import csv
from selenium.webdriver import ActionChains
f = open('./51116.csv','w',newline='')
writer = csv.writer(f)
a = []
def login(driver):
global gangwei, zhiweixin, gsxinxi
li = []
driver.delete_all_cookies()
url = "https://login.51job.com/login.php?lang=c" #https://www.qcc.com/weblogin?back=%2F
driver.get(url)
time.sleep(5)
# 点击密码登入
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/div[1]/span[3]/a').click()
time.sleep(1)
# 输入账号密码
#driver.find_element_by_id('nameNormal').send_keys(username) # /html/body/div[1]/div[3]/div/div[2]/div[3]/form/div[1]/input
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[1]/div/input[1]').send_keys('账号')
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[2]/div/input[1]').send_keys('密码')
time.sleep(10)
driver.find_element_by_xpath('/html/body/div[3]/div[1]/div[2]/form/div[4]/button').click() # 点击登录
time.sleep(5)
url = ["https://search.51job.com/list/000000,000000,0000,00,9,99,python,2,{0}.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=".format(i) for i in range(1, 822)]
for k in url:
driver.get(k)
time.sleep(10)
url_3 = []
for id in range(1,50):
x = driver.find_element_by_xpath('/html/body/div[2]/div[3]/div/div[2]/div[4]/div[1]/div[{}]/a'.format(id))
url_3.append(x.get_attribute("href"))
for j in url_3:
po = 1
driver.get(j) # 详细资料爬取
kl = 0
time.sleep(5)
while True:
try:
kl += 1
gangwei = driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]').text.split('\\n')
break
except:
if kl == 10:
print('--------*****************----------')
time.sleep(5)
print('-----------*************************************************-------')
po = 0
break
else:
time.sleep(5)
continue
if po == 0:
continue
print(gangwei)
li.extend(gangwei)
t1 = 0
while True:
try:
t1 += 1
zhiweixin=driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div').text
gsxinxi = driver.find_element_by_xpath('/html/body/div[3]/div[2]/div[3]/div[3]/div').text
break
except:
time.sleep(5)
if t1==3:
break
if t1==3:
continue
li.extend([j,zhiweixin,gsxinxi])
try:
writer.writerow(li)
except:
pass
time.sleep(5)
time.sleep(60)
def main():
# while True:
"""
chromeOptions 是一个配置 chrome 启动是属性的类,就是初始化
"""
option = webdriver.ChromeOptions()
"""
add_experimental_option 添加实验性质的设置参数
"""
option.add_experimental_option('excludeSwitches', ['enable-automation']) # webdriver防检测
'''
add_argument 添加启动参数
'''
# option.add_argument("--disable-blink-features=AutomationControlled")
# option.add_argument("--no-sandbox")
# option.add_argument("--disable-dev-usage")
# option.add_experimental_option("prefs", {"profile.managed_default_content_settings.images": 2})
"""
Chrome 配置驱动
"""
driver = webdriver.Chrome(executable_path=r'D:\\chromedriver.exe',options=option)#需要下载跟你谷歌版本相对应的chromedriver驱动
driver.set_page_load_timeout(15)
login(driver)
# jugesd(driver)
if __name__ == '__main__':
username = '51job账号'
password = '51job密码'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36'}
main()
f.close()
数据集
共享51job数据集:https://download.csdn.net/download/qq_44936246/21959320
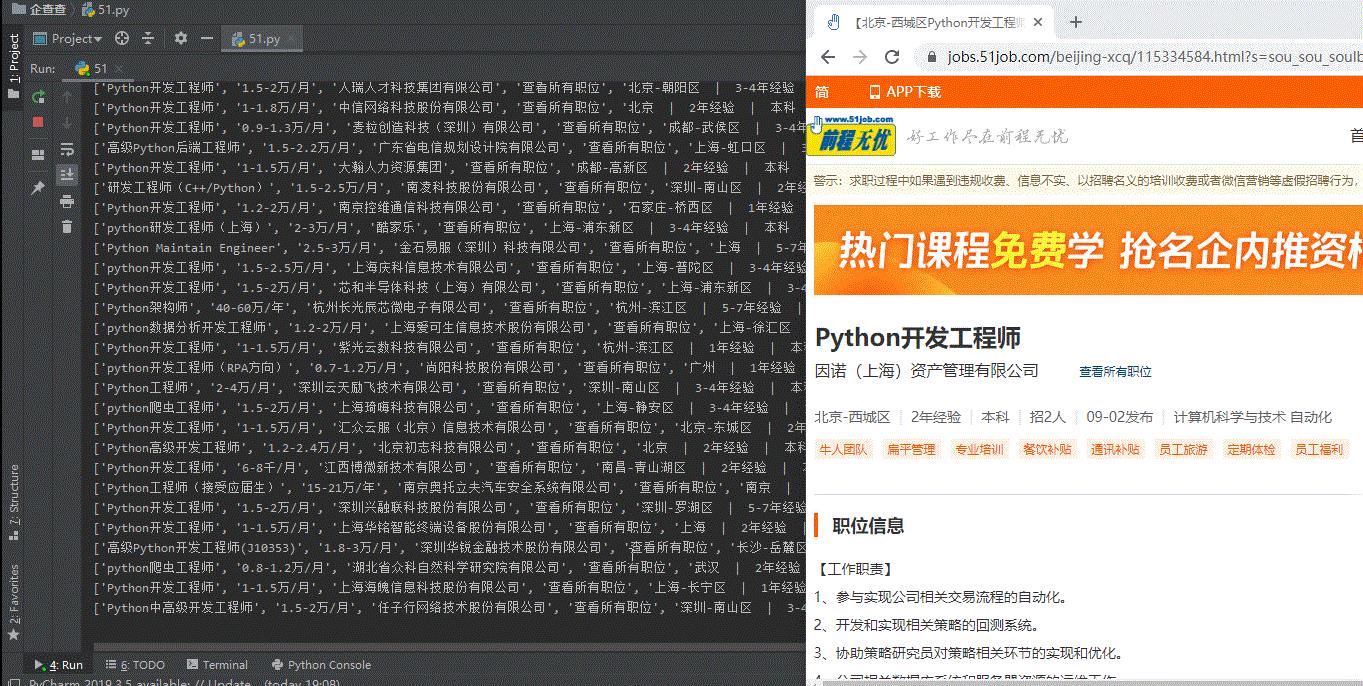
结果展示
希望这篇博文对你有用!
谢谢点赞评论!
以上是关于selenium 分分钟爬取51job(前程无忧),获取职位招聘详细信息,十万数据不是梦的主要内容,如果未能解决你的问题,请参考以下文章